От схемы БД до клиентского кода: когда общие типы помогают, а когда вредят
Переход от схемы базы данных к клиентскому коду может ускорить команды, но иногда он протаскивает детали таблиц в интерфейс. Узнайте, где стоит делиться типами, а где — остановиться.
Содержание
Почему всё быстро превращается в хаос
Генерация типов на первый взгляд кажется идеальной. Вы направляете инструмент на базу данных, получаете типы бесплатно, и обе стороны приложения соглашаются с именами и формой полей. Для небольшой команды это действительно экономит время.
Путаница начинается, когда «что хранит база данных» превращается в «что интерфейс думает о продукте». В таблице обычно есть поля для хранения и работы бэкенда, а не для самого экрана. Это могут быть временные метки аудита, флаги мягкого удаления, идентификаторы связей, внутренние коды статуса или хвосты от миграций. Базе они нужны. Пользовательскому интерфейсу — чаще всего нет.
Как только фронтенд начинает импортировать сырые типы таблиц, разработчики строят логику вокруг названий столбцов, а не вокруг продуктовых понятий. Страница заказов может читать deleted_at, status_code, warehouse_id и updated_by, потому что сгенерированный тип их показывает. В итоге экран знает о лишних деталях, которые ему не должны быть важны.
Вот где контракты между фронтендом и бэкендом начинают шататься. Разработчик бэкенда переименовывает столбец, разбивает одно поле на два или переносит данные в связанную таблицу. Поведение продукта может не измениться, но экран всё равно ломается, потому что он опирался не на модель ответа, а на детали хранения, созданные не для UI.
Эта проблема расползается тихо. Один компонент импортирует тип таблицы. Потом его переиспользует форма. Потом так же поступают тесты, фильтры, клиентские кэши и вспомогательные функции. Через несколько месяцев простая чистка схемы превращается в большой рефакторинг фронтенда.
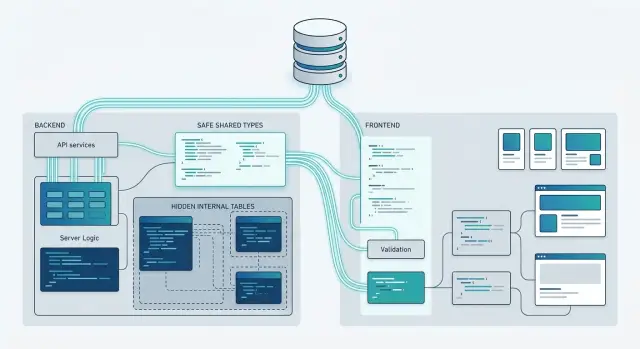
Сгенерированные типы — не зло. Они очень помогают внутри бэкенда, в коде доступа к данным и иногда между внутренними сервисами. Проблемы начинаются тогда, когда схема базы данных напрямую уходит в клиентский код без границы между ними.
Хорошее правило простое: если поле существует из-за того, как вы храните данные, оставьте его на сервере. Если поле существует потому, что оно нужно пользователю, отдавайте его через API-структуру, которой фронтенд может доверять. Этот дополнительный шаг сначала кажется медленнее, но потом защищает от того, чтобы мелкие изменения схемы сломали полпродукта.
Что хорошо делают общие типы
Общие типы лучше всего работают там, где бэкенд и фронтенд уже говорят почти на одном языке. В настройке, где схема базы данных напрямую попадает в клиентский код, это часто простые CRUD-экраны, админ-панели и внутренние инструменты, где запись на сервере очень похожа на запись в интерфейсе.
Первый плюс — синхронизация. Если бэкенд переименует order_total в total_amount, клиент не продолжит молча использовать старое поле неделями. Проверка типов быстро покажет ошибку, и команда исправит несоответствие до того, как пользователи увидят сломанный экран.
Это важнее, чем кажется. Маленькие ошибки в названиях скучны, но они съедают часы. Общие типы превращают их в быстрые и понятные ошибки компиляции, а не в обращения в поддержку.
Они также уменьшают количество одинаковых моделей, скопированных в разные места. Без общего источника команды часто держат почти одинаковые определения в трёх местах: модели базы данных, модели API и интерфейсы фронтенда. Эти файлы расходятся. В одном появляется nullable-поле, в другом о нём забывают, и вот уже форма, таблица и API слегка расходятся друг с другом.
Для небольшой команды такой выигрыш во времени вполне реальный. Один человек меняет поле, заново генерирует типы и идёт по ошибкам, пока приложение снова не станет согласованным. Это часто быстрее, чем вручную обновлять модели в разных сервисах и надеяться, что ничего не забыли.
Польза особенно заметна на простом примере:
- Бэкенд добавляет в заказы новое поле
status. - Сгенерированные клиентские типы сразу его подхватывают.
- Фронтенд теперь знает, что
statusсуществует и какие значения он может принимать. - Интерфейс может показать это поле в таблице или форме без догадок.
Это делает повседневную работу чище. Редакторы подсказывают правильные имена полей, формы используют нужные типы значений, а API-вызовам легче доверять.
Общие типы особенно хороши, когда обеими сторонами приложения владеют одни и те же люди. Стартапы часто подходят под этот сценарий. Когда продукт ещё простой, а команда небольшая, общие типы снимают лишнее трение и помогают работе двигаться быстрее.
В такой узкой области они практичны и скучны — в лучшем смысле.
Где типы БД протекают слишком далеко
Когда вы пускаете схему базы данных прямо в клиентский код без фильтра, интерфейс часто получает поля, к которым ему вообще не стоит прикасаться. Первую неделю или две это выглядит удобно. Потом формы, экраны и тесты начинают зависеть от деталей хранения, которые были нужны только серверу.
Частая утечка — внутренние идентификаторы. Клиенту может понадобиться публичная ссылка, чтобы загрузить запись или перейти к ней, но обычно ему не нужно редактировать сырые первичные ключи, идентификаторы тенантов, внешние ключи или поля версии строки. Как только всё это появляется в типах клиента, кто-то добавит их в состояние формы, отправит обратно при обновлении и начнёт считать обычным пользовательским вводом. Так и появляются случайные ошибки с доступом.
Поля аудита текут не реже. Экран редактирования профиля не нуждается в created_at, updated_at, deleted_at или created_by. Эти поля полезны для логов, инструментов поддержки и админских представлений. В обычных продуктовых экранах они создают шум и провоцируют строить интерфейс вокруг данных, которые должны оставаться только для чтения.
Связующие таблицы — ещё одна ловушка. Экран может показывать, что пользователь состоит в трёх командах, но интерфейсу не нужно знать о user_team_memberships или о том, хранится ли эта связь в одной таблице или в двух. То же самое относится и к enum-значениям хранения. Если в базе статус хранится как archived_soft, это не значит, что продукт должен показывать archived_soft в кнопке или в фильтре.
Имена тоже наносят тихий вред. Названия в базе часто короткие, старые или появились из-за истории миграций. Столбец cust_name может быть нормальным для SQL. Для формы это плохая подпись. Когда текст на экране начинает следовать названиям таблиц и столбцов, продукт наследует все странные решения, которые база приняла много лет назад.
Лучшее правило простое: экспортируйте типы, которые соответствуют тому, что клиент может читать и писать, а не тому, что база данных просто хранит. Держите серверные модели близко к схеме. Держите клиентские модели близко к пользовательскому действию. Это не одно и то же, и если считать их одним и тем же, позже почти всегда появляется лишняя работа.
Осознанно выберите границу
Проблема со схемой базы данных в клиентском коде редко заключается в генераторе как таковом. Команды попадают в неприятности, когда выносят слишком далеко не ту форму данных. Табличная модель может отлично работать на сервере и при этом быть плохим контрактом для браузера.
Оставляйте модели базы данных внутри серверного кода. В них часто есть поля, которые интерфейс не должен знать: внутренние флаги, внешние ключи, аудиторские столбцы, метки мягкого удаления или поля цены, которые должны видеть только сотрудники финансового отдела. Как только фронтенд начинает зависеть от этих полей, любое изменение схемы превращается в изменение продукта.
Более чистое разделение обычно выглядит так:
- Модели базы данных описывают, как данные живут в хранилище.
- Модели ответа API описывают, что возвращает один endpoint.
- Модели представления описывают, что нужно одному экрану для отображения.
- Код преобразования переводит один слой в следующий.
Модели ответа API должны соответствовать сценарию использования, а не таблице. Endpoint заказов для личного кабинета клиента может нуждаться в номере заказа, статусе, сумме и коротком описании доставки. Тот же заказ в админском экране может требовать состояние возврата, проверки рисков и внутренние заметки. Один общий тип для обоих экранов кажется аккуратным, но он тащит лишние поля везде и провоцирует случайную связанность.
Модели представления могут идти ещё дальше. Экрану могут понадобиться canCancel, statusLabel или isLate, даже если ни одного из этих полей нет в базе данных. Это нормально. Интерфейс работает лучше, когда читает простые и готовые к использованию данные, а не пересобирает бизнес-логику в пяти компонентах.
Поместите преобразование в одно понятное место. Подойдёт сервис, контроллер или файл адаптера. Важно, чтобы всё было последовательно. Когда команда размазывает преобразование по SQL-запросам, обработчикам API, React-компонентам и вспомогательным утилитам, никто уже не понимает, где на самом деле живёт контракт.
Сначала этот дополнительный шаг кажется медленнее. На практике он экономит время. Вы можете переименовывать столбцы, делить таблицы или менять внутреннюю логику, не ломая фронтенд. Для стартапов и небольших команд такая свобода важнее, чем сэкономить десять минут на сгенерированном типе, о котором вы пожалеете в следующем месяце.
Общие типы по-прежнему полезны, но только когда они пересекают границу осознанно. Экспортируйте тот контракт, которому должен доверять другой код, а не детали хранения, которые у вас есть сегодня.
Как настроить более безопасный поток типов
Когда команды переходят от схемы базы данных к клиентскому коду, самый безопасный путь начинается не с базы. Начните с пользовательского действия. Подумайте, что экран должен отправить и что он должен получить назад. «Создать аккаунт», «оплатить счёт» и «загрузить историю заказов» — для каждого нужны свои формы данных. Таблица редко совпадает с ними без натяжки.
Сначала определите типы запросов и ответов. Делайте их небольшими и пишите на языке продукта. Если экран просит «email» и «password», не экспортируйте все поля из таблицы users. Если интерфейс показывает orderStatus, не делайте его зависимым от сырых столбцов вроде paid_at, refund_code или внутренних флагов. Контракт должен описывать функцию, а не хранение.
Генерируйте типы базы данных, но держите их на сервере. Они помогают коду запросов, вставкам и миграциям оставаться честными. Они также делают рефакторинг безопаснее, когда меняется тип столбца. Фронтенд не должен импортировать их. Как только клиент узнаёт названия таблиц и редкие nullable-сценарии, он начинает зависеть от деталей, которые вам, возможно, захочется изменить уже в следующем месяце.
Небольшие мапперы решают большую часть проблемы. Считайте данные из базы в серверный тип, а потом преобразуйте результат в API-модель. Пишите это преобразование вручную. Линий кода будет немного больше, но именно они заставляют принимать чёткие решения.
Простой поток выглядит так:
- UI отправляет тип запроса, основанный на действии пользователя
- Сервер валидирует его и вызывает код работы с базой, используя только серверные типы
- Сервер преобразует строки таблиц в типы ответа для клиента
- Фронтенд импортирует только эти типы запросов и ответов
Такой подход держит каждый слой в рамках. База данных может хранить пять столбцов ради одного статуса, а клиент увидит только status: "paid" | "pending" | "failed". Это и проще использовать, и гораздо безопаснее менять.
Названия важнее, чем думают многие команды. Экспортируйте типы, которые соответствуют языку продукта: OrderSummary, CheckoutRequest, ProfileCard. Избегайте в клиентском коде названий вроде orders_row или public_users_select. Они протекают внутрь и приучают фронтенд-команду мыслить как база данных.
Если нужен один принцип, используйте такой: типы базы данных нужны для хранения, типы API — для поведения. Сохраните это разделение, и общие типы будут помогать, а не привязывать приложение к вчерашней схеме.
Простой пример с заказами
Таблица заказов часто хранит больше, чем когда-либо должен видеть клиент. В ней может быть код статуса, отдельные поля налога, внутренняя заметка для поддержки, флаги мошенничества, данные склада и несколько временных меток. Для хранения это нормально. Для экрана клиента это плохая форма данных.
Предположим, в таблице есть поля status_code, subtotal_cents, tax_amount_cents, delivery_eta и internal_note. На странице клиента обычно нужно гораздо меньше. Нужна итоговая сумма, понятный статус вроде «Отправлено» и ожидаемая дата доставки.
Если вы напрямую проталкиваете типы из схемы базы данных в клиентский код, фронтенд получает все поля, нужны они ему или нет. Кто-то начнёт использовать status_code напрямую. Кто-то другой покажет сырое поле налога просто потому, что оно уже есть. Через месяц бэкенд изменит способ хранения налога или добавит новый код статуса, и экран станет зависеть от внутренних деталей, о которых ему вообще не следовало знать.
Более удачный API-ответ может выглядеть так:
total: 42.50status: "В пути"deliveryDate: "2026-04-14"
Такой ответ делает несколько полезных вещей. Он полностью скрывает internal_note. Он превращает код вроде 4 или out_for_delivery в обычный текст. Он также объединяет subtotal и tax в одну сумму, которую клиент может понять без лишней математики в браузере.
Это важно даже если вам нравятся общие типы. Общие типы лучше всего работают, когда они описывают границу между системами, а не саму базу данных. Клиентский тип должен соответствовать экрану. Если экран никогда не показывает разбивку налога или внутренние комментарии, такие поля не должны попадать в клиентскую модель.
У одного и того же заказа могут быть разные формы для разных задач. Для support-дэшборда может понадобиться internal_note. Для финансового экспорта — все поля налога. Для клиентского приложения — нет. Одна таблица может кормить все три сценария, но каждый API-ответ должен нести только то, что нужно этому пользователю и этому экрану.
Такой маленький шаг делает контракты между фронтендом и бэкендом стабильнее. Он также даёт бэкенду свободу переименовывать столбцы, разделять поля или менять логику статусов, не таща интерфейс через каждое изменение хранения.
Ошибки, которые команды повторяют
Проблемы со схемой базы данных в клиентском коде начинаются тогда, когда команда воспринимает модель базы данных как модель продукта. Сначала это кажется быстрым. Один пакет, один источник истины, никакого кода преобразования. Потом браузер начинает импортировать ORM-типы, и фронтенд уже знает о внутренних флагах, связующих таблицах, полях мягкого удаления и названиях столбцов, которые должны оставаться приватными.
Частый паттерн — проблема «одного огромного типа». Команды используют один и тот же тип для экранов чтения, записи через формы и админских инструментов. С виду это аккуратно, но этим задачам нужны разные формы данных. Модель чтения может включать вычисляемые поля. Модель записи не должна содержать значения, которыми управляет сервер. Админская модель может раскрывать поля, которые обычным пользователям видеть нельзя. Один общий тип превращает все три сценария в компромисс, а компромиссы плохо стареют.
Ещё одна ошибка проявляется в тестах. Тест фронтенда начинает проверять created_at, customer_id или is_deleted, потому что эти имена пришли прямо из базы данных или ORM. Через несколько месяцев бэкенд переименовывает столбец или разбивает одну таблицу на две, и UI-тесты падают, хотя поведение продукта не изменилось. Тест проверял детали хранения, а не то, что видит пользователь.
Крупные рефакторинги делают это ещё хуже. Команды часто пропускают версионирование API-типа, потому что хотят двигаться быстрее. Потом старые и новые клиенты зависят от одной и той же нестабильной формы, и любое изменение превращается в согласованный выпуск. Небольшое переименование может одновременно потребовать обновлений для mobile, web, admin и внутренних инструментов.
Более безопасная привычка проста:
- Держите типы базы данных на сервере.
- Определяйте модели ответа API для того, что должны видеть клиенты.
- Используйте отдельные типы ввода для действий создания и обновления.
- Версионируйте API-типы, когда рефакторинг меняет смысл, а не только названия полей.
Да, это добавляет немного кода. Зато у вас появляется пространство, чтобы переименовать столбец, скрыть внутренний enum или разделить таблицу, не заставляя фронтенд заново учить вашу схему. Команды, которые делают так рано, тратят меньше времени на исправление избегаемых поломок позже.
Быстрые проверки перед экспортом типа
Когда тип переходит из схемы базы данных в клиентский код, относитесь к этому как к продуктовому решению, а не как к короткому пути. Поле может быть валидным в хранилище и всё равно быть неправильным для интерфейса.
Начните с самого простого теста: будет ли это поле понятно пользователю? Если экран показывает заказ, то «status» наверняка понятен. deleted_at, internal_score или last_recalculated_by_job — обычно нет. Фронтенд-код должен описывать то, что нужно интерфейсу, а не тащить каждый столбец просто потому, что он существует.
Второй тест более практичный. Если бы кто-то завтра переименовал столбец, сломался бы экран без веской причины? Если ответ «да», значит UI слишком тесно зависит от деталей хранения. Это тревожный сигнал. Экран должен зависеть от API-модели, которая меняется только тогда, когда меняется поведение для пользователя.
Короткая проверка отлавливает большую часть плохих экспортов:
- Удаляйте поля, которые пользователи никогда не видят и не используют.
- Исключайте секреты, аудиторские данные и внутренние флаги.
- Проверяйте, заставит ли переименование в схеме менять фронтенд.
- Спрашивайте, остаётся ли поле понятным, если не упоминать таблицы и столбцы.
Последняя проверка строже, чем кажется. Попробуйте объяснить каждое поле дизайнеру, специалисту поддержки или продакт-менеджеру. Если вам приходится говорить «это из связующей таблицы» или «это нужно базе для синхронизации», такое поле, вероятно, должно оставаться за API, а не в клиентском типе.
Простой пример хорошо это показывает. Допустим, запись заказа в базе включает fraud_review_state, payment_retry_count, archived_by и updated_at. Экран клиента может нуждаться только в orderNumber, status, total и canCancel. Экспортировать всю запись кажется быстрым решением в первый день. Через месяц фронтенд начинает ветвиться по внутренним флагам, и уборка становится дорогой.
Общие типы лучше всего работают, когда описывают стабильный смысл. Они создают проблемы, когда раскрывают выбор, сделанный ради хранения. Если тип читается как строка таблицы, остановитесь и сократите его до того, как он начнёт расползаться.
Что делать дальше
Начните с небольшого аудита. У большинства команд уже есть больше общих типов, чем они думают, и часть из них, вероятно, пришла прямо из базы данных без осознанного решения.
Составьте короткий список всех типов, которые ваш клиент импортирует сегодня. Напротив каждого отметьте, откуда он появился: определение таблицы, модель ORM, вручную написанный API-тип или маппер, сделанный для одного экрана.
Такой простой проход обычно быстро показывает настоящую проблему. Если фронтенд-страница зависит от названий столбцов, nullable-полей, форм связей или внутренних значений статуса, граница проведена слишком низко. Клиент читает детали реализации, а не продуктовый контракт.
Практичный следующий шаг — проверить один экран, а не менять всё сразу:
- Выберите один экран с несколькими чтениями и одной записью
- Замените импорты на основе таблицы или ORM на модели ответа API, сделанные именно для этого экрана
- Добавьте небольшой слой преобразования на сервере
- Сравните результат после одного обычного запроса на изменение
Сравнение обычно очевидно. При API-first типах фронтенд меняется меньше, когда меняется схема. Проверки кода тоже становятся проще, потому что люди обсуждают, что должен получить клиент, а не то, что база данных просто хранит.
Если вы работаете в команде, которая уже много лет живёт на переходе от схемы базы данных к клиентскому коду, не пытайтесь чинить весь стек за один проход. Двигайтесь экран за экраном. Некоторое время поддерживайте оба подхода, а потом уберите общие типы базы данных, когда их уже никто не импортирует.
Некоторым командам нужен взгляд со стороны, потому что эта граница проходит между продуктом, бэкендом и фронтендом. Консультация Oleg's Fractional CTO advisory может просмотреть архитектуру, показать, где общие типы всё ещё имеют смысл, и помочь выстроить более чистые контракты без большого переписывания.
Хороший результат прост: клиент импортирует типы, которые описывают UI и API, а не таблицы под ними.


