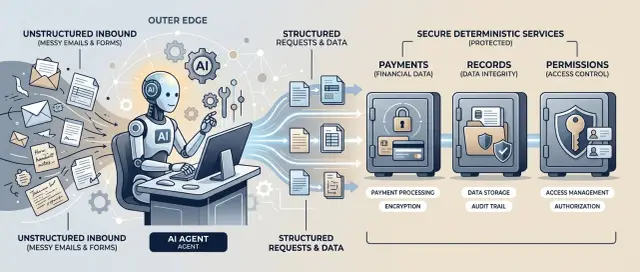
От no-code MVP к стабильному продукту без большой команды
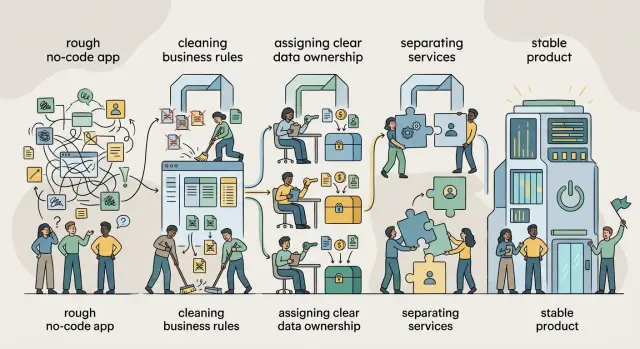
Переход от no-code MVP к стабильному продукту — это наведение порядка в правилах, назначение владельцев данных и разделение сервисов в правильном порядке, без слишком раннего найма большой команды.
Содержание
Почему no-code MVP начинает ломаться
Вначале no-code MVP кажется надежным, потому что у него только одна задача: проверить спрос. Проблемы начинаются позже, когда той же быстрой сборке нужно обрабатывать возвраты, крайние случаи, ручные правки администратора и растущий набор исключений.
Ранние упрощения — это нормально. Основатель копирует правило, чуть меняет фильтр, добавляет еще одну таблицу и подправляет workflow, чтобы успеть к запуску. Каждое изменение по отдельности выглядит безобидно. Но через несколько месяцев в приложении уже может быть пять мест, которые решают, кто может редактировать заказ, три поля, означающие почти одно и то же, и автоматика, которая срабатывает не в том порядке.
После этого даже небольшие изменения становятся рискованными. Новое правило ценообразования ломает счета. Обновление формы скрывает данные, которые все еще ожидает другой экран. Одна правка создает еще две ошибки, потому что никто не знает, какой workflow на самом деле принимает решение.
Приложение для бронирования хорошо показывает этот сценарий. Сначала хватает одной базы данных и нескольких автоматизаций. Потом команда добавляет купоны, права сотрудников, переносы записей, напоминания, депозиты и ручные исключения. Теперь статус брони живет в нескольких местах, а support не может объяснить, почему с одного клиента списали деньги дважды, а у другого платеж вообще не прошел.
Еще один признак — когда основатель становится живым мостом между системами. Support спрашивает, что значит тот или иной статус. Финансы спрашивают, почему суммы не сходятся. Операционная команда спрашивает, какая автоматика должна победить. Если одному человеку приходится объяснять приложение по памяти, продукт уже перерос форму MVP.
Нанимать больше людей слишком рано редко помогает. Новые разработчики или операционные специалисты попадают в лабиринт правил без понятного владельца. Они двигаются осторожно, задают одни и те же вопросы и все равно мешают друг другу работать. Скорости не становится. Появляется только больше неопределенности.
No-code MVP становится стабильным продуктом, когда команда сначала наводит порядок в структуре, а уже потом увеличивает штат. Понятные правила, четкое владение данными и аккуратные границы дают продукту пространство для роста. Без такой уборки каждая новая функция стоит дороже, чем должна, а каждый релиз ощущается менее безопасным.
Что исправить до найма
Переход от no-code MVP к стабильному продукту усложняется по простой причине: приложение начиналось как быстрый эксперимент, а потом стало местом, где живет все. Прежде чем добавлять людей, приведите в порядок уже существующие части, которые путают продукт.
Начните с правил. Если цены, approvals, доступ пользователей или смена статусов живут в трех-четырех местах, команда будет постоянно спотыкаться о них. Основатель правит один workflow, подрядчик меняет правило в таблице, а старая автоматизация все еще работает в фоне. Приложение может работать большую часть времени, но никто не сможет сказать, какое правило действительно главное.
Следом идут проблемы с данными. Дубликаты быстро подрывают доверие. Если статус клиента хранится в приложении, CRM и billing-инструменте, отчеты перестают совпадать. Support видит один ответ, финансы — другой, а основатель начинает вручную проверять выгрузки. Это не просто раздражает. Это тормозит каждое решение, потому что люди сначала спорят о цифрах, а уже потом — о способе исправления.
Смешение разных задач в одном приложении создает еще одну проблему. Многие MVP одновременно обрабатывают регистрацию, оплату, админскую работу, внутренние заметки, отчеты и письма. На старте это кажется удобным. Позже небольшое изменение в одном потоке заставляет команду тестировать еще пять несвязанных. Выпуски замедляются, потому что у приложения нет четких границ.
Хаос обычно заметен в обычной работе. Сотрудник support не может понять, можно ли редактировать заказ. Менеджер по продажам видит клиента как активного, а billing показывает неуспешную оплату. Разработчик добавляет одно поле формы — и вдруг перестают уходить письма-напоминания. Это не отдельные баги. Это признаки того, что владение неясно.
Сначала исправьте самые рискованные части: правила, связанные с деньгами, доступом или поведением клиента; дубли записей, которые меняют отчеты или ответы support; и потоки, которые ломаются, когда небольшое обновление попадает в другое место. Полировку интерфейса и замену инструментов можно отложить, если они не убирают риск сразу.
Если нанимать до этой уборки, новые люди первые недели будут разбирать старые обходные решения. Небольшая команда с понятными правилами и одним надежным источником данных обычно движется быстрее, чем большая команда в запутанном приложении.
Сначала наведите порядок в правилах
Прежде чем делить системы или добавлять людей, разберитесь с правилами. Большинство no-code-приложений превращаются в хаос потому, что одно и то же правило спрятано в формах, automations, админских экранах и email-потоках. Тогда одно маленькое изменение превращается в четыре правки, и одну из них обычно пропускают.
Начните с простого языка. На минуту забудьте про названия инструментов и блоки логики. Запишите каждое правило так, как его описал бы коллега или сотрудник support: «платящие пользователи могут экспортировать», «возврат требует одобрения менеджера», «отправить уведомление, если платеж не прошел дважды». Если правило нельзя объяснить одним предложением, скорее всего, оно делает слишком много.
Потом сгруппируйте правила по задачам. Правила billing должны быть вместе. Правила доступа — вместе. Правила approvals — вместе. Правила уведомлений — вместе. Такой быстрый проход показывает, где именно начинается беспорядок. Логика billing часто появляется в checkout, счетах, страницах аккаунта и админских инструментах. Логика доступа часто живет и в приложении, и в админ-панели. Когда одно и то же правило встречается больше чем в одном месте, отметьте это. Именно там начинается расхождение.
После этого выберите одно место, которое владеет каждым правилом. Если trial заканчивается через 14 дней, решать это должна одна система. Все остальные экраны должны читать результат, а не заново создавать логику. Если два места могут менять одно и то же решение, команда будет отлаживать одну и ту же ошибку снова и снова.
Полезно проверить правила на нескольких реальных случаях. Возьмите пять недавних обращений в support или крайних сценариев и прогоните их через список правил. Если команда все еще спорит, что должно произойти, значит правило пока недостаточно ясно. Это звучит просто. И работает.
Представьте SaaS-продукт, который дает скидку на годовой тариф, блокирует экспорт для просроченных аккаунтов и требует одобрения на возвраты выше определенной суммы. Во многих MVP эти правила копируются в страницы checkout, админские формы и email-автоматику. Спустя полгода support находит клиента, который все еще может экспортировать данные, хотя billing уже не прошел. Баг не случайный. Правило жило в нескольких местах.
Цель — не идеальный документ политики. Цель в том, чтобы любой человек в команде мог без догадок ответить на простые вопросы: кто может оформить возврат, кто может экспортировать, когда аккаунт теряет доступ, когда срабатывает уведомление. Lean-команды делают эту работу рано, потому что чистые правила уменьшают переделку, снижают риск релизов и упрощают каждый следующий шаг.
Определите, кто владеет каждым кусочком данных
Проблемы начинаются, когда один и тот же клиент, заказ или подписка живет в трех инструментах, и каждый рассказывает свою версию истории. Команда потом тратит время на проверку таблиц, исправление сломанных синхронизаций и ручные ответы на простые вопросы.
Начните с записей, в которых нельзя ошибаться: карточки клиентов, статус оплаты и подписки, доступ к функциям и права пользователей, заказы, счета, возвраты и любые внутренние заметки, которые влияют на support или delivery. Для большинства команд этот список короткий. И это хорошо. Значит, важные вещи можно решить в первую очередь.
После этого назначьте одну систему владельцем каждой записи. Одно место создает ее, хранит исходную версию и решает, что является истиной. Другие инструменты могут читать ее, копировать для отчетов или использовать в workflows, но не должны незаметно перезаписывать ее.
Обычно хорошо работает простая схема. Ваш billing-инструмент владеет статусом оплаты. База данных приложения владеет доступом к функциям. CRM владеет заметками по продажам и историей контактов. Если два инструмента могут редактировать одно и то же поле, выберите одного победителя и запретите другому делать запись обратно.
Запишите правила и держите их простыми. Правки нужно вносить сначала в системе-владельце. Скопированные данные должны сохранять исходный ID записи. Синхронизация должна идти в одну сторону, если только нет понятной причины усложнять ее. Удаления требуют особой осторожности, а скопированные данные никогда не должны случайно стирать источник.
Временные метки тоже важны. Когда данные переходят между системами, фиксируйте, когда произошло обновление и откуда оно пришло. Это сильно упрощает работу support. Вместо фразы «где-то сломалась синхронизация» команда видит, что billing обновился в 10:03, приложение скопировало статус в 10:04, а help desk еще показывал старое значение в 10:01.
Возьмем типичный пример. Пользователь меняет email в приложении, оплачивает через Stripe и обращается в help desk. Если приложение владеет профилем, изменение email начинается там, а потом распространяется дальше. Stripe по-прежнему владеет billing-фактами вроде paid, failed или refunded. Help desk может копировать email, но support-сотрудники не должны случайно становиться источником правды.
Этот шаг кажется скучным. Но он экономит огромное количество будущей переделки. Когда у каждого кусочка данных есть свой дом, ошибки синхронизации проще отследить, а небольшая команда может удерживать продукт в стабильном состоянии без слишком раннего найма.
Задайте границы сервисов по реальной работе
Переход от no-code MVP к стабильному продукту становится легче, когда каждый сервис соответствует реальной бизнес-задаче. Не делите систему по инструментам, фреймворкам или тому, кто построил ее первым. И не делите ее по названиям команд. Делите по тому, что бизнес действительно делает каждый день.
Большинству небольших команд нужно меньше сервисов, чем кажется. Если слишком рано создать шесть крошечных сервисов, вы получите больше deploy, больше логов, больше точек отказа и больше времени на поиск багов между системами. Два-три понятных блока обычно лучше, чем десять аккуратных схем.
Хорошая проверка простая: можете ли вы описать каждый сервис одним предложением, не называя инструмент? Если нет, граница, скорее всего, слабая. «Отвечает за billing и счета» — понятно. «Запускает Node service» — не говорит ничего полезного о задаче.
Для многих продуктов практичное начальное разделение выглядит так. Одна часть владеет профилями клиентов, настройками аккаунта, правами доступа и заметками support. Другая владеет тарифами, счетами, статусом оплаты и продлениями. Третья занимается основной задачей, ради которой пользователи вообще пришли в приложение. Сервис уведомлений может отправлять письма или сообщения, но он не должен решать правила billing или доступа пользователей.
Данные о клиентах и данные о billing лучше держать отдельно, даже если сначала они живут в одной базе данных. Это звучит скучно, но позже спасает от большого количества боли. Ваше приложение может спрашивать: «Этот аккаунт активен?» — на это должен отвечать billing-блок. Он не должен позволять клиентской части переписывать счета или историю платежей.
Отчеты — хороший пример того, где команды переусердствуют. Отчеты часто нуждаются в данных из нескольких источников, но это не значит, что reporting должен владеть этими записями. Он может читать данные клиентов, billing и продукта. Но он не должен становиться местом, где их редактируют только потому, что кому-то нужен удобный админский экран.
Запишите ограничения для каждого сервиса. Коротко. Для каждого нужна заметка: какие данные он владеет, что может менять, что может только читать, и какие события или API-вызовы могут использовать остальные части. Обычного текстового файла достаточно. Смысл не в документации ради документации. Смысл в том, чтобы в момент поломки команда понимала, где искать проблему.
Порядок, который снижает риск
Самый безопасный путь от no-code MVP к стабильному продукту — намеренно немного скучный. Команды попадают в неприятности, когда переписывают логику, переносят данные и добавляют функции одновременно. На неделю это кажется быстрым. Потом список багов становится неприятным.
Сначала сделайте текущий продукт видимым. Вам нужна простая карта каждого экрана, каждой автоматизации, каждой таблицы и всех передаточных точек между ними. Если экран регистрации пишет в три места и запускает два фоновых действия, запишите это до любых изменений. Если у support есть ручной обходной способ, тоже запишите. Скрытые ручные шаги часто объясняют, почему система вроде бы работает, пока вы не попробуете что-то изменить.
- Сначала выберите одну рискованную область. Возьмите ту часть, которая ломается чаще всего, мешает выручке или путает support. Заказы, платежи, регистрация и права доступа — частые хорошие стартовые точки.
- Заморозьте работу над функциями в этой области. Короткая заморозка экономит время, потому что команда перестает двигать цель, пока вы переносите основные правила.
- Сначала перенесите правила, потом полировку. Поместите бизнес-логику в одно понятное место, даже если интерфейс пока останется прежним.
- Проверьте старый и новый сценарии рядом. Прогоните один и тот же ввод через оба пути и сравните результат. Маленькие расхождения важны.
- Переносите по одной границе за раз и ведите заметки. Когда вы отделяете сервис или передаете владение данными, записывайте, что изменилось, кто теперь владеет этим, и от чего это зависит.
Такой порядок делает сбои маленькими. Если новый сценарий оформления заказа сломается, вы будете знать, где искать, потому что меняли одну границу, а не пять. Support тоже получает более простой рассказ: «новая логика checkout, старая зона аккаунта». Это делает инциденты менее запутанными для клиентов и менее стрессовыми для команды.
Хорошее правило: сначала закончить очистку правил, а уже потом делить сервисы. После этого решить, кто владеет каждой частью данных. И только затем рисовать границы вокруг этой работы. Если сделать наоборот, вы обычно просто переносите тот же хаос в новую кодовую базу.
После каждого шага остановитесь достаточно надолго, чтобы посмотреть на реальное использование. Проверьте обращения в support, упавшие задачи, странные ручные правки и несоответствия в billing. Если один и тот же странный случай повторяется, уборка еще не завершена.
Эта пауза кажется медленной, но она дешевле, чем обнаружить ту же ошибку после еще трех миграций.
Именно такой последовательности придерживаются опытные CTO, когда превращают сырой продукт во что-то, что небольшая команда может поддерживать без паники. Медленный старт часто означает меньше откатов позже.
Простой пример из реального продукта
Небольшое приложение для бронирования часто начинается как один no-code поток. Клиент заполняет форму, выбирает время, получает напоминание и оплачивает. Одна таблица хранит все: данные клиента, статус брони, флаги напоминаний, заметки по оплате и, возможно, текстовое поле для комментариев сотрудников.
Для MVP это работает. Но потом бизнес добавляет реальные правила: буфер между встречами, разные окна отмены для каждой услуги, депозиты для одних бронирований и не для других, ограничения на количество активных записей у одного клиента.
Первый шаг — не платежи. Сначала нужно навести порядок в правилах. Если команда меняет логику оплаты, пока правила бронирования все еще меняются каждую неделю, она в итоге будет переделывать один и тот же путь дважды.
Команда выносит правила бронирования в один небольшой сервис или в один явно владеемый модуль. Эта часть решает, свободен ли слот, разрешен ли перенос, какая комиссия применяется и что происходит, когда клиент отменяет запись. Форма по-прежнему собирает запрос, но больше не принимает решение о правилах сама. Это быстро убирает странные крайние случаи.
Дальше команда выбирает одну карточку клиента как доверенную версию. Имя, email, телефон, согласие и история бронирований живут в одном месте. Напоминания могут читать эту запись. Платежи тоже могут ее читать. Никто не редактирует данные клиента в трех разных таблицах и не надеется, что потом все совпадет. Support тоже выигрывает: сотрудники могут отвечать на простые вопросы, не переключаясь между четырьмя экранами.
После этого внедрение можно оставить простым. Сначала сохраняются старые формы, но правила бронирования переносятся в одно место. Потом наводится порядок в карточках клиентов и объединяются дубликаты. После этого напоминания начинают читать те же данные о клиенте и брони. Платежи переносятся последними, уже после того, как поток бронирования перестает меняться каждую неделю.
Этот порядок важен. Платежи затрагивают чеки, неуспешные списания, возвраты, споры по платежам и политики поддержки. Если команда переносит их слишком рано, обычно получается связать возвраты с системой бронирования, которая еще не может уверенно сказать, был ли это поздний отказ, исключение со стороны сотрудников или неявка.
Один случай это показывает особенно хорошо. Клиент бронирует массаж на пятницу, переносит его на субботу, а потом отменяет за два часа до визита. Если правила бронирования живут в одном месте, приложение может определить комиссию, обновить слот, освободить календарь сотрудника и запустить нужную логику напоминаний. Если правила, данные клиента и платежи раскиданы по разным no-code-веткам, кто-то в итоге все исправляет вручную и надеется, что счет потом совпадет.
Именно так lean-команда сохраняет контроль. Сначала двигать самую загруженную логику, потом очищать слой за слоем и после каждого изменения оставлять продукт проще, чем он был.
Ошибки, которые создают лишнюю переделку
Самая дорогая ошибка — переписывать интерфейс до того, как вы исправили модель данных. Более аккуратный дизайн ощущается как прогресс, но слабые поля и запутанные связи между записями все равно заставят вас переделывать эти экраны снова. Команды часто тратят две недели на визуальную полировку, а потом еще четыре — на переименование полей, разбиение записей или изменение прав доступа.
Еще одна частая ошибка — переносить правила из no-code-инструмента, не записав их сначала. Если никто не сформулировал правила простыми словами, одно и то же правило окажется в формах, автоматизациях и backend-коде, но уже с небольшими отличиями. Тогда одного клиента одобряют, другого блокируют, и никто не понимает, какой результат правильный. Хорошо работает простой формат: «Когда происходит X, Y может измениться, если истинно Z».
Некоторые команды совершают противоположную ошибку: документируют все, кроме реального поведения. Получаются красивые схемы, но никто не проверяет их на свежих обращениях в support или реальных возвратах. Документация помогает только тогда, когда она совпадает с тем, что продукт действительно делает сегодня.
Слишком раннее создание слишком большого числа сервисов приводит к другому виду потерь. Небольшому продукту не нужны отдельные сервисы для пользователей, billing, уведомлений, отчетности и административной работы только потому, что так красиво смотрится на схеме. Больше сервисов — это больше шагов для deploy, больше точек отказа и больше времени, потраченного на соединение систем вместо исправления самого продукта.
Конфликты данных еще хуже. Если две системы могут редактировать одну и ту же карточку клиента, счет или заказ, расхождение начинается очень быстро. Один инструмент говорит, что заказ оплачен, другой — что он в ожидании, и ваша команда тратит время на поиск того, какое изменение произошло первым. Назначьте одного владельца для каждой записи, а все остальные системы либо пусть читают данные из него, либо запрашивают изменения через него.
Слишком ранний найм узких специалистов может закрепить неправильную структуру. Если форма продукта все еще меняется каждый месяц, большая команда обычно создает больше передач между людьми, больше споров и больше кода, который потом придется выбросить. На этом этапе один опытный технический лидер или Fractional CTO обычно полезнее, чем три узких специалиста.
Проблемы обычно видны заранее. Команда начинает говорить о «rewrite», хотя еще не может объяснить текущие правила. Два инструмента меняют одно и то же поле статуса. Новые сотрудники спрашивают, какая система на самом деле решает, что правда. Схемы выглядят аккуратно, но небольшие изменения продукта по-прежнему занимают дни.
Если вам нужен lean-путь от no-code MVP к стабильному продукту, сначала исправьте владение и правила. Потом рисуйте границы вокруг той работы, которая уже некоторое время остается стабильной.
Быстрые проверки перед каждым релизом
Перед нажатием deploy релиз должен ответить на пять простых вопросов. Если команда не может сделать это за две минуты, продукт все еще слишком запутан.
Сначала проверьте владение. Кто-то должен уметь сказать, кто владеет карточками клиентов, billing-данными, правами доступа и журналами событий. Если два человека дают разные ответы, баги будут мигать туда-сюда и оставаться открытыми дольше.
Потом проверьте правила. Попросите одного человека объяснить, где сегодня живут правила ценообразования, доступа и approvals. Здоровый продукт не разбрасывает одно и то же правило по формам, automation, скриптам и обходным решениям support. Когда одно правило живет в трех местах, четвертым местом становится ночной патч.
Короткий список для релиза помогает держать это под контролем:
- Назовите владельца для каждого набора данных, которого касается релиз.
- Укажите единственное место, где живет каждое измененное правило.
- Измените одну функцию в staging и посмотрите, что еще сдвинется.
- Проверьте недавние обращения support на повторяющуюся боль в одной области.
- Отрепетируйте откат до того, как он понадобится.
Третья проверка быстро показывает неожиданные зависимости. Если небольшое изменение onboarding ломает счета, письма или отчеты, ваши границы все еще размыты. Исправьте это до того, как добавлять еще код или еще людей. Найм в запутанную систему только распространяет беспорядок.
Держите и объем релиза небольшим. Если deploy одновременно меняет правила billing, синхронизацию данных и админский интерфейс, будет трудно понять, что именно вызвало проблему. Маленькие релизы проще тестировать, проще объяснять и гораздо проще откатывать.
Обращения в support говорят правду. Если одна и та же проблема возвращается снова и снова, значит эта область слаба по конструкции, а не по плохой удаче. Повторяющиеся ручные исправления обычно означают, что одно правило неясно, одного владельца данных не хватает или один сервис делает слишком много.
Откат — последняя проверка, и многие команды откладывают его до момента, когда плохой релиз уже случился. Вам нужен простой ответ на один вопрос: можем ли мы отменить это изменение за минуты, а не за часы? Если ответ отрицательный, релиз слишком большой.
Именно на этом этапе переход от no-code MVP к стабильному продукту часто удается или проваливается. Небольшая команда может безопасно выпускать изменения, если каждый релиз остается скучным, понятным и легко обратимым.
Что делать дальше без большой команды
Когда вы переводите no-code MVP в стабильный продукт, следующий шаг — это редко «нанять еще людей». Больше пользы обычно дает последовательная очистка одной рискованной области за другой. Шум может подождать. Первым делом должны идти баги, которые ломают billing, workflow, редактируют не ту запись или создают недоверенные передачи между инструментами.
Лучше работает простой 30-дневный план, чем большая переделка. На первой неделе выберите область с самым высоким бизнес-риском и составьте карту текущих правил. На второй — уберите дублирующую логику и запишите, кто владеет каждой записью и каждым полем. На третьей — разделите один workflow или одну границу сервиса, чтобы изменения перестали расползаться по всему продукту. На четвертой — проверьте реальные случаи, аккуратно выкатывайте изменения и фиксируйте, что все еще кажется хрупким.
Такой темп может казаться медленным. Но обычно он быстрее, чем добавить трех человек, которые по-разному представляют, как работает продукт.
Держите команду небольшой, пока границы выдерживают обычные изменения. Если один человек может поменять цены, не сломав onboarding, а другой — изменить onboarding, не трогая billing, значит вы уже продвинулись. Вот тогда дополнительные руки начинают помогать, а не создавать новую переделку.
Внешний взгляд со стороны полезен, когда команда застряла или слишком близко к хаосу. Хороший Fractional CTO не будет предлагать грандиозный редизайн только для того, чтобы работа выглядела серьезнее. Он должен помочь выбрать следующую проблему, сузить объем и задать порядок, который снижает риск. И еще — удерживать архитектуру достаточно бережной, чтобы небольшая команда действительно могла ее обслуживать.
Именно здесь естественно может подключиться Oleg Sotnikov. На oleg.is его работа как Fractional CTO сосредоточена на бережной архитектуре, практичной последовательности изменений и AI-first-операциях в software, что часто как раз и нужно запутанному MVP перед большим rebuild или большим наймом.
Если в следующем месяце вы сделаете только одну вещь, сделайте вот что: выберите область, которая может сильнее всего навредить бизнесу, полностью приведите ее в порядок и оставьте после себя четкую границу. Потом повторите тот же подход на следующем слабом месте.
Часто задаваемые вопросы
Как понять, что мой no-code MVP перерос свою исходную структуру?
Ваш MVP перерос начальную форму, если небольшие изменения все время ломают несвязанные части приложения. Еще один сильный признак — когда одному человеку приходится объяснять статусы, суммы или результаты workflow по памяти, потому что сам продукт уже не дает эти ответы достаточно ясно.
Стоит ли нанимать больше людей до того, как я наведу порядок в приложении?
Нет. Сначала наведите порядок в рискованных местах. Если нанимать людей в запутанное приложение, они будут тратить время на расшифровку старых обходных решений вместо того, чтобы делать продукт безопаснее и быстрее.
Что нужно исправить в первую очередь перед масштабированием продукта?
Начните с того, что связано с деньгами, доступом или поведением клиента. Правила цен, возвраты, права доступа, статус брони и дубли записей обычно наносят больше всего ущерба, когда начинают расходиться.
Как навести порядок в бизнес-правилах, не усложняя все лишний раз?
Сначала запишите каждое правило простыми словами, например: «возвраты требуют одобрения» или «после неуспешного платежа доступ закрывается через 14 дней». Потом сгруппируйте похожие правила и выберите одно место, которое принимает решение по каждому из них, чтобы остальные части приложения только читали результат.
Как выбрать источник правды для данных?
Назначьте одного владельца для каждой важной записи. Пусть ваш billing-инструмент владеет платежными фактами, приложение — доступом к функциям, а CRM — заметками по продажам. Остальные инструменты не должны тихо править то же самое поле.
Нужны ли microservices, чтобы уйти от no-code MVP?
Обычно нет. Большинству небольших продуктов нужны несколько понятных границ, а не набор крошечных сервисов. Разделяйте работу по бизнес-задачам — например, billing, клиентские аккаунты и основной пользовательский поток — и оставляйте каждую часть понятной в одном предложении.
Какой самый безопасный порядок перехода от no-code к стабильному продукту?
Сначала составьте карту текущего продукта: экраны, automations, таблицы и ручные обходные шаги. Затем выберите одну рискованную область, на время заморозьте там изменения, перенесите правила в одно место, проверьте старый и новый сценарии рядом друг с другом и только потом меняйте владение данными или границы сервисов.
Почему переносить платежи лучше позже, а не сразу?
Потому что платежи зависят от правил, которым сначала нужно доверять. Если правила бронирования, approvals или статуса аккаунта меняются каждую неделю, ранний перенос платежей только привяжет чеки, возвраты и неуспешные списания к нестабильной логике.
Как понять, что релиз слишком рискованный?
Считайте релиз слишком рискованным, если команда не может быстро ответить, кто владеет затронутыми данными, где живет каждое измененное правило и как откатить изменения за минуты. Если один deploy меняет billing, логику синхронизации и админские экраны одновременно, сократите объем.
Когда есть смысл привлекать Fractional CTO?
Приглашайте Fractional CTO, когда команда застряла, правила постоянно «плывут» или никто не согласен с правильной очередностью работы. Хороший специалист должен уменьшать объем, прояснять владение и помогать оставить более простые границы вместо того, чтобы толкать к большой переделке.