Паттерн репозитория для тестирования без тяжёлой стены абстракций
Паттерн репозитория для тестирования даёт чистые швы для модульных тестов без обёртки каждой операции в шаблонный код. Узнайте, когда его добавить и когда остановиться.
Содержание
Почему доступ к данным быстро становится запутанным
Большинство кодовых баз не запутывается потому, что кто‑то так задумал. Обычно всё начинается с одного метода сервиса, который загружает запись, проверяет несколько полей, что‑то обновляет и возвращает ответ. Через неделю в том же методе уже SQL, логика ретраев, проверки на null, правила ценообразования и специальный кейс для одного клиента.
Именно такое смешение — настоящая проблема. Код запросов и бизнес‑правила оказываются в одном месте, поэтому любое изменение кажется большим. Если вы хотите протестировать правило скидки, часто нужен реальный ряд в базе, правильные джойны и много настройки, не относящейся к самому правилу.
Изменения схемы только усугубляют ситуацию. Переименовали колонку, разбили таблицу или изменили способ загрузки связи — и тесты падают по нескольким сервисам. Бизнес‑действие не поменялось, но тесты знают слишком много о деталях хранения. Вы правите один запрос, а оставшийся час тратите на фикс фикстур, моков и повторяющейся настройки.
Скопированные запросы тоже тихо размножаются. Один запрос работает, кто‑то копирует его в другой сервис с небольшой правкой. Потом снова. Вскоре у вас четыре версии одного и того же поиска, каждая с чуть другим фильтром или набранными полями. Когда нужно изменить запрос, никто не уверен, какая версия безопасна.
Малые команды сталкиваются с этим рано. Вы двигаетесь быстро, поэтому размещаете доступ к данным там, где идёт работа. Это нормально. Проблемы начинаются, когда одно бизнес‑правило появляется в нескольких местах, и каждое место обращается к базе немного по‑своему.
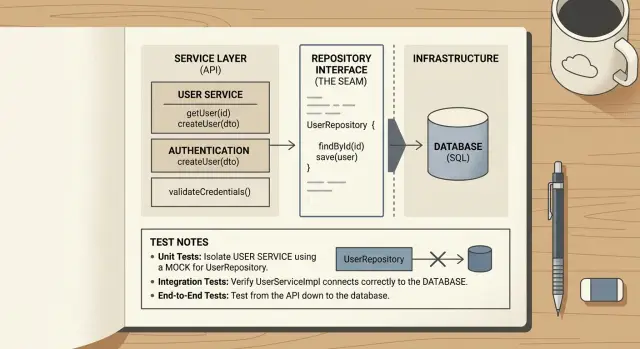
Небольшой шов начинает окупаться в очень конкретный момент: когда вы хотите протестировать поведение, не заботясь о том, как данные были получены. Часто это первый признак, что нужен тонкий граница. Не огромный слой доступа к данным. Не стена интерфейсов. Просто одно место, где сервис запрашивает данные в стабильном виде.
Именно поэтому тонкий репозиторий может помочь, даже если вы планируете удалить его позже. Шов даёт одно место для правок при изменении таблиц и одну простую зависимость для замены в тестах. Иногда этого достаточно, чтобы остановить распространение хаоса.
Что должен делать тонкий репозиторий
Тонкий репозиторий даёт один чистый шов между кодом приложения и базой данных. Он не должен превращаться во второе приложение внутри вашего приложения. Цель проста: сделать доступ к базе лёгким для замены в тестах и простым для чтения в продакшене.
Держите код запросов рядом с клиентом базы данных. Репозиторий должен уметь вызывать ORM, строить SQL, биндинговать параметры и маппить строки. Эта работа принадлежит инструменту, который с этим работает.
Бизнес‑решения должны оставаться вне репозитория. Репозиторий не должен решать, можно ли отправить заказ, нужно ли повторять платёж или давать ли клиенту возврат. Эти решения поместите в слой сервисов или use case, там, где уже живут правила.
Хороший тонкий репозиторий возвращает простые данные приложения. Это может быть небольшой struct, запись или простой объект с полями, которые действительно используются в приложении. С тестами работать проще, когда они оперируют простыми данными, а не ORM‑объектами с ленивой загрузкой, скрытым состоянием и неожиданными вызовами к базе.
Такая простая форма возврата также облегчает рефакторинг. Если вы смените ORM, перепишете запрос или переведёте одно чтение на сырой SQL, остальной код приложения не должен об этом знать. Шов остаётся прежним.
Тонкие репозитории также дают небольшое обещание. Метод вроде findOrderById(id) или savePayment(payment) легко понять. Метод вроде processOverdueInvoicesAndNotifyUsers() уже пересёк грань. Он смешивает хранение с поведением приложения и тяжело тестируется по нужной причине.
Ещё одно правило: останавливайтесь рано. Не нужен полный слой доступа к данным для каждой таблицы в день ноль. Постройте один репозиторий там, где тесты причиняют боль, где запросы повторяются или где ORM протекает в слишком многие файлы.
Если этот первый шов экономит время, оставьте его. Если остальной код по‑прежнему понятен, не трогайте. Репозиторий, который можно удалить позже, обычно лучше грандиозного слоя абстракций, который вам придётся защищать годами.
Выберите один шов и оставьте остальное в покое
Когда тесты причиняют боль, ответ редко
Часто задаваемые вопросы
Do I need a repository for every table?
Нет. Начните с той части, которая вызывает боль в тестах, где повторяются запросы или где код ORM разбросан по нескольким файлам. Если остальной код по-прежнему легко читается, оставьте его как есть.
What makes a repository thin?
Тонкий репозиторий лишь занимается доступом к данным. Он строит запросы, общается с клиентом базы данных и преобразует результаты в простые данные приложения. Как только он начинает принимать продуктовые решения, он перестаёт быть тонким.
Where should business logic go?
Деловая логика должна жить в сервисах или коде use case. Именно там принимаются решения вроде возврата денег, ретраев или возможности отправки заказа. Репозиторий лишь получает и сохраняет данные, необходимые этим правилам.
What should a repository return?
Возвращайте простые данные, понятные приложению, например небольшой объект или запись с полями, которые вы используете. Это упрощает тесты и предотвращает утечку состояния ORM или ленивой загрузки в остальной код.
How does a repository help with testing?
Вы можете заменить репозиторий фэйком или стабом и тестировать поведение, не настраивая реальные таблицы, джойны и фикстуры. Так вы тестируете правило, а не настройку хранения.
When should I add the first repository?
Добавьте его, когда сервис смешивает SQL с бизнес-правилами, когда один и тот же запрос встречается в нескольких местах или когда изменения схемы ломают слишком много тестов. Это хорошие признаки, что один маленький шов сэкономит время.
Can I still use my ORM directly?
Да. Если прямой вызов ORM остаётся понятным и локальным, оставьте так. Репозиторий нужен там, где нужен стабильный шов, а не для каждой операции чтения и записи по умолчанию.
Can I delete the repository later?
Да. И это часто хороший знак. Если шов перестал приносить пользу, удалите его. Небольшой репозиторий должен облегчать изменения, а не превращаться в то, что вы храните только потому, что он существует.
What happens when the schema changes?
Репозиторий даёт одно место для правок при изменении таблиц, колонок или связей. Код сервисов и многие тесты остаются прежними, потому что они зависят от формы данных репозитория, а не от деталей хранения.
How do I know a repository got too big?
Следите за методами, которые делают больше, чем загрузку или сохранение данных. Если репозиторий начинает отправлять письма, применять правила ценообразования или связывать несколько продуктовых действий, верните эту логику в сервис и оставьте репозиторий маленьким.


