PgBouncer: transaction vs session pooling перед запуском
PgBouncer transaction vs session pooling влияет на prepared statements, temp tables и поведение приложения. Разберитесь в сбоях, особенностях драйверов и безопасном переключении.
Содержание
Какую проблему PgBouncer на самом деле решает
У загруженного приложения может быть намного больше подключений к Postgres, чем база должна обрабатывать напрямую. Каждое подключение занимает память, даже если простаивает. Postgres создаёт для каждого клиента отдельный backend-процесс, поэтому даже цепочка «спящих» подключений всё равно давит на сервер.
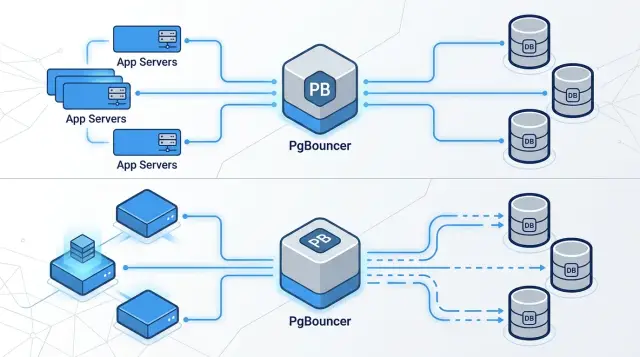
PgBouncer исправляет это несоответствие. Он стоит между приложением и Postgres, принимает много клиентских подключений и делит между ними гораздо меньший набор настоящих серверных подключений. Ваше приложение продолжает подключаться как обычно, а Postgres обрабатывает только то число server connections, которое ему действительно нужно.
Чаще всего это важно, когда трафик идёт неровно. Короткий всплеск может заставить сотни web-запросов, workers, cron-задач и скриптов подключиться одновременно, даже если реально выполняется только часть из них. Без pooler’а Postgres платит за все подключения. С Postgres connection pooling вы ограничиваете число серверных соединений и позволяете PgBouncer вместо этого ставить запросы в очередь или переиспользовать подключения.
Результат вполне практический, а не волшебный: меньше открытых подключений в Postgres, меньше давления на память и более ровное поведение при скачках трафика. Но PgBouncer — не бесплатный буст скорости. В первую очередь это инструмент контроля нагрузки на базу. А дальше вопрос уже в том, выдержит ли ваше приложение выбранный режим пула.
Именно здесь начинает иметь значение выбор между PgBouncer transaction vs session pooling.
Как работает session pooling
Session pooling закрепляет одно подключение Postgres за одним клиентом на всю жизнь этой клиентской сессии. Если ваше приложение открывает connection и держит его какое-то время, PgBouncer будет снова и снова отдавать ему то же серверное подключение, пока клиент не отключится.
Такое поведение легко понять. Оно ещё и сохраняет состояние сессии. Если код выполняет SET search_path, меняет часовой пояс, создаёт temp table или использует prepared statements, которые должны оставаться доступными для следующих запросов, всё это будет на месте в следующей транзакции, потому что приложение продолжает работать через то же backend-подключение.
Поэтому session pooling часто хорошо подходит как первый шаг. Старые приложения, админские инструменты, скрипты миграций и некоторые ORM молча предполагают стабильную сессию. Они задают параметры один раз при входе и больше к ним не возвращаются. Создают temp table, заполняют её, а потом читают из неё позже. Session pooling обычно оставляет такие сценарии рабочими и с меньшим числом сюрпризов.
Минус простой: вы теряете большую часть переиспользования соединений. Если PgBouncer должен держать одно server connection на каждую активную client session, у Postgres всё равно может остаться много открытых подключений под нагрузкой. Если ваш API, workers и админские задачи держат сессии дольше, чем нужно, экономия получается ограниченной.
Используйте session pooling, если ваш код зависит от состояния, привязанного к соединению, или если вы хотите максимально безопасный первый запуск. Обычно это более простой путь миграции, потому что приложение ведёт себя почти так же, как при прямых подключениях.
Как работает transaction pooling
Transaction pooling — более агрессивный вариант. PgBouncer выдаёт клиенту реальное подключение Postgres только на время одной транзакции. Как только транзакция заканчивается COMMIT или ROLLBACK, PgBouncer забирает серверное подключение обратно и может отдать его другому клиенту.
Это быстро меняет математику. Вместо того чтобы привязывать один backend Postgres к каждому соединению приложения, многие клиентские подключения могут делить гораздо меньший пул реальных database connections. Если у вашего API много коротких запросов, это обычно сокращает пустые простои и не даёт Postgres тратить память на сессии, которые в основном ждут.
Компромисс тоже очевиден. Код не может ничего предполагать о состоянии database session после окончания транзакции. Следующий запрос может попасть уже на другой backend с другой историей сессии. Transaction pooling лучше всего работает, когда каждый запрос начинает транзакцию, делает свою работу и заканчивается чисто, не оставляя после себя состояния.
Хорошая мысленная модель — не личная машина, а очередь такси. Вы используете connection для одной поездки, а потом он возвращается в линию. Не стоит ожидать, что всё, что вы оставили в этой сессии, будет ждать вас в следующий раз.
Этот режим отлично подходит для коротких web-запросов, сервисов с большим числом чтений и задач, которые оборачивают каждую единицу работы в одну транзакцию. Он плохо подходит для кода, который тихо зависит от temp tables, session-level SET, долгоживущих cursors, session advisory locks или prepared statements, которые должны переживать несколько транзакций.
Если у приложения уже есть чёткие границы транзакций, transaction pooling может почти не ощущаться. Если же у него есть скрытые сессионные привычки, он начнёт ломаться так, что это сначала выглядит случайностью, пока вы не разберёте поведение соединений.
Что ломается, когда код зависит от состояния сессии
Некоторые возможности Postgres предполагают, что последующие запросы попадут на то же backend-подключение. В session pooling это условие выполняется. В transaction pooling оно часто нарушается.
Prepared statements — классическая ловушка. Если приложение один раз подготовило statement и ожидает использовать его в нескольких транзакциях, следующий запрос может попасть на backend, где этого statement никогда не создавали. Тогда появляются ошибки вроде "prepared statement does not exist" или наоборот — когда имя statement уже существует на одном backend, но не существует на другом.
Temp tables ломаются по той же причине. Если код создаёт temp table, делает commit, а потом читает из неё позже, следующий запрос может уйти на другой backend, где этой таблицы никогда не было.
Session settings заметить сложнее, потому что фреймворки часто прячут их от вас. SET search_path, SET TIME ZONE или SET ROLE меняют только текущую сессию. Если приложение ждёт, что эти значения сохранятся после commit, transaction pooling рано или поздно докажет обратное.
LISTEN/NOTIFY тоже требует стабильной сессии. Подписчик должен оставаться привязанным к одному connection, чтобы получать уведомления. У session advisory locks та же проблема. Long-lived cursors — тоже. Если код открывает cursor, забирает часть результата и возвращается к нему позже, transaction pooling быстро ломает такой сценарий.
При ревью кода обращайте внимание на несколько явных красных флагов: один раз подготовить statement и использовать его позже, создать temp table и читать из неё после commit, выполнять SET при логине и считать, что оно сохранится, держать LISTEN-подключение внутри основного app pool или читать большие результаты через cursors в несколько шагов.
Одного такого паттерна уже достаточно, чтобы перед запуском провести точечное тестирование.
Какие сбои стоит ожидать после переключения
Первый сигнал тревоги обычно не выглядит как падение базы. Это скорее система, которая работает наполовину. Какие-то запросы проходят. Какие-то падают по, казалось бы, не связанным причинам.
Prepared statements ломаются чаще всего первыми. После деплоя один запрос работает, а следующий падает с "prepared statement does not exist" или "already exists". Обычно причина в кэше statement’ов на стороне драйвера, который предполагает, что backend-подключение всегда одно и то же.
Та же картина возникает с session variables, temp tables, cursors, advisory locks и командами SET. Ошибка выглядит случайной, но причина постоянна: состояние соединения больше не следует за запросом.
Long transactions — ещё одна частая проблема. Воркер открывает транзакцию, медленно делает работу в цикле и держит её открытой несколько минут. Потом миграции или другие задачи ждут позади него, потому что не хватает locks или свободного слота в маленьком пуле. Команды часто обнаруживают это уже во время релиза.
App-side pools создают вторую ловушку. Если каждый процесс приложения всё ещё держит 20 или 50 idle client connections, PgBouncer в итоге может обрабатывать большую кучу спящих клиентов. Postgres при этом защищён, но задержка растёт, потому что запросы теперь ждут в двух местах: сначала в app pool, потом в PgBouncer.
Админские скрипты ломаются чаще, чем люди ожидают. Скрипт подключается, выполняет SET search_path, создаёт temp table, а потом предполагает, что все следующие команды попадут на тот же backend. В локальном тестировании это может сработать, а в продакшене упасть уже на второй или третьей команде.
Быстрая карта симптомов помогает сориентироваться:
- Внезапные ошибки statement после деплоя обычно указывают на кэш prepared statements.
- Запрос проходит один раз и падает на следующем вызове, если код зависит от session state.
- Миграции зависают, когда long transactions или ожидание locks блокируют пул.
- Большое число idle clients обычно означает, что app pools всё ещё слишком большие.
- Странное поведение админских задач часто говорит о том, что им нужен session pooling или прямое подключение к Postgres.
Найти это до запуска намного проще, чем во время инцидента в продакшене.
Особенности драйверов и фреймворков, которые стоит проверить
Большинство сюрпризов с PgBouncer появляются не из самого Postgres. Их приносят настройки драйвера по умолчанию, которые раньше казались безобидными.
Начните с prepared statements. Многие драйверы и ORM автоматически делают prepare после того, как запрос выполняется несколько раз. В session pooling это часто работает нормально, потому что к клиенту всё время привязан один и тот же backend. В transaction pooling следующий transaction может попасть на другой backend, и prepared statement там уже не будет. Перед переключением посмотрите документацию и логи драйвера на предмет auto-prepare.
Следующее место, на которое стоит смотреть, — session state. Некоторые ORM задают search_path, TimeZone или другие значения через SET, когда открывают connection. Это работает, когда приложение держится за один backend. Это ломается, когда PgBouncer переиспользует backend’ы между многими клиентами. Если вам нужны эти настройки, задавайте их в начале каждой транзакции, по возможности переносите их в SQL или оставляйте такие нагрузки на session pooling.
Background workers требуют особого внимания. Web-запрос обычно быстро начинается и быстро заканчивается. Workers часто так не делают. Они могут открыть транзакцию, вызвать внешний API, подождать очередь и только потом записать результат. В результате server connection удерживается гораздо дольше, чем ожидалось, и блокирует другую работу.
Несколько проверок закрывают большую часть проблем. Прогоните тестовый набор с auto-prepare включённым и выключенным. Проследите один запрос и одну задачу воркера, чтобы увидеть, где транзакции реально начинаются и заканчиваются. Запустите миграции, health checks, cron-задачи и разовые скрипты вне обычного app traffic. Потом сравните лимиты app-side pool с лимитами PgBouncer и max_connections в Postgres.
Математика пулов важнее, чем многие думают. Если каждый экземпляр приложения открывает 50 подключений, а у вас 8 экземпляров, код может пытаться удерживать 400 client connections. PgBouncer сможет поставить этот трафик в очередь, но если реальный server pool — 40 или 80, задержка быстро вырастет, и в этом часто обвиняют Postgres, хотя проблема на самом деле в настройке размера.
Относитесь к API-серверам, воркерам, админ-скриптам и инструментам миграции как к разным программам. Им часто нужны разные варианты pooling.
Смешанные нагрузки: API, воркеры и админ-инструменты
Именно на смешанной нагрузке выбор между PgBouncer transaction vs session pooling перестаёт быть теоретическим.
Большинство web API хорошо подходят для transaction pooling. Запрос приходит, выполняет несколько операций, делает commit и заканчивается. Через секунду ему всё равно не нужно то же самое backend-подключение. Простой JSON API, который читает пользователя, пишет audit row и отвечает за 40 мс, — это самый простой случай.
Background workers устроены иначе. Batch imports, отчётные задачи и операции очистки часто держат транзакции открытыми гораздо дольше. Некоторые создают temp tables, используют cursors или зависят от того, что session settings остаются на месте. Такие задачи обычно лучше держать на session pooling, а некоторые вообще лучше отправлять мимо PgBouncer напрямую.
Админские консоли — ещё одна частая зона проблем. Кто-то открывает psql или GUI, делает SET ROLE, меняет search_path, смотрит temp objects, делает паузы между запросами и иногда случайно оставляет транзакцию открытой. Такое поведение гораздо лучше подходит для session pooling, чем для transaction pooling.
На практике самое чистое решение — разделять трафик по типам нагрузки. Stateless API-трафик отправляйте через transaction pooling. Воркеры с temp tables, длинными транзакциями или липким session behavior оставляйте на session pooling. Админский доступ направляйте в отдельный session pool или напрямую на Postgres порт.
Пытаться заставить всех клиентов жить в одном режиме — именно то место, где команды начинают терять время.
Как мигрировать с меньшим риском
Переход на transaction pooling редко превращается в большой проект по переписыванию кода. Реальный риск — это скрытые предположения о сессии, которые проявляются только под нагрузкой.
Начните с простого списка всего, что открывает подключение к Postgres: API-серверы, background workers, cron-задачи, инструменты миграции, админские скрипты и разовые maintenance jobs. Команды часто проверяют основное приложение и забывают про скрипт, который запускается раз в ночь и зависит от session state.
Потом проведите аудит типичных проблемных мест. Ищите в коде и SQL-файлах SET, temp tables, LISTEN/NOTIFY, advisory locks, cursors и настройки prepared statements на стороне драйвера. Проверьте не только request code, но и migration tools и seed scripts. Отметьте сервисы, которые держат long transactions или удерживают connection, пока делают что-то не связанное с базой.
Если драйвер умеет отключать auto-prepare, сделайте это до первого раунда тестов. Это уберёт одну из самых частых причин поломок при transaction pooling. Если потом понадобится, вы всегда сможете вернуть его обратно.
Не переключайте весь стек сразу. Начните в staging с одного низкорискового сервиса, в идеале маленького API или внутренней задачи, которая работает короткими транзакциями и не зависит от state, привязанного к соединению. Следите за error rate, query latency, насыщением пула, временем транзакций и числом server connections. Метрики подскажут, что что-то не так. Логи обычно подскажут, что именно.
После того как staging выглядит чисто, выкатывайте по нагрузке, а не по командам. Переведите один сервис, дайте ему поработать, потом следующий. Миграции, админские задачи и необычные SQL-пути оставляйте на конец — именно там обычно прячется странное поведение.
Если среда сложная, полезно получить второе мнение. В больших миграциях человек, который уже видел сбои PgBouncer, обычно быстро замечает рискованные места.
Проверки до и после запуска
Начинайте с цифр, а не с догадок. До того как пустить реальный трафик через PgBouncer, снимите простой baseline из Postgres и приложения: active connections, idle connections, queueing и sessions, которые ждут слот. После запуска сравнивайте те же показатели каждые несколько минут. Если ожидание растёт, а нагрузка на базу остаётся прежней, пул слишком маленький или клиенты держат соединения слишком долго.
Настройки пула заслуживают внимательной проверки. Перед переключением проверьте pool_size, резервную ёмкость, лимиты клиентов и timeout’ы. Частая ошибка — выставить max_client_conn достаточно высоким, чтобы принять трафик, но оставить реальный server pool слишком маленьким для всплесков логина, активности воркеров или админских задач.
Также стоит один раз прогнать реалистичный сценарий до запуска: войти и выйти в основном приложении, запустить background jobs, которые читают и пишут данные, выполнить миграции так же, как это делает ваша команда в продакшене, посмотреть логи на ошибки prepared statement и сбои с temp table, убедиться, что можно быстро обойти PgBouncer или вернуться к session mode.
Проверяйте логи сразу из трёх мест: приложения, PgBouncer и Postgres. Ищите пропавшие prepared statements, temp relations, которые исчезают, и транзакции, которые остаются открытыми дольше, чем ожидалось. Такие проблемы обычно проявляются рано.
План отката должен быть скучным. Сохраните настройки прямого подключения к Postgres, держите session mode готовым, если начинаете с transaction pooling, и заранее решите, кто может переключить трафик обратно. Если для отката нужен долгий созвон, план запуска ещё не готов.
Простое правило для команды
Считайте режим пула правилом сервиса, а не глобальной настройкой по умолчанию. Большинству команд помогает короткая политика: API используют transaction pooling, если им не нужно session state, а миграции, админ-инструменты и долгоживущие задачи остаются на session pooling или подключаются напрямую.
Это одно правило предотвращает много будущих ошибок. Оно ещё и не даёт новым сервисам копировать неправильную схему только потому, что так когда-то сделал старый проект.
Небольшой тест релиза стоит оставить в CI. Пусть он проходит через PgBouncer и падает, если код предполагает, что одно и то же backend-подключение остаётся привязанным между запросами. Откройте connection через пул, задайте session state или создайте временное состояние, а затем выполните следующий шаг так, как будто это новый запрос, и убедитесь, что приложение не зависит от старой сессии.
Такой баг часто спокойно переживает локальные тесты и появляется уже после деплоя. Один надёжный тест дешевле, чем ночной откат.
Пересматривайте настройки пула каждый раз, когда меняется характер нагрузки, а не только когда растёт трафик. Новая batch-задача, отчётный процесс или другой паттерн работы воркера может нагружать Postgres connection pooling совсем не так, как это делает ваш API. Снова проверьте размер пула, timeout’ы, резервную ёмкость и число client connections, которые открывает каждый сервис.
Если переключение затрагивает много сервисов, часто полезно получить ещё одну пару глаз на план запуска. Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами над инфраструктурой и в формате Fractional CTO, и это как раз тот практический аудит, который может поймать неверное допущение ещё до продакшена.
Цель проста: каждый сервис знает, какой режим он использует, один тест защищает от багов со session state, а команда пересматривает настройки, когда система меняется. Обычно этого достаточно, чтобы первый запуск прошёл спокойно, а не превратился в хаос.
Часто задаваемые вопросы
В чём на самом деле разница между session и transaction pooling?
Session pooling оставляет одно подключение Postgres закреплённым за одним клиентом на всю сессию. Transaction pooling выдаёт клиенту реальное серверное подключение только на время одной транзакции, а потом возвращает его в пул.
Выбирайте session mode, если вашему коду нужно состояние, привязанное к соединению. Выбирайте transaction mode, если запросы короткие и не зависят от сессии.
Какой режим выбрать для обычного веб-API?
Большинству веб-API лучше начинать с transaction pooling, если каждый запрос открывает транзакцию, выполняет нужные запросы и нормально завершается. Так много клиентов приложения могут делить меньшее число подключений Postgres.
Если ваш API тихо зависит от temp-таблиц, session SET или «липких» prepared statements, лучше оставить session pooling, пока вы не уберёте эти допущения.
Когда стоит оставить session pooling?
Оставайтесь на session pooling, если ваш код ожидает, что то же backend-подключение будет доступно и дальше. Сюда входят temp-таблицы, используемые после commit, долгоживущие cursors, LISTEN/NOTIFY, session advisory locks и SET, выполненные при входе в систему и которые должны сохраняться.
Это также разумный более безопасный первый шаг, если вы не до конца доверяете старым скриптам, админ-инструментам или поведению ORM.
Почему prepared statements ломаются в transaction pooling?
Они ломаются, потому что многие драйверы кэшируют prepared statements так, будто один клиент всегда подключается к одному и тому же backend. В transaction pooling следующая транзакция может попасть на другой backend, где этого statement просто нет.
Если драйвер позволяет, отключите auto-prepare на время тестирования. Это убирает очень частый источник ошибок, которые выглядят случайными.
Работают ли temp tables, SET commands и LISTEN/NOTIFY с transaction pooling?
Не работают между транзакциями. Temp-таблица или session SET живут в одном backend-подключении, а transaction pooling может отправить ваш следующий запрос на другое.
С LISTEN/NOTIFY та же проблема, потому что listener должен оставаться на одном стабильном соединении. Такие нагрузки лучше держать на session pooling или подключать напрямую к Postgres.
Могут ли background workers использовать transaction pooling?
Иногда да, но только если воркер держит транзакции короткими и не зависит от сессионного состояния. Воркер, который открывает транзакцию, вызывает внешний API, ждёт в очереди или работает в цикле по несколько минут, будет слишком долго держать серверное соединение.
Считайте воркеры отдельными программами. Короткие stateless-задачи могут использовать transaction pooling, а batch-задачам и sticky-сессиям обычно нужен session pooling.
Почему задержка может расти, даже если у Postgres меньше открытых соединений?
Обычно это значит, что запросы ждут не в одном месте. Приложение может по-прежнему держать большой client-side pool, а PgBouncer — ещё раз поставить очередь перед тем, как Postgres увидит работу.
Такая же боль возникает из-за длинных транзакций. Уменьшите пулы на стороне приложения, проверьте лимиты PgBouncer и посмотрите, не держит ли код транзакции открытыми дольше, чем нужно.
Как лучше тестировать PgBouncer перед продакшеном?
Тестируйте через PgBouncer, а не напрямую через Postgres. Прогоните один веб-запрос, одну задачу воркера, миграции, cron-задачи и любой админ-скрипт, который работает с базой.
Смотрите вместе логи приложения, PgBouncer и Postgres. Ищите ошибки prepared statement, пропавшие temp-объекты, длинные транзакции и запросы, ожидающие слот в пуле.
Нужен ли отдельный путь подключения для миграций, psql и админ-скриптов?
Да. Админ-инструменты и миграции часто предполагают стабильную сессию, потому что люди выполняют SET ROLE, меняют search_path, смотрят temp-объекты или случайно оставляют транзакцию открытой.
Дайте им session pool или прямой путь к Postgres. Не заставляйте всех клиентов идти через transaction pooling только потому, что API это выдерживает.
Как безопаснее всего внедрять PgBouncer в смешанной системе?
Переводите по одной нагрузке за раз, а не весь стек сразу. Начните с малорискового API с короткими транзакциями, а потом дайте ему поработать достаточно долго, чтобы увидеть реальное поведение.
Откат должен быть простым. Сохраните настройки прямого подключения к Postgres, оставьте session mode готовым и заранее решите, кто сможет вернуть трафик обратно, если появятся ошибки.


