Периодические задачи в Go с четкими границами между сервисом и планировщиком
Периодические задачи в Go работают лучше, когда приложение отвечает за бизнес-логику, а планировщик — за время запуска. Узнайте про повторные попытки, идемпотентность и безопасные границы задач.
Содержание
Что ломается, когда время запуска живет в приложении
С периодическими задачами в Go команды часто начинают с малого. Shell-скрипт запускается каждую ночь, один конфиг хранит правило cron, а в приложении есть маленькая проверка «запускать, если сейчас 2:00». Такая схема работает неделю или две. Потом уже никто не может сказать, где на самом деле живет расписание.
Одна задача оказывается с правилами времени в трех местах: cron, код приложения и конфигурация деплоя. Разработчик меняет выражение cron, но забывает про проверку времени в Go. На другом сервере все еще лежит старый скрипт. Теперь задача запускается с опозданием, дважды или не запускается вовсе. Хуже всего то, насколько это выглядит нормально, пока не случится что-то важное.
Когда приложение начинает само решать, когда выполнять работу, оно берет на себя задачу, которой не должно владеть. Веб-сервис должен отвечать на запросы и выполнять работу, когда его просят. Он не должен гадать, подходит ли именно «сейчас» нужный момент, особенно если у вас несколько экземпляров. Перезапуск, вторая реплика или медленный деплой могут превратить один запланированный запуск в несколько.
Обычно тревожные сигналы появляются быстро:
- Одно и то же правило cron встречается в комментариях к коду, скриптах и серверной конфигурации.
- Одна задача ведет себя по-разному в тестовой и боевой среде.
- Деплой меняет время запуска, хотя расписание никто не трогал.
- Люди спрашивают: «Сбой был или он вообще не стартовал?»
Повторные попытки тоже быстро превращаются в хаос. Внешний планировщик повторяет запуск, потому что процесс завершился с ошибкой. Внутри приложения обработчик тоже повторяет вызов API. Если оба уровня пытаются «помочь», один таймаут может привести к дублирующим записям, повторным письмам или двум синхронизациям счетов, которые мешают друг другу.
Разобрать неудачный запуск становится отдельным проектом. Логи могут показывать, что команда стартовала, но не видно, какая попытка нанесла ущерб. У обертки скрипта одна метка времени, у приложения другая, а у внешнего API — третья. Команды часами отвечают на простой вопрос: это был один неудачный запуск или три частичных?
Такой сценарий часто встречается в стартап-командах, особенно когда скрипт постепенно превращается в сервис. Проблема не в расписании как таковом. Проблема в том, что время, повторные попытки и бизнес-логику смешивают в одном месте.
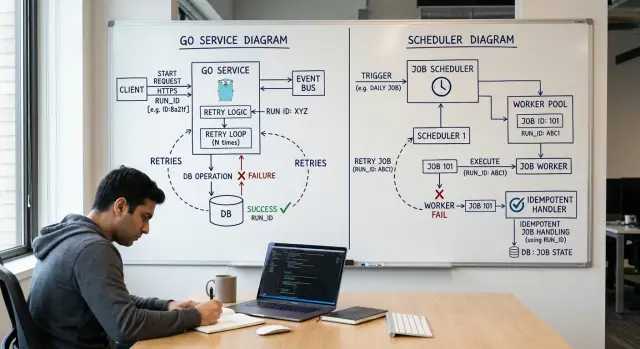
Проведите границу между приложением и планировщиком
Для периодических задач в Go раздел простой: планировщик решает, когда задача должна запуститься, а Go-сервис решает, что делать, когда приходит этот запрос на запуск. Смешивать эти две роли сначала кажется безобидным, но обычно это приводит к обработчикам, которые слишком много знают о времени, тексте cron и задержках повторных попыток.
Эта граница важна, потому что изменения расписания не должны требовать изменения кода. Если команде нужно запускать задачу в 5:00 вместо 6:00, достаточно поправить конфигурацию планировщика и двигаться дальше. Не нужно открывать код обработчика, трогать вычисления времени и заново выкатывать сервис.
Небольшой контракт между обеими сторонами
Оставляйте полезную нагрузку минимальной. Во многих случаях планировщику достаточно передать только имя задачи и дату запуска.
{
"job": "billing_sync",
"run_date": "2026-04-12"
}
Этого достаточно, чтобы сервис понял контекст, проверил запрос, выбрал нужный обработчик и выполнил работу именно за эту дату. Кроме того, так гораздо проще тестировать. Разработчик может отправить тот же payload из локального скрипта или тестового раннера, не дожидаясь cron.
Go-сервис должен сосредоточиться на нескольких вещах: проверить, что payload корректный, сопоставить имя задачи с обработчиком, выполнить бизнес-логику и вернуть понятный результат. Если данные плохие — отклонить запрос сразу. Если работа не удалась — сообщить об этом так, чтобы планировщик понял, что делать дальше.
Текст cron не должен жить в коде обработчика. Функция вроде RunBillingSync() не обязана знать, кто и как ее запускал: по 0 5 * * *, каждый час или из очереди. Ей нужно понимать только одно: она должна обработать один именованный запуск за одну дату.
Такое разделение дает и свободу на будущее. Потом можно перейти с cron на workflow engine, cloud scheduler или очередь, не переписывая саму логику задачи. У сервиса останутся те же входные данные и то же поведение.
Хороший тест специально скучный: если вы можете запустить обработчик с крошечной полезной нагрузкой и без логики, завязанной на время, граница, скорее всего, проведена правильно.
Сделайте обработчики безопасными для повторного запуска
Периодическая задача рано или поздно запустится дважды. Ее может перезапустить деплой, успешный запрос может скрыться из-за таймаута, или планировщик повторит запуск после медленного сетевого вызова. Если обработчик не переживет второй запуск, появятся дублирующиеся письма, двойные списания и болезненная зачистка.
У каждого запуска должен быть устойчивый идентификатор. Если задача работает с бизнес-объектом, используйте ключ дедупликации, связанный именно с этим объектом, например invoice:2026-04:customer_481 или account_77:billing_sync. Сохраните этот ключ до того, как совершите побочный эффект, а затем отклоняйте тот же ключ при следующих попытках.
Это особенно важно, когда из системы уходят деньги или сообщения. Если задача создает списание, отправляет счет или отправляет webhook, второй запуск должен увидеть, что действие уже произошло, и завершиться успешно, не делая его снова. Многие платежные и почтовые сервисы поддерживают idempotency tokens. Если нет — ведите свой журнал отправок и проверяйте его первым.
Большим задачам нужен контроль прогресса. Если один обработчик затрагивает 50 000 строк, не считайте это одним огромным блоком работы. Сохраняйте контрольную точку после каждой небольшой партии или каждой завершенной записи, чтобы повторная попытка могла продолжить с последнего безопасного места, а не начинать заново.
Обычно достаточно курсора, последнего обработанного ID или таблицы завершенных элементов. Выберите то, что вашей команде проще всего проверить в 2 часа ночи, когда задача зависнет.
Записывайте изменения в безопасном порядке. Сначала фиксируйте намерение, потом выполняйте действие один раз, и только затем сохраняйте подтвержденный результат. Если сначала отправить, а потом записать, сбой в середине оставит вас в догадках: повторять попытку или остановиться.
Обработчик должен возвращать один понятный результат:
done, когда работа завершена или уже выполненаretry, когда временная ошибка помешала движению впередstop, когда плохие данные или бизнес-правило означают, что следующая попытка тоже провалится
Такой небольшой контракт делает правила повторов чистыми. Он еще и сильно упрощает тестирование идемпотентных обработчиков задач, потому что два одинаковых запуска должны оставлять систему в одном и том же конечном состоянии.
Выберите правила повторов до релиза
Не всякий сбой заслуживает еще одной попытки. Таймаут со стороны API часто проходит сам собой. Неверный customer ID — нет. Если считать их одинаковыми, вы тратите ресурсы, засоряете логи и скрываете настоящую проблему.
Разделите сбои на два типа. Временные ошибки нужно повторять. Постоянные — сразу останавливать и просить исправление. Команды, которые переходят от скриптов к сервисам, часто пропускают этот шаг, а потом удивляются, почему простая периодическая задача крутится часами.
Обычно достаточно небольшого набора правил:
- Повторять сетевые таймауты, кратковременные ошибки 5xx, лимиты запросов и короткие обрывы соединения с базой данных.
- Останавливаться на некорректных данных, отсутствующих записях, которые уже должны существовать, сломанной конфигурации и ошибках прав доступа.
- Поставить жесткий лимит на количество попыток. Для большинства задач достаточно трех-пяти повторов.
- Делать паузу между попытками. Начните с 30 секунд или нескольких минут, а если одна и та же ошибка повторяется, увеличивайте задержку.
Время ожидания очень важно. Если задача повторяется каждую секунду, короткий сбой у внешней системы превращается в лишнюю нагрузку для обеих сторон. Backoff дает другой системе время на восстановление и делает работу вашего сервиса спокойнее.
Каждая попытка должна оставлять понятный след. Сохраняйте номер попытки, сообщение об ошибке, код причины и следующее действие. Это может быть «повторить через 2 минуты», «остановиться и оповестить» или «отбросить, потому что данные некорректны». Когда позже кто-то смотрит на задачу, ему не нужно гадать, что произошло.
Поставьте еще одно ограничение: общее время повторов. Если задача запускается каждые 10 минут, но может повторяться час, можно накапливать перекрывающуюся работу. Очень быстро это становится грязным. Закройте окно повторов, пометьте запуск как неудачный и дайте человеку или следующему чистому запуску подхватить проблему.
Правила повторов не обязаны быть хитрыми. Они должны быть скучными, предсказуемыми и понятными. Если команда может прочитать сбой и за несколько секунд понять следующее действие, значит, правила работают как надо.
Переходите со скриптов на сервис небольшими шагами
Большинству команд не нужен полный переписанный проект. Когда периодические задачи в Go начинаются как shell-скрипты, безопаснее сначала составить карту того, что уже работает, а потом переносить по одной задаче в небольшой сервис.
Начните с простого инвентаря. Запишите каждый скрипт, что он делает, как часто запускается, где запускается и кто запускает его сегодня. Обычно всплывает беспорядочная смесь: одна cron-задача на VM, один скрипт, который запускает основатель, еще одна операция, спрятанная в CI-пайплайне. Этот список дает реальный план миграции, а не тот, который люди помнят по памяти.
Затем сгруппируйте задачи по времени и владельцу. Ночная синхронизация биллинга принадлежит финансовой команде. Импорт товаров каждые 15 минут — команде, которая отвечает за каталог. Это звучит скучно, но помогает избежать частой проблемы: команда разработки запускает задачу, а в бизнесе никто не замечает, что результат выглядит неправильно.
Прежде чем переносить что-то, выберите один формат обработчика и одну обертку задачи для всех запусков. Пусть она будет скучной и одинаковой. Каждый запуск должен содержать одни и те же базовые поля:
- имя задачи
- запланированное время
- идентификатор запуска
- номер попытки
- payload
Такая обертка делает логи, повторы и уведомления гораздо понятнее. Она еще и не дает разовым задачам обзаводиться собственными исключениями.
Соберите определения расписаний в одном месте. Это может быть конфигурационный файл планировщика, небольшая таблица или отдельный пакет внутри сервиса. Не размазывайте правила времени по коду, cron-табам и скриптам деплоя. Когда кто-то спрашивает: «Когда это запускается?», должен быть один ответ.
Затем сначала выпустите одну задачу с низким риском. Выберите что-то полезное, но простое для проверки, например ежедневный отчет или обновление кэша. Понаблюдайте за ним несколько дней. Проверьте время запуска, сбои, дубли и то, сколько времени занимает восстановление после ошибки. Если команда может объяснить, что произошло во время одного неудачного запуска, значит, схема достаточно хороша, чтобы переносить следующую задачу.
Небольшие SaaS-команды часто торопятся на этом этапе. Позже они об этом жалеют. Медленная и видимая миграция обычно лучше, чем изящная.
Пример: ежедневная синхронизация счетов для небольшого SaaS
Небольшой SaaS, который забирает счета из клиентских billing-аккаунтов, часто запускает синхронизацию ночью, когда трафик к API ниже. В 02:00 планировщик создает по одной задаче на каждый аккаунт. Он лишь создает запрос на запуск с account ID, плановым временем и идентификатором запуска. Он не забирает счета и не решает, прошла ли синхронизация успешно.
Go-сервис выполняет бизнес-работу. Обработчик задачи загружает аккаунт, читает последний сохраненный курсор синхронизации и запрашивает у billing API счета, которые новее этого курсора. После сохранения новых счетов он записывает самый свежий курсор. Такое разделение сохраняет границу чистой. Планировщик отвечает за время. Приложение отвечает за логику синхронизации.
Предположим, один аккаунт обычно завершается меньше чем за минуту, но API провайдера начинает тормозить, и обработчик упирается в таймаут. Запуск должен завершиться статусом таймаута, а планировщик должен поставить одну повторную попытку через 10 минут. Это дает провайдеру шанс восстановиться, не создавая шторм дублирующих запусков.
Если повторная попытка стартует после того, как первая уже успела сохранить часть счетов, обработчик все равно должен работать безопасно. Он еще раз читает текущий курсор перед обработкой. Если этот курсор уже покрывает счета из предыдущей попытки, они пропускаются. Никаких дублирующихся строк, никакого второго webhook и никакой грязной зачистки следующим утром.
Некоторые сбои требуют жесткой остановки. Если провайдер сообщает, что access token истек, задачу не нужно повторять вообще. Обработчик должен пометить аккаунт как требующий ручного действия, сохранить причину и выйти. Отложенный повтор никогда не исправит сломанные учетные данные.
Вот как на практике выглядят идемпотентные обработчики задач и понятные правила повторов. Когда команда переходит от скриптов к сервису, такая ежедневная синхронизация счетов остается предсказуемой: одно решение планировщика, одна задача-обработчик, один сохраненный курсор и понятные случаи для повторной попытки или ручного вмешательства.
Ошибки, которые команды допускают в начале
Первая версия периодических задач в Go часто начинается как одна функция, которая делает все. Она читает расписание cron, решает, запускаться ли ей, загружает данные, пишет в базу, вызывает API и отправляет сообщение, когда заканчивает. Сначала это кажется быстрым. Через месяц никто не хочет к этому прикасаться.
Такое смешение рождает мелкие баги, которые трудно заметить. Если логика времени живет рядом с бизнес-логикой, каждое изменение становится рискованным. Простое изменение времени запуска может сломать саму работу задачи, а изменение задачи может повлиять на ее расписание.
Еще одна частая ошибка — прятать повторные попытки внутри обработчика. Разработчик оборачивает вызов API в цикл, а затем планировщик еще и повторяет всю задачу после сбоя. Один плохой запрос может превратиться в шесть вызовов, дублирующиеся записи или лимит запросов у партнерского API. Обычно команды замечают это только после того, как клиенты получают два письма или два счета.
Обработка времени тоже создает проблемы. Разработчики вызывают time.Now() глубоко внутри бизнес-кода, и тогда тесты начинают зависеть от часов. Тест проходит в 10:00, падает в полночь, и никто ему не доверяет. Вместо этого передавайте текущее время в обработчик. Так правила остаются понятными, а тесты — скучными, что и нужно.
Письма и другие побочные эффекты тоже быстро подставляют команды. Задача обновляет заказ, отправляет письмо с подтверждением и только потом завершает транзакцию в базе. Если commit падает, у клиента остается письмо о том, чего на самом деле не произошло. Порядок действий важен. Сначала сохраните состояние, потом запускайте побочные эффекты на основе уже зафиксированных данных.
Трассировка тоже часто отсутствует с первого дня. Задача запускается, падает, повторяется, частично проходит и оставляет после себя беспорядок. Без идентификатора запуска невозможно понять, какие логи, строки в базе и исходящие вызовы относятся к одной и той же попытке. В итоге приходится гадать. А гадание медленное и дорогое, когда задача затрагивает деньги или клиентские аккаунты.
Более чистая схема проста: планировщик решает, когда запускать, обработчик делает одну единицу работы, а у каждой попытки есть ID, по которому ее можно отследить в логах и хранилище. В коде такое разделение выглядит скучно. Но скучный код проще доверить в 2 часа ночи.
Быстрая проверка перед запуском задачи
Перед тем как выводить периодические задачи в Go в продакшен, сначала проверьте скучные вещи. Большинство сбоев задач связаны не с бизнес-логикой. Они связаны с повторными запусками, размытыми ошибками, отсутствием видимости и одним плохим tenant, который блокирует всех остальных.
Короткая предварительная проверка сильно экономит время на зачистку позже:
- Запустите обработчик дважды с одним и тем же входом. Второй запуск не должен делать ничего вредного. Если он создает дублирующиеся строки, отправляет второе письмо или списывает деньги дважды — остановитесь и исправьте это до релиза.
- Разделите ошибки на две группы. Временные сбои, например таймаут или лимит запросов, должны повторяться. Постоянные ошибки, например некорректные данные или отсутствующая запись клиента, должны останавливаться и сообщать о проблеме.
- Изолируйте tenants или аккаунты. Один клиент с испорченными данными не должен замораживать всю задачу. Обрабатывайте каждого tenant в своей единице работы, чтобы можно было пропустить, повторить или поставить на паузу одного, не трогая остальных.
- Храните достаточно входных данных, чтобы можно было воспроизвести один неудачный запуск. Сохраняйте payload запроса, выбранного tenant и версию задачи, либо явно логируйте их. Если поддержка не может повторно запустить один случай без догадок, отладка затянется.
- Показывайте время последнего успеха и последнюю ошибку в месте, где человек может быстро это прочитать. Обычно достаточно простой admin-страницы или dashboard.
Эти проверки кажутся мелкими, но именно они формируют всю архитектуру. Идемпотентные обработчики задач нуждаются в стабильных идентификаторах и понятных правилах записи. Правила повторов требуют типов ошибок, которые что-то значат. Изоляция tenants часто означает, что вы перестаете думать о «ежедневной синхронизации» как об одной огромной задаче и начинаете мыслить более мелкими запусками.
Простой пример хорошо показывает суть. Допустим, синхронизация биллинга запускается каждую ночь для 200 клиентов. У клиента 37 плохие учетные данные. Задача должна пометить этот tenant как неуспешный, записать ошибку и продолжить работу. Команда по-прежнему должна видеть, что 199 клиентов завершены, одному клиенту нужно внимание, а неудачный случай можно запустить снова после исправления учетных данных.
Если вы не можете ответить на эти проверки простым языком, задача еще не готова.
Следующие шаги к более чистой схеме задач в Go
Более чистая схема начинается на бумаге, а не в коде. Для каждой периодической задачи запишите три вещи: кто решает, когда она запускается, какой вход ей нужен и когда она должна прекращать повторы. Если эти правила остаются размытыми, обработчик превращается в мешанину из логики времени, бизнес-логики и кода восстановления.
Сначала достаточно простой заметки о задаче. Сделайте ее короткой и конкретной:
- Планировщик отвечает за время и правила запуска
- Go-сервис отвечает за обработчик и бизнес-проверки
- У каждого запуска есть идентификатор запуска для трассировки и логов
- Повторы останавливаются после фиксированного лимита или явной терминальной ошибки
Одна такая страница экономит время позже. Когда задача падает в 2 часа ночи, команда сразу видит, проблема в расписании, входных данных или в самом обработчике.
Затем на этой неделе выберите одну задачу и вынесите логику расписания из обработчика. Не начинайте с самой запутанной. Возьмите то, что уже работает по фиксированному интервалу, например ежедневную синхронизацию или очистку. Перенесите правило времени в планировщик, оставьте обработчик сосредоточенным на одной единице работы и передавайте контекст запуска как входные данные. Маленькие победы здесь важны. Одна чистая задача учит шаблону лучше, чем большой переписанный кусок.
Прежде чем добавлять больше задач, добавьте базовые вещи, которые команды часто пропускают. Храните время последнего успеха. Включайте идентификатор запуска в логи, метрики и оповещения. Решите, кого уведомлять, когда повторы заканчиваются, и что считать шумом, а что — реальной проблемой. Без этого задачи тихо накапливаются, пока кто-то не заметит устаревшие данные.
Если ваша команда переходит от скриптов к сервисам и хочет второе мнение, Oleg Sotnikov может как Fractional CTO посмотреть на архитектуру ваших Go-задач и модель повторов. Такой разбор обычно рано ловит простые проблемы: повторы, которые бесконечно бьют по одной и той же плохой записи, обработчики, небезопасные для повторного запуска, или расписания, которые живут в двух местах и расходятся.
Хорошие периодические задачи скучны. Они запускаются вовремя, падают понятным образом и оставляют достаточно следов, чтобы кто-то другой быстро их починил.


