PHP-пакеты для поиска по каталогам, справочным центрам и инструментам
PHP-пакеты для поиска помогают перейти от простого SQL к полноценным поисковым движкам. Узнайте, что подходит для каталогов товаров, справочных центров и внутренних инструментов.
Содержание
Почему поиск кажется простым, пока не сломается
Поиск часто выглядит готовым уже после первой демонстрации. Вы вводите точное название товара, заголовок статьи или email пользователя — и результат появляется. Первую неделю это радует.
Но реальные пользователи ищут не так. Они вводят названия, которые помнят лишь наполовину, старые номера деталей, опечатки, короткие фразы и лишние слова, важные для них, но не существующие как аккуратные поля в ваших данных. Покупатель может искать "красные кроссовки до 100". Пользователь поддержки может написать "не могу войти после сброса". Сотрудник может ввести ID тикета, имя клиента или просто "Jane из отдела продаж".
Поиск по каталогу товаров ломается первым, потому что сопоставление текста — лишь часть задачи. Людям нужны фильтры, ограничения по цене, размер, цвет, наличие на складе, бренд и иногда синонимы. Если ваш поиск находит все товары со словом "красный", но игнорирует размер 8 и бюджет, он кажется неправильным, даже если база данных технически вернула совпадения.
У справочного центра другая проблема. Люди не хотят длинный список. Им нужен самый понятный ответ как можно быстрее. Если лучшая статья лежит ниже расплывчатых заметок о релизах или старых публикаций с теми же словами, пользователи решают, что в справке ответа нет. После этого они создают обращение в поддержку из-за вещи, которую могли бы решить за 30 секунд.
Внутренние инструменты добавляют ещё один слой сложности. Сотрудники ищут по ID, именам, email, названиям компаний, номерам счетов и странным сокращениям, понятным только внутри бизнеса. Плюс важны права доступа. Правильный результат для одного сотрудника может быть тем, что другому нельзя видеть ни в коем случае.
Именно в этот момент команды обычно начинают смотреть на PHP-пакеты для поиска, а не только на обычные запросы. Поле поиска не стало сложнее из-за того, что изменились пользователи. Оно стало сложнее, потому что настоящая работа наконец проявилась.
Когда поиск не работает, люди делают одно и то же:
- пробуют один и тот же запрос тремя разными способами
- включают больше фильтров, чем хотели
- пишут в поддержку или спрашивают коллегу
- считают, что данных просто нет
Вот почему поиск сначала кажется простым. Ранние тесты используют чистые данные. Реальное использование — это хаос, спешка и контекст.
Что люди ищут в каждом инструменте
Люди ищут по-разному в каталоге, справочном центре и внутреннем админ-экране. Если считать это одной задачей, результаты быстро становятся шумными.
Покупатель обычно вводит короткие фрагменты. Он ищет название товара, часть названия, SKU, бренд или размер. "Air Zoom 42", "SKU 18452" или "black hoodie xl" — нормальные запросы для каталога. Такие поиски должны ставить прямые совпадения наверх. Если человек вводит точный SKU, а поиск сначала показывает широкие страницы категорий, он решит, что магазин сломан.
Посетители справочного центра ведут себя иначе. Они часто пишут полные вопросы обычным языком, потому что не знают название статьи. Они спрашивают что-то вроде "как изменить адрес доставки" или "почему не прошла оплата". Хороший поиск по справке должен понимать длинные фразы и близкие формулировки, а не только точные совпадения заголовков. Статья под названием "Обновите платёжные данные" всё равно должна появляться на запрос "сменить карту".
Поиск для сотрудников строже и менее снисходителен. Операторы поддержки, команды операций и отдел продаж обычно ищут идентификаторы: ID клиента, номер заказа, код счёта, email или статус вроде "возврат оформлен" или "в ожидании". Часто они ищут, пока клиент ждёт. Один понятный результат лучше десяти умных догадок.
Для каждого экрана нужны свои правила ранжирования. В каталоге точный SKU и точное название товара должны быть выше расплывчатых совпадений в описаниях. В справочном центре совпадения по вопросам и заголовки статей должны быть выше набора ключевых слов в основном тексте. Во внутреннем инструменте первыми должны идти точные ID, email и свежие записи.
Даже при базовом поиске по базе данных на PHP полезно думать об этом как о трёх разных задачах поиска. Поле поиска может выглядеть одинаково на каждом экране. Намерение за ним — нет.
Начните с поиска в базе данных
Большинству команд стоит начать с той базы данных, которая у них уже есть. Если в каталоге товаров всего несколько тысяч строк или в справочном центре несколько сотен статей, SQL обычно справляется без лишнего сервиса, который нужно разворачивать, настраивать и оплачивать.
Используйте LIKE для небольших таблиц и точных полей, по которым люди ищут намеренно. Название товара, SKU, заголовок статьи, адрес email и ID тикета — хорошие примеры. Если пользователи вводят короткие и ясные запросы, простой запрос часто кажется достаточно быстрым и точным.
Когда этого начинает не хватать, попробуйте полнотекстовый индекс, встроенный в MySQL или PostgreSQL, прежде чем добавлять что-то новое. Встроенный полнотекстовый поиск может ранжировать результаты лучше, чем набор проверок через LIKE, и при этом не усложняет инфраструктуру. Прежде чем пробовать новые PHP-пакеты для поиска, убедитесь, что ваш поиск по базе данных на PHP хорошо справляется с простой работой.
Держите список индексируемых колонок компактным. Это важнее, чем многие команды ожидают. Ищите по заголовку, короткому описанию, тегам, SKU и, возможно, по основному тексту статьи. Пропускайте служебные заметки, остатки импорта, длинные JSON-поля и другой текст, который никто не ожидает искать. Широкий поиск сначала кажется полезным, а потом наполняет результаты мусором.
Реальные журналы запросов показывают, когда поиск по каталогу товаров начинает ломаться. Отслеживайте, что люди вводили, какой результат открыли и какие запросы ничего не вернули. Через несколько дней вы увидите закономерности: люди ищут по номерам деталей, которые вы не учли, используют прозвища вместо названий товаров или вводят два слова, которые никогда не встречаются в одном поле.
В этом и смысл простого старта. Вы узнаёте, где поиск в справочном центре или во внутренних инструментах реально не справляется, а не гадаете. Для небольшой PHP-команды дольше держать поиск внутри MySQL или PostgreSQL часто дешевле и проще в сопровождении.
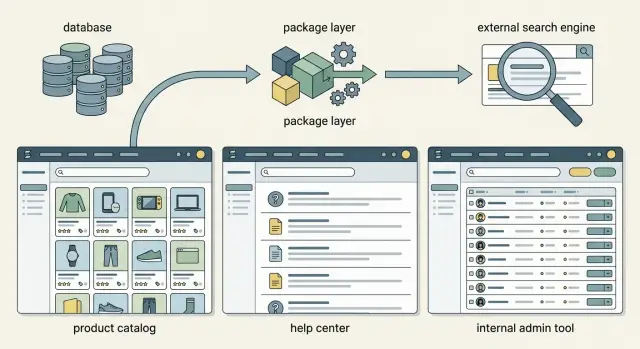
Что добавляет слой пакета
Слой пакета даёт приложению одно место, куда можно обращаться за результатами поиска, независимо от того, где лежат данные. Контроллеры остаются компактными, шаблоны только отображают результаты, а правила ранжирования живут в коде, который легко тестировать.
Это важнее, чем кажется. Правила поиска быстро расползаются, если каждый экран строит свой запрос. Один контроллер ищет заголовки через LIKE, другой добавляет теги, а третий сортирует по дате, потому что никто не знал о первых двух.
Со слоем пакета вы определяете поиск один раз и переиспользуете его. Каталог товаров, справочный центр и внутренний админ-инструмент могут использовать один и тот же подход, даже если каждый ранжирует результаты немного по-разному.
Например, в каталоге товарам можно давать больший вес названию и SKU, чем полному описанию. В справочном центре можно поднимать заголовки статей и подзаголовки выше основного текста. Во внутреннем инструменте сначала можно ставить точные ID, затем имена, затем заметки.
Хороший слой пакета обычно даёт несколько практичных преимуществ:
- один интерфейс поиска для разных моделей или таблиц
- одно место, где можно настраивать веса для заголовков, тегов и описаний
- одно место, где можно добавлять фильтры вроде статуса, категории или команды
- меньше повторяющегося кода запросов в приложении
- более простой переход на другой backend в будущем
Последний пункт экономит реальное время. Многие команды начинают с поиска по базе данных на PHP, потому что это дёшево и быстро вывести в продакшен. Позже им нужны устойчивость к опечаткам, лучшее ранжирование или более быстрые результаты на больших объёмах данных. Если приложение обращается к слою пакета, а не к сырому SQL из десяти разных контроллеров, переход на Meilisearch, Elasticsearch или другой движок становится гораздо менее болезненным.
Это не значит, что внешний движок нужен в первый же день. Это значит, что приложению не должно быть слишком важно, работает ли поиск сегодня на MySQL, а через шесть месяцев — на отдельном движке.
Если вы делаете софт небольшой командой, такое разделение окупается быстро. Вы тратите меньше времени на распутывание логики поиска и больше — на настройку результатов, которые люди действительно видят.
Как выбрать первую конфигурацию
Многие команды начинают с сравнения PHP-пакетов для поиска, но выбор становится проще, если сначала смотреть не на пакет, а на экраны. Каталог товаров, справочный центр и внутренний админ-инструмент все говорят "поиск", но ожидают разного поведения.
Запишите все экраны, где нужен поиск. Сформулируйте просто: список каталога, поиск по статьям, поиск заказов, справочник пользователей. Если у экрана другая цель, считайте его отдельной задачей поиска.
Затем перечислите поля, по которым должен искать каждый экран. Каталогу могут понадобиться название товара, SKU, бренд и категория. Поиск по справочному центру — заголовок, основной текст и теги. Внутреннему инструменту часто нужны точные совпадения, например email, ID заказа или название компании.
Помогает простая таблица оценки:
- Какому экрану нужны частичные совпадения, например "shoe" должно находить "running shoes"?
- Какому экрану нужны точные совпадения, например номер счёта?
- Какому экрану нужна сортировка по релевантности, а не по дате или цене?
- Какому экрану нужны фильтры вроде бренда, статуса или языка?
- Какому экрану нужна устойчивость к опечаткам, а какому — нет?
После этого соберите 20 реальных запросов. Возьмите их из обращений в поддержку, журналов поиска, звонков продаж или сообщений от вашей команды. Реальные фразы лучше придуманных примеров каждый раз, потому что пользователи вводят неаккуратные вещи вроде "возврат по ЕС" или "nik air размер 10".
Проверьте эти запросы на самой простой конфигурации, которую вы можете быстро собрать. Для многих небольших PHP-приложений это значит поиск по базе данных на PHP с полнотекстовым SQL или даже с базовыми индексированными запросами, плюс тонкий слой пакета только если он упрощает ранжирование, фильтры или сборку запросов. Если такая конфигурация проходит большую часть проверок, на этом и остановитесь.
Оценивайте результат по трём вещам: скорость, качество результатов и сопровождение. Если страницы загружаются быстро, пользователь находит нужный объект в первых результатах, а команде не нужно постоянно обслуживать ещё один сервис, вы выбрали удачно.
Если какой-то экран продолжает ломаться, а другие работают нормально, не переводите пока всё приложение на внешний движок. Обновите только проблемную часть. Каталогу с тысячами товаров поисковая мощность может понадобиться гораздо раньше, чем небольшому справочному центру.
Простой пример с тремя экранами поиска
Представьте небольшое PHP-приложение с тремя полями поиска. Одно используют клиенты, чтобы находить товары. Второе — читатели, чтобы находить ответы. Третье — сотрудники, чтобы быстро искать заказы. Данные лежат в одной базе, но каждому экрану нужны свои правила совпадений.
Для каталога люди редко вводят аккуратные названия товаров. Они вставляют часть SKU, пишут бренд с ошибкой или ищут по категории. Если человек вводит "nike running" или "1842", поиск должен проверять название, SKU, бренд и категорию, а затем ставить точные совпадения по SKU выше расплывчатых текстовых совпадений. Слой пакета держит эти правила в одном месте вместо того, чтобы разбрасывать SQL по контроллерам.
Справочному центру нужен другой стиль. Люди ищут вопросами, а не отточенными заголовками. Кто-то может ввести "сбросить пароль", даже если статья называется "Измените данные входа". В таком случае поиск должен смотреть на заголовки статей и сохранённые вопросные фразы, а затем давать фразовым совпадениям больший вес, чем широким текстовым совпадениям.
Админ-инструмент строже. Сотрудники ищут ID заказов, email и названия компаний, часто пока клиент ждёт. Если они вводят "ORD-10428", им нужен этот заказ первым, а не размытый список, где он, возможно, есть. Поиск по email должен поддерживать частичные совпадения, а поиск по названию компании — оставаться гибким, потому что люди часто помнят только одно слово.
Один слой пакета может покрыть все три экрана, если для каждого поиска задать свои правила:
- Каталог использует нечёткое совпадение для названий и брендов, но сильно повышает вес SKU.
- Справочный центр отдаёт приоритет заголовкам статей и частым формулировкам вопросов.
- Админ-инструмент сначала проверяет точные ID, а затем переходит к частичным совпадениям по email или компании.
Именно здесь PHP-пакеты для поиска имеют смысл ещё до перехода на внешний движок. Вы сохраняете один поисковый сервис, один механизм индексации и одно место для настройки ранжирования. Код остаётся чище, а каждый экран работает так, как нужно для его задачи, а не как будто один и тот же поиск просто скопировали три раза.
Ошибки, которые тратят время
Команды теряют время на поиске, когда сначала решают не ту задачу. Они покупают больше поиска, чем нужно, индексируют слишком много данных и только потом понимают, что именно люди вводили.
Одна частая ошибка — платить за внешний движок до того, как вы собрали реальные примеры запросов. Журналы поиска показывают разницу между ожиданиями команды и тем, что делают пользователи. В каталоге товаров люди часто ищут по цвету, размеру или фрагменту SKU. В справочном центре они обычно вводят короткие фразы проблемы вроде "сбросить пароль" или "счёт не прошёл". Без этих примеров даже хорошие PHP-пакеты для поиска — это в основном догадки.
Ещё одна ошибка — индексировать каждый столбец, потому что так спокойнее. Обычно это ухудшает ранжирование, а не улучшает его. Если поиск по каталогу сопоставляет названия товаров, внутренние заметки, старые ярлыки поставщиков и скрытые метаданные с одинаковым весом, в результатах начинает доминировать шум. Начинайте с тех полей, по которым пользователи действительно собираются искать. Добавляйте остальное только тогда, когда журналы показывают явный промах.
Команды также тратят время, когда смешивают товары и статьи справки на одной странице результатов. У этих типов контента разные правила ранжирования и разные фильтры. Тот, кто ищет "возврат" в магазине, может сначала хотеть статью о политике возврата, а тот, кто ищет "USB-C hub", явно хочет товары. Если свалить всё в один список, не нравится ни один вариант.
Опечатки, формы множественного числа и сокращения слишком долго игнорируют. Это быстро вредит. Люди пишут "iphon", "qty", "auth", существительные в единственном и множественном числе и названия моделей, которые помнят лишь наполовину. Если поиск по базе данных на PHP работает только с точными совпадениями, пользователям кажется, что поиск сломан. Проверяйте конфигурацию на грязных, коротких, реальных запросах, прежде чем настраивать что-либо ещё.
У инструментов только для сотрудников есть ещё одна ловушка: ограничения доступа. Поиск должен каждый раз учитывать права. Оператор поддержки может искать по номеру заказа, но это не должно открывать финансовые заметки или записи HR. Это важнее релевантности. Быстрый результат, который показывает не те данные, — серьёзный сбой.
Если нужен один простой принцип, держите поиск узким, пока поведение пользователей не докажет, что нужно больше. Реальные запросы каждый раз лучше предположений.
Когда внешний движок действительно окупается
Внешний поисковый движок имеет смысл тогда, когда поиск начинает ограничивать продукт, а не просто раздражать команду. До этого момента поиск по базе данных на PHP обычно дешевле, проще и удобнее в сопровождении.
Масштаб часто становится первым чётким сигналом. Каталогу с 5 000 строк редко нужно что-то большее, чем хорошие индексы и аккуратные запросы. Каталог с 200 000 товаров, частыми обновлениями и несколькими полями поиска может уже загонять SQL в медленные проходы по таблицам, особенно когда пользователи одновременно применяют текстовый поиск, категорию, цену, наличие и бренд.
Ожидания пользователей растут ещё быстрее, чем объём данных. Люди ждут устойчивости к опечаткам, частичных совпадений и подсказок, которые появляются сразу. Если кто-то вводит "iphnoe charger" или помнит только половину названия статьи справки, обычный SQL начинает казаться слишком жёстким.
Ещё одна точка, где всё ломается, — фасетные счётчики. Базы данных хорошо фильтруют записи, но считать совпадения по множеству фильтров одновременно дорого. Если на одном экране поиска нужны живые счётчики для размеров, цветов, тегов, регионов и статусов, внешний движок часто делает эту работу с меньшими потерями.
На решение влияет и ранжирование. Простые текстовые совпадения — это легко. Настоящее ранжирование — нет. Как только вы хотите упорядочить результаты по смеси текстовой релевантности, популярности, наличия на складе, свежести, качества статьи поддержки или внутренних прав доступа, вы строите логику поиска, для которой специализированный движок и предназначен.
На переход может повлиять и поддержка языков. Английского одного обычно достаточно. Но если добавить немецкие сложные слова, испанские формы слов или смешанный контент справки, качество поиска падает, если движок не понимает стемминг, токенизацию и языковой анализ.
Стоимость — это не только деньги. Появляется ещё один сервис, задачи индексации, мониторинг и настройка релевантности. Поэтому многим командам стоит подождать.
Переходите, когда несколько признаков совпадают одновременно:
- медленные запросы продолжают возвращаться даже после обычной оптимизации SQL
- качество поиска влияет на продажи или на то, как легко найти статью
- фильтры и фасетные счётчики становятся тяжёлыми
- ранжирование требует бизнес-правил, а не только текстовых совпадений
- вы поддерживаете несколько языков с реальными ожиданиями к поиску
Если поиск влияет на продажи, нагрузку на поддержку или ежедневную работу сотрудников, дополнительный сервис может быстро окупиться. Если поиск всё ещё маленькая функция, оставьте его в базе данных и потратьте время на что-то другое.
Быстрые проверки перед тем, как принять решение
Система поиска выглядит дешёвой, пока вы не выбрали не ту. Десять минут проверки сейчас могут сэкономить недели переделок, особенно если вы выбираете между обычным SQL, слоем пакета и отдельным поисковым движком.
Начните с самого поля поиска. В каталоге товаров многие ищут по SKU, номеру детали или точному названию товара. В справочном центре обычно вводят расплывчатые фразы вроде "возврат за повреждённый товар". Во внутренних инструментах часто есть и то и другое. Если пользователи вставляют ID в половине случаев, быстрое точное совпадение важнее, чем сложные трюки с нечётким текстом.
Не менее важна частота изменений контента. Справочный центр с несколькими обновлениями в неделю — это одно. Каталог, где цены, остатки и названия меняются весь день, — совсем другое. Если данные меняются часто, нужно понимать, насколько быстро поиск должен отражать эти изменения. Задержка индекса терпима в документации. В экранах с остатками — это уже проблема.
Количество записей даёт ещё один понятный сигнал. Несколько тысяч строк редко оправдывают сложность. Десятки тысяч всё ещё хорошо работают с поиском по базе данных на PHP, если вы индексируете нужные столбцы и не усложняете запросы без причины. Когда на каждом экране уже сотни тысяч записей или пользователи ждут устойчивости к опечаткам и ранжированных результатов, ограничения становятся заметны быстрее.
Фильтры заслуживают отдельной проверки. Многие команды думают, что им нужен умный текстовый поиск, но пользователям на самом деле важнее бренд, статус, категория, дата, местоположение или цена. Если фильтры делают большую часть работы, реляционная база данных часто выигрывает, потому что уже хорошо справляется со структурированными запросами.
Ещё одна скучная, но очень важная проверка: может ли ваша команда обслуживать ещё один сервис? Внешние поисковые движки добавляют настройку, мониторинг, резервное копирование, расход памяти и задачи синхронизации. PHP-пакеты для поиска могут смягчить этот переход, но не убирают его. Если команда небольшая, простое обычно лучше, чем хитрое.
Хороший первый выбор соответствует тому, как поиск работает сейчас, а не тому, каким вы представляете его через полгода.
Следующие шаги для небольшой PHP-команды
Маленькие команды выигрывают, когда сначала держат поиск узким. Выберите одну страницу, запустите её и посмотрите, как люди реально ею пользуются. Одна поисковая страница в каталоге товаров или справочном центре научит вас большему, чем недели догадок.
Многие команды слишком рано тянутся к PHP-пакетам для поиска. Если ваш текущий запрос уже достаточно быстрый, а пользователи могут находить очевидные вещи, оставайтесь в простоте. Лучше вложитесь в более точное сопоставление полей, понятные заголовки и небольшой набор фильтров, которые люди понимают.
Короткий еженедельный обзор помогает лучше, чем большой переписанный проект. Ведите обычный текстовый список или таблицу запросов, которые не сработали, дали слабый результат или ни к чему не привели. Сначала исправляйте повторяющиеся. Если пользователи ищут "статус возврата", а в справочном центре есть только "политика оплаты", это не проблема поискового движка. Это проблема контента и формулировок.
Практичный ритм выглядит так:
- запустите одну поисковую страницу и логируйте запросы
- каждую неделю проверяйте самые частые неудачные запросы
- сначала исправляйте названия, синонимы и недостающий контент
- измеряйте скорость поиска и долю запросов без результата
- заранее назначьте дату или порог, когда снова пересмотрите конфигурацию
Последний пункт особенно важен. Заранее решите, когда вернётесь к выбору движка. Например, пересмотрите его, когда поиск начинает тормозить при обычной нагрузке, когда ранжирование начинает приводить к обращениям в поддержку или когда вашей команде нужны обработка опечаток и правила релевантности, которые трудно поддерживать в поиске по базе данных на PHP.
Хорошая контрольная точка успокаивает команду. Она останавливает бесконечный поиск инструментов и одновременно не даёт вам цепляться за конфигурацию, которая уже не подходит.
Если хотите получить второе мнение, прежде чем добавлять новые компоненты, Oleg Sotnikov может проверить вашу настройку поиска на PHP в роли Fractional CTO. Такой разбор часто позволяет понять, достаточно ли нескольких аккуратных исправлений или пора переходить на отдельный поисковый движок.


