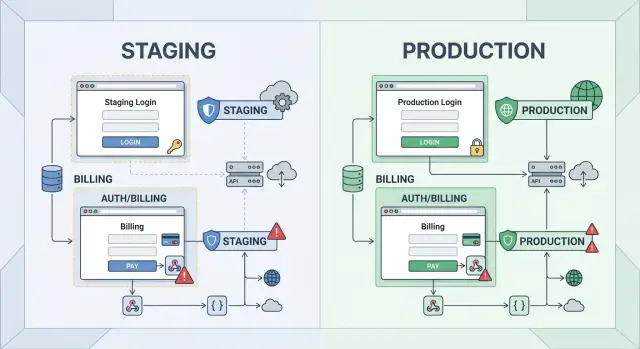
Паритет staging для авторизации и биллинга до полного паритета
Паритет staging для авторизации и биллинга помогает командам рано ловить проблемы с входом и платежами, чтобы выпускать с уверенностью до того, как выровнять всё остальное.
Содержание
Почему команды ошибаются с паритетом staging
Команды часто относятся к staging как к музейной копии production. Они пытаются одновременно дублировать каждый сервис, каждый флаг, каждый источник данных, каждую фоновую задачу и каждое мелкое поведение. Звучит аккуратно, но обычно это создаёт окружение, которое долго разворачивать, дорого поддерживать и которому трудно доверять.
Проблема проста: не каждая разница несёт одинаковый риск. В staging допустимы фальшивые посты в блоге, уменьшенные данные поиска или небольшой каталог — эти пробелы редко вредят пользователям. Быстро вред наносят ошибки входа в систему, невозможность сбросить пароль или неправильное списание средств.
Именно поэтому «паритет staging для авторизации и биллинга» важнее, чем полный паритет по всем остальным частям. Команды поступают наоборот, тратя недели на копирование деталей с низким риском и оставляя опасные сценарии на потом. В результате staging на бумаге выглядит близким к production, но потоки входа и платежей по-прежнему ведут себя иначе там, где это действительно критично.
Подумайте о радиусе поражения. Косметическое несоответствие может на минуту ввести в замешательство одного тестировщика. Ошибка в аутентификации может лишить реальных людей доступа к аккаунтам после релиза. Ошибка в платежном потоке может привести к неудачным списаниям, дублирующимся платежам, нарушенным триалам или счетам, которые не совпадают с тем, что видит пользователь.
Небольшой SaaS-пример делает это очевидным. Если в staging используется другой callback для входа, более простой таймаут сессии и фейковый webhook для биллинга, команда может чувствовать себя «в основном согласованной» с production. Но в день релиза пользователи, входящие через Google, получают ошибку, а апгрейды подписок застревают в фоне. Главная страница выглядела нормально. Опасные пути — нет.
Команды также гонятся за полным паритетом, потому что это выглядит аккуратно: можно сделать чеклист, назначить владельцев и сказать, что всё совпадает. Риск не заинтересован в аккуратности — он сосредоточен там, где через систему проходят идентификация и деньги.
Лучшее staging-окружение начинается с путей, которые могут закрыть доступ пользователю или повлиять на списания. Сначала сопоставьте их. Оставьте безопасные отличия на потом, когда они перестанут быть предположениями и станут стоящими усилий.
Оставляйте области с низким риском на потом
Команды часто тратят время, заставляя staging совпадать с production в местах, которые редко приводят к реальному ущербу. Это приятно смотреть, но мало снижает риск релиза. Небольшая ошибка на маркетинговой странице раздражает. Сломанный вход или неверное списание создают тикеты, возвраты и злых клиентов.
Именно поэтому паритет staging для авторизации и биллинга должен быть в приоритете. Начните с частей, которые контролируют доступ и деньги. Оставьте остальное на потом, если только «маленькая» область уже не создавала проблем.
Низкоприоритетные пробелы обычно находятся по краям:
- маркетинговые страницы с другими баннерами, текстами или экспериментами
- настройки темы и косметические предпочтения
- инструменты аналитики, которые отправляют тестовые данные вместо реальных событий production
- поиск или чат, которые работают на меньших индексах или с ограниченными интеграциями
- редкие админские экраны, которые использует внутренняя команда раз в месяц
Эти отличия часто допустимы какое-то время. Если в staging поиск возвращает меньше результатов из-за меньшего индекса, релиз всё ещё может быть безопасным. Если цифры аналитики немного отличаются, вы всё ещё можете оценить, работают ли вход, оформление заказа и доступ к аккаунту.
То же самое касается виджетов чата и скриптов трекинга. Они важны, но обычно не мешают клиенту использовать продукт. Рассматривайте их как вторичный этап работы, а не как приоритет для первого дня.
Бэк-офисные потоки тоже могут подождать, особенно те, к которым ваша команда прикасается редко. Экран внутреннего экспорта, отчёт для финансов или разовый экран настроек не должны отнимать столько же внимания, как сброс пароля, истечение сессии, апгрейд подписки или восстановление при неудачном платеже.
Простое правило помогает: тратьте время там, где ошибка быстро вызывает нагрузку в поддержку. Неработающий вход останавливает людей у дверей. Неправильные списания ломают доверие и требуют времени на возврат. Именно там нужен реалистичный staging-данные, совпадающие провайдеры и повторяемые тесты.
Стремление к совершенству по каждой фиче звучит ответственно. На практике это часто замедляет команды и скрывает реальный риск. Сначала сделайте стабильными auth, затем billing. Потом закрывайте меньшие пробелы по очереди.
Что означает паритет в аутентификации
Паритет аутентификации означает, что человек может попасть в staging тем же способом, что и в production: пройти те же проверки и столкнуться с теми же блокировками. Если staging пропускает эти шаги, вы не тестируете аутентификацию — вы тестируете обходной путь.
Начните с полного пути учётной записи. Новый пользователь должен суметь зарегистрироваться, подтвердить email (если production этого требует), войти, выйти и сбросить пароль через тот же поток. Если production отправляет магическую ссылку, в staging тоже должна быть магическая ссылка. Если в production есть SSO или MFA, в staging нужны те же пути, а не фейковый локальный вход, который используют только разработчики.
Менее очевидные случаи важны ещё больше, потому что они ломаются тихо. Хорошее тестирование аутентификации должно покрывать:
- истечение сессии по реальному таймауту
- блокировку аккаунта после неудачных попыток
- изменения ролей, которые вступают в силу на следующем запросе
- подтверждение email и истёкшие ссылки для сброса
- запросы MFA на тех же аккаунтах и действиях, что и в production
Многие команды не учитывают настройки провайдера. Эти настройки меняют реальный путь пользователя сильнее, чем код приложения. Одна галочка в настройках провайдера аутентификации может требовать подтверждение email, разрешать вход без пароля, менять время жизни токена, блокировать домены или требовать MFA лишь для некоторых групп. Если в staging используется другая конфигурация, поток может выглядеть нормально, тогда как реальные пользователи получат совсем другой опыт.
SSO требует особого внимания. Если клиенты логинятся через Google Workspace, Microsoft Entra ID, Okta или другого провайдера идентификации, в staging нужно тестировать тот же handshake, правила callback и логику сопоставления аккаунтов. В противном случае вы доказываете лишь, что fallback-вход работает. Это не тот рискованный путь.
Изменения ролей и прав тоже входят в паритет аутентификации. Повысьте пользователя, снимите доступ, приостановите аккаунт и проверьте, что происходит в текущей сессии и после повторного входа. Некоторые системы обновляют claims сразу, другие держат устаревший доступ до истечения токена. Если staging не совпадает с этим поведением, день релиза может превратиться в очередь тикетов.
Паритет auth — это не копирование всех production-пользователей. Речь о совпадении реальных ворот, тайминга и точек отказа, которые решают, кто проходит, а кто нет.
Что означает паритет в биллинге
Удачная зелёная тестовая оплата доказывает почти ничего. Паритет биллинга означает, что ваше staging-окружение ведёт себя как production, когда деньги меняют форму, время или статус.
Большинство команд проверяют один счастливый сценарий с тестовой картой: списание прошло — и всё. Реальные сбои происходят в грязных моментах: триал кончается в полночь, клиент апгрейдится в середине периода, купон истекает или банк отклоняет продление спустя полгода гладких платежей.
Если ваш продукт использует подписки, staging должен покрывать моменты, которые меняют доход и доступ клиента. Обычно это включает:
- начало и окончание триала
- апгрейд и даунгрейд в активном периоде
- продление, отмена и реактивация
- неудачное списание, повторная попытка, возврат и спор по платежу (если это поддерживает ваш провайдер)
Эти сценарии важны, потому что они запускают не только платеж. Они меняют лимиты плана, количество мест, суммы в счёте, налоги и даты, которые контролируют статус аккаунта.
Налоги, купоны, прората и правила выставления счетов тоже должны совпадать с production-логикой. Небольшое расхождение здесь быстро породит тикеты. Клиент ожидает одну сумму, видит другую в счёте — и ваша команда тратит день на проверку чисел вместо разработки.
Webhook'ы заслуживают особого внимания. Многие баги в биллинге начинаются после того, как провайдер платежей отправил событие, а не в момент списания. Staging должен получать те же типы событий webhook, проверять подписи так же, обрабатывать дубликаты и корректно работать, когда события приходят с опозданием или вне порядка.
Повторные попытки важны тоже. Неудачное списание обычно не кончается одной неудачей — провайдеры пытаются снова по расписанию, и у приложения должны быть правила доступа в этот период. Если staging никогда не тестирует повторные попытки, команды пропускают одни из самых дорогостоящих ошибок биллинга.
Хорошее staging для биллинга немного раздражает, потому что включает кейсы-крайности, ожидания и «уродливые» сценарии со счетами. В этом и смысл. Для паритета auth и billing паритет биллинга означает тестирование полного жизненного цикла, а не только первого успешного списания.
Как закрывать разрыв в правильном порядке
Команды теряют время, пытаясь копировать production всё и сразу. Лучше исправлять те части, которые могут закрыть доступ пользователям или привести к потере денег. Поэтому паритет staging для auth и billing должен быть первым в очереди.
Сделайте одну общую карту всех зависимостей в этих двух областях. Включите провайдера идентификации, хранилище сессий, шаги проверки по email или SMS, платёжный процессор, налоговую логику, состояние подписки, webhook'и и любые внутренние сервисы, которые обновляют доступ к аккаунту после платежного события.
Отметьте, что должно точно совпадать с production. Некоторые настройки могут оставаться упрощёнными в staging, но несколько деталей не должны дрейфовать, иначе они скрывают реальный риск.
- callback URL и пути редиректа
- время жизни токена, правила обновления и поведение истечения сессии
- роли, проверки доступа и изменения состояния аккаунта
- endpoints webhook'ов, signing secrets и правила повторных попыток
- логика планов, правила триалов и обработка неудачных платежей
Копируйте эти настройки в первую очередь. Команды часто оставляют callback URL, секреты или конфигурацию webhook'ов на потом, потому что это кажется настройкой. На практике именно они решают, будет ли поток вести себя как production или даст вам фальшивую зелёную галочку.
После этого сначала протестируйте нормальный путь: регистрация, вход, апгрейд плана, продление подписки и подтверждение, что доступ меняется в нужный момент. Если простой путь ломается, крайние случаи ещё не имеют значения.
Когда базовый путь работает, переходите к случаям с ошибками. Проверьте истёкшие сессии, сброс пароля, повторную доставку webhook'ов, отклонённые карты, отмены подписки и задержки в подтверждении платежа. Эти тесты ловят «уродливые» баги, но они помогают только после того, как базовый поток надёжен.
Ведите короткий лог несоответствий по ходу. Записывайте каждое отличие, влияние на пользователя и блокирует ли оно релиз. Исправляйте те разрывы, которые лишают вас доверия к результату, а проще работу по очистке оставляйте на потом.
Этот порядок менее гламурен, чем погоня за полным staging по всем сервисам. Зато он спасает команды от худших сюрпризов в день релиза.
Простой пример из SaaS-продукта
Представьте маленький SaaS-инструмент для командного планирования. Новый пользователь нажимает «Sign up with Google» в staging, возвращается в приложение и запускает бесплатный триал. Команда проверяет не только счастливый путь: OAuth-callback работает, приложение создаёт один аккаунт, триал стартует с правильными датами, и welcome-письмо доходит до нужного почтового ящика.
Этот первый шаг ловит распространённую проблему. Если в staging нет тех же настроек аутентификации и правил учётных записей, Google-вход может работать в демо и падать для реальных пользователей или создавать дубликаты аккаунтов, когда кто-то позже присоединяется к рабочему пространству по приглашению.
Днём позже коллега приглашает того же пользователя в платное рабочее пространство. Теперь команда смотрит на сопоставление идентичности, а не только на приглашение по email. Пользователь должен присоединиться к существующему аккаунту, сохранить способ входа и попасть в нужное рабочее пространство с правильной ролью.
Если в staging есть паритет, здесь выявляются баги ролей. Пользователь, начавший с триала, не должен потерять доступ к своему аккаунту и не должен случайно получить права администратора просто потому, что поток приглашения и поток входа через Google по-разному опознают, кто он.
Далее владелец рабочего пространства апгрейдит план. Платёжный провайдер фиксирует изменение, отправляет webhook, и приложение обновляет места, лимиты и платные функции. Команда проверяет тайминг, потому что многие баги прячутся в разрыве между «платёж принят» и «аккаунт обновлён».
Потом они намеренно провоцируют неудачное продление с тестовым методом оплаты. Это одно событие расскажет многое. Система биллинга должна корректно отметить продление, отправить нужные письма, пытаться снова, если это правило, и обновить статус аккаунта, не закрывая доступ слишком рано и не оставляя платные функции открытыми на недели.
Команда также проверяет логи и внутренние события. Пришёл webhook один раз или три? Приложение обработало его один раз? Аккаунт перешёл в льготный период, в ограниченный режим или в отмену согласно реальным production-правилам?
Вот почему паритет staging для auth и billing важен до того, как вы добьётесь полного паритета везде. Один путь покрывает вход, приглашения, роли, подписки, webhook'и и изменения статуса аккаунта. Если этот путь держится — риск релиза быстро падает.
Ошибки, создающие ложную уверенность
Команды часто думают, что staging готов, потому что один чистый тест прошёл: вход, апгрейд плана, экран успеха. Этот тест доказывает очень мало. Реальные проблемы всплывают, когда у пользователей разные роли, события биллинга приходят с задержкой или настройки между staging и production расходятся.
Одна распространённая ошибка — использование единственного админ-аккаунта для всех тестов. Админы видят и могут почти всё, поэтому они скрывают баги прав. Обычный пользователь, сотрудник финотдела или клиент с ограниченной ролью пойдёт иным путём.
Это быстро важно в SaaS. Админ может без проблем купить дополнительные места, а менеджер команды не сможет пригласить пользователей из-за ошибок в логике лимитов. Сотрудник финансового отдела ожидает поле налогов в счёте, а в staging налоговые настройки вовсе не проверяли.
Ещё слабое место — тесты биллинга, покрывающие только успешные списания. Если вы проверяете лишь «карта списана, аккаунт апгрейднут», вы пропускаете кейсы, которые вызывают тикеты и злые письма. Возвраты, неудачные продления, даунгрейды, отмены в конце периода и сокращение мест меняют состояние аккаунта так, что в них легко ошибиться.
Та же проблема с webhook'ами. Многие команды делают один счастливый тест и останавливаются. Они не симулируют:
- задержки доставки webhook'ов
- дублирующие события
- таймауты и поведение повторных попыток
- отсутствующие или неверные подписи
- события, пришедшие вне порядка
Когда эти кейсы падают, staging всё ещё выглядит здоровым, потому что UI сработал при первом клике. Production же рассказывает другую историю, когда провайдер платежей пытается отправить событие три раза, а ваше приложение создаёт дубликаты записей.
Сдвиг конфигураций — ещё одна ловушка. Если секреты staging, callback URL или endpoints webhook'ов не совпадают с production, ваши тесты дают успокоение без точности. Вы уже не проверяете реальную интеграцию, а упрощённую версию, которой пользователи никогда не увидят.
Правила ролей и настройки аккаунта тоже часто пропускаются. Лимиты мест, налоговые настройки, даты окончания триала и доступы по ролям требуют отдельных проверок, потому что они меняют результат даже тогда, когда экран выглядит нормально. Маленькие настройки вызывают большие ошибки биллинга.
Если вы хотите добиться паритета staging для auth и billing, тестируйте края перед тем, как проверять всё остальное. Используйте больше чем один тип аккаунта. Нарочно ломайте поток webhook'ов. Прогоняйте возвраты и отмены, а не только покупки. Эта работа менее приятна, чем зелёный демонстрационный сценарий, но именно она находит баги, которые обычно ускользают.
Быстрые проверки перед каждым релизом
Чеклист релиза для паритета staging auth и billing должен быть коротким и строгим. Если эти несколько проверок проходят в staging, вы снижаете шанс неприятного сюрприза после деплоя.
Проводите их с реальными тестовыми аккаунтами, а не с моками. Вы хотите пройти весь путь: письмо, вход, смена плана, неудачное списание и ту трассу, которой пользуется ваша команда для дебага.
-
Создайте совершенно новый аккаунт и завершите первый шаг идентификации, который требует ваш продукт. Это может быть подтверждение email, одноразовый код или базовый экран подтверждения. Если аккаунт попадает в неправильное состояние после регистрации — остановитесь.
-
Сбросьте пароль у старого тестового аккаунта, затем войдите с новым паролем. Это ловит битые токены, неправильную обработку сессий и распространённый случай, когда сброс проходит, но следующий вход — нет.
-
Переведите тестового пользователя с одного плана на другой и подтвердите, что доступ меняется немедленно. UI, запись аккаунта и feature-gates должны согласовываться в течение секунд, не после ручного обновления или фоновой зачистки.
-
Смоделируйте неудачное списание и проследите, что происходит дальше. Аккаунт должен перейти в ожидаемое состояние: льготный период, ограниченный доступ или даунгрейд. Неопределённые состояния — место, где копятся тикеты.
-
Откройте логи и дашборды, которыми пользуется ваша служба поддержки, и проследите тот же пользовательский путь от начала до конца. Они должны найти регистрацию, сброс, событие биллинга и изменение доступа без догадок о том, какая система является источником правды.
Это займёт чуть больше времени, чем быстрый smoke-test, но сбережёт гораздо больше позже. Команды часто выпускают код, который выглядит нормально в продукте, но ломается, когда реальный пользователь сталкивается с доставкой писем, истечением токенов или повторными попытками оплаты.
Если вы можете позволить себе лишь несколько проверок перед релизом — сделайте эти. Красивые баги в UI могут подождать день. Сломанная регистрация, вход или биллинг обычно не могут.
Что делать дальше, если команда застряла
Если команда всё время говорит о паритете, но ничего не завершает, сильно урежьте объём. Сделайте в эту неделю один auth-поток и один billing-поток. Этого достаточно, чтобы снизить реальный риск релиза и набрать инерцию.
Выберите auth-поток, который быстрее всего ломает доверие: вход с MFA, сброс пароля или принятие приглашения. Выберите billing-поток, который может потерять деньги или вызвать боль в поддержке: новая подписка, обновление карты или восстановление после неудачного продления.
Запишите точные production-правила, которые нужно зеркалить. Будьте буквальными. Перечислите настройки провайдера, callback URL, длину сессии, правила повторных попыток, налоговую логику, события webhook'ов, триггеры писем и состояния отказа, которые обычно забывают.
Короткий чеклист помогает:
- назовите единственный auth-поток, который нужно сначала совпадать
- назовите единственный billing-поток, который нужно сначала совпадать
- скопируйте production-правила в один общий документ
- назначьте одного владельца за конфигурацию staging, тестовые данные и здоровье webhook'ов
Один владелец важнее, чем многие команды хотят признать. Когда пять человек по одному владеют частью staging, никто не замечает просроченные секреты, устаревшие тестовые аккаунты или сломанные повторные попытки webhook'ов до дня релиза.
Этому владельцу не нужно делать всё в одиночку. Ему нужна власть поддерживать честность staging, убирать фальшивые обходы и просить production-настройки, когда что-то не совпадает.
Если эта работа постоянно уступает фичам — считайте это управленческой проблемой, а не провалом команды. Паритет staging для auth и billing — это мелочь по сравнению со стоимостью сломанного входа или неверного списания в production.
Внешняя помощь может ускорить процесс, если команда слишком близка к проблеме. Fractional CTO может просмотреть риски, расставить приоритеты и составить план, который впишется в вашу команду. Oleg Sotnikov — один из вариантов для такого обзора. Его опыт охватывает стартап-продуктовую работу, production-инфраструктуру и AI-first engineering, так что он может помочь подтянуть staging, не превращая это в гигантский боковой проект.
Хороший следующий шаг прост: запланируйте одну рабочую сессию, выберите первые два потока и закончите с назначенными владельцами, правилами и дедлайном для реального теста.


