Партиционирование Postgres для аудиторских таблиц и журналов событий
Партиционирование Postgres для таблиц аудита работает лучше всего, когда вы заранее задаёте правила хранения и шаблоны запросов. Планируйте размеры, запуск и очистку до того, как начнётся боль в эксплуатации.
Содержание
Почему эти таблицы становятся проблемой
Таблицы аудита и событий растут совсем не так, как большинство продуктовых таблиц. Профиль клиента меняется время от времени. Таблица событий может добавлять строку при каждом входе в систему, API-вызове, запуске задания, webhook-событии или изменении прав доступа.
Эта разница быстро становится дорогой. У продукта могут быть несколько миллионов бизнес-записей, и при этом он всё равно ощущается управляемым, а его журнал аудита незаметно уходит далеко за сотни миллионов строк.
Команды тоже используют эти данные очень неравномерно. Они постоянно проверяют последние часы или дни для работы поддержки, отладки, разбирательств по биллингу и проверок безопасности. Старые записи часто лежат нетронутыми, пока кому-то не понадобится расследовать один конкретный инцидент.
Этот шаблон доступа важен, потому что большие таблицы вредят не только чтению. Они ещё и утяжеляют обычное обслуживание. Удаление старых строк создаёт лишнюю активность. Vacuum получает больше работы. Индексы раздуваются. Бэкапы, восстановление и репликация тащат за собой данные, которые почти никто не читает.
Знакомая картина выглядит так: продуктовая команда каждый день открывает недавние события, чтобы ответить на вопрос «что произошло с этим аккаунтом?». А база тем временем хранит в той же таблице годы малополезной истории. Недавние запросы замедляются, задачи очистки тянутся, и каждая операция обслуживания начинает раздражать чуть сильнее.
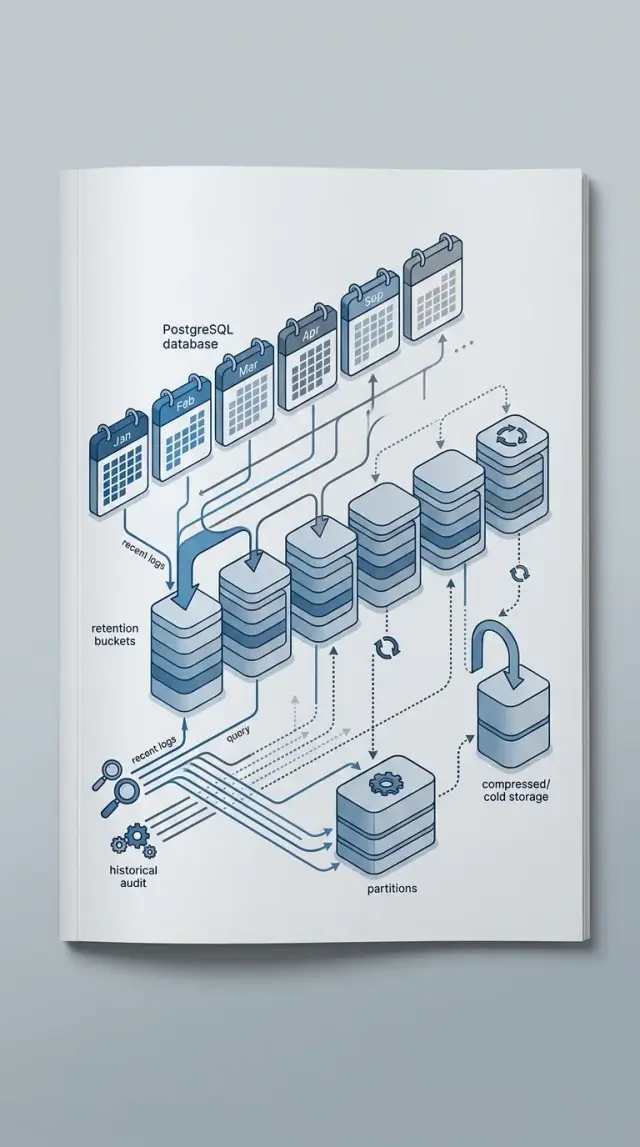
Именно поэтому партиционирование привлекает столько внимания в таблицах аудита. Оно может сильно упростить хранение и оставить недавние запросы работать по меньшим кускам данных. Удалить одну старую партицию куда чище, чем вычищать 200 миллионов старых строк.
Но партиционирование — не волшебство. Оно помогает, когда запросы совпадают с границей партиции, обычно по времени. Если большинство запросов спрашивают «события за последние 7 дней», Postgres может пропустить старые партиции. Если же запросы в основном ищут «все события для клиента 42» без фильтра по времени, Postgres всё равно может затронуть длинный список партиций.
Именно здесь команды часто ошибаются сами. Они добавляют партиции, чтобы справиться с ростом, но оставляют те же размытые запросы, те же длинные сроки хранения и те же слишком большие индексы. В итоге у них становится больше таблиц для поддержки, а скорости — почти не прибавляется.
Сначала решите срок хранения, потом проектируйте таблицу
Большинство команд начинают с размера партиции, названий или автоматизации. Это подход задом наперёд. Самое сложное — не создать партиции. Самое сложное — решить, какие данные должны остаться, какие можно сократить и какие пора убрать.
Не складывайте все события в одну кучу. Строка аудита безопасности, изменение в биллинге, событие доставки письма и отладочная трассировка живут очень разное время. Запишите срок хранения для каждого типа события простыми словами и с точными числами. «Хранить строки платёжного аудита 7 лет» — полезно. «Хранить их какое-то время» — так таблицы растут, пока к ним уже никто не хочет прикасаться.
Рабочий план хранения обычно состоит из трёх уровней. Недавние данные остаются сырыми в Postgres, потому что их часто запрашивают и нужен полный уровень деталей. Более старые данные уходят в архивное хранилище или сокращаются до сводок. Просроченные данные удаляются по расписанию.
Отдельно учитывайте потребности разных команд, даже если данные выглядят похожими. Юристам может понадобиться длинная история того, кто что изменил и когда. Поддержке обычно нужен более короткий период, чтобы разобраться в жалобе или восстановить цепочку сломанного процесса. Финансам может понадобиться более долгое хранение строк, связанных со счетами, возвратами или изменениями доступа, которые влияют на деньги. Один и тот же срок для всех трёх групп обычно плохо подходит.
Перед проектированием таблицы запишите четыре решения для каждого семейства событий:
- как долго сырые строки остаются в Postgres
- когда строки переезжают в архивное хранилище
- когда полные строки превращаются только в сводки
- когда вы удаляете их окончательно
Один такой документ сильно упрощает дальнейшую очистку. Он также помогает легче рассуждать о зоне резервного копирования, отсечении партиций и задачах удаления.
Небольшой пример хорошо показывает смысл. Вы можете хранить события входа сырыми 90 дней, архивировать их на 1 год, а потом удалять. Строки биллингового аудита могут оставаться сырыми 12 месяцев и лежать в архиве ещё несколько лет. Отладочным событиям часто достаточно всего 7 дней, потому что позже они в основном становятся шумом.
Пусть реальные запросы формируют партиции
Партиционирование помогает тогда, когда оно позволяет Postgres игнорировать большую часть таблицы. Если партиции не совпадают с запросами, которые люди выполняют каждую неделю, вы добавляете обслуживание и почти ничего не получаете взамен.
Начните с простого списка реальных запросов. Возьмите их из дашбордов, обращений в поддержку, выгрузок для комплаенса и админских инструментов. Отложите в сторону придуманные будущие потребности. Именно скучные повторяющиеся запросы должны определять дизайн.
Во многих системах эти запросы звучат знакомо: показать аудит одной организации за последние 30 дней, найти все неудачные входы одного пользователя за последние 24 часа, выгрузить один месяц событий для биллинга или посмотреть один тип событий в окне инцидента.
Шаблон обычно очевиден. Времени требует почти каждый серьёзный запрос. Потом уже tenant, actor или event_type сужают поиск. Это часто означает, что время должно задавать структуру партиционирования, а остальные поля — жить в индексах.
Отсечение партиций помогает только тогда, когда запросы подсказывают Postgres, какие партиции можно пропустить. Если команды часто запускают запросы без диапазона дат, месячные или дневные партиции их не спасут. Postgres всё равно может затронуть слишком много партиций, а время планирования будет расти вместе с их количеством.
Поэтому задайте прямой вопрос как можно раньше: ваши обычные запросы всегда включают дату начала и дату конца? Если да, временное партиционирование обычно безопасный выбор для таблиц аудита и событий. Если нет, сначала исправьте запросы или примите, что партиционирование даст меньше, чем вы надеетесь.
Осторожнее с фильтрами, которые красиво выглядят на доске, но почти не встречаются в продакшене. Партиционирование по actor, event_type или tenant часто создаёт много маленьких партиций и дополнительную нагрузку на эксплуатацию, а большинству чтений всё равно нужен фильтр по дате.
Практическое правило простое: партиционируйте по тому фильтру, который есть почти в каждом серьёзном запросе, а затем индексируйте фильтры, сужающие выборку. Для большинства audit-логов это означает время в первую очередь.
Выберите размер партиции, который команда сможет обслуживать
Большинству таблиц аудита и событий хорошо подходят месячные партиции. Они достаточно малы, чтобы vacuum, reindex и удаление не превращались в ночной кошмар. Для стабильного роста месячный вариант обычно самый скучный, а скучно — это хорошо.
Дневные партиции имеют смысл только тогда, когда объём записи настолько велик, что это оправдывает их. Если за один день может добавляться огромный кусок строк, дневные разбиения ускоряют очистку и ограничивают объём данных, который затронет один неудачный запрос. Но если таблица растёт умеренно, дневные партиции создают другую проблему: слишком много таблиц, слишком много индексов и слишком много шансов, что планировщик или скрипт миграции пропустит одну из них.
Годовые партиции выглядят аккуратно на бумаге, но очень быстро становятся тяжёлыми. Одна слишком большая партиция может замедлять vacuum, тормозить работу с индексами и превращать очистку хранения в более тяжёлую задачу, чем она должна быть. Когда старые данные нужно убрать, удалить один месяц намного проще, чем разрезать один гигантский год.
Для большинства команд работает такой ориентир:
- Используйте месячные партиции, когда рост ровный, а срок хранения измеряется месяцами или годами.
- Используйте дневные партиции только тогда, когда за один день появляется столько строк, что месячную партицию уже неудобно обслуживать.
- Избегайте годовых партиций, если только таблица не остаётся маленькой весь год.
Создавайте следующую партицию заранее. Не ждите первого записи в новом периоде, чтобы обнаружить, что создание партиции не сработало, права изменились или деплой пропустил задачу. Небольшая плановая задача, которая создаёт следующий месяц или следующие несколько дней для высоконагруженных таблиц, сильно снижает стресс.
Названия важнее, чем многие думают. Выберите простые имена, которые дежурный инженер прочитает за две секунды, например audit_log_2025_04 или events_2025_04_15. Избегайте хитрых сокращений или схем нумерации, из-за которых человеку приходится открывать runbook прямо во время инцидента.
Лучший план партиционирования — не самый умный. Лучший план — тот, который команда всё ещё понимает через шесть месяцев, после одного изменения схемы и одного неприятного инцидента в субботу.
Внедряйте поэтапно
Менять большую таблицу аудита или событий одним махом обычно больно вдвойне: сначала во время миграции, а потом ещё раз, когда под нагрузкой всплывает упущенный крайний случай. Более безопасный путь — какое-то время держать новую схему рядом со старой и проверять её на реальном трафике.
Начните с цифр, а не с догадок. Посмотрите последние 30–90 дней и запишите суточный рост строк, рост диска, самые тяжёлые запросы и текущую задержку вставок. Если ваша таблица событий в тихие дни растёт до 2 миллионов строк, а во время импорта или всплесков webhook — до 15 миллионов, эта разница должна повлиять и на схему партиций, и на скорость заполнения истории.
Безопасный запуск часто выглядит так:
- Создайте новую партиционированную таблицу рядом с текущей.
- Сначала направьте свежие записи в новую таблицу.
- На короткое время оставьте чтение по старому пути или читайте из обеих таблиц, если приложение может делать это аккуратно.
- Скопируйте более старые строки небольшими партиями по диапазону времени или ID.
- Перед переключением сравните итоги, выборочные записи, медленные запросы и задержку записи с обеих сторон.
Небольшие партии важнее, чем ожидает большинство команд. История, которая кажется быстрой в staging, может перегрузить autovacuum, растянуть checkpoints или заставить реплики отстать в продакшене. Десять маленьких задач, которые завершаются чисто, лучше одной большой, которая стопорит записи в 2 часа ночи.
Если старая таблица аудита хранит 900 миллионов строк, не пытайтесь перенести её одним запуском за один уикенд. Переносите по одной неделе или одному месяцу, в зависимости от размера строк и трафика. После каждой партии проверяйте, совпадают ли количества, и действительно ли обычные запросы отсекают партиции, а не сканируют всё подряд.
Переключайтесь только после того, как скучные проверки проходят несколько дней подряд. Вставки должны оставаться ровными. Логи медленных запросов не должны становиться хуже. На дашбордах должны быть нормальные CPU, I/O и задержка реплик. Когда эти цифры спокойны, старая таблица становится не самым большим риском, а вашим путём отката.
Один практический пример
Представьте SaaS-приложение с тремя активными потоками событий: входы пользователей, изменения админов и webhook-события от внешних систем. Все три важны, но люди используют их очень по-разному.
Поддержка в основном ищет недавнюю активность. Клиент говорит: «Я не смог войти вчера», и команда проверяет последние несколько дней входов и изменений аккаунта. Для этой задачи им редко нужны данные старше двух недель, поэтому база должна делать недавние строки дешёвыми для поиска.
Финансам нужно другое. Биллинг-webhook’и, изменения статуса счёта и повторные попытки платежей могут быть доступны целый год. Эти записи важны для споров, возвратов и проверок в конце месяца. Продуктовым командам часто вообще не нужны старые сырые события. Через 90 дней им могут быть важны только месячные итоги: сколько было входов или сколько ошибок webhook пришло в конкретную интеграцию.
Разумная схема довольно проста. Поместите сырые события в месячные партиции. Оставьте недавние партиции удобными для запросов поддержки. Храните события, связанные с биллингом, 12 месяцев. Удаляйте или архивируйте сырые события без биллинга через 90 дней. Сохраняйте месячные сводки в summary-таблицах для продуктовой аналитики.
Месячные партиции хорошо подходят этому сценарию, потому что совпадают со сроком хранения и не создают слишком много мелких частей. Дневные партиции добавили бы много обслуживания почти без пользы. Годовые партиции, наоборот, собрали бы слишком много холодных данных вместе и сделали бы очистку неудобной.
Задачу завершают сводные таблицы. Когда сырые product-события проходят отметку 90 дней, плановая задача может сохранить итоги по месяцам, типу события или аккаунту, а затем удалить старые подробные строки. Продукт сохраняет тренды. Финансы сохраняют нужные им записи. Поддержка тратит большую часть времени на недавние партиции, поэтому отсечение партиций помогает сократить объём сканирования Postgres.
Партиционирование особенно уместно тогда, когда одной таблицей пользуются команды с очень разными временными горизонтами. Если одной группе нужен вчерашний день, другой — год, а третьей — только подсчёты, месячные партиции вместе со сводными таблицами трудно чем-то заменить.
Ошибки, которые создают лишнюю работу для эксплуатации
Многие партиционированные таблицы аудита разочаровывают по одной причине: схема партиций не совпадает с тем, как люди читают данные. Если поддержка, комплаенс и инженеры обычно спрашивают «что произошло в прошлый вторник?», тогда время должно управлять раскладкой. Партиционирование по tenant может выглядеть аккуратно в мультиарендном приложении, но часто заставляет каждый временной запрос затрагивать слишком много партиций.
Слишком мелкие партиции создают ещё одну медленную проблему. Дневные партиции могут быть правильным выбором, когда объём записи экстремальный, но многие команды копируют этот подход слишком рано. В итоге они получают сотни или тысячи маленьких таблиц, у каждой свои индексы и своё обслуживание. Планирование шумит сильнее. Изменения схемы идут дольше. Обычная админская работа превращается в рутину.
Индексы всё ещё важны после партиционирования. Временная схема без индексов, соответствующих реальным фильтрам, — это просто куча меньших проблем. Если люди обычно фильтруют по created_at, tenant_id и event_type, стройте схему под это. Иначе Postgres может правильно отсечь партиции, но всё равно сделать слишком много работы внутри каждой из них.
Очистка обычно ломается первой
Огромные DELETE-задачи — частая ошибка. Они раздувают таблицы, создают долгую нагрузку на запись и могут замедлить всю базу именно тогда, когда сюрпризы особенно нежелательны. Для хранения событий обычно чище и дешевле удалить старую партицию, чем вычищать миллионы строк из одной большой таблицы.
Автоматизацию команды откладывают до тех пор, пока не начинает болеть. Если никто заранее не создаёт будущие партиции, вставки могут начать падать. Если никто не удаляет старые партиции по графику, хранилище будет расти, пока очистка не превратится в срочный проект. Во многих случаях достаточно небольшой плановой задачи. Она должна заранее создавать новые партиции, применять нужные индексы и удалять истёкшие партиции после безопасного окна.
Один быстрый тест говорит очень о многом. Представьте, что кто-то просит все события входа одного клиента за последние 30 дней. Если этот запрос всё равно сканирует много лишних партиций, ждёт огромный цикл удаления или зависит от ручной настройки партиций, значит схема добавляет лишнюю работу эксплуатации, а не убирает её.
На какие вопросы нужно ответить до решения
Партиционирование окупается только тогда, когда раскладка облегчает ежедневную работу. Если она добавляет церемонии, кастомные задачи и неожиданные замедления, вы построили систему учёта, а не решение.
Перед тем как создать первую партицию, ответьте на несколько простых вопросов:
- Когда приложение запрашивает последние 7, 30 или 90 дней, читает ли Postgres только эти партиции?
- Когда срок данных истекает, можно ли удалить их, просто убрав старую партицию, вместо большого DELETE?
- Если кому-то нужен один месяц во время инцидента или аудита, можно ли сохранить или восстановить именно этот диапазон, не затрагивая всё остальное?
- Если новый инженер откроет схему, поймёт ли он названия, границы и правила хранения за один просмотр?
- Может ли отчётность использовать ежедневные или еженедельные сводки для подсчётов, трендов и алертов вместо того, чтобы каждый раз ходить в сырые строки?
И сделайте ещё одну вещь: проверьте три реальные production-запроса, а не учебные примеры. Один может вытаскивать недавний аудит одного пользователя. Другой — считать неудачные события за последний день. Третий — питать месячный отчёт. Если после предложенной схемы эти запросы не становятся проще, дешевле или быстрее, остановитесь и поменяйте план.
Также посмотрите на человеческую цену. Схема партиций, которой постоянно нужны ручные исправления, начнёт раздражать команду уже через месяц. Простые месячные партиции с понятными правилами хранения часто лучше, чем хитрый дизайн с множеством крайних случаев.
Если вы не можете объяснить раскладку и план очистки на одной короткой странице, скорее всего, всё слишком сложно. Таблицы аудита и событий растут быстро. План обслуживания должен оставаться скучным.
Что делать дальше
Начните с простого документа, а не с SQL. Запишите, как долго вы храните каждую таблицу аудита или событий, когда старые данные переезжают в более дешёвое хранилище, когда их удаляют и кто утверждает это правило. Если какое-то правило сейчас звучит расплывчато, позже оно превратится в лишнюю работу.
Затем перечислите реальные запросы, которые люди выполняют. Спросите поддержку, какие поиски они используют, когда клиент сообщает о проблеме. Спросите команду отчётности, какие диапазоны дат им нужны каждую неделю, каждый месяц и во время аудитов. План партиций должен соответствовать этим привычкам, а не чьему-то абстрактному представлению о том, как «должно быть правильно».
Разумный первый шаг должен быть небольшим: перечислите каждую таблицу с датами хранения, архивации и удаления; соберите 5–10 самых частых запросов для каждой таблицы; протестируйте партиционирование сначала на одной загруженной таблице; и автоматизируйте создание партиций, архивные задачи и задачи удаления до запуска.
Этот пилот важен. Партиционирование действительно может сильно помочь, но только если таблица достаточно большая, а шаблон доступа — предсказуемый. Если одна тестовая таблица даст вам более чистое удаление, более быстрые запросы и меньше боли с vacuum, у вас появится схема, которую стоит повторять. Если нет — вы просто дёшево чему-то научились.
Не обсуждайте дизайн только с людьми из базы данных. Привлеките тех, кто отвечает на тикеты, выгружает отчёты и работает с запросами комплаенса. Они часто быстро замечают неудобные пробелы. Месячная схема партиций может выглядеть нормально для инженеров, а поддержке при этом нужно будет искать по трём месяцам активности пользователя десятки раз в день.
Автоматизация должна быть частью первого запуска, а не задачей на потом. Создавайте партиции заранее. Архивируйте по расписанию. Удаляйте старые партиции с понятными защитными проверками. Проверьте и восстановление тоже, чтобы архивированный месяц был не только теоретически доступен.
Если перед запуском вам нужен второй взгляд, Oleg Sotnikov на oleg.is проверяет дизайн схемы, выбор сроков хранения и планы миграции в рамках работы Fractional CTO и startup advisory. Такой ревью часто дешевле, чем исправлять схему партиций, которая на бумаге выглядела аккуратно, а через месяц превратилась в операционную нагрузку.
Часто задаваемые вопросы
Всегда ли партиционирование стоит того для таблиц аудита?
Нет. Партиционирование лучше всего помогает, когда запросы почти всегда содержат временной диапазон и у вас есть чёткие правила хранения. Если люди часто ищут без дат, вы просто добавите больше таблиц в обслуживание и можете почти не увидеть прироста скорости.
Стоит ли планировать сроки хранения до выбора размера партиции?
Начинайте со сроков хранения. Решите, как долго каждый тип события остаётся сырым в Postgres, когда он уходит в архив и когда удаляется. После этого выбрать месячные или дневные партиции становится гораздо проще.
По чему лучше партиционировать журналы аудита?
В большинстве audit- и event-таблиц используйте время. Обычно команды ищут данные за день, неделю или месяц, и время позволяет Postgres пропускать старые партиции. Положите tenant, actor или event_type в индексы, если ваши реальные запросы не показывают другой рисунок.
Выбирать месячные или дневные партиции?
Месячные партиции подходят большинству команд. Они остаются достаточно небольшими для обычных задач vacuum, reindex и очистки, не создавая слишком много дочерних таблиц. Выбирайте дневные только тогда, когда за один день появляется столько строк, что месячную партицию уже неудобно обслуживать.
Нужны ли индексы после партиционирования?
Нет. Партиционирование только уменьшает число партиций, которые читает Postgres. Вам всё равно нужны индексы, соответствующие фильтрам внутри каждой партиции, например по времени вместе с tenant или event_type.
Лучше ли удалять старые партиции, чем старые строки?
Чаще всего да. Удаление старой партиции убирает истёкшие данные аккуратно и без лишней нагрузки, раздутия таблиц и долгой записи, которые создают большие DELETE-задачи.
Как безопаснее всего перенести огромную таблицу событий?
Создайте новую партиционированную таблицу рядом со старой и сначала направьте туда свежие записи. Потом догружайте старые строки небольшими партиями, сравнивайте количество и примеры записей и переключайтесь только после того, как реальные запросы и задержка записи выглядят нормально.
Когда для данных событий имеют смысл сводные таблицы?
Используйте сводные таблицы, когда людям нужны тренды, подсчёты или месячные отчёты, но не нужны все старые сырые строки. Оставьте свежую детализацию для поддержки и инцидентов, затем сверните старые product-events в сводки и удаляйте сырые данные по графику.
Какую автоматизацию нужно настроить для партиционированных таблиц?
Автоматизируйте создание партиций до начала следующего периода, добавляйте нужные индексы, архивируйте старые данные и удаляйте истёкшие партиции после защитного окна. Если этого не делать, вставки могут начать падать, а хранилище — расти намного дольше, чем планировалось.
Как понять, что схема партиционирования действительно работает?
Проверяйте реальные production-запросы, а не игрушечные примеры. Недавние поиски должны затрагивать только недавние партиции, хранение должно опираться на удаление партиций вместо огромных DELETE, а вставки, CPU, I/O и задержка реплик должны оставаться стабильными после запуска.


