Ошибки пагинации API, которые ломают экспорты и синхронизацию
Ошибки пагинации API могут заставлять экспорты и задачи синхронизации пропускать или дублировать записи. Узнайте про стабильную сортировку, надёжные курсоры и правила повтора, которые работают в масштабе.
Содержание
Почему баги пагинации остаются незамеченными
Баги пагинации часто проходят ранние тесты, потому что маленькие наборы данных слишком аккуратны. Список из 200 строк часто возвращается в одном и том же порядке, даже если API этого не обещал. Поэтому такие ошибки могут годами сидеть в проде.
Маленькие аккаунты не создают достаточно нагрузки, чтобы проявить проблему. Разработчик экспортирует десять страниц, сравнивает итоги, и всё кажется в порядке. Баг проявляется позже, когда у одного клиента 800 000 записей и задача читает достаточно долго, чтобы данные успели измениться в процессе.
Новые записи усугубляют ситуацию. Пока синхронизация читает страницу 3, свежие строки могут попасть в начало страницы 1 или где‑то посередине порядка сортировки. Если API сортирует по нестабильному полю или многие строки имеют одинаковую метку времени, записи перемещаются между страницами во время прогона. Одна страница «украдёт» строки у следующей, а следующая об этом не узнает.
Крупные аккаунты обнаруживают разрывы, потому что они создают больше совпадений, больше обновлений и больше времени между первым и последним запросом. Экспорт на десять секунд может выглядеть нормально. Экспорт на два часа по активным данным — совсем другая история. Именно тогда слабые курсоры, пагинация через offset и нестабильная сортировка начинают терять или дублировать строки.
Проблема остаётся тихой. Пропущенные строки обычно не вызывают ошибок, потому что API продолжает возвращать валидные ответы, и задача всё равно завершается. Бухгалтерия может заметить отсутствующий счёт через недели. Аналитический отчёт может оказаться слегка заниженным, но никто не свяжет это с одной ошибочной границей страницы.
Тестирование на «спокойном» наборе даёт ложное чувство безопасности. Чтобы поймать такую ошибку, нужны данные, которые меняются пока идёт экспорт, а не после него.
Как записи пропускаются или дублируются
Большинство пропусков и повторов приходят от одной простой причины: набор данных меняется, пока клиент проходит по нему страницу за страницей. Маленький аккаунт может этого не показать. Большой — обычно покажет.
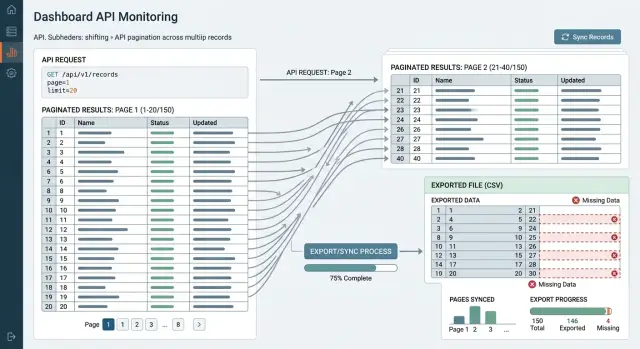
Первая ловушка — нестабильная сортировка. Если API сортирует по полю вроде updated_at, многие строки могут иметь одинаковое значение. Когда база по‑разному разбивает такие «ничьи» при следующем запросе, границы страниц сдвигаются. Последний элемент страницы 1 может снова появиться на странице 2, или одна запись может проскочить обе страницы и исчезнуть из экспорта.
Несколько паттернов вызывают большинство ошибок пагинации. Эндпоинт может сортировать по полю, которое меняется между запросами. Две или более строки могут иметь одинаковое значение сортировки без фиксированного тай‑брейкера. Пользователь может отредактировать строку после прочтения страницы 1, что смещает её вперёд или назад в результирующем наборе. Строка может быть удалена, и тогда все последующие оффсеты смещаются на одну позицию.
Пагинация через offset ухудшает всё это. Представьте задачу, которая запрашивает по 1000 записей за раз. Она читает страницу 1 с offset=0, затем страницу 2 с offset=1000. Если одна из ранних строк исчезает до второго вызова, старая запись с номером 1001 становится 1000. Задача её пропускает. Если рядом с началом появляется новая строка, задача может прочитать одну старую строку дважды.
Обновления создают хаос даже без вставок и удалений. Предположим, синхронизация сортирует по updated_at asc. Запись на странице 4 редактируется после чтения страницы 1. Её метка времени прыгает вперёд. Теперь она может попасть на страницу 7. Если задача использует слабый курсор или plain offsets, она может полностью пропустить эту запись или снова подтянуть её с нового места.
Вот почему такие баги остаются скрытыми неделями. Эндпоинт возвращает валидные страницы. Каждая страница по‑отдельности выглядит нормально. Разрыв происходит через несколько запросов, при реальном трафике, когда записи продолжают двигаться.
Сначала зафиксируйте стабильный порядок сортировки
Страничный токен не спасёт порядок, который движется. Если записи меняют позиции, пока идёт экспорт, задача может пропускать и повторять строки без видимой ошибки.
Начните со сортировки, которая остаётся фиксированной на протяжении жизни каждой записи. Частый выбор — created_at ASC, id ASC. Это работает, потому что время создания обычно не меняется, а id даёт каждой записи точное место в последовательности.
Команды часто сортируют только по метке времени и считают, что этого достаточно. Это не так. Если 4 000 записей имеют одну и ту же секунду, база может вернуть эти одинаковые метки в разном порядке в разных запросах. Страница 1 может закончиться записью 812, а страница 2 начаться с 815, при этом 813 и 814 тихо потеряются между ними.
Стабильная сортировка следует трём простым правилам. Используйте поле, которое не «дрейфует» во время экспорта. Добавьте второе поле, которое уникально — обычно id. Сохраняйте точно ту же сортировку на каждой странице.
Именно в updated_at начинается много проблем. Оно кажется полезным, но каждое редактирование может сдвинуть запись вперёд или назад, пока задача всё ещё читает страницы. Это подходит для представления «последних изменений», но плохо подходит для полного экспорта.
Держите правило сортировки идентичным от первого до последнего запроса. Не сортируйте первую страницу одним способом, а последующие — иначе. Даже небольшое несовпадение может создать баги, которые проявятся только у больших аккаунтов с активными данными.
Тестируйте на «грязных» данных, а не на чистых примерах. Создайте тысячи записей с одной и той же меткой времени, затем вытащите все страницы и сравните итог с исходной таблицей. Каждая запись должна появиться ровно один раз. Если одна строка исчезает или появляется дважды, исправьте сортировку прежде, чем лезть в курсоры, повторные попытки или логику синхронизации.
Делайте курсоры, которые держатся под нагрузкой
Курсор должен возвращать следующую страницу ровно с того места, где остановилась предыдущая, даже когда приходят новые строки. При реальном трафике курсор, который хранит только last_id или номер страницы, начинает «дрейфовать».
Храните поля, которые определяют порядок сортировки, а не только один id. Если эндпоинт сортирует по created_at в нисходящем порядке, курсор должен нести эту временную метку и id, использованное как тай‑брейкер. Во время импорта, пакетной записи или пиковых часов многие строки могут иметь одинаковую метку.
На практике курсор часто требует четырёх небольших полей состояния: значение сортируемого поля, id‑тай‑брейкер, направление сортировки или версия курсора и подпись или checksum.
Тай‑брейкер легко пропустить и дорого потом исправлять. Представьте: одна страница заканчивается тремя записями с одинаковым created_at. Если курсор запомнит только временную метку, следующий запрос может повторить одну запись или перепрыгнуть одну. Это тот баг, который молча живёт неделями, а затем ломает крупный экспорт.
Относитесь к курсору как к ненадёжному вводу. Клиенты могут его редактировать, логи обрезать, старые приложения присылать повреждённые значения. Подписывайте курсор или хотя бы валидируйте каждое поле и отклоняйте значения, которые не соответствуют правилам эндпоинта. Ясная ошибка лучше, чем молчаливое откатывание на первую страницу или стандартную сортировку.
Держите старые форматы курсоров читаемыми при изменении эндпоинта. Добавьте поле версии, поддерживайте декодер старых форматов некоторое время и по возможности переводите старые курсоры в новый формат. Длительные экспорты и синхронизации часто пересекают деплои, поэтому задача, начатая до релиза, должна завершиться после него.
Когда клиент синхронизирует миллионы строк, дизайн курсора решает, закончится ли задача чисто или оставит разрывы, которые никто не сможет объяснить.
Добавьте правила повтора до того, как задачи начнут падать
Многие баги пагинации остаются невидимыми, пока длинный экспорт не упадёт в 2:00 и не возобновится не с того места. У каждой задачи должны быть правила повтора ещё до первого большого клиента, который запустит полный синк.
Начните с точки возобновления. Не возобновляйте по номеру страницы, если границы страниц могут двигаться. Возобновляйте после последней подтверждённой записи — то есть после последнего объекта, который ваша система действительно сохранила и проверила. Если воркер загрузил 500 записей, но записал только 320 до краша, следующий прогон должен продолжать после 320‑й записи, а не после всей страницы.
Повторы тоже должны быть безопасными. Второй запуск может снова получить некоторые те же записи, и это нормально. Ваш импортер должен уметь обрабатывать дубликаты так, чтобы не появлялись лишние строки, двойные списания или повторные события. Если одна и та же страница пришла дважды, итог должен остаться прежним.
Короткий набор правил предотвращает большую часть проблем. Сохраняйте чекпоинт только после того, как код завершил запись для этой записи или батча. Храните точные значения сортировки и курсор, использованные для следующего запроса. Делайте каждую запись безопасной для повторного выполнения. Установите границу окна экспорта, например updated_at <= job_start_time.
Это правило решает распространённую проблему в длинных экспортных задачах. Новые вставки и обновления могут появиться, пока задача всё ещё читает старые страницы. Если вы включаете эти новые записи в тот же прогон, поздние страницы могут сдвинуться, и некоторые старые записи исчезнут из результата. Граница делает один прогон консистентным, а следующий прогон подхватит всё новое.
Кажется мелочью, пока ночной синк не упадёт у крупного клиента. Один таймаут и один плохой повтор могут оставить тихую дыру в финансовых, аналитических или CRM‑данных. Ясные правила повтора превращают краш в нормальный повтор, а не в долгую очистку данных.
Как тестировать эндпоинт шаг за шагом
Многие баги пагинации не видны на аккуратных тестовых данных. Нужен движущийся набор данных, а не застывший. Эндпоинт должен по‑прежнему возвращать каждую запись ровно один раз в предсказуемом порядке, даже когда строки меняются.
Начните с пары сотен записей, а не с десяти‑двадцати. Убедитесь, что много строк имеют точно одинаковую метку времени. Это быстро вытащит слабую сортировку, потому что сортировка вроде created_at desc сама по себе недостаточна, когда несколько записей связаны по значению.
Запускайте тест как реальную задачу экспорта. Начните экспорт и сохраняйте все возвращаемые ID в том порядке, в котором они приходят. Добавляйте новые строки до завершения экспорта. Обновляйте некоторые существующие строки во время прогона, особенно поля, используемые в сортировке или фильтрации. Сравните экспортированные ID с ID, которые существовали в начале и в конце прогона. Потом повторите то же самое с удалениями посередине.
Сравнение важнее, чем многие думают. Если вы только считаете строки, вы можете пропустить молчаливый ущерб. Одна пропущенная ID и один дубликат могут оставить итоговое число без изменений, хотя экспорт уже неверен.
Проверьте результаты с трёх сторон. Появилась ли каждая ожидаемая ID ровно один раз? Сохранился ли стабильный порядок среди связанных записей на разных страницах? Продолжал ли работать курсор после вставок, обновлений и удалений?
Обновления заслуживают особого внимания. Если строка меняет timestamp или статус, пока задача всё ещё пагинит, слабый курсор может сдвинуть эту строку на более позднюю страницу или подтянуть назад на более раннюю. Так экспорты и синки тихо теряют записи.
Удаления тоже важны. Когда строка исчезает между запросами страниц, следующий курсор всё ещё должен двигаться вперёд чисто. Если эндпоинт опирается на offsets или рыхлую сортировку, поздние страницы могут сдвинуться, и клиент пропустит живые строки.
Запускайте этот тест несколько раз, а не один раз. Многие баги проявляются только на второй или третьей попытке, когда тайминги меняются на доли секунды.
Простой пример из синхронизации
Ночной экспорт счётов читает инвойсы в порядке возрастания updated_at. Задача запрашивает по 100 строк за раз, сохраняет последний timestamp с страницы и использует его для следующего запроса.
Всё кажется нормальным, пока не наступит загруженный час. Десять инвойсов отредактировали в 2026-04-11 10:15:42. Первая страница заканчивается инвойсом 8451, у которого тоже эта метка. Экспорт сохраняет только 2026-04-11 10:15:42 как курсор.
Следующий запрос по сути говорит: «верни инвойсы, где updated_at больше, чем 2026-04-11 10:15:42». API пропускает все другие инвойсы, обновлённые в ту же секунду, потому что они не больше курсорного времени — они равны ему.
Финансы замечают проблему позже, а не во время экспорта. Файл содержит меньше инвойсов, чем ожидалось, но ничего явно не упало. Все вызовы API вернули данные. Каждая страница выглядела полной. Сигналов об ошибке не было.
Некоторые команды пытаются исправить это, переключившись на >= вместо >. Это меняет пропуски на повторы. Следующая страница теперь снова включает инвойс 8451, и синк может импортировать дубликаты, если у него нет строгой дедупликации.
Более безопасный вариант — стабильная сортировка с тай‑брейкером, например updated_at ASC, id ASC. Курсор хранит обе величины из последней строки, а не только timestamp. Следующая страница начинается после (2026-04-11 10:15:42, 8451), и API может продолжить внутри группы инвойсов, у которых та же секунда.
Правило повтора добавляет ещё один уровень безопасности. Если экспорт перечитывает последнюю минуту и дедуплицирует по id инвойса, кратковременный баг или ретрай не уменьшит окончательный отчёт. Это небольшое правило часто спасает бухгалтерию от долгого утра.
Распространённые ошибки команд
Большинство сбоев пагинации выглядят безвредно на небольших тестах. Команда запускает один экспорт на спокойной базе, получает правильное количество строк и закрывает задачу. Проблема проявляется позже, когда крупный аккаунт продолжает создавать данные, пока синк всё ещё листает старые результаты.
Сортировка только по метке времени — один из простейших способов потерять записи. Метки часто совпадают, особенно когда много строк прибывают в ту же секунду или миллисекунду. Если у двух записей одинаковое время и API не добавляет уникальный тай‑брейкер вроде id, база может вернуть их в разном порядке при следующем запросе.
Номера страниц вызывают другой тихий сбой. Они работают для пользователя, который листает список, но слабы для движущихся данных. Если новые строки появятся между страницей 12 и 13, содержимое сдвинется, и задача может пропустить одну запись или прочитать ту же запись дважды.
Команды также ломают долгоживущие клиенты, когда слишком легко меняют формат курсора. Курсор, который сначала был одной закодированной величиной, часто требует позже дополнительных полей: значений сортировки, фильтров, области тенанта, возможно маркера версии. Если формат меняется без отката, старые воркеры могут упасть посреди прогона. Версионированные курсоры — скучный, но очень полезный подход.
Повторы после частичных записей создают другой класс багов. Допустим, воркер записал 500 строк в конечную систему, затем упал до сохранения следующего курсора. При повторе он запрашивает ту же страницу снова. Если приёмная сторона не умеет безболезненно принимать одну и ту же запись дважды, вы получите дубликаты, конфликты или молчаливые перезаписи. Хорошие правила повтора означают два простых правила: сохраняйте прогресс только после надёжной записи и делайте повторные записи безопасными.
Один успешный прогон ничего не доказывает. Пропуски записей обычно проявляются при движении: новые вставки, поздние обновления, рестарты воркеров, лимиты по скорости или задача, которая идёт часы вместо минут.
Если хотите стабильной пагинации — тестируйте её на движущемся наборе. Там слабые дизайны чаще ломаются.
Быстрая проверка перед релизом
Эндпоинт пагинации может пройти базовую QA и всё равно провалиться на загруженном аккаунте с миллионами строк. Большинство проблем появляются только тогда, когда данные меняются во время длинного экспорта или синка.
Запустите одну проверку релиза против реального запроса, реальных фильтров и реалистичного объёма данных. По возможности тестируйте на таблице, которая действительно меняется в течение дня.
Держите чеклист коротким и строгим:
- Зафиксируйте один порядок сортировки для эндпоинта.
- Добавьте уникальный тай‑брейкер в каждый запрос страницы.
- Версионируйте формат курсора с первого дня.
- Определите правило возобновления после ошибки.
- Тестируйте на живых изменяющихся данных.
Одно простое упражнение ловит многое. Запустите экспорт 50 000 строк, поставьте на паузу после нескольких страниц, обновите несколько записей с одинаковым updated_at, вставьте новые строки, затем продолжите. Посчитайте финальные строки и сравните ID. Если количество совпадает, но некоторые ID отличаются, у вас всё ещё есть пробел в пагинации.
Команды часто останавливаются после проверки первой и второй страницы и «следующий курсор работает». Этого недостаточно. Порог релиза должен быть выше: одна и та же сортировка каждый раз, детерминированное разрешение ничьих, курсор, который можно изменить позже, и правило возобновления, которого запускающий механизм будет автоматически придерживаться.
Если эндпоинт не проходит эти проверки — не выкладывайте его для экспортов и синков. Малые наборы скрывают проблему. Крупные аккаунты за неё заплатят.
Что делать дальше
Начните с эндпоинта, который двигает больше всего данных. Если один экспорт или синк обрабатывает большую часть ваших записей, исправьте его первым. Малые баги пагинации сидят молча, пока большой клиент не запустит бэкфилл или длинную синхронизацию.
Короткий обзор обычно быстро находит проблему. Проверьте точный порядок сортировки и убедитесь, что он не может измениться между страницами. Запишите, какие поля хранит курсор и почему они остаются уникальными. Определите правила возобновления и повтора для упавших задач, ретраев и частичных выгрузок. Потом сделайте один бэкфилл‑тест на большом аккаунте, а не на выборочном тенанте с сотнями строк.
Документация важнее, чем многие думают. Если инженер не может ответить на вопросы «по какому полю мы сортируем?» или «что происходит, если страница 84 упала?» без двадцатиминутного чтения кода, эндпоинт не готов. Стабильная сортировка должна быть явной, а правила повтора — описывать, когда задача перечитывает старые строки, как она избегает дубликатов и когда останавливается.
Сделайте реальный стресс‑тест. Выберите аккаунт с активной записью, запустите экспорт и пусть новые записи приходят в процессе. Затем сравните счёт, ID и временные метки после завершения. Там большинство багов пагинации и проявляется.
Если разрывы продолжают появляться, полезен второй взгляд. Oleg Sotnikov at oleg.is работает со стартапами и малыми бизнесами по дизайну API, инфраструктуре и безопасности синхронизаций как fractional CTO. Такой аудит полезен, когда баг не в одном запросе, а в том, как ретраи, курсоры и фоновые задачи взаимодействуют.
Один аккуратный проход по самому загруженному эндпоинту может сэкономить дни на очистке данных позже. И он не даст крупным клиентам найти баг раньше вашей команды.
Часто задаваемые вопросы
Why do pagination bugs show up on large accounts first?
Потому что у крупных аккаунтов данные продолжают меняться, пока ваш процесс читает страницы. Новые вставки, правки и удаления сдвигают границы страниц, поэтому то, что работает на 200 строках, может пропускать или повторять записи при 800 000.
Is offset pagination safe for exports?
Как правило — нет. Смещения (offset) подходят для простого браузинга, но для экспортов и синхронизаций нужна более надёжная стратегия. Если строки появляются или исчезают до следующего запроса, offset=1000 уже не указывает на то же место, и задача может пропустить одну запись и прочитать другую дважды.
What sort order should I use for a full export?
Используйте стабильную сортировку, которая не меняется в ходе выполнения, например created_at ASC, id ASC. Первое поле даёт разумный порядок, а id гарантирует уникальное разрешение равных значений.
Why is sorting only by updated_at a problem?
Метки времени часто совпадают, особенно при массовых загрузках или в пиковые периоды. Если сортировать только по updated_at, база может возвращать строки с одинаковым значением в разном порядке на разных страницах — это создаёт пропуски или дубли.
What should a good cursor contain?
Надёжный курсор должен хранить значение поля сортировки и id как тай-брейкер последней строки. Добавьте версию формата и валидируйте или подписывайте курсор, чтобы повреждённые или отредактированные значения не сбрасывали клиента на первую страницу.
How should I resume a sync after a crash?
Продолжайте после последней записи, которую вы действительно записали, а не после последней загруженной страницы. Сохраняйте прогресс только после надёжной записи, и делайте повторные записи безопасными, чтобы повторы не создавали дубликаты или двойные списания.
Should I use > or >= for timestamp cursors?
Ни тот, ни другой не работают надёжно в одиночку, когда много строк имеют одну и ту же отметку времени. > может пропускать равные записи, а >= может повторять последнюю. Храните и временную метку, и id, и продолжайте после этой пары.
How do I test pagination properly?
Запускайте экспорт на данных, которые меняются в ходе теста. Вставляйте строки, обновляйте поля, влияющие на сортировку, удаляйте некоторые записи, затем сравнивайте полученные ID, а не только количество строк. Одна отсутствующая ID и один дубликат могут компенсировать друг друга в сумме и скрыть проблему.
Can deletes and edits break pagination too?
Да. Удаление сдвигает последующие оффсеты назад, а правка может переместить строку в другое место, если сортировка зависит от поля вроде updated_at. Поэтому важны стабильный порядок и правила повторного запуска.
What is the fastest way to improve an existing pagination endpoint?
Начните с самого загруженного эндпоинта и сначала исправьте порядок. Зафиксируйте сортировку, добавьте уникальный тай-брейкер, версионируйте курсор и установите границу, например updated_at <= job_start_time, чтобы один прогон был консистентным окном, а следующие прогоны подхватывали новые изменения.


