Паттерны SQLAlchemy 2.0, которые помогают избежать скрытых ошибок запросов
Паттерны SQLAlchemy 2.0 помогают растущим сервисам избегать скрытых ошибок запросов благодаря явным сессиям, типизированным моделям и более понятному потоку чтения и записи.
Содержание
Почему ошибки запросов проявляются после стадии прототипа
Обычно у прототипа один путь запроса, одна сессия базы данных и ровно столько кода, чтобы заработал happy path. Потом приложение растёт. Один файл превращается в обработчики API, фоновые задачи, админские скрипты, импорт задач и планировщики. Код для базы данных по-прежнему работает, но теперь он запускается в разных местах, с разным временем, разным жизненным циклом и разными допущениями.
Именно тогда появляются тихие баги. Обработчик читает заказ и возвращает JSON. Во время сериализации код обращается к order.customer или order.items, и SQLAlchemy запускает дополнительные запросы через ленивую загрузку. Никто не просил о дополнительной работе с базой в этот момент, но она всё равно происходит. На ноутбуке это выглядит безобидно. Под реальным трафиком такие неожиданные запросы быстро накапливаются.
Общие сессии делают ситуацию хуже, потому что границы ответственности размываются. Один хелпер открывает сессию, другой переиспользует её, а третий делает commit или rollback, не объясняя этого явно. Через несколько месяцев уже никто не понимает, какая функция владеет границей транзакции. Обычное чтение может оставить грязное состояние. Запись может произойти раньше, чем ожидалось. Баги кажутся случайными, потому что сессия живёт дольше, чем думает разработчик.
Старые вспомогательные функции часто прячут самую важную работу с базой. Функция с названием get_current_account() звучит безобидно, но она может выполнить запрос, вызвать ленивые загрузки и прикрепить объекты к долгоживущей сессии. Другой хелпер может вернуть модель, которая выглядит безопасной для передачи дальше, хотя одно обращение к атрибуту позже снова ударит по базе. Место вызова выглядит чисто. Поведение — нет.
Небольшие сервисы ещё и собирают временные обходные решения. CLI-скрипт импортирует код приложения и повторно использует логику сессий веб-запроса. Cron-задача вызывает тот же стек хелперов, но работает вне request flow. Тестовые фикстуры держат сессии открытыми дольше, чем это допустимо в production-коде. Каждый такой обход делает код чуть сложнее для понимания.
Вот почему команды сталкиваются с странным поведением запросов уже после стадии прототипа, а не во время неё. Слой базы перестаёт быть одной понятной дорогой и превращается в сеть скрытых чтений, неясной ответственности и хелперов, которые делают больше, чем обещают их названия. Именно это Python backend refactor должен убирать в первую очередь.
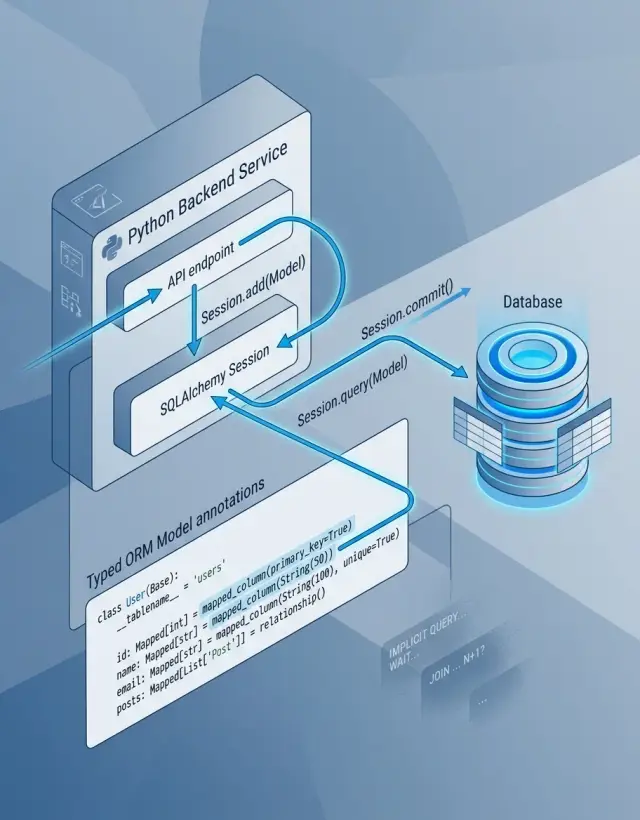
Что меняет SQLAlchemy 2.0 в повседневном коде
Сначала SQLAlchemy 2.0 кажется более строгим. Обычно это хороший компромисс. Старый ORM-код часто запихивал слишком много поведения в session.query(...), а потом ещё прятал дополнительную работу в хелперах и ленивых связях. Прототип может это пережить. Растущий сервис — уже не всегда.
# old style
user = session.query(User).filter(User.email == email).one()
# 2.0 style
stmt = select(User).where(User.email == email)
user = session.scalars(stmt).one()
Этот переход важнее, чем кажется. select() даёт объект запроса, который можно прочитать ещё до выполнения. scalars() делает форму результата очевидной: вы ждёте объекты моделей, а не кортеж строк, который меняется, когда кто-то добавляет ещё один столбец. Многие паттерны SQLAlchemy 2.0 на самом деле сводятся к одной идее: сделать намерение видимым.
Поток транзакций тоже читается лучше. В старом коде сессия часто жила слишком долго и проходила через лишние слои приложения. Кто-то добавлял запись в одном хелпере, flush в другом и commit уже на границе запроса. Когда появлялся баг, приходилось распутывать половину стека вызовов.
with Session(engine) as session:
with session.begin():
session.add(order)
session.add(audit_log)
Теперь граница видна сразу. Понятно, где начинается работа с базой, где она заканчивается и какие действия относятся к одной транзакции. Это ускоряет ревью и делает поведение rollback менее неожиданным.
Типизированные модели помогают тише, но не меньше. Когда ревьюер видит Mapped[int], Mapped[str | None] или Mapped[list[OrderItem]], ему проще понять форму модели без догадок по одним названиям столбцов. Nullable-поля, коллекции и связи перестают быть скрытыми деталями. Небольшие несоответствия видны раньше, до того как они превращаются в странные запросы или неверные joins в production.
Польза в повседневной работе простая. Обработчик строит select(), выполняет его в явной сессии и делает commit внутри понятного блока. Код говорит сам за себя. Это не убирает баги полностью, но отсеивает странные случаи, на которые обычно уходит целый день.
Задайте чёткую границу сессии
Большая часть странного поведения ORM начинается тогда, когда сессия живёт дольше самой работы. Один из самых полезных паттернов SQLAlchemy 2.0 — создавать одну сессию для одной единицы работы и быстро её завершать.
Обычно эта единица работы — один веб-запрос, одна CLI-команда или одна фоновая задача. Если держать сессию для нескольких действий подряд, старое состояние просачивается в новый код. Появляются устаревшие объекты, неожиданные flush и записи, которые происходят раньше, чем надо.
Передавайте сессию в функцию, которой она нужна. Не позволяйте хелперам открывать свою сессию за кулисами. Когда сессия приходит через аргументы функции, сразу видно, кто владеет транзакцией и где именно происходят изменения данных.
from sqlalchemy.orm import Session
def create_order(session: Session, data: dict) -> int:
order = Order(customer_id=data["customer_id"], status="new")
session.add(order)
return order.id
def handle_request(session: Session, data: dict) -> int:
try:
order_id = create_order(session, data)
session.commit()
return order_id
except Exception:
session.rollback()
raise
Commit должен находиться в write path, ближе к верхнему уровню, а не внутри маленьких хелперов. Если хелпер делает commit слишком рано, а следующий шаг ломается, вы сохраняете только половину изменения и оставляете систему в грязном состоянии. Один commit делает транзакцию понятной.
При ошибках каждый раз делайте rollback. Потом закрывайте сессию. Быстрая очистка важна, потому что сессия — это не просто удобный Python-объект. Она хранит состояние транзакции, отслеживает загруженные строки и может дольше нужного держать занятым подключение к базе.
Фоновые воркеры должны следовать тому же правилу, но со своим жизненным циклом. Воркер должен открывать свежую сессию для каждой задачи, завершать задачу, затем делать commit или rollback и закрывать сессию. Не передавайте request-сессию в task очереди и не держите одну глобальную сессию в долгоживущем воркере.
Команды, которые делают рефакторинг Python-сервисов после стадии прототипа, обычно довольно быстро видят эффект от этого изменения. Баги становится проще воспроизводить, потому что у каждого запроса или задачи есть чёткое начало и конец.
Определяйте модели через типы, а не догадки
Быстрые прототипы часто обращаются с моделями как с размытыми контейнерами. Какое-то время это работает, а потом одно nullable-поле, одна неверная связь или один скрытый default начинают подбрасывать странные запросы в растущий сервис.
SQLAlchemy 2.0 подталкивает к более строгой форме модели, и это хорошо. С DeclarativeBase, Mapped[...] и mapped_column(...) ваша модель показывает читателям, редакторам и тестам, что база данных действительно может хранить.
Модель должна говорить, что может пойти не так
Если столбец может быть пустым, типизируйте его именно так. Поле вроде shipped_at: Mapped[datetime | None] подсказывает следующему человеку, что пустой случай надо обработать. Если скрыть этот риск и написать тип так, будто значение всегда есть, баг просто переедет ниже — в фильтры запросов, сериализаторы или логику биллинга.
То же самое касается связей. Связь один-ко-многим должна выглядеть как список. Связь многие-к-одному должна выглядеть как один объект или None, если значение может отсутствовать. Это кажется мелочью, но редактор начинает ловить ошибки до запуска, например когда order.items принимают за одну строку или считают, что order.customer существует всегда.
from datetime import datetime
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column, relationship
from sqlalchemy import ForeignKey, String
class Base(DeclarativeBase):
pass
class Order(Base):
__tablename__ = "orders"
id: Mapped[int] = mapped_column(primary_key=True)
status: Mapped[str] = mapped_column(String(20), default="new")
shipped_at: Mapped[datetime | None] = mapped_column(nullable=True)
customer_id: Mapped[int | None] = mapped_column(ForeignKey("customers.id"), nullable=True)
customer: Mapped["Customer | None"] = relationship(back_populates="orders")
items: Mapped[list["OrderItem"]] = relationship(back_populates="order")
Держите default и правила столбца рядом с полем. Если у status default — new, укажите это в mapped_column. Если столбец допускает NULL, напишите об этом там же. Когда правила живут в хелперах, событиях или разбросаны по сервисному коду, люди их пропускают и строят запросы на неверных допущениях.
Это один из самых полезных паттернов SQLAlchemy 2.0, потому что он убирает догадки. Типизированная модель не только документирует схему. Она ещё и показывает, где сервис может сломаться, какие ветки нужно покрыть тестами и какие запросы требуют особой осторожности во время Python backend refactor.
Разделяйте чтение и запись
Когда одна функция и получает данные, и меняет их, ошибки прячутся в обычных путях кода. Read endpoint вызывает хелпер, чтобы «получить заказ», хелпер касается ленивой связи, запускает flush, и в базу уходит незавершённое изменение.
Более чистый паттерн скучный специально. Функции чтения только выбирают данные и возвращают их. Функции записи меняют строки и возвращают результат этого изменения. Они не смешивают роли.
Среди паттернов SQLAlchemy 2.0 этот приносит быстрый эффект в сервисах, которые начинались как быстрые прототипы. Код становится предсказуемее, а лог запросов перестаёт выглядеть случайным.
Код чтения должен загружать только то, что использует endpoint. Если список заказов показывает id, status, total и имя клиента, загружайте эти поля и только ту связь, которая нужна для имени клиента. Не тяните line items, payments и события доставки только потому, что другому экрану это может понадобиться потом. Лишние данные занимают память, а лишние связи часто вызывают ленивые загрузки в самый неудобный момент.
Код записи должен делать изменение явно. Функция вроде cancel_order(session, order_id, reason) может загрузить один заказ, обновить его статус и оставить управление commit вызывающему коду. Так timing транзакции остаётся в одном месте. Тесты тоже становятся проще, потому что именно тест решает, когда изменения попадут в базу.
Проблемы обычно начинаются с хелперов, которые выглядят безобидно:
get_or_create(...)touch_last_seen(...)ensure_customer(...)load_order_context(...)
Если хелпер может делать flush или commit, считайте его кодом записи и не пускайте в read path. Скрытые commits хуже медленных запросов, потому что они меняют данные тогда, когда никто этого не ждёт.
Такое разделение помогает и с формированием ответа. Функция чтения может вернуть компактный типизированный результат для API-ответа. Функция записи может вернуть обновлённую сущность или просто новый статус. Каждый путь остаётся коротким, и у каждого запроса есть понятная причина существовать.
В order service это часто первым делом убирает самые странные баги. Read-обработчики перестают запускать update statements. Write-обработчики перестают грузить огромные графы объектов. Когда что-то ломается, вы сразу знаете, где искать.
Небольшой order service до и после
Типичный route для заказа в прототипе часто выглядит нормально в быстром тесте. Он загружает один заказ, возвращает пару полей, и никто не замечает, что код ответа тихо просит базу о дополнительных данных после первого запроса.
from sqlalchemy import select
def get_order(order_id: int, session: Session) -> dict:
order = session.scalar(
select(Order).where(Order.id == order_id)
)
if order is None:
raise NotFoundError()
return {
"id": order.id,
"status": order.status,
"items": [
{"sku": item.sku, "qty": item.qty}
for item in order.items
],
"total": sum(item.price_cents * item.qty for item in order.items),
}
Этот route начинает с одного запроса к Order. Потом начинаются проблемы. Когда код обращается к order.items, SQLAlchemy может сделать ещё один запрос, чтобы лениво загрузить связь. Если другая часть ответа затронет ещё одну связь, появится ещё один. Небольшой builder ответа легко превращается в набор скрытых round trips.
Ситуация становится хуже, когда route разрастается. Сериализатор, логгер или шаблон могут обращаться к атрибутам далеко от исходного запроса. Вы читаете функцию сверху вниз, но реальная работа с базой происходит в разбросанных местах.
Более чистая версия заранее загружает всё необходимое и держит работу внутри одной границы сессии.
from sqlalchemy import select
from sqlalchemy.orm import selectinload
def get_order(order_id: int, session: Session) -> dict:
stmt = (
select(Order)
.options(selectinload(Order.items))
.where(Order.id == order_id)
)
order = session.scalar(stmt)
if order is None:
raise NotFoundError()
items = [
{"sku": item.sku, "qty": item.qty}
for item in order.items
]
total = sum(item.price_cents * item.qty for item in order.items)
return {
"id": order.id,
"status": order.status,
"items": items,
"total": total,
}
Теперь route заранее показывает, что ему нужно, прежде чем собирать ответ. Сессия остаётся явной, связь загружается намеренно, а возвращаемые данные не вызывают неожиданных запросов позже.
Такой стиль становится особенно важным по мере роста сервиса. Его проще тестировать, проще ревьюить и гораздо легче понимать, когда в production появляется медленный endpoint. Для команд, которые приводят в порядок старый Python backend refactor, такой шаг убирает много путаницы без изменения бизнес-логики.
Ошибки, которые всё ещё вызывают странные запросы
Даже если вы перешли на более чистые паттерны SQLAlchemy 2.0, несколько привычек всё ещё могут порождать странный трафик к базе. Эти баги часто прячутся в коде, который выглядит безобидно, а потом проявляются как случайные замедления, устаревшие данные или записи, которые происходят раньше, чем вы ожидали.
Одна из частых проблем — повторное использование одной и той же сессии для многих запросов. Сессия хранит состояние объектов в памяти. Если запрос A загружает заказ, а запрос B позже касается той же сессии, можно получить старые данные, неожиданные обновления или запутанные чтения из identity map вместо базы. В веб-сервисе один запрос должен владеть одной сессией.
Ещё одна ловушка появляется, когда код ответа обращается к ленивым связям уже после закрытия сессии. Допустим, handler возвращает заказ, а сериализатор читает order.customer.name или проходит по order.items. Если эти связи не были загружены намеренно, SQLAlchemy может попытаться достать их в самый неподходящий момент, либо вообще упасть, потому что живой сессии уже нет. Загружайте нужные связи в запросе, а потом превращайте результат в обычные данные до выхода из request flow.
Долгоживущие кэши создают похожие проблемы. Хранить ORM-объекты в Redis, памяти или модульном кэше кажется удобным, но эти объекты несут состояние сессии и предположения о том, что уже загружено. Спустя часы одно обращение к атрибуту может вызвать неожиданный запрос или вернуть устаревшее значение. Лучше кэшировать ID или обычные dict.
Неявные flush тоже мешают командам, которые смешивают бизнес-правила с объектами базы. Запрос может запустить autoflush раньше, чем вы собирались что-то сохранять. Это быстро становится грязным, когда правило проверяет остаток на складе, создаёт позицию, а потом в том же блоке выполняет ещё один запрос. Держите проверки правил отдельно от записей и вызывайте flush() только тогда, когда действительно хотите отправить pending changes в базу.
Стандартная загрузка связей — ещё один тихий источник странного поведения. Если API-код проходит по 50 заказам и читает order.items по одному, вы получаете классическую проблему N+1.
Следите за такими признаками:
- Список-эндпоинт становится медленнее по мере роста числа строк
- Сериализатор падает вне границ request scope
- Кэш возвращает объекты с недостающими полями
- Проверка только на чтение случайно записывает данные
Большинство скрытых ошибок запросов сводится к одному правилу: запрос должен заранее говорить, что ему нужно. Код ответа не должен решать это позже.
Быстрые проверки во время ревью
Когда Python-сервис начинает вести себя странно, исправление часто приходит из короткого code review, а не из большого переписывания. Большинство скрытых ORM-багов связано с неясной ответственностью: одна функция открывает сессию, другая делает commit, третья вызывает ленивую загрузку, и никто не замечает этого, пока production-трафик не начнёт всё проявлять.
Используйте короткий чек-лист и прогоняйте его по одному пути запроса за раз.
- Пройдите по write path и найдите единственный commit. Если нельзя указать одно понятное место, где транзакция заканчивается, поток всё ещё размытый. Два commit в одном вызове сервиса часто означают частичные обновления и сложные для воспроизведения падения.
- Сравните типы модели с правилами базы. Если столбец может быть null, Python-тип должен это показывать. Если база сама заполняет default, модель не должна делать вид, что приложение всегда задаёт его первым.
- Посмотрите на каждую сервисную функцию, которая трогает базу. Она должна либо принимать сессию от вызывающего кода, либо явно создавать и закрывать её сама. Скрытое создание сессии внутри хелперов — частый источник странного состояния и неожиданных запросов.
- Проверьте тесты для нагруженных путей и считайте не только результаты, но и запросы. Тест, который доказывает, что «этот endpoint выполняется за 3 запроса», ловит ленивые загрузки раньше пользователей.
- Прочитайте запрос и спросите себя, какие связи он загружает заранее. Новый член команды должен видеть это прямо из кода, без догадок. Если ответ зависит от default'ов ORM, код всё ещё слишком неявный.
Такой ревью-подход работает хорошо, потому что он конкретный. Вы не спрашиваете, выглядит ли код «чисто». Вы спрашиваете, может ли человек проследить одну сессию, одну транзакцию и один план загрузки, не открывая пять файлов.
Именно здесь паттерны SQLAlchemy 2.0 помогают сильнее всего. Они делают правильную форму кода проще для ревью. Если коллега может открыть одну сервисную функцию и сразу сказать, где начинается сессия, где она заканчивается и какие строки будут загружены, вы уже убрали массу будущих багов до релиза.
Что стоит почистить следующим
Не начинайте с полного переписывания. Выберите один endpoint, который уже болит: медленную страницу заказа, фоновую задачу со странными дублями запросов или handler, который иногда возвращает устаревшие данные. Один шумный путь учит лучше, чем неделя абстрактных задач на cleanup.
Перед тем как рефакторить этот путь, добавьте маленький тест, который считает запросы для одного обычного запроса и одного edge case. Это звучит скучно, но потом экономит часы. Когда число запросов растёт после изменения, вы ловите скрытые ленивые загрузки и лишние refresh до того, как они попадут в production.
Хорошо работает простой порядок очистки:
- выберите один endpoint с заметным шумом запросов
- добавьте тесты на количество запросов вокруг его основного потока
- сделайте границу сессии в этом потоке очевидной
- замените предполагаемые поля модели на типизированные там, где до них дотрагивается запрос
После этого напишите короткое правило для команды и держите его рядом с чек-листом code review. Оно не обязано быть сложным. Одной страницы достаточно, если она ясно отвечает на три вопроса: кто создаёт сессию, кто может делать commit и когда код может загружать связанные строки.
Для многих команд это правило звучит примерно так: один запрос или одна задача получает одну сессию, service code владеет commit, а связи загружаются только тогда, когда этого просит запрос. Одного этого уже хватает, чтобы убрать много случайного поведения. И тогда паттерны SQLAlchemy 2.0 ощущаются не строгими, а просто последовательными.
Если сервис рос через быстрые исправления, не стоит ждать, что cleanup обязательно произойдёт сразу целиком. Обычно лучше работает поэтапный план. Исправьте самый загруженный путь, перенесите подход ещё на два-три похожих handler'а, а потом удалите старые shortcuts.
Иногда помогает внешний разбор, особенно когда команда чувствует беспорядок, но не может договориться о первом шаге. Oleg Sotnikov работает со стартапами и небольшими командами над практичной очисткой backend и архитектуры, поэтому короткий разбор может превратить расплывчатый рефакторинг в небольшой план с понятными шагами, владельцами и границами.
Такой план легче завершить, а законченный cleanup всегда лучше идеального.


