Откат AI-автоматизации: как приостановить, отменить и запустить заново
Откат AI-автоматизации начинается с простых инструментов: приостановить работу, отменить изменения и запустить задачу заново, прежде чем боты затронут счета, данные клиентов или доступ.
Содержание
Что идет не так без плана отката
Один неудачный запуск может распространиться быстрее, чем ожидает большинство команд. AI-рабочий процесс редко ошибается один раз и останавливается. Чаще он повторяет ту же ошибку для каждой записи, до которой дотрагивается.
Например, модель читает обращения в поддержку и помечает запросы на возврат денег как «решено» вместо «нужна проверка». За десять минут она может закрыть сотни обращений, запустить письма для дальнейших действий и убрать работу из очереди команды. К тому времени, как кто-то заметит проблему, неверный статус уже будет в системе.
Вот почему изменения записей требуют особой осторожности. Черновик резюме, предложенный ответ или внутренняя заметка легко заменить. А вот запись в аккаунте клиента, счете, заказе, договоре или обращении в поддержку — это уже совсем другое дело. Как только система сохраняет такое изменение, другие инструменты могут сразу начать на него реагировать.
Плохая запись редко остается в одном месте. Она может отправить клиентам неверное сообщение, скрыть работу, которая все еще требует участия человека, испортить отчеты, на которые команда потом опирается, или запустить изменения в биллинге, доставке или доступе.
Оповещения помогают, но они не восстанавливают данные. Оповещение лишь говорит, что что-то выглядит не так. Оно не ставит процесс на паузу, не показывает все измененные записи и не возвращает прежние значения. Без пути отката людям приходится в спешке вести собственное расследование.
Такая уборка стоит дороже, чем большинство команд ожидает. Кому-то нужно найти плохие записи, сравнить старые и новые значения, решить, что оставить, исправить данные ниже по цепочке и объяснить случившееся поддержке, финансам или клиентам. Ошибка, на запись которой ушла одна минута, может потом распутываться два дня.
Без плана отката команды начинают бояться собственных автоматизаций. Они вешают ручные проверки везде, откладывают запуск и перестают доверять данным. И это недоверие бьет по работе даже тогда, когда в следующий раз модель срабатывает нормально.
Самый безопасный подход к AI простой: если он может менять важные записи, ему нужен способ приостановить, отменить и заново запустить эту работу под контролем.
Определите, какие записи важнее всего
Сначала разделите записи, которые можно восстановить, и записи, которые нельзя. Черновик ответа, внутренняя заметка или предложенный тег обычно легко заменить. Оплаченный счет, подписанное соглашение, баланс клиента, настройка доступа или статус отправки — нет.
Это кажется очевидным, но команды постоянно пропускают этот шаг. Они позволяют AI записывать данные в живые системы, прежде чем решат, какие данные могут пережить ошибку, а какие способны нанести реальный ущерб за считанные минуты.
Рабочий план отката начинается с простого списка. Выпишите все записи, которых может коснуться автоматизация, а затем отметьте каждую как черновую или финальную. Черновые записи по задумке должны оставаться обратимыми. Для финальных нужны более строгие правила, прежде чем модель сможет что-то менять.
К записям, которым обычно нужен особый контроль, относятся:
- данные биллинга и платежей
- статус аккаунта клиента
- права пользователей и уровни доступа
- состояние склада или заказа
- договоры, согласования и журналы соответствия
Потом расставьте действия по уровню ущерба, который они могут причинить при сбое. Не по тому, насколько сложно их реализовать. Плохое резюме в внутренней заметке может стоить десяти минут. Неверная сумма возврата, закрытое обращение в поддержку или удаленное правило доступа могут привести к часам исправлений и недовольству клиентов.
Хорошо работает простая шкала. Отметьте каждое действие как низкорисковое, среднерисковое или высокорисковое, исходя из двух вещей: сколько записей оно может изменить и насколько сложно эти записи восстановить. Если один неудачный запуск может затронуть 5000 профилей клиентов, такое действие относится к высокорисковым, даже если каждое изменение выглядит мелким.
У каждого типа записи также должен быть человек-ответственный. Поддержка может владеть статусом тикетов. Финансы — счетами и кредитами. Операции — данными по выполнению заказов. Продукт или инженерная команда — правами доступа и состоянием пользователя. Именно этот ответственный решает, что автоматизация может менять сама, что нужно ставить на паузу для проверки, а что должно остаться только для чтения.
Так откат перестает быть гаданием. Когда вы знаете, какие записи важнее всего, можно задать точки паузы, правила отмены и повторные запуски с гораздо меньшим хаосом.
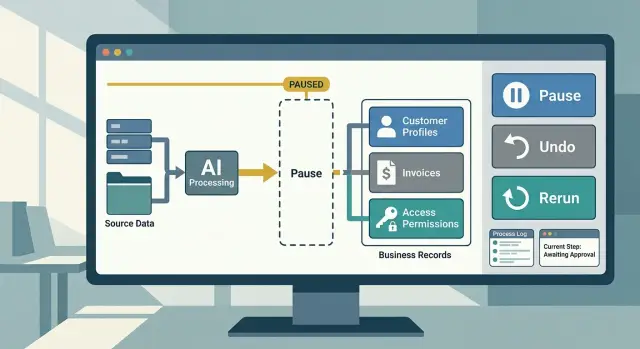
Поставьте точку паузы до того, как изменения попадут в систему
Самое безопасное место, чтобы поймать плохое решение, — прямо перед тем, как система запишет что-то в реальную запись. Как только модель обновит профиль клиента, отправит возврат денег или закроет тикет, исправлять станет намного сложнее.
Хорошее правило простое: модель может сначала подготовить изменения, но не должна всегда применять их сразу. Пусть она формирует действие, показывает, что изменится, и ждет, если риск высокий.
Когда точка паузы особенно полезна
Точка паузы нужна, если одно действие может повлиять на деньги, юридические записи, доступ клиента или данные, от которых зависят другие инструменты. В таких случаях очередь на проверку лучше полной автоматизации.
Эта очередь не обязана быть сложной. Это может быть маленький inbox, таблица в админке или список задач во внутренней системе. Главное, чтобы человек быстро видел предлагаемое изменение, причину и точную запись, которую оно затронет.
Используйте понятные правила согласования, чтобы людям не приходилось гадать. Например:
- отправлять все, что выше лимита возврата, человеку
- ставить на паузу изменения аккаунтов для VIP- или enterprise-клиентов
- удерживать правки, когда уверенность модели низкая
- проверять действия, которые затрагивают больше одной записи одновременно
Держите эти правила узкими. Если направлять каждое действие человеку, очередь превратится в пробку, а люди перестанут обращать внимание.
Низкорисковая работа все равно должна выполняться автоматически. Создание тегов, сортировка входящих запросов, заполнение внутренних заметок или подготовка предложенных ответов обычно не требуют согласования. Такие задачи экономят время, не ставя важные записи под угрозу.
Разделение простое: если действие легко пережить, автоматизируйте его. Если оно меняет то, на что люди полагаются, сначала ставьте паузу.
Есть еще одна важная деталь. Показывайте проверяющему изменение простым языком, а не сырым выводом модели. «Изменить email для биллинга с A на B» легко согласовать. Блок JSON — нет.
Небольшие команды часто справляются с этим лучше крупных, потому что держат правила короткими. Именно так опытные CTO настраивают безопасные AI-операции: автоматизируют скучное, добавляют проверку там, где ошибки становятся дорогими, и делают путь согласования очевидным.
Сделайте каждое изменение легко отменяемым
Если автоматизация может редактировать живую запись, у нее должен быть чистый путь назад. И это начинается до записи, а не после того, как кто-то заметит плохой результат на дашборде, в почте или CRM.
Сначала сохраняйте предыдущее состояние. Часто достаточно простого снимка до изменения: значение поля, версия записи и точные данные, которые автоматизация собирается заменить. Если задача затрагивает несколько полей, сохраняйте их все вместе, чтобы система могла восстановить запись одним действием.
Не менее важен журнал действий. Нужно знать, какая именно автоматизация внесла изменение, когда она сработала, какой prompt или правило его запустили и какие записи она затронула. Под давлением это экономит часы на поиске проблемного запуска.
Что должно быть в записи об отмене
- исходное значение или полный снимок до изменения
- новое значение, которое записала автоматизация
- ID задания, пользователь или служебная учетная запись, стоящие за изменением
- время записи и номер пакета или запуска
Не стоит считать каждое обновление поля отдельным крошечным событием, если люди воспринимают работу как одно действие. Если автоматизация закрывает запрос на возврат денег, добавляет заметку и меняет статус, объединяйте эти обновления. Тогда одна отмена откатывает все действие целиком, а не его половину.
Скорость важнее, чем думает большинство команд. Когда модель начинает менять не те записи, никому не нужен длинный ручной план восстановления. Отмена должна быть достаточно быстрой, чтобы оператор смог сделать это за минуты, с понятным охватом и предварительным просмотром того, что будет возвращено назад.
Хорошее правило простое: если человек может заметить ошибку на одном экране, он должен уметь отменить ее тоже на одном экране. Это может быть одна кнопка для последнего запуска, пакетный откат по ID задания или команда, которая восстанавливает записи из сохраненного снимка.
Вот здесь откат перестает быть теорией. Вы не пытаетесь построить идеальную модель. Вы строите систему, которая позволяет людям быстро восстановиться, продолжить работу и запустить задачу заново после того, как они исправят prompt, правило или фильтр данных.
Добавляйте безопасный повторный запуск шаг за шагом
Когда автоматизация ломается на середине, худшее решение — нажать повтор и надеяться на лучшее. Так команды отправляют одно и то же письмо дважды, добавляют две заметки в один аккаунт или меняют запись, которую человек уже исправил.
Более безопасный подход начинается с маленьких шагов. Если ваш workflow читает запись, просит модель сформировать ответ, сохраняет заметку и обновляет статус, каждый шаг должен существовать сам по себе. Если один шаг падает, повторно запускайте только его. Не перезапускайте всю цепочку, если не уверены, что прежние шаги ничего не оставили после себя.
Перед любым повторным запуском проверьте, не сработал ли первый запуск частично. Частичный успех — обычное дело. Модель могла создать черновик, но финальное сохранение не успело завершиться по тайм-ауту. Или сохранение прошло, но система так и не отметила задачу как завершенную. Если пропустить эту проверку, повтор может создать второе изменение вместо завершения первого.
Повторный запуск также должен защищать от дублей. Дайте каждому запуску уникальный идентификатор операции и прикрепляйте его к каждой записи. Тогда ваше приложение сможет понять: «Я уже сохранил это изменение» — и пропустить вторую запись. Такая защита экономит очень много времени на исправления.
Хорошая проверка перед повторным запуском короткая:
- подтвердить, какой именно шаг упал
- проверить, не дошла ли до системы какая-то ранняя запись
- убедиться, что запись все еще соответствует ожидаемому состоянию
- использовать тот же идентификатор операции при повторе
Для каждого повторного запуска ведите простую запись в журнале. Фиксируйте, кто его запустил, что именно сломалось, что система обнаружила при проверке и почему повтор был разрешен. «Тайм-аут» — полезно. «Модель вернула неверный формат» — полезно. «Пользователь изменил запись, поэтому мы пропустили повтор» — еще лучше.
Команды, которые используют AI в продакшене, обычно учатся этому на собственных ошибках: повторные запуски — это не инструмент ремонта, если они слишком широкие, не защищены от дублей и потом их трудно объяснить. Если команда не может точно сказать, что затронет повторный запуск, он слишком широк.
Простой пример из команды поддержки
Команда поддержки часто начинает с бота, который делает небольшие, но полезные задачи. Он читает новые обращения, добавляет теги, заполняет данные аккаунта и пишет короткую внутреннюю заметку, чтобы следующий агент видел контекст. Это звучит безобидно, пока бот не перепутает двух клиентов с похожими именами.
Представьте себе биллинговое обращение от «Northwind Solar». Бот ошибочно связывает его с «Northwind Systems», затем добавляет неправильный тег клиента и готовит заметку о том, что по аккаунту есть спор о возврате денег. Именно такие ошибки превращают простое обращение в проблему для финансового отдела.
Более безопасный поток ставит точку паузы прямо перед тем, как правка попадет в биллинговые заметки. Бот по-прежнему может подготовить заметку, предложить тег и показать найденную запись клиента, но человек подтверждает ID аккаунта перед тем, как система что-либо сохранит. Одна эта пауза экономит много последующей уборки.
Поток может выглядеть так:
- Бот читает обращение и предлагает совпадение с клиентом.
- Он добавляет черновой тег и черновую заметку, но не сохраняет их в историю биллинга.
- Специалист поддержки проверяет предварительный просмотр и замечает неверного клиента.
- Специалист отклоняет изменение, исправляет ID клиента и отправляет шаг на повторный запуск.
Если плохая правка уже успела пройти, команде нужен чистый откат. Это значит, что система хранит исходную заметку, новую заметку, кто ее согласовал и когда произошло изменение. Один клик должен убрать неправильный тег и восстановить предыдущую версию биллинговой заметки.
После этого команда повторно запускает только неудачную часть. Им не нужно заново открывать весь тикет или повторять прошлые шаги, которые были верными. Они обновляют совпадение клиента, сохраняют исходное сообщение и перезапускают шаг с заметкой с исправленным вводом.
Вот разница между небольшим инцидентом и тяжелым вечером. Бот по-прежнему помогает, но люди сохраняют контроль, когда запись может повлиять на биллинг, возвраты денег или доверие.
Ошибки, которые создают еще больший бардак
Небольшие ошибки становятся дорогими, когда автоматизация пишет в живые записи раньше, чем кто-то успевает понять, что произошло. Хуже всего не первая ошибка. Хуже — уборка после того, как команда потеряла след: какие записи изменились, почему они изменились и не сделает ли повтор все еще хуже.
Один частый сбой начинается с того, что сначала пишут изменения, а логируют их потом. Workflow обновляет заметки клиента, меняет статус заказа или правит поле биллинга, а записывает факт действия уже постфактум. Если шаг журнала падает, у вас остаются измененные записи, но нет чистой истории. Команде потом приходится гадать, какие строки исправлять вручную.
Другой беспорядок начинается, когда люди перезапускают всю задачу без проверок. Неудачная задача не всегда означает, что ничего не произошло. Возможно, она обновила 200 записей, затем зависла на 201-й и вернула ошибку. Если кто-то повторит весь пакет, первые 200 могут измениться еще раз. Это может продублировать сообщения, снова открыть закрытые тикеты или перезаписать правку человека, который успел вмешаться после первого запуска.
Слишком широкий охват тоже создает проблемы. Один prompt не должен одновременно трогать слишком много систем. Если один и тот же шаг может править запись в CRM, отправлять письмо, создавать счет и писать сообщение в Slack, одна плохая выдача быстро разойдется дальше. Держите зону влияния модели узкой. Пусть один шаг предлагает изменение, а другой применяет его там, где оно должно оказаться.
Тестовые данные тоже дают командам ложную уверенность. Чистые примерные записи редко ведут себя как живая работа. Реальные записи содержат странные имена, пропущенные поля, старые заметки, дубли и исключения, которые никто не задокументировал. Если не тестировать на данных, которые похожи на продакшен, первый реальный запуск и становится тестом.
Лучший подход специально скучный. Сначала логируйте намерение, потом запись. Помечайте каждую запись ID запуска. Повторно запускайте только те записи, которым нужен еще один проход. Тестируйте на очищенных данных, которые все еще сохраняют сложность реальных операций. Это немного замедляет первый запуск, но экономит часы, когда что-то ломается во вторник днем.
Быстрые проверки перед запуском
План отката должен пройти несколько простых тестов, прежде чем вы разрешите ему трогать живые записи. Если хотя бы одна проверка не проходит, оставьте автоматизацию в режиме проверки и сначала закройте пробел.
Начните с кнопки остановки. Когда что-то выглядит неправильно, человек должен уметь приостановить новую работу одним кликом. Пауза должна останавливать новые задачи, при этом четко показывая, какие элементы уже были обработаны, а какие еще ждут.
Потом проверьте восстановление. Если автоматизация правит заметки клиентов, данные заказов, тикеты или счета, команде нужен чистый способ вернуть последний удачный вариант. Этот путь восстановления должен быть быстрым и скучным. Если для восстановления инженеру приходится под давлением писать свой скрипт, вы еще не готовы.
Используйте этот короткий чек-лист:
- не-технический коллега может поставить workflow на паузу без доступа к shell и без правок кода
- команда может восстановить одну запись или небольшой пакет до предыдущей версии
- система может повторно запустить один неудачный элемент без дублей, двойных списаний или повторных сообщений
- логи показывают, что модель прочитала, что изменила и почему действие произошло, простым языком
Проверка повторного запуска важнее, чем думают многие команды. Неудачная задача неприятна. Неудачная задача, которая запускается дважды и создает две записи, — хуже. Возьмите один реальный элемент в тестовой среде, намеренно сломайте его, затем повторно запустите только этот элемент и убедитесь, что результат остается чистым.
К логам нужен такой же уровень внимания. Руководитель поддержки или операционный менеджер должен уметь прочитать цепочку событий и ответить на четыре простых вопроса: что это запустило, что изменилось, что сломалось и что будет дальше. Если журнал понятен только тому, кто его написал, система слишком хрупкая.
Есть одно правило, которое стоит сохранить: если команда не может поставить это на паузу, восстановить или объяснить, не позволяйте этому записывать что-либо в важные данные.
Что делать дальше
Если команда пытается сделать безопасными сразу все workflow, работа обычно буксует. Возьмите один workflow, один тип записи и одно место, где плохое изменение нанесло бы ущерб. Так первая версия останется достаточно маленькой, чтобы ее можно было протестировать, исправить и начать ей доверять.
Хороший план отката специально сделан простым. Вам нужны понятные шаги, а не хитрая логика. Если AI-процесс редактирует тикеты поддержки клиентов, начните с этого. Биллинг, возвраты денег и доступ к аккаунтам оставьте на потом.
Проведите тренировку на сбой до запуска. Дайте workflow плохой ввод, остановите его на середине и проверьте, может ли команда поставить задачу на паузу, отменить изменения и повторно запустить только безопасную часть. Засеките время. Если люди тратят 20 минут на вопрос, кто отвечает за исправление, процесс еще не готов.
Запишите ответственных в одной короткой заметке и храните ее там, где команда уже работает:
- кто может поставить workflow на паузу
- кто может одобрить откат
- кто может повторно запустить задачу после исправления
- кто потом проверяет логи
Имена лучше, чем размытые роли. «Команда ops» — слишком расплывчато. «Майя ставит на паузу, Крис одобряет откат, Ли запускает заново» — намного лучше.
Также полезно держать небольшой тестовый набор записей, который команда может ломать специально. Это дает безопасный способ потренироваться в отмене автоматических изменений и повторном запуске неудачных автоматизаций, не трогая живые данные. После двух-трех таких тренировок слабые места становятся очевидны. Возможно, логи слишком короткие. Возможно, шаг повторного запуска повторяет работу, которую вы уже откатили. Лучше узнать это сейчас.
Если вам нужен внешний взгляд, Олег Сотников на oleg.is делает такую работу в формате Fractional CTO для стартапов и небольших команд. Короткая проверка перед запуском может улучшить шаги паузы, отката и повторного запуска, пока исправления еще недорогие.
Как только один workflow переживет непростой тестовый прогон, используйте тот же подход для следующего. Безопасные AI-операции растут по одному проверенному процессу за раз.


