Паттерны релизов GitLab для растущих команд
Паттерны релизов GitLab для монорепозитория помогают командам использовать теги, карты сервисов и scopes изменений, чтобы каждый релиз оставался понятным по мере роста репозитория.
Содержание
Почему релизы в одном репозитории начинают путать
Сначала монорепозиторий кажется удобным. Все лежит в одном месте, и это ощущается проще, чем куча отдельных репозиториев. Потом команда растет, релизы становятся чаще, и один merge уже затрагивает сразу несколько частей системы.
Один commit может обновить API, изменить общую библиотеку, подправить billing worker и скорректировать скрипт деплоя. Для монорепозитория это нормально. Проблема начинается, когда в релизной заметке указано только v2.14.0 и больше ничего. Люди видят, что что-то вышло, но не понимают, что именно изменилось в каждом сервисе.
Этот пробел быстро съедает время. Продукт спрашивает, вышел ли customer portal. Поддержка хочет понять, дошло ли исправление бага до production. Инженеры открывают логи коммитов, смотрят пайплайны и пишут друг другу, чтобы ответить на простой вопрос: что вышло и где?
Номера версий делают ситуацию еще хуже, если команда начинает считать весь репозиторий одним приложением. Один номер может скрывать десять изменений с очень разным уровнем риска. Небольшой фикс в одном сервисе стоит рядом со сменой схемы в другом, но по релизному ярлыку они выглядят одинаково.
Откаты тоже становятся запутанными по той же причине. Если никто не видит полный радиус влияния, люди начинают сомневаться. Откатывать весь репозиторий или только один сервис? Это общая package сломала два downstream-приложения или только одно? Такие решения принимаются медленно, когда история релизов читается как размытое пятно.
Представьте репозиторий с auth, billing и notifications. В пятничный релиз входят новое правило входа, исправление налога и изменение retry для неудачных писем. К понедельнику в billing возникает проблема. Без понятных тегов, change scopes или карты зависимостей команда копается в merge-записях вместо того, чтобы чинить баг.
Вот почему release patterns так важны в GitLab монорепозитории. По мере роста репозитория команде нужны релизы, которые объясняют сами себя, а не просто пайплайны с зеленым статусом.
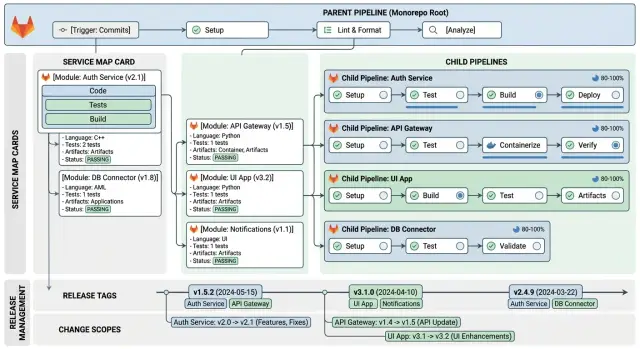
Начните с карты сервисов
Монорепозиторий становится запутанным, когда никто не согласовал, что и где лежит. Прежде чем думать о parent-child pipelines, тегах или change scopes, опишите структуру репозитория простыми словами.
Service map не должен быть сложным. Это всего лишь небольшой документ, который показывает команде, какие папки относятся к какому сервису, package или общей области кода. Когда меняется папка, люди должны понимать, кого это касается, без догадок.
Для каждой записи держите четыре вещи понятными:
- название сервиса или package
- папки, которые к нему относятся
- владелец — один человек или одна команда
- общие папки, от которых он зависит
Владение важнее, чем многие команды ожидают. Если в релиз входят изменения в общей библиотеке, кто-то должен решить, влияет ли это на один сервис, на пять сервисов или на весь репозиторий. Если ответственность размыта, релизные заметки превращаются в расследование.
Сопоставление по папкам экономит время и в CI. Parent pipeline может отправить работу в нужный child pipeline только если команда уже знает, что services/payments/ относится к одному сервису, packages/ui/ — к нескольким приложениям, а infra/ — к деплою, а не к коду приложения. Без такой карты каждый релиз кажется больше, чем он есть на самом деле.
Держите карту рядом с репозиторием и обновляйте ее, когда меняется структура. Добавляйте новые workers в карту в тот же день, когда они появляются. Если общая папка делится надвое, сразу обновите затронутые сервисы. Если package переименовали, исправьте карту до того, как кто-то начнет использовать новое имя в CI.
Работа скучная. Но она быстро окупается. Команды перестают спорить о scope, владельцы раньше замечают рискованные изменения, а релизные теги становятся понятнее, потому что все используют одни и те же названия для одних и тех же частей репозитория.
Разделяйте работу с помощью parent и child pipelines
Один большой пайплайн быстро становится шумным, если в одном репозитории живет много сервисов. Более аккуратный подход простой: пусть parent pipeline определяет, что изменилось, а затем запускает child pipelines только для тех сервисов, которым нужна работа.
Parent pipeline должен сначала выполнить недорогие общие проверки. Он может посмотреть на измененные пути, проверить правила для веток и тегов, а также запустить общие jobs для всего репозитория, например проверку lockfile или быструю валидацию общих build-скриптов. Это делается один раз, а не отдельно для каждого сервиса.
После этого parent pipeline создает по одному child pipeline для каждого затронутого сервиса. Если commit затрагивает api/ и worker/, GitLab запускает два child pipeline и игнорирует все остальное. Уже одно это делает релизный вид намного понятнее.
Обычно достаточно простого разделения:
- Parent pipeline проверяет измененные папки и правила релиза.
- Parent запускает общие проверки один раз.
- Каждый затронутый сервис получает свой child pipeline.
- Каждый child pipeline отвечает за тесты, сборку и деплой этого сервиса.
Ошибки становятся гораздо легче для чтения. Если ломается payments, падает child pipeline payments. Search остается зеленым и не мешает картине. Звучит мелко, но в день релиза это экономит заметное количество времени.
Логику сервиса лучше держать внутри child pipeline, даже если jobs выглядят похожими. Тесты, сборка образа, migrations и шаги деплоя должны находиться рядом с сервисом, который они меняют. Общая логика, конечно, тоже нужна, но ей место в переиспользуемых шаблонах, а не в одном огромном parent-файле, перегруженном всеми правилами репозитория.
Для растущих команд это один из самых полезных монорепо-паттернов в GitLab. У вас остается один верхний уровень управления и более маленький пайплайн для каждого сервиса. Репозиторий может расти, а процесс релиза все еще остается понятным для тех, кто его читает.
Настройте поток пошагово
Начните с того, что зафиксируйте названия в репозитории. У каждого сервиса должно быть одно понятное имя, одна папка и одна метка, которая везде остается одинаковой. Если сервис живет в services/billing, называйте его billing в service map, в именах jobs и в релизных тегах. Команды путаются, когда одно и то же приложение называется по-разному в зависимости от места.
Небольшой service map в YAML или JSON вполне подойдет. В нем можно перечислить каждый сервис, его папку и child pipeline file, который он использует. Parent pipeline читает эту карту, смотрит на измененные пути и решает, какие child pipelines запускать. Так логика остается в одном месте, а не расползается по множеству CI-файлов.
Path rules должны быть узкими. Сначала сопоставляйте папку сервиса, а общие области добавляйте только тогда, когда они действительно влияют на этот сервис. Если меняется libs/auth, и его используют и api, и admin, обязательно укажите это в карте. Но если каждый общий файл запускает каждый сервис, вся схема перестает быть полезной.
Порядок важен. Сначала закрепите названия сервисов и пути к папкам, а уже потом пишите CI rules. Затем добавьте path rules. Генерируйте child pipeline jobs из service map, а не прописывайте их вручную в нескольких местах. После этого протестируйте поток на ветке с несколькими небольшими commit'ами, прежде чем создавать первый настоящий тег.
Такое тестирование на ветке помогает поймать большую часть ошибок заранее. Сделайте один commit, который меняет только один сервис. Сделайте другой, который затрагивает общую папку. Parent pipeline должен запустить только те child jobs, которые вы ожидаете. Если он запускает все подряд, scope слишком широкий. Если он пропускает изменившийся сервис, path rules слишком узкие.
Правила согласования тоже важны. Держите в репозитории короткий файл с владельцем каждого релизного тега. Один человек утверждает billing-*, другой — api-*, а запасной владелец подключается, когда нужно. Даже в маленькой команде это экономит время и убирает споры в напряженный день релиза.
Используйте теги, которые говорят, что вышло
Хорошие теги снимают много догадок. Они должны быстро отвечать на один вопрос: что изменилось и где?
Выберите один формат заранее и держите его простым. Тег должен легко читаться в списке коммитов, легко сортироваться и легко произноситься в чате. Для релизов всего репозитория хорошо работают даты. Semantic versions удобны для сервисных релизов, если у каждого сервиса своя история версий.
Несколько простых примеров:
repo-2026.04.13.1для релиза всего репозиторияbilling-v1.12.0для одного сервисаauth-v2.0.0для одного сервиса с собственной линией версийweb-v0.9.5для frontend-приложения в том же репозитории
Держите теги всего репозитория и теги сервисов отдельно. Одно это правило сильно снижает путаницу в будущем. Репозиторный тег показывает состояние всего монорепозитория в один момент. Сервисный тег говорит, что одна часть готова к выпуску, даже если больше ничего не менялось.
В каждом сервисном теге указывайте название сервиса. Не полагайтесь на имена папок, веток или релизных заметок, чтобы люди сами догадались. Если кто-то видит v1.7.3, не должен звучать вопрос: «для какого сервиса это?» А вот search-v1.7.3 сразу все объясняет.
Для breaking changes нужен еще один намек. Оставьте имя тега простым, а затем добавьте короткую заметку в annotated tag или release note. «BREAKING: payment callback payload changed» вполне достаточно. Люди, которые поддерживают другой сервис, мобильное приложение или внешнюю интеграцию, заметят риск до деплоя.
Небольшая команда с тремя сервисами может какое-то время жить и без этого. Но потом проходят шесть месяцев, релизы ускоряются, и никто уже не помнит, пришел ли v2.3.1 из API, web или worker. Понятные теги экономят это время каждую неделю.
Определяйте scopes изменений перед каждым релизом
Релизы становится трудно читать, когда команда группирует изменения по тому, кто над ними работал. Лучше группировать их по сервисам. «Payments API», «admin app» и «email worker» говорят людям гораздо больше, чем «backend» или «frontend».
Этот простой сдвиг помогает всем. Инженеры понимают, что тестировать. Продукт видит, что изменилось. Поддержка может понять, откуда взялась проблема, если что-то пошло не так после деплоя.
Каждое изменение в scope стоит также описать по типу. Код, конфиг, schema и docs несут разный риск. Обновление конфига может потребовать новых секретов. Изменение schema может задать порядок деплоя. Изменения в документации обычно вообще не влияют на runtime.
Короткая scope-заметка часто полезнее длинного changelog. Назовите сервис, тип изменения, общий package, если он есть, и отметьте порядок rollout, если несколько сервисов должны двигаться вместе.
Общие библиотеки требуют особого внимания. Если один internal package влияет на пять сервисов, выделите его как отдельный scope item. Иначе небольшое обновление helper'а может выглядеть безобидно в теге, но изменить поведение в половине репозитория.
Нотатки про согласованный rollout не менее важны. Если один сервис начинает отправлять новый формат события, другой сервис должен уметь его читать до переключения трафика. То же самое относится к database migrations, feature flags, queue format и auth changes. Запишите порядок заранее, пока готовите релиз, а не после того, как что-то сломалось.
Хорошие scope-notes звучат просто. «Catalog service — schema and code. Run migration before deploy.» Или: «Shared auth library — affects API and admin app. Deploy both in the same window.» Для растущего монорепозитория этого достаточно. Это делает релизные теги читаемыми и спасает команду от разбора истории коммитов под давлением.
Простой пример с тремя сервисами
Представьте один репозиторий с тремя частями: web app, billing service и общим auth module. Код хранится вместе, но каждая часть выходит по своему графику. Именно здесь грамотная схема релизов в GitLab начинает казаться понятной, а не хаотичной.
Небольшое изменение в web должно остаться небольшим. Если разработчик исправляет верстку checkout в web app и затрагивает только apps/web, parent pipeline смотрит на service map, видит, что scope — web, и запускает только child pipeline для web. Billing и auth ничего не делают.
Теперь возьмем баг в billing. Допустим, округление налога в invoice работает неверно в одной стране, и исправление лежит только в services/billing. Пайплайн запускает billing-тесты, собирает billing artifact, а команда создает тег вроде billing-v1.8.2. Репозиторный тег при этом не создается, потому что весь репозиторий не выпускался как единое целое. Этот небольшой выбор позже избавляет от множества недоразумений.
Общий код требует другого правила. Если кто-то обновляет auth module в libs/auth, service map уже должен показывать, какие сервисы от него зависят. В этом примере auth используют и web app, и billing, поэтому parent pipeline запускает два child pipeline вместе: web и billing.
Релизная заметка должна отражать этот общий scope, а не делать вид, что это два независимых релиза. Достаточно такой короткой записи:
- Scope: auth update
- Web: исправлен refresh token при входе
- Billing: исправлена проверка сессии во время оплаты
Это показывает команде, что в общем коде произошло одно изменение, а два сервиса вышли из-за него. Даже через несколько месяцев будет понятно, почему существуют оба тега.
Ошибки, из-за которых релизы трудно читать
Большинство нечитаемых релизов возникают не из-за кода, а из-за имен. Пайплайн может пройти успешно, сервисы могут задеплоиться, а люди все равно уйдут с ощущением, что они не понимают, что изменилось.
Самый быстрый способ создать шум — тегировать каждый commit. Сначала это кажется аккуратным. Через неделю у вас уже куча тегов, которые отличаются одним маленьким исправлением, одной документацией или повторным запуском того же child pipeline. Никто не хочет читать такую историю. Релизный тег должен отмечать событие, которое можно понять и обсудить, а не каждый push.
Следующий беспорядок создают названия. Если релизная заметка говорит apps/api-v2/internal вместо billing service, читателю сначала приходится расшифровать репозиторий, а только потом — релиз. Пути папок помогают CI rules. Они не помогают product manager'ам, support staff или разработчикам из другой части системы. Используйте названия сервисов в тегах, заметках и дашбордах. Пути папок оставьте в CI config там, где им и место.
Общий код создает более тихую, но упрямую проблему. В монорепозитории common packages часто лежат между несколькими сервисами. Когда за этот общий код никто не отвечает, команды спорят, относится ли релиз к auth, billing или platform. Обычно этот спор начинается уже после поломки. Назначьте владельца и релизную метку для общих частей до того, как это случится.
Scope labels тоже могут испортить релизные заметки. Если «minor» на этой неделе значит «небольшое изменение интерфейса», а на следующей — «безопасное изменение backend», такой ярлык бесполезен. То же самое относится к labels вроде «infra», «internal» или «ops», если команды используют их слишком свободно. Parent-child pipelines работают лучше, когда scope names остаются простыми и постоянными.
Читаемые релизы обычно похожи друг на друга по нескольким признакам: один тег на одно релизное событие, названия сервисов, которые совпадают с тем, как люди говорят о системе, понятная ответственность за shared modules и scope labels с одним стабильным значением.
Когда теги, service map и scopes расходятся, каждый релиз начинает казаться больше и туманнее, чем он есть на самом деле.
Быстрая проверка перед выпуском релиза
Релиз быстро становится запутанным, если тег говорит одно, а diff — другое. Перед тем как пушить тег, сравните измененные пути со своей service map и задайте простой вопрос: какие сервисы действительно изменились?
Читайте diff, а не только заголовок merge request. Сервисный тег должен указывать на файлы, конфиги и тесты, которые относятся к этому сервису. Если изменения затрагивают общий package, общую schema или deployment template, добавьте в scope релиза все зависимые сервисы. Потом прочитайте релизную заметку глазами человека из поддержки или продукта. Используйте те названия сервисов, которые люди уже применяют в ежедневной работе, а не сокращения папок или старые кодовые имена.
Также стоит заранее проверить шаги отката для каждого тегированного сервиса, прежде чем релиз уйдет в прод. Нужно понимать, какой image, config, feature flag или migration вы будете откатывать. Такая проверка занимает всего несколько минут, а экономит намного больше времени, если что-то ломается поздно вечером.
Небольшой пример делает это наглядным. Допустим, изменились services/users, libs/auth, а services/marketing-site не менялся. Релиз должен назвать users service и любой другой сервис, который зависит от общего auth-кода. Но marketing site в него включать не надо. Если в заметках написано auth-lib-v2, а команда называет это «login service», люди не поймут масштаб влияния.
Чистые теги, понятные названия сервисов и явные заметки по откату делают parent-child pipelines более надежными. Люди видят, что вышло, кто за это отвечает и что нужно откатить, если релиз придется остановить.
Что делать дальше
Начните с малого. Одна service map и один формат тегов уберут больше путаницы, чем еще один уровень pipeline YAML.
Эти release patterns работают лучше всего, когда названия, scopes и пути пайплайнов совпадают. Если эти три вещи расходятся, каждая релизная заметка начинает выглядеть как догадка.
Практичный первый шаг прост. Составьте service map для каждого разворачиваемого сервиса, его владельца и пути папки, который его запускает. Выберите один формат тега, который люди могут прочитать за секунду, например billing-v1.8.0 или web-v2.3.1. Добавьте change scopes до того, как усложнять parent-child логику. Затем посмотрите на релизы за последний месяц и удалите ярлыки, которыми никто не пользуется.
Этот порядок важен. Команды часто сначала строят умную логику пайплайнов, а потом понимают, что никто не согласован в том, что изменилось и что означает тег. В итоге автоматизации больше, а ясности меньше.
Держите service map простой. Таблицы в репозитории достаточно. Если разработчик меняет services/auth, он должен сразу понимать, какой пайплайн запустится, какой тег применится и входит ли это изменение в следующий релизный scope.
Будьте строже с labels. Если люди не могут объяснить scope одной короткой фразой, он слишком расплывчатый. «Auth fix» — понятно. «Platform improvements» обычно ничего никому не говорит.
Через несколько недель вернитесь к недавним релизам. Посмотрите, какие теги помогли во время тестирования, откатов или вопросов в поддержку. Остальные уберите. Более короткий релизный словарь проще поддерживать в порядке.
Если ваша GitLab-настройка постоянно усложняется, полезен свежий внешний взгляд. Oleg Sotnikov на oleg.is работает как Fractional CTO и startup advisor, и именно такой дизайн релизов хорошо ложится на его опыт в CI/CD, границах сервисов и lean production systems.
Лучший следующий шаг обычно самый скучный: четко называйте сервисы, тегируйте только то, что действительно вышло, и делайте каждый scope легко читаемым.
Часто задаваемые вопросы
С чего начать, чтобы релизы в монорепозитории стали понятнее?
Начните с простой service map в репозитории. Для каждого сервиса укажите папку, владельца и общий код, от которого он зависит, чтобы люди перестали гадать, на что повлияет изменение.
Когда лучше использовать тег для всего репозитория, а когда — тег сервиса?
Используйте репозиторный тег только тогда, когда выпускаете весь монорепозиторий как одно релизное событие. Если отдельно выходит один сервис, создайте сервисный тег вроде billing-v1.8.2, чтобы всем было понятно, что именно ушло в релиз.
Зачем использовать parent и child pipelines в GitLab монорепозитории?
Parent pipeline проверяет измененные пути и правила репозитория, а затем запускает дочерние пайплайны только для затронутых сервисов. Так релиз становится компактнее, а ошибку проще привязать к одному сервису.
Какой формат имени тега считается хорошим?
В каждом сервисном теге указывайте название сервиса и используйте один формат везде. Теги вроде search-v1.7.3 или repo-2026.04.13.1 сразу показывают, что именно вышло, без просмотра истории коммитов.
Как работать с релизами, когда меняются общие библиотеки?
Относитесь к общему коду как к отдельному релизному scope и называйте все сервисы, которые от него зависят. Если меняется libs/auth, а его используют и web, и billing, запускайте оба пайплайна и укажите это в релизной заметке.
Что должно входить в change scope?
Пишите scope по сервисам, а не по командам или путям в папках. Короткая заметка вроде Catalog service: schema and code. Run migration before deploy. дает инженерам, продукту и поддержке достаточно контекста быстро.
Как не дать именам запутать релизы?
Выберите одно понятное имя для каждого сервиса и используйте его в service map, именах задач и тегах. Если services/billing называется billing, не зовите его где-то еще payments-api, иначе релизные заметки начнут путать людей.
Нужно ли тегировать каждый коммит в монорепозитории?
Нет. Тегирование каждого коммита создает шум и делает историю релизов труднее для чтения. Помечайте теги релизных событий, которые можно объяснить одной фразой, а не каждый push или повторный запуск.
Нужны ли правила согласования для релизов сервисов?
Да, держите в репозитории короткий файл с владельцами и назначайте по одному человеку или команде на каждый шаблон сервисного тега. Когда релизный день становится напряженным, понятная ответственность ускоряет согласования и убирает споры.
Что стоит проверить прямо перед выпуском релиза?
Проверьте diff по вашей service map, убедитесь, какие сервисы изменились, и заранее посмотрите шаги отката для каждого из них. Это занимает несколько минут и дает команде понятный план, если деплой пойдет не так.


