B2B‑пайплайн обработки файлов, изолирующий плохие загрузки
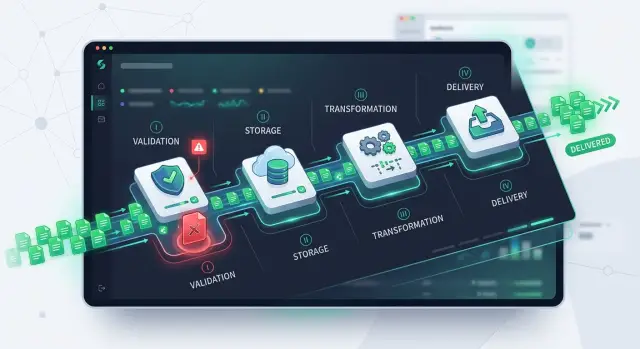
Пайплайн обработки B2B‑файлов разделяет загрузки на валидацию, хранение, трансформацию и доставку, чтобы один сломанный файл не останавливал работу всех клиентов.
Содержание
Почему один плохой файл останавливает всю загрузку
Загрузка пачкой кажется эффективной, пока один файл не сломает парсер. У CSV пропал столбец. У PDF повреждены метаданные. Какой‑то поставщик выводит даты в другом формате. Если весь батч выполняется как одна задача, эта единственная ошибка может остановить сотни корректных файлов за ней.
Чаще всего это происходит из-за дизайна пайплайна. Валидация, хранение, трансформация и доставка связываются под одним финальным статусом: успех или провал. На дашборде выглядит аккуратно, но реальные загрузки — грязнее. Одно исключение в файле 137 может заблокировать файлы 138–500, хотя с ними всё в порядке.
Поддержка страдает первой. Батч со статусом «failed» не говорит, какой именно файл вызвал проблему, какие файлы уже сохранились и дошли ли данные до следующей системы. Люди начинают копаться в логах, просить инженеров и гадать, что должен повторить клиент. Небольшая проблема с загрузкой превращается в длинную переписку с поддержкой.
Повторы всего батча усугубляют ситуацию. Система перечитывает файлы, которые уже прошли, заново запускает конверсии, которые уже сработали, и может доставить тот же результат дважды, если дедупликация слабая. Одна ошибка парсера создаёт давление на очередь, дубли записей и ещё одну волну тикетов.
Принцип исправления прост: перестаньте считать батч единицей работы. Считайте единицей работы файл. В заблокированном батче один плохой файл может остановить 499 хороших. В потоке «файл за файлом» 499 продолжают двигаться, пока один ждёт ревью. Поддержка тоже получает реальный ответ: точный файл, точный шаг и точная причина провала.
Здоровый B2B‑пайплайн изолирует ошибки рано. Каждый файл должен иметь собственный статус, путь повтора и аудит‑трейл. Когда одна загрузка идёт не так, остальная работа должна продолжаться.
Что должна делать каждая стадия
Пайплайн становится гораздо более надёжным, когда у каждой стадии одна задача и один однозначный результат. Такое разделение не даёт мелким проблемам распространяться. Если валидация падает, хранение не должно изменяться. Если доставка провалилась, не следует запускать трансформацию заново, если данные не изменились.
Валидация — это ворота. Она проверяет, можно ли файл вообще пустить в систему. Обычно это тип, размер, схема, обязательные поля и несколько базовых правил по содержимому. Если в CSV обязаны быть номер счета, дата и сумма, валидация должна сразу поймать отсутствие столбца. Эта стадия должна быть быстрой и строгой.
Хранение сохраняет оригинал до начала тяжёлой работы. Сохраняйте «сырую» загрузку точно такой, какой она пришла, вместе с метаданными: источник, чек‑сумма и время загрузки. Это даёт команде чистую точку восстановления. Когда следующая стадия упадёт, у вас всё ещё будет исходный файл и можно будет повторить обработку без запроса к клиенту прислать файл снова.
Трансформация — здесь происходит приведение к порядку. Она превращает сырой вход в внутренний формат вашего продукта: маппинг столбцов, нормализация дат, исправление плохих значений, разделение позиций и превращение текста в структурированные записи. Держите эту логику здесь, а не в валидации и не в доставке. Чёткие границы значительно упрощают отладку.
Доставка отправляет результат дальше — другой сервис, экспорт для клиента или учётная система. Доставка должна фиксировать, прошёл ли хенд‑офф, и поддерживать безопасные повторы. Если целевая система таймаутится, команда должна повторить только шаг доставки, а не перепроцессить весь файл.
Когда каждая стадия завершается понятным статусом, команды могут повторять один файл, одну стадию и одну ошибку за раз. Это и держит загрузки в движении, даже если некоторые файлы плохи.
Как разделить поток пошагово
Пайплайн работает лучше, когда каждый файл идёт своим путём. Если один файл падает, остальные должны пройти валидацию, хранение, обработку и доставку без ожидания.
Разделение начинается в момент прихода загрузки. Не держите весь запрос открытым, пока инспектируете, конвертируете и экспортируете файлы. Примите файл, присвойте ему ID сразу и быстро верните управление пользователю.
-
Принять файл и пометить его.
Примите загрузку, создайте уникальный ID файла и запишите, кто и когда его прислал. Даже если последующие этапы упадут, у вас появится стабильная запись по этому файлу.
-
Быстрые проверки прежде, чем делать тяжёлую работу.
Сразу проверьте размер, тип, расширение и базовую структуру. Если у CSV нет заголовка или PDF пустой — отклоните его на ранней стадии. Это экономит вычисления и даёт пользователю понятную ошибку, пока загрузка свежая.
-
Сохраните сырой файл и запишите статус.
Сохраните оригинал точно как пришёл. Затем создайте или обновите статус:
received,rejectedилиready for processing. Поддержке часто нужен этот сырой копия позже, чтобы воспроизвести проблему. -
Отправьте работу по трансформации в очередь.
Парсинг, маппинг полей, антивирусная проверка, OCR и конвертация форматов могут занимать время. Поместите эту работу в очередь, а не выполняйте её в теле запроса загрузки. Пользователь получает быстрый ответ, и один медленный файл не задерживает остальных.
-
Доставьте результат и закройте только этот файл.
По завершении обработки запишите результат в целевое место и пометьте только этот файл как завершённый. Если доставка упала, оставьте честный статус, например
processed, но неdelivered. Это делает повторы значительно безопаснее.
Не нужен громоздкий статус‑модуль. Короткой дорожки вроде received, rejected, stored, queued, processing, delivered и failed обычно достаточно. Важна ясность.
Такая структура также успокаивает поддержку. Когда клиент спрашивает «Что случилось с моей загрузкой?», команда может ответить по конкретному ID файла, а не копаться в смешанном батче и гадать, где всё сломалось.
Отслеживайте каждый файл отдельно
Батч — это просто контейнер. Система должна обращаться с каждым файлом как с отдельной задачей и собственной записью. Это одно решение значительно облегчает эксплуатацию, потому что одна сломанная загрузка больше не скрывает 199 файлов, которые работали.
Давайте каждому файлу стабильный ID сразу при поступлении. Храните текущий статус, последнее сообщение об ошибке, счётчик повторов и временные метки для событий: uploaded, validated, transformed и delivered. Когда в поддержку приходит тикет, им не нужно угадывать, где файл остановился.
Поиск важен не меньше статуса. Сотрудники должны уметь найти файл по клиенту, по ID батча или по ID файла за несколько секунд. Если поиск возможен только по батчу, один проваленный документ превращается в меденную ручную охоту.
Храните оригинал отдельно от последующих артефактов. Сохраните сырой аплоад в одном месте, затем запишите трансформированный вывод, разобранные данные и копии для доставки в других местах. Это предотвращает случайные перезаписи и делает повторную обработку безопасной. Если сегодня в парсере баг, завтра можно исправить код и снова запустить сырой файл.
Обычно достаточно простой модели статусов: queued для файлов, ожидающих следующего шага; running для файлов, проходящих стадию; done для тех, что дошли до конца; failed для тех, кто требует ревью или повтора.
Сверху записей на уровне файла показывайте простые счёты для всего батча. Люди сначала хотят быстрый ответ: сколько done, failed, running и waiting. Затем они могут открыть упавшие элементы и посмотреть ошибку.
Это особенно полезно для маленьких команд. Один оператор быстро заметит закономерность — например, десять ошибок от одного клиента после смены шаблона — вместо того, чтобы читать логи строка за строкой. Хорошее отслеживание не делает пайплайн модным. Оно делает его спокойным при сбоях.
Простой пример с продажными счетами
В конце месяца ваш продукт получает CSV‑счета от 60 поставщиков. Финансы хотят получить числа в едином формате перед отправкой в accounts payable. Здесь файл‑пайплайн либо спасает дело, либо создаёт поддержку.
Каждая загрузка от поставщика должна идти своим путём. Система даёт каждому файлу собственную запись, сохраняет сырой аплоад и сначала проверяет базовые вещи. Есть ли обязательные столбцы? Парсятся ли даты? Числовые ли итоги? Совпадает ли ID поставщика с аккаунтом, который прислал файл?
Представьте: 59 файлов проходят, а один нет. Поставщик 18 присылает CSV с amt вместо amount, а столбец due_date отсутствует. Если месячный батч выполняется как одна задача, финансы ждут всех из‑за одного плохого файла. Это плохая торговля.
Лучший поток разбивает работу на небольшие стадии. После валидации каждый хороший файл попадает в хранилище, затем в трансформацию, где система мапит столбцы поставщика в вашу внутреннюю схему. Оттуда чистый вывод уходит в доставку — экспорт для финансов, API‑передачу или файл для просмотра в дашборде.
Плохой CSV останавливается на валидации. Система хранит сырой файл для поддержки и помечает загрузку как failed с простым сообщением вроде Missing column: due_date. Только затронутый клиент получает уведомление. Остальные не слышат ничего, потому что с их файлами всё в порядке.
Финансы видят 59 завершённых файлов и 1 заблокированный. Они могут сразу работать с готовым набором, не дожидаясь идеального батча. Когда поставщик 18 исправит шаблон и загрузит снова, только этот файл зайдёт в пайплайн. Команда не перерабатывает остальные 59 файлов и не теряет день на выяснения.
Такое простое разделение меняет настроение всего процесса. Поддержка решает одну проблему, клиент понимает, что исправить, а финансы продолжают работу.
Ошибки, которые засоряют пайплайн
Большинство забитых пайплайнов начинается с одного выбора: пытаться сделать всё в момент загрузки. Если валидация, парсинг, хранение и доставка выполняются в одном цикле, один медленный парсер или одна сломанная строка могут заблокировать всю задачу. Пайплайн должен продолжать работать, даже когда один файл падает.
Ещё одна частая ошибка — удалять оригинал сразу после парсинга. Это выглядит аккуратно, но сильно усложняет поддержку. Когда клиент спрашивает, почему изменились суммы или куда пропала запись, команде нужен сырой файл, чтобы посмотреть, что действительно пришло.
Обобщённые сообщения об ошибках наносят больше вреда, чем многие думают. Upload failed ничего не говорит клиенту и почти ничего не говорит вашей команде. Простые сообщения вроде row 48 has an invalid date или required column invoice_id is missing гораздо полезнее.
Логика повторов часто создаёт вторую проблему. Если в батче из 500 файлов есть одна битая запись и система повторяет весь батч, вы тратите вычислительные ресурсы, создаёте задержки и иногда отправляете один и тот же результат дважды. Команды замечают это обычно после жалоб на дубли.
Пропуск проверки дубликатов — ещё один тихий провал. Поставщики часто повторно отправляют тот же файл, меняя имя. Если вы не сравниваете контрольные суммы, source IDs или маркеры батча, пайплайн создаёт дубликаты счетов, экспортов или уведомлений.
Несколько изменений снимают большую часть трений:
- Разделите загрузку, валидацию, парсинг и доставку на отдельные задачи.
- Храните оригинальный файл и сыровые метаданные пока действует окно ретенции.
- Повторяйте только упавший файл или группу упавших записей.
- Показывайте точные ошибки пользователям и сохраняйте полные логи для команды.
- Добавьте детекцию дубликатов перед трансформацией и перед финальной доставкой.
Риск легко представить. Поставщик шлёт 20 файлов со счётами, и один файл имеет сломанный десятичный формат. Если приложение обрабатывает все 20 в одном запросе, весь батч встанет. Если каждый файл имеет свой статус и путь повтора, 19 файлов успеют вовремя, а один будет ждать исправления.
Эта разница не косметическая. Она решает, останется ли операция спокойной или команда проведёт полдня, распутывая одну легко избегаемую проблему загрузки.
Быстрые проверки перед релизом
Пайплайн может выглядеть надёжным в стейджинге и всё равно упасть в проде из‑за нескольких пробелов. Самый надёжный тест прост: отправьте смешанный батч файлов, намеренно испортите один и смотрите, что произойдёт с остальными.
Если один плохой аплоад ставит на паузу весь батч, дизайн всё ещё нужно доработать. Надёжный поток обращается с каждым файлом как с отдельной задачей, с собственным статусом, путём повтора и записью об ошибке.
Перед релизом убедитесь, что вы можете сделать пять вещей, не трогая весь батч: повторить один упавший файл; показать в админке или вью поддержки точную упавшую стадию; сохранить оригинальную загрузку для последующей проверки; отклонять слишком большие или неверного формата файлы до тяжёлой обработки; и алертить по задачам, которые слишком долго сидят на одной стадии.
Тест повтора важнее, чем кажется. Если поддержке придётся перезапускать весь батч, чтобы починить один сломанный PDF или CSV, через две недели люди начнут собирать ручные обходы. Это обычно приводит к дубликатам, запутанным клиентам и долгим перепискам с поддержкой.
Видимость тоже важна. Команда должна видеть, упала ли загрузка на валидации, застряла в очереди трансформации или закончила обработку, но не дошла до доставки. Без этого вида каждое инцидент начинается одинаково: с гаданий.
На что смотреть после запуска
Когда реальные клиенты начинают присылать файлы, слабые места проявляются быстро. Пайплайн может выглядеть нормально в тестах и всё равно забиться в понедельник утром, когда десять клиентов загрузят разные форматы одновременно.
Отслеживайте, сколько времени каждый файл проводит в валидации, хранении, трансформации и доставке. Не останавливайтесь на общем времени обработки. Файл может дойти до клиента за шесть минут и при этом потратить пять из них в ожидании на одной стадии.
Группируйте ошибки так, чтобы это помогало команде действовать: по типу файла, по клиенту и по правилу, которое отклонило файл. Если XML от одного клиента постоянно падает на одном и том же поле даты, вы сразу знаете, куда смотреть.
Средние значения скрывают пробки. Следите за глубиной очередей в часы пик и сравнивайте с временем обработки. Если очередь растёт каждый день в 9:00 и чистится к полудню, это не случайность — это проблема ёмкости.
Повторы требуют собственной метрики. Когда вы меняете правила валидации или код трансформации, измеряйте, как часто повтор срабатывает со второго раза. Если успешность повторов не растёт, изменение не решило реальную проблему.
Хранилище тоже заслуживает внимания. Отслеживайте, сколько места занимают сырые загрузки, трансформированные файлы, логи и временные рабочие файлы каждую неделю. Многие команды смотрят только на основное ведро и забывают о временных файлах, которые создаются во время конвертации. Эти файлы накапливаются, увеличивают затраты и замедляют очистку позже.
Правила очистки нужно рассматривать как продуктовые решения, а не фоновые поручения. Решите, как долго хранить упавшие загрузки, артефакты повторов и доставленные файлы. Храните достаточно истории для отладки клиентских инцидентов, а затем удаляйте остальное по расписанию.
Когда вы еженедельно смотрите эти числа, паттерны появляются рано. Это даёт команде время починить парсер, добавить рабочего или ужесточить правило очистки до того, как маленькая ошибка превратится в бэклог.
Следующие шаги для вашей команды
Большинству команд не нужен полный рефакторинг сначала. Лучше найти стадию, которая генерирует больше всего тикетов поддержки, и начать с неё. Если пользователи постоянно спрашивают, почему загрузка пропала, почините рабочий процесс валидации и трекинг статусов до того, как лезть в парсер. Если файлы доходят до хранилища, но не попадают туда, куда нужно, начните с доставки.
Нарисуйте текущий путь загрузки на одной странице. Покажите, где файл входит, где происходят проверки типа и схемы, где хранится сырой файл, где фоновые задачи подхватывают его и как пользователь видит успех или провал. Эта быстрая карта часто вскрывает реальную проблему. Одна ошибка парсера может блокировать весь батч потому, что несколько стадий всё ещё разделяют одну запись задачи.
Практический порядок прост. Создайте уникальный ID для каждого файла сразу при старте загрузки. Сохраняйте статус на уровне файла, а не только для всего батча. Разделите результаты валидации и трансформации. Переведите доставку в отдельную очередь, чтобы один повтор не морозил всё остальное.
Статус на уровне файла — это обычно первый выигрыш, который стоит выпустить. Не нужно переписывать все парсеры, чтобы добавить его. Как только каждый файл сможет двигаться по пайплайну независимо, поддержка ответит клиентам быстрее, продукт увидит, где останавливается работа, а инженеры смогут поэтапно заменять слабые места.
Держите первую версию узкой. Выберите один болезненный путь загрузки, сделайте видимыми ошибки и остановите плохие файлы от блокировки здоровых. Это уже может существенно сократить ежедневный шум.
Если вашей команде нужен внешний обзор, Oleg Sotnikov at oleg.is может оценить поток как Fractional CTO или советник. Его опыт охватывает архитектуру продуктовых стартапов, production‑инфраструктуру и AI‑ориентированную разработку — это полезно, когда проблема не только в парсинге файлов, но и в решении, как вообще распараллелить систему.
Часто задаваемые вопросы
Почему один плохой файл блокирует всю загрузку?
Обычно причина — одна общая задача для всего батча. Когда валидация, парсинг, сохранение и доставка выполняются под одним статусом батча, одно исключение переводит весь батч в failed. Если дать каждому файлу свою задачу, остальные продолжат двигаться.
Стоит ли обрабатывать весь батч или каждый файл по отдельности?
Обрабатывайте каждый файл как отдельную единицу работы. Батч оставьте как контейнер для отчётов — количества done, failed и running. Такое разделение позволяет поддержке и операционным командам работать с одним файлом, не трогая остальные.
Какие статусы нужны для каждого файла?
Начните с простого и понятного набора статусов. Статусы вроде received, rejected, stored, queued, processing, delivered и failed подойдут большинству команд. Главное — чтобы каждая стадия записывала честный результат.
Действительно ли нужно хранить сырой файл?
Да. Сохраняйте оригинальный файл точно таким, каким он пришёл, вместе с метаданными — источником, контрольной суммой и временем загрузки. Это даёт чистую точку восстановления и помогает поддержке проверить, что на самом деле прислал клиент.
Где должна заканчиваться валидация и начинаться трансформация?
Валидация отвечает на один вопрос: можно ли вообще принять этот файл в систему. Трансформация — это место, где данные чистят и мапят в внутренний формат. Если смешивать эти роли, отладка замедлится, а повторы станут грязными.
Как должны работать повторы в таком пайплайне?
Повторяйте только тот файл и ту ступень, которая упала. Если доставка таймаутнулась, повторите шаг доставки, а не перепарсите файл. Повторы всего батча тратят ресурсы и увеличивают риск дубликатов.
Как избежать дубликатов, когда поставщики повторно отправляют файлы?
Проверяйте дубликаты до тяжёлой обработки и снова перед финальной доставкой. Сравнивайте контрольные суммы, ID источника и любые пометки батча, которым вы доверяете. Поставщики часто шлют один и тот же контент с новым именем файла.
Какое сообщение об ошибке должен увидеть пользователь?
Показывайте точный файл, точную стадию и простое понятное сообщение об ошибке. Например: Missing column: due_date или row 48 has an invalid date. Такие ошибки дают клиенту инструкцию по исправлению и дают поддержке старт для расследования. "Upload failed" никому не помогает.
Что нужно протестировать перед выпуском?
Отправьте смешанный батч, намеренно испортите один файл и посмотрите, что произойдёт с остальными. Вы должны уметь повторить один упавший файл, увидеть, на какой стадии он остановился, сохранить сырой файл и отбраковывать большие или неверные форматы до тяжёлой обработки. Если один плохой файл ставит на паузу всё — ещё не готово к релизу.
Что нужно мониторить после релиза?
Следите за временем на каждой стадии, глубиной очередей в часы пик, причинами ошибок по клиентам и типам файлов, успешностью повторных попыток и ростом хранилища. Эти метрики покажут, где проблема: парсер, мощность или уборка артефактов.


