Пересборка поискового индекса без дрейфа после изменения схемы
Пересборка поискового индекса требует не только новой загрузки. Узнайте, как добивать данные, переключать индексы без простоя и проверять релевантность после изменения схемы.
Содержание
Почему результаты дрейфуют после изменения схемы
Поиск может казаться неправильным, даже если он не падал. Запросы по‑прежнему возвращают результаты, логи выглядят нормально, и ничего явно не сломано. Но изменение схемы может изменить то, какие данные хранит документ, как индексируется текст и какие поля влияют на ранжирование.
Небольшие изменения часто дают более серьёзный эффект, чем команды ожидают. Добавили оценку популярности, разделили одно текстовое поле на два или поменяли способ хранения тегов — и тот же запрос может вернуть другой порядок. Пользователям всё равно, что схема менялась. Они сравнивают сегодняшние результаты с тем, что работало на прошлой неделе.
Дрейф усиливается, когда в индексе живут смешанные старые и новые записи. Новые документы могут содержать свежие поля, а у старых остаются пустые или запасные значения. Тогда логика ранжирования обрабатывает похожие элементы по‑разному, хотя они должны одинаково соответствовать запросу.
Пробелы в добивке вызывают большую часть этого. Если вы добавили поле вроде brand, category_weight или normalized_title, но получили его только у новых записей, старые записи тихо теряют позиции. В логах этого не видно. Пользователи просто начинают замечать странный порядок, слабые совпадения или почти одинаковые товары, которые стоят на разном месте.
Именно поэтому пересборка — это не просто копирование данных из одного индекса в другой. Изменение схемы может незаметно переписать правила ранжирования. Если старые и новые документы имеют разную структуру, дефолты и входы для скоринга, релевантность раскалывается.
Решите, что должно остаться прежним
Прежде чем менять маппинги или стартовать пересборку, решите, что нельзя ломать для пользователей.
Начните с реальных поисков из логов. Группируйте их по намерению: поиски бренда, точные названия продуктов, терминология категорий, номера деталей и распространённые запросы по проблеме. Именно они обычно приносят большую часть трафика, и пользователи быстро заметят, если они перестанут работать.
Затем сопоставьте эти запросы с полями, которые за них отвечают. Некоторые имена можно переименовать без особых проблем. Другие — нельзя. Если приложение ищет по title, фильтрует по brand и сортирует по price, переименование любого из этих полей без плана создаёт тихие отказы. Приложение может продолжить отправлять старое имя поля, новое поле может индексироваться иначе, или фильтр может вернуть пустой набор без явной ошибки.
Будьте явными и с фильтрами и сортировкой. Если пользователи сегодня могут фильтровать по размеру и цвету, эти фильтры должны возвращать тот же тип наборов завтра. Если «price low to high» сейчас игнорирует недоступные товары — сохраните это правило, если вы не хотите менять поведение по‑целенаправленно.
Короткая шкала проверки поможет это контролировать:
- Топ‑ежедневные запросы возвращают те же или лучшие результаты на первой странице.
- Фильтры возвращают ожидаемые счётчики для нескольких известных запросов.
- Сортировка соответствует текущему поведению продукта.
- Количество пустых результатов не растёт после переключения.
Небольшой пример показывает риск. Допустим, магазин переименовал product_name в title и разделил category на department и type. Это может работать, но только если логика запроса всё ещё знает, где искать, какие фильтры показывать и как сортировать. Решив это до начала пересборки, вы избежите медленного утечки релевантности позже.
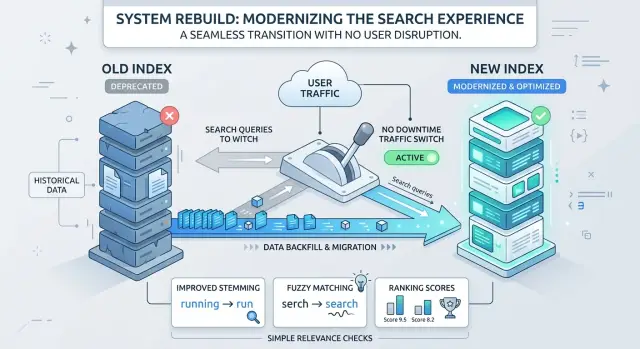
Добивайте новый индекс по шагам
Закройте новую схему до загрузки данных. Если поля, анализаторы, токен‑фильтры или настройки ранжирования продолжают меняться во время загрузки, вы перестаёте измерять одну пересборку и начнёте гнаться за движущейся целью.
Создайте новый индекс рядом с живым. Не переиспользуйте старый индекс и не направляйте продовые чтения на новый по ошибке. Два индекса дают пространство для сборки, тестов и сравнения без вмешательства в результаты, которые видят пользователи.
Загружайте данные пакетами, которые можно спокойно перезапускать. Для одной команды это может быть 500 записей, для другой — 5000. Правильный размер пакета — самый большой, который вы можете быстро запустить снова, легко инспектировать и восстановить, если воркер упал посередине.
Каждый прогон добивки должен фиксировать несколько простых чисел: сколько записей прочитано, сколько записей записано, самый старый и самый новый timestamp в этом пакете, какие элементы упали и сколько занял пакет. Эти метрики ловят проблемы рано. Если записи вдруг перестали писаться или временные метки перестали двигаться — вы знаете, куда смотреть.
Сделайте загрузчик идемпотентным. Если один и тот же продукт или документ придёт дважды, вторая запись должна аккуратно заменить первую. Это экономит много уборки при перезапусках задач.
Ближе к концу выполните проход поймать‑догонять для записей, которые изменились во время основной загрузки. В загруженной системе данные всегда будут двигаться. Запросите по времени последнего обновления, перезагрузите этот меньший набор и повторяйте, пока лаг не станет приемлемым.
Многие команды также делают небольшую паузу в записях, выполняют финальную дельту и затем переключают трафик. Пауза может быть короткой. Смысл прост: когда вы переключаете индексы, новый должен отражать тот же мир, что и старый, на момент чуть раньше.
Переключайте индексы без простоя
Держите все чтения на живом индексе пока строите замену. Команды всё ещё ошибаются и направляют часть продового трафика в полупустой индекс. Так пользователи оказываются дебагерами вашей пересборки.
Передcutover прогрейте новый индекс подборкой реальных запросов из недавнего трафика. Используйте частые запросы, «грязные» запросы и несколько примеров из long tail. Это наполняет кэши, выявляет медленные фильтры и показывает, не изменила ли схема ранжирование нежелательным образом.
Если стек поиска поддерживает alias или маршрутизацию — используйте их для одного атомарного действия. Указывайте read alias на старый индекс во время сборки, затем переключите его на новый одним действием. Не меняйте серверы приложений по‑одному. Не ждите пошагового обновления кэшей. Один шаг безопаснее и проще восстанавливаем.
На что смотреть сразу после переключения
Первые несколько минут дают много информации. Следите за коротким набором сигналов, которые быстро показывают проблемы:
- уровень ошибок поиска
- задержки запросов, особенно p95 и p99
- частота пустых результатов по частым запросам
- поведение кликов или добавлений в корзину, если поиск влияет на покупки
Держите эту панель открытой в течение первого часа. Если задержки растут или пустые результаты скачут — воспринимайте это как проблему релиза сейчас, а не как задачу по‑дальнейшей тонкой настройке.
Откат требует такого же планирования, как и переключение. Оставьте старый индекс целым, аккуратно подходите к зеркальным записям и убедитесь, что alias может указать назад так же быстро, как и вперёд. План отката, который живёт только в чьей‑то голове — не план.
Самый безопасный паттерн и есть скучный: добивайте в фоне, прогрейте новый индекс, один раз переключите трафик и будьте готовы вернуться назад.
Проверяйте релевантность до того, как пользователи заметят
Пересборка может закончиться вовремя и всё равно сделать поиск «не таким». Пользователи быстро заметят, если точное совпадение опустилось ниже широкого соответствия, если фильтры скрывают очевидные товары или если сортировка «новые» стала выглядеть случайно.
Используйте реальные запросы из логов, а не выдуманные тесты. Выберите запросы, которые приносят основной трафик, те, что связаны с продажами или поддержкой, и несколько повторяющихся с небольшими опечатками. Запросы с реальной историей показывают больше проблем, чем синтетика.
Запустите старый и новый индексы рядом и сосредоточьтесь на первой странице. Это всё, что большинство людей вообще просматривает. Если одно и то же намерение теперь даёт другой топ‑набор, остановитесь и найдите причину до переключения.
Для каждого запроса проверьте пару вещей. Попадает ли точное совпадение по‑прежнему в топ? Возвращают ли фильтры те же элементы и примерно те же счётчики? Сохраняется ли порядок сортировки по цене, дате и популярности? Не стало ли какое‑то поле пустым во время добивки и тихо не повлияло на ранжирование?
Пустые поля наносят больше вреда, чем команды ожидают. Если в новом индексе нет оценки популярности, названия бренда, пути категории или флага наличия, ранжирование может сместиться, даже если изменение схемы выглядело небольшим.
Немного движения нормально. Более чистый индекс может вознаградить лучшие заголовки или опустить товары без наличия, и это может быть полезно для пользователей. Проблема — необъяснимое движение. Если результат 2 стал результатом 18, вы должны знать, какое поле или правило это вызвало.
Не останавливайтесь на частых запросах. Просмотрите небольшой набор редких запросов тоже. Длинные названия продуктов, номера моделей, артикулы и непривычные формулировки быстро выявляют ошибки маппинга.
Держите ревью маленьким и честным. 20–30 сильных запросов скажут больше, чем большой набор синтетики, если они покрывают широкие термины, точные идентификаторы и крайние случаи. Пометьте каждый запрос как «так же», «лучше» или «хуже» и укажите причину. Если та же причина повторяется — исправьте данные или правило ранжирования до переключения.
Простой пример каталога продуктов
Магазин с 20 000 товаров делает проблему наглядной. Команда расширяет схему каталога и добавляет два поля для каждого товара: цвет и размер. Новые товары получают эти поля сразу, а у старых значения остаются пустыми.
Этот разрыв меняет поиск больше, чем многие думают. Если движок теперь даёт дополнительный вес полю цвет, запрос вроде «black shoes» начнёт возвращать смешанные результаты. Некоторые новые товары поднимутся, потому что у них color = «black», а старые чёрные туфли останутся ниже, потому что у их записи нет этого значения.
До пересборки
На бумаге изменение схемы безвредно. Заголовок всё ещё говорит «Men's Black Running Shoes», а описание упоминает цвет. Но как только поиск начинает использовать новые структурированные поля, документы с отсутствующими значениями часто теряют позиции.
Пользователи почувствуют это как непоследовательность. Два почти идентичных товара могут ранжироваться очень по‑разному только потому, что одна запись обновлялась на прошлой неделе, а другая пришла из старого импорта.
Исправление начинается с полной добивки. Команда строит новый индекс параллельно и сначала заполняет color и size для старого каталога. Иногда эти значения берутся из опций продукта, иногда из данных вариантов, а иногда из скрипта очистки, который извлекает их из существующего текста.
Если у товара действительно нет известного размера или цвета, отметьте это явно, вместо того чтобы оставлять поле наполовину пустым. Пустые поля и явные значения «unknown» ведут себя по‑разному в правилах ранжирования и фильтрах.
После добивки
Когда отсутствующие данные заполнены, запрос «black shoes» становится значительно стабильнее. Старые и новые продукты теперь конкурируют по одним и тем же сигналам, и ранжирование отражает релевантность продукта, а не возраст записи.
Команде не стоит доверять одной точечной проверке. Сохраните небольшой набор запросов и сравните старый и новый порядок до переключения. Для этого каталога набор может включать «black shoes», «red dress size m», «kids blue sneakers» и «winter boots 42». Просмотрите первую страницу для каждого запроса и задайте простой вопрос: выглядят ли новые результаты более логичными, чем старые?
Это и есть реальная работа пересборки. Обновление схемы делает новые поля возможными, а добивка — полезными.
Ошибки, которые ломают поиск во время пересборки
Большинство неудачных пересборок не падают. Поиск просто становится чуть хуже каждый день.
Одна распространённая ошибка — менять токенизацию и думать, что это не повлияет. Бренды часто ломаются первыми. Если вы иначе разбиваете или нормализуете текст, запросы вроде «3M», «AT&T» или модели с числами могут перестать совпадать так, как люди ждут. Всегда тестируйте бренд‑термины, артикулы и короткие имена перед тем, как доверять новому анализатору.
Ещё одна частая проблема — вернуть удалённые записи в новый индекс. Обычно это случается, когда добивка читает старый экспорт или soft‑deleted строки выглядят как живые. Пользователи быстро заметят, если поиск показывает товары, которые нельзя открыть или купить.
Скоринг также может пойти не так при нулевом даунтайме переиндексации. Если alias указывает на индексы с разной логикой ранжирования, один и тот же запрос может дать смешанную страницу: часть результатов от старого скоринга, часть — от нового, и порядок будет ощущаться как случайный. Держите чтения на одном индексе, пока новый полностью не готов, или сохраните согласованность правил скоринга для обоих индексов.
Команды также забывают мелкие настройки, которые формируют повседневный поиск. Синонимы, стоп‑слова, правила стемминга, поля фасетов и поля сортировки часто живут вне основной схемы. Если вы пересобрали маппинг, но забыли «tv = television» или поле, отвечающее за сортировку по цене, поиск будет ощущаться незаконченным.
Последняя и самая частая ошибка — проверить только количество документов и на этом остановиться. Совпадение счётчиков доказывает только, что данные перенеслись. Оно не доказывает, что люди найдут то, что им нужно.
Задайте несколько простых вопросов перед тем, как объявить работу завершённой. Бренд‑названия всё ещё совпадают? Удалённые элементы остаются в стороне? Один и тот же запрос возвращает стабильное ранжирование? Фильтры и сортировки работают? Топ‑результаты имеют смысл? Если на любой вопрос ответ «нет» — пересборка не завершена.
Быстрая проверка до и после запуска
Большинство проблем поиска после релиза выглядят сначала незначительными. Исчезают несколько продуктов, счётчик фильтра странно выглядит или один популярный запрос начинает ранжировать не тот товар первым. Поймайте такие проблемы в первый час — и большинство пользователей ничего не заметит.
Начните с сравнения нового индекса с исходными данными, а не только со старым индексом. Если источник говорит, что у вас 48 220 живых записей, новый индекс должен содержать тот же набор, за вычетом всего, что вы целенаправленно исключили. Проверьте полный счётчик и несколько срезов, например активные товары, архивные или одну большую категорию.
Перед переключением выполните короткую выборку реальных запросов. Используйте точные названия продуктов, частичные названия, распространённые опечатки и широкие категории. Для каждого запроса подтвердите, что первые несколько результатов по‑прежнему имеют смысл. Пересборки обычно ломают релевантность на краях, а не в очевидных запросах.
Фильтры требуют отдельной проверки. Откройте несколько привычных комбинаций фильтров и проверьте и значения, и счётчики рядом с ними. Каталог с правильными товарами, но неправильными фасет‑счётчиками всё равно создаёт ощущение поломки.
Сразу после запуска держите практические проверки:
- сравните количество документов с источником снова
- прогоните выборку запросов и пересмотрите топ‑результаты
- протестируйте несколько фильтров и подтвердите, что счётчики соответствуют возвращаемым элементам
- следите за логами ошибок, задачами индексирования и таймаутами поиска на предмет пиковой активности
- отредактируйте одну запись, синхронизируйте её и убедитесь, что откат всё ещё работает
Последняя проверка важна. План отката может выглядеть хорошо, пока не произойдёт первая запись в новую схему. Если обновление товара попадёт в новый индекс, а старый перестанет принимать такой тип записей — откат перестаёт быть реальным.
Если этот чеклист занимает больше 15–20 минут, сократите его, чтобы люди действительно выполняли его каждый раз.
Что делать дальше
Относитесь к каждой пересборке как к повторяемому релизу, а не как к разовому ремонту. Напишите план до следующего изменения схемы. Одной страницы достаточно, если она называет старые и новые поля, порядок добивки, шаги переключения и триггер отката.
Сохраните небольшой набор запросов и используйте его при каждом релизе. Берите его из реальных поисков, а не из догадок. Включите высокотрафиковые термины, несколько длинных запросов, опечатки и запросы, которые часто ведут к покупкам, обращению в поддержку или пустым результатам. Когда один и тот же набор прогоняется до и после каждой пересборки, дрейф заметить гораздо проще.
Короткий раннобук должен описывать, что вы добиваете в первую очередь, как сравниваете старые и новые результаты, кто утверждает переключение, кто может откатывать и какие сигналы запускают откат.
Назначьте одного владельца для cutover. Проблемы возникают, когда изменения поиска, приложения и инфраструктуры пересекаются и никто не принимает окончательное решение. Один человек должен владеть чеклистом, временем и решением об откате.
Если поиск и инфраструктурные изменения выпускаются одновременно, проведите короткий архитектурный обзор. 30 минут могут поймать плохой подбор шардов, ошибку с alias, давление в очередях или нагрузку на базу до того, как пользователи почувствуют проблему.
Если нужна внешняя проверка, Oleg Sotnikov at oleg.is работает как fractional CTO и стартап‑советник. Он помогает командам с архитектурой продукта, lean‑инфраструктурой и практическим AI‑ориентированным развитием, что полезно, когда пересборка поиска затрагивает и логику ранжирования, и операционные вопросы.
Сам процесс прост: сохраните раннобук, сохраните набор запросов, назначьте владельца и используйте один и тот же процесс каждый раз.
Часто задаваемые вопросы
Почему мои результаты поиска изменились после небольшого обновления схемы?
Небольшое изменение схемы может сильнее повлиять на ранжирование, чем кажется. При добавлении полей, переименовании или смене анализаторов поисковая система по‑другому хранит и оценивает документы, поэтому один и тот же запрос может вернуть другой порядок результатов даже при нормальных логах.
Нужна ли полная добивка после добавления новых полей?
Чаще всего — да. Если новые поля появляются только у новых записей, старые записи начинают конкурировать с более слабой информацией и опускаются в ранжировании. Полная добивка приводит старые и новые документы к одному виду, чтобы поиск сравнивал их честно.
Что нужно определить перед началом пересборки?
Определите, что пользователи должны по‑прежнему получать после изменений. Держите короткую шкалу проверки для топ‑запросов, фильтров, сортировок и частоты пустых результатов, затем сопоставьте каждое правило с полями, которые за это отвечают. Это даст конкретные тесты до переключения трафика.
Как пересобрать индекс без простоя?
Постройте новый индекс рядом с живым и держите все чтения на текущем индексе, пока замена не будет готова. Загружайте данные пакетами, устойчивыми к повторным запускам, выполните финальную синхронизацию изменений и переключите чтение одним атомарным действием через alias или маршрутизацию.
Как понять, что новый индекс готов?
Запустите реальные запросы из логов одновременно к старому и новому индексам. Проверьте первую страницу результатов на точные совпадения, поведение фильтров, порядок сортировки и отсутствующие поля, которые меняют ранжирование. Если вы не можете объяснить большое изменение результатов — не переключайтесь.
Что мониторить сразу после переключения?
Следите за ошибками поиска, задержками (особенно p95 и p99), увеличением пустых результатов для частых запросов и пользовательскими действиями (клики, добавления в корзину), если поиск ведёт к продажам. Оставьте старый индекс на месте, чтобы быстро вернуть трафик при необходимости.
Почему смешанные старые и новые документы вызывают дрейф релевантности?
Смешанные данные заставляют похожие товары выглядеть по‑разному для правил ранжирования. Новые документы могут содержать brand, normalized_title или оценки популярности, а старые — пустые поля, поэтому движок оценивает их по разным входам и пользователи видят странный порядок.
Какие ошибки ломают поиск во время пересборки?
Команды часто меняют токенизацию без тестов на бренды и артикулы, подтягивают удалённые записи в новый индекс или направляют чтения на индексы с разной логикой ранжирования. Также легко забыть синонимы, фасеты или поля сортировки, которые живут вне основной схемы.
Сколько запросов нужно протестировать перед запуском?
Не нужно сотни тестов. Набор из ~20–30 реальных запросов обычно достаточен, если он покрывает широкие термины, точные названия продуктов, модели, опечатки и несколько крайних случаев. Повторное использование одного и того же набора на каждой пересборке помогает быстро заметить дрейф.
Когда лучше откатывать, а не настраивать новый индекс?
Откатайте, когда наблюдаются явные регрессии, а не после долгих обсуждений. Если резко выросли пустые результаты, сильно увеличилась задержка, фильтры вернули неправильные наборы или топ‑запросы потеряли очевидные совпадения — верните трафик на старый индекс и исправьте причину прежде чем пытаться снова.


