План бэктфилла для живой миграции данных без простоя
Практическое руководство по бэктфиллу при живой миграции: разбивайте историю на батчи, защищайте новые записи, отслеживайте скорость догоняния и завершайте с меньшим риском.
Содержание
Почему живые миграции ломаются в реальной жизни
Большинство команд не могут остановить продукт настолько долго, чтобы скопировать всё из одной системы в другую. Заказы продолжают поступать. Пользователи продолжают править профили. Саппорт продолжает менять настройки аккаунтов. Фоновые задания продолжают писать данные. Даже несколько часов простоя могут означать потерянные продажи, сердитых клиентов и работу по очистке, которая тянется днями.
Поэтому у живой миграции две задачи, а не одна. Нужно перенести старые данные, которые уже лежат в источнике, и нужно успеть за новыми записями, которые приходят в процессе копирования. Команды обычно планируют первую задачу и недооценивают вторую.
Старые записи создают проблему объёма. Возможно, придётся скопировать миллионы строк, файлов, событий или документов, и каждая партия занимает время на чтение, трансформацию, валидацию и запись. Новые записи создают проблему времени. Клиент может обновить ту же запись в то время, как бэктфилл ещё на половине пути, или через секунду после того, как вы скопировали старую версию.
Когда миграция начинает отставать, пользователи быстро замечают это. Они видят пропущенные заказы, устаревшие балансы, дублированные сообщения, результаты поиска, которые не отражают недавние правки, или дашборд, где на одном экране вчерашнее состояние, а на другом — сегодняшнее. Приложение вроде бы "вверх", но данные кажутся случайными — и тогда доверие начинает падать.
Для загруженного SaaS-продукта это усиливается. Представьте команду, переносящую аккаунты клиентов в новую базу, в то время как менеджеры по продажам продолжают обновлять платёжные данные, а пользователи — права доступа. Если миграция копирует старые строки большими кусками без обработки свежих изменений, новая система всегда будет отставать от реальной активности.
Цель проста: переместить данные, не блокируя ежедневную работу. Для этого план должен скопировать прошлое, зафиксировать настоящее и показывать команде, насколько он отстаёт в любой момент. Если обычная работа должна остановиться, чтобы миграция "перевела дух", план слишком хрупок.
Что нужно защитить в плане
Начните с одного прямого вопроса: какие данные не могут быть ошибочными даже на минуту? Команды часто стремятся перенести всё. Безопаснее сначала назвать записи, которые влияют на деньги, доступ, активность клиентов и отчётность.
В большинстве систем есть два очень разных типа данных. Исторические записи — это старые заказы, логи, архивные сообщения и прошлые снимки. Свежие записи — это строки, файлы или события, которые пользователи создают прямо сейчас. Историю обычно можно бэктфиллить партиями, если дать на это время. Свежие записи требуют жёстких правил, потому что они меняются в ходе миграции.
Если обращать с этими группами одинаково, проблемы остаются незамеченными до позднего этапа. Клиент меняет адрес в старой системе, платёж приходит в новую — и один и тот же аккаунт оказывается в двух разных состояниях. Дашборд может выглядеть нормально, но продукт ломается в реальном использовании.
Практичный способ сортировать приоритеты — по бизнес-риску. Ставьте на верх балансы, биллинг, инвентарь и права доступа. Далее — записи, которые клиенты могут менять во время миграции. Потом — записи, нужные для саппорта, аудитов или юридической истории. Большие старые наборы данных, которые редко меняются, могут подождать, пока процесс не станет стабильным.
Такой порядок даёт разумный порядок раскатки. Начинайте с данных, которые можно копировать и верифицировать при невысокой изменчивости. Оставьте самые загруженные пути записи на потом, когда проверки версий, правила реплея и валидация уже работают. Если файлы зависят от строк в базе, или события позже восстанавливают таблицы, перемещайте их в порядке, который сохраняет зависимости.
Полезно также записать, что может отставать, на сколько и что должно совпадать до переключения. Команда, которая заранее согласует эти правила, принимает лучшие решения в стрессовых ситуациях.
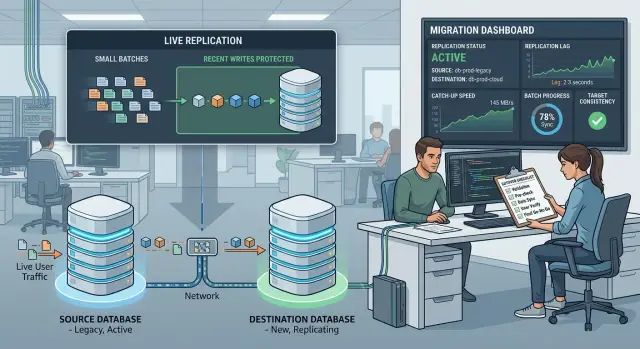
Как разрезать данные на безопасные батчи
Бэктфиллы работают лучше, когда каждый батч скучен. Нужны куски, которые быстро завершаются, при ошибке затрагивают небольшую область и дают точную информацию о том, что нужно повторить. Если один батч идёт два часа и трогает половину таблицы, это уже не батч — это ещё одна миграция внутри первой.
Выберите поле, которое уже разделяет данные аккуратно. Команды обычно используют диапазоны по времени, по ID, по арендаторам или по регионам. Лучший выбор зависит от того, как люди пользуются продуктом. Если у вас всплески трафика вокруг нескольких крупных клиентов, разрезы по арендаторам обычно лучше, чем простые диапазоны ID. Если старые записи редко меняются, оконные диапазоны по дате легче управлять.
Держите батчи достаточно маленькими, чтобы повторный запуск был дешёвым. Хороший батч обычно завершается за пару минут, а не полдня. Это даёт возможность приостановиться, проверить ошибки и заново прогнать тот же срез без превращения всей миграции в пожар.
Простые правила помогают. Используйте одну понятную границу на батч — например, один день данных или одна группа арендаторов. Подберите размер так, чтобы при ошибке можно было быстро повторить. Начинайте с тихих данных перед тем, как брать занятые аккаунты или недавние записи. Зафиксируйте точный порядок перед началом и заранее определите стоп‑условия: уровень ошибок, растущий лаг или несоответствие количества строк.
Порядок важнее, чем многие думают. Начните с низкорискованных срезов, чтобы протестировать путь при обычной нагрузке. Переходите к более тяжёлым или активным срезам только после прохождения ранних валидаций. Первые запуски покажут, реалистичный ли размер батча или его нужно уменьшить.
Запишите план простым языком. Например: мигрировать арендаторов 101–150, затем 151–200, приостанавливать, если лаг остаётся выше пяти минут более десяти минут, останавливать при провале валидации на любом батче. Во время живой миграции простые правила бьют умные.
Как защитить недавние записи во время бэктфилла
Если клиенты продолжают делать заказы, править профили или отменять подписки, бэктфилл быстро устаревает. Во время миграции делайте источник единственным местом, принимающим записи, до момента переключения.
Этот выбор избегает грязной схемы split brain. В большинстве случаев самая безопасная защита — один путь записи плюс зеркальный поток изменений, а не две параллельные записи из приложения в две БД.
Каждая новая вставка, обновление и удаление должны создавать запись изменения, которую цель может применить в порядке. Команды часто используют change data capture, outbox‑таблицу или событийный лог для этого. Инструмент менее важен, чем правило: каждое изменение должно быть воспроизводимо.
Цель также должна уметь отвергать устаревшие данные. Если бэктфилл копирует старую строку после того, как более новое изменение уже попало в цель, цель должна сохранить новую версию. Номер версии источника, счётчик, последовательность или доверенное время обновления обычно решают проблему. Если входящий батч старее, чем то, что уже есть в цели — пропустите его.
Удаления требуют того же внимания. Не убирайте их из потока только потому, что строка исчезла в таблице источника. Храните tombstone или событие удаления, чтобы цель знала, что запись была удалена и не восстановила её при следующем батче.
Храните достаточно метаданных, чтобы восстановиться после пропущенного окна или падения воркера: стабильный ID записи, тип операции, порядковый номер источника или позиция в логе, время коммита или версия источника и маркер удаления, когда строка больше не существует.
Небольшой пример всё поясняет. Допустим, пользователь поменял адрес в 10:02, и поток изменений доставил это обновление в цель сразу. В 10:03 бэктфилл копирует старую строку с 9:55. Без проверок версий цель окажется неверной. С проверками цель проигнорирует устаревшую строку и сохранит новый адрес.
Если зеркало останавливается на 20 минут, вы должны точно знать, откуда возобновить. Когда можно перезапустить с последней сохранённой позиции и воспроизвести каждое пропущенное изменение, недавние записи защищены, пока бэктфилл продолжает двигаться.
Как измерять скорость догоняния
Миграция проваливается, когда команда смотрит только на общее число скопированных строк, но игнорирует лаг. Грубая скорость красиво смотрится на дашборде, но не показывает, приближается ли цель к реальному времени.
Следите за четырьмя числами вместе: строки в минуту, число неудач или процент повторных попыток, лаг между источником и целью и глубина очереди ожидающих батчей или событий.
Строки в минуту показывают, как быстро воркеры копируют старые данные. Процент повторов показывает, настоящая ли это скорость. Воркер, копирующий 200 000 строк в минуту и затем повторяющий 15 % из них, далеко не так быстр, как кажется.
Лаг особенно важен перед переключением. Измеряйте его во времени и в записях. Временной лаг отвечает на вопрос «насколько цель отстаёт?», лаг в записях — «сколько данных ещё нужно доставить?». Нужны оба показателя, потому что небольшое число тяжёлых записей всё ещё может затянуть финиш.
Используйте чистую пропускную способность, а не просто сырой throughput. Если бэктфилл‑воркеры переносят 180 000 строк в минуту, но источник получает 30 000 новых строк в минуту, реальная скорость догоняния — 150 000 строк в минуту. Если осталось 12 миллионов строк, потребуется около 80 минут, а не 67. Пересчитывайте оценку по живому трафику каждые несколько минут. Оценка до запуска долго не продержится.
Также следите за зависаниями. Настройте алерты, когда воркер не показывает прогресса несколько минут, когда повторные попытки прыгают выше обычного или когда очередь ожидающих растёт вместо того, чтобы уменьшаться. Растущая очередь обычно означает одно из двух: цель стала медленнее или свежие записи начали приходить быстрее, чем конвейер успевает их обработать.
Не ждите полного отказа, чтобы считать это проблемой. Если лаг растёт 10–15 минут подряд, приостановите следующий батч, проверьте нагрузку записи и найдите узкое место, пока пользователи ещё работают нормально.
Пошаговый план раскатки
Хорошая раскатка сначала кажется немного медленной. Это обычно хороший знак. Вам нужна достаточно контроля, чтобы поймать неверные предположения, пока они не распространились на миллионы строк.
Обращайтесь с миграцией как с серией проходов с ограждениями (gated passes). У каждого прохода должны быть чёткая цель, стоп‑правило и один человек, который решает — продолжать или приостановиться.
-
Заморозьте объём для первого прохода. Выберите точные таблицы, поля и пути записи, которые включите, и не трогайте остальное. Если продуктовая команда продолжит добавлять изменения схемы или особые случаи в первом прогоне, вы потеряете возможность отличить несоответствие, вызванное миграцией, от меняющихся требований.
-
Запустите небольшой пробный батч первым. Возьмите узкий срез данных, который легко проверить — один арендатора, один диапазон дат или несколько тысяч записей. Сравните числа строк, контрольные суммы, таймстемпы и несколько реальных записей вручную. Маленькие тесты быстро ловят неприятные сюрпризы, вроде сдвигов часовых поясов или пропущенных значений по умолчанию.
-
Увеличивайте объём ступенями. Переходите от крошечных батчей к средним, затем к большим, наблюдая за лагом, процентом повторов, глубиной очереди и нагрузкой на базу. Если первый батч скопировал 10 000 строк чисто, следующий не обязательно должен быть 10 миллионов. Увеличение в 5x или 10x проще контролировать.
-
Приостанавливайте при дрейфе чисел. Не прогоняйте дальше плохие сигналы. Если счёты перестали сходиться, недавние записи не появляются или база источника замедляется — остановитесь, исправьте причину и возобновите с последнего чистого контрольного пункта. Это гораздо дешевле, чем чистить тихие повреждения данных потом.
Ведите записи в ходе каждого прохода. Записывайте размер батча, время выполнения, лаг и что изменилось перед следующим запуском. После двух–трёх раундов обычно проявляется закономерность, и финальная раскатка перестаёт быть ставкой.
Простой пример из загруженного продукта
Подписочное приложение — хороший кейс, потому что оно почти не спит. Клиенты меняют карты, закрываются счета, срабатывают продления и саппорт правит данные аккаунтов весь день. Если вы остановите записи, вы блокируете выручку. Если сдвинуть всё за раз, растёт шанс грязного отката.
Более безопасный план начинается с древней истории клиентов. Команда копирует закрытые счета, прошлые расчётные периоды и неактивные аккаунты в первую очередь. Эти строки важны, но реже меняются, поэтому их безопаснее переносить партиями.
Команда может разбить копирование по месяцу выставления счета или по диапазону ID клиентов. Это держит каждый батч достаточно маленьким для повтора. Если неудача случилась в батче 18, они перезапускают только батч 18, а не всё заново.
Пока этот бэктфилл идёт, приложение продолжает принимать свежие платежи и правки профилей. Каждая новая оплата, возврат, смена email или тарифа идёт через очередь реплея. Новая база получает эти свежие записи после того, как базовые записи прибыли, так что она не уходит далеко в отставание.
Одно простое правило помогает: сначала копируйте прошлое, непрерывно воспроизводите настоящее. Это держит миграцию в движении без заморозки обычной работы.
Перед переключением чтений сравните обе стороны по числам, которые действительно важны бизнесу: активные подписки по планам, итоги счётов по дням, итоги неоплаченных балансов, последние ID платежей для выборки клиентов и недавние обновления профилей для выборки аккаунтов.
Не переключайте трафик только потому, что job копирования закончилась. Подождите, пока эти итоги не сольются и очередь реплея не будет практически пуста. Если старая система показывает 12 404 активных подписки, а новая — 12 398, остановитесь и найдите разрыв.
Когда счёты и денежные итоги совпадут, переведите небольшую долю чтений на новую базу. Саппорт должен проверить пару реальных аккаунтов, включая один с неудачным платёжом и один с недавней правкой профиля. Если они выглядят правильно, перевод остальных чтений станет гораздо менее рискованным.
Ошибки, которые команды делают при бэктфилле
Большинство провалов происходит из простых решений, которые на бумаге кажутся безобидными. Команды часто гоняются за сырой скоростью, не обеспечив безопасность повторных запусков. Быстрые копии красиво выглядят до тех пор, пока один плохой батч не вызовет грязный рестарт.
Первая ошибка — делать батчи слишком большими. Если один батч трогает миллионы строк, тайм-аут, блокировка или плохая трансформация превращают мелкую проблему в часы очистки. Меньшие срезы требуют больше планирования, но их гораздо легче снова прогнать и проверить. Если батч падает днём, команда должна иметь возможность перезапустить этот срез за минуты, а не провести остаток дня в распутывании.
Удаления создают ещё одну тихую проблему. Команды часто держат вставки и обновления в синхроне, а удаления оставляют на финальное переключение. Это создаёт "призрачные" записи в цели: данные, которые там кажутся реальными, но уже не существуют в источнике. Если клиент удалил проект три дня назад, переключение не должно вернуть его. Обрабатывайте удаления с самого начала, даже если вы отслеживаете их в простом логе изменений.
Ещё одна частая ошибка — доверять только числу строк. Две таблицы могут иметь одинаковое количество строк и при этом отличаться по полям, которые реально важны. Флаг статуса, настройка биллинга, отметка времени или значение прав могут сломать продукт, даже если итоги совпадают. Сравнивайте примерные записи по полям и начинайте с колонок, которые меняют пользовательский опыт.
Команды также переключаются слишком рано. Они видят падение лага один раз, считают цель готовой и переключают трафик, хотя система ещё шатается под нормальной нагрузкой. Наблюдайте лаг во времени, а не по одному счастливому моменту. Если утром по будням всегда всплеск, дождитесь этого окна и убедитесь, что цель всё ещё догоняет.
Хороший бэктфилл должен быть скучным в лучшем смысле. Малые повторы работают. Удаления синхронизированы. Проверки глубже простых подсчётов строк. Лаг остаётся низким настолько долго, что никто не угадывает.
Короткий чеклист перед переключением
День переключения — плохое время полагаться на интуицию. Перед тем как переключить чтения или остановить старый путь, приостановитесь и вручную проверьте несколько вещей.
- Сравните небольшой набор записей в обеих системах. Включите старые строки, записи, созданные в последние минуты, и записи, которые менялись больше одного раза в окне бэктфилла.
- Проверьте эти примеры по полям. Ищите пропущенные обновления, неправильные таймстемпы, пустые поля и дублированные строки.
- Вызовите несколько реальных записей и убедитесь, что они попадают в нужное место. Если используете зеркальные записи, убедитесь, что обе стороны получают одно и то же изменение в одном порядке.
- Просмотрите лаг, объём повторов и неудачных записей. Низкий средний лаг может скрывать небольшой набор застрявших элементов, которые много значат.
- Ещё раз прогоните шаги отката, даже если вы тестировали их на прошлой неделе. Люди забывают команды, истекают креденшалы, меняются дашборды.
Числа помогают, но не заменяют прямых проверок. Если ваш дашборд показывает лаг почти ноль, а один недавний аккаунт всё ещё отличается — остановитесь и сначала исправьте это. Одна рассогласованная запись указывает на класс записей, который вы ещё не нашли.
Держите финальную проверку маленькой и практичной. 10–20 проверочных записей, пара свежих операций и один прогон отката обычно говорят больше, чем ещё час споров. Если что‑то не ясно, отложите переключение. Короткая задержка дешева. Исправление тихой потери данных после запуска — дорого.
Следующие шаги, если нужна вторая пара глаз
План миграции, живущий в голове одного человека, обычно разваливается под давлением. Запишите весь ранбук перед работой в проде. Держите его простым: что стартует первым, что остаётся только для чтения, что сравнивается, кто принимает решение о переключении и что переводит команду к откату.
Ваш ранбук должен отвечать на вопросы, которые люди задают, когда всё накаляется. Если лаг перестаёт снижаться — кто решает ждать или прерывать? Если зеркальные записи расходятся — кто проверяет источник правды? Если саппорт начинает видеть проблемы у клиентов — кто приостанавливает миграцию?
Чёткая ответственность помогает больше, чем ещё одна встреча. Один человек должен отвечать за копирование данных и проверки валидации. Другой — за поведение записей приложения, зеркальные записи и feature‑флаги. Третий — за шаги отката и журнал решений. Четвёртый — за метрики, ошибки и скорость догоняния во время перемещения.
Такой уровень ясности особенно важен, когда затрагиваются деньги или данные клиентов. Если миграция касается биллинга, заказов, подписок, балансов или истории аккаунтов — привлеките опытного fractional CTO или внешнего ревьюера до переключения. Свежий взгляд часто замечает неприятные вещи, которые внутренние команды уже не видят: скрытые пути записи, слабые шаги отката или план бэктфилла, который на бумаге норм, но отстаёт под реальной нагрузкой.
Хороший ревью не требует недель. Опытный человек может прочитать план миграции, посмотреть размер батчей, защиту от свежих записей, правила валидации и последовательность переключения, а затем быстро указать на слабые места.
Если хотите внешнюю помощь, Oleg Sotnikov на oleg.is работает со стартапами и малыми компаниями как fractional CTO и советник. Он может просмотреть архитектуру миграции, поток бэктфилла и риски переключения до того, как вы переведёте боевой трафик.
Часто задаваемые вопросы
Что такое бэктфилл при живой миграции?
Копирует исторические данные батчами, пока поток изменений продолжает доставлять новые вставки, обновления и удаления в целевую систему.
Держите источник единственным путём записи до переключения. Это упрощает процесс и избегает split-brain.
Как выбрать безопасные границы батчей?
Выбирайте границы, которые соответствуют работе продукта, а не только тому, что удобно в базе данных.
Диапазоны по времени хорошо подходят для старых записей. Группы арендаторов или сегменты клиентов чаще работают лучше, когда несколько крупных клиентов генерируют львиную долю трафика. Диапазоны по ID помогают, когда данные распределены равномерно.
Насколько большим должен быть каждый батч?
Сделайте каждый батч дешёвым для повторного запуска. Хороший кусок обычно завершается за несколько минут, а не за часы.
Если одна неудача заставляет тратить полдня на восстановление, батч слишком большой. Уменьшите его, чтобы повторный запуск был простым.
Как не допустить, чтобы старые данные из бэктфилла перезаписали свежие правки?
Дайте каждому изменению версию, порядковый номер или надёжное время обновления. Цель должна применять только самую новую версию, которую она видела.
Так, если бэктфилл пришлёт старую строку после того, как пришло свежее обновление, цель сохранит новое значение.
Нужно ли обрабатывать удаления в ходе миграции?
Отслеживайте удаления с самого начала с помощью tombstone-сообщений или событий удаления. Если пропустить их, целевая система может вернуть записи, которые пользователи удалили.
Обращайтесь с удалениями как с любым другим изменением: проигрывайте их в порядке и храните метаданные, чтобы возобновить после сбоя.
Какие метрики показывают, что миграция догоняет?
Следите одновременно за копируемыми строками в минуту, процентом повторных попыток, лагом и глубиной очереди.
Лаг важнее всего перед переключением. Измеряйте его и во времени, и в количестве записей, и используйте чистую пропускную способность вместо грубой скорости. Если вы копируете 180 000 строк в минуту, а пользователи создают 30 000 новых, реальный прирост — 150 000 в минуту.
Когда следует приостановить миграцию?
Приостанавливайте, когда лаг растёт, повторные попытки резко увеличиваются, валидация начинает падать или воркеры перестают прогрессировать.
Также останавливайтесь, если источник замедляется настолько, что это чувствуют пользователи. Короткая пауза дешевле, чем исправление тихих повреждений данных позже.
Достаточно ли совпадающего числа строк, чтобы доказать успешность миграции?
Нет. Совпадающие счёты строк лишь говорят, что в обеих системах одинаковое число строк.
Могут различаться важные поля: статусы, таймстемпы, права или балансы. Сравнивайте выборочные записи по полям, особенно те, которые влияют на то, что видит пользователь или какие действия он может выполнить.
Что проверить прямо перед переключением?
Сравните небольшую выборку старых записей, недавних записей и тех, что менялись несколько раз во время миграции.
Затем выполните несколько реальных записей, подтвердите, что они попадают туда, куда нужно, проверьте, что лаг остаётся низким, и ещё раз отрепетируйте откат. Если хотя бы одна выборочная запись неверна, остановитесь и найдите причину.
Когда имеет смысл просить внешнюю помощь?
Привлекайте ревьюера, когда миграция затрагивает биллинг, заказы, подписки, балансы, права доступа или другие данные, которые могут быстро навредить клиентам.
Второй взгляд часто замечает скрытые пути записи, слабую валидацию или план отката, который на бумаге выглядит хорошо, но разваливается под нагрузкой. Fractional CTO может проверить ранбук, поток бэктфилла и шаги переключения перед тем, как вы переведёте трафик в прод.


