Ошибки OCR в счетах: почему проверка всё ещё пропускает крайние случаи
Ошибки OCR в счётах продолжают проскальзывать, когда поставщики меняют макеты, сканы бывают плохими, а проверка спешит. Узнайте, где поля ломаются и как их поймать.
Содержание
Почему счета всё ещё проскальзывают через OCR и проверку
OCR умеет читать текст на странице. То, что он часто пропускает — это смысл.
На счёте могут быть две даты, три номера ссылок, промежуточная сумма, плата за доставку и налоговый номер примерно в одной области. Текст виден, но системе всё ещё нужно решить, какое значение относится к какому полю. Многие ошибки извлечения начинаются именно здесь.
Счета полны похожих друг на друга значений. Номер счёта поставщика может выглядеть как номер счёта-фактуры. Период оказания услуг может принять за срок оплаты. Налоговый номер может оказаться там, где парсер ожидает номер заказа (PO). На знакомом шаблоне программное обеспечение может «угадывать» и обходиться «приблизительным» решением. На чуть необычном счёте то же самое предположение разваливается.
Человеческая проверка не всегда ловит проблему. Ревьюеры часто пробегают взглядом по названию поставщика и итоговой сумме, а затем утверждают счёт, если оба кажутся верными. Они могут пропустить неправильную валюту, неверный PO, смещённую сумму налога или дату строки, попавшую в чужое поле. Даже внимательные люди упускают детали, когда очередь длинная, а большинство счетов выглядит рутинно.
Одна неверная ячейка может причинить больше вреда, чем полный сбой OCR. Если OCR ничего не распознал, счёт встаёт на контроле и кто‑то исправляет его вручную. Если же он правильно распознал большую часть документа, счёт может пойти дальше с незаметной ошибкой. Не прошёл матчинг, одобрение попало не тому человеку или ERP записал сумму под неправильным поставщиком.
Ущерб накапливается тихо. Десять мелких ошибок за день — это десять писем по доразбору, десять ручных исправлений и десять шансов заплатить с опозданием или занести некорректные данные. По одному каждая такая ошибка не выглядит драматично. Вместе они превращают быстрый поток в уборку после него.
Простой пример иллюстрирует идею. Ревьюер видит, что итог совпадает и имя поставщика нормальное, и утверждает счёт. Позже AP обнаруживает, что OCR записал номер клиента в поле «номер счёта». Счёт не проходит проверку на дубли, и кто‑то вручную разбирает ситуацию.
Как сдвиг макета ломает извлечение полей
Сдвиг макета звучит незначительно, но он ломает извлечение быстрее, чем многие ожидают. Парсер не читает счёт как человек. Он ищет метки и значения в местах, которым научился раньше. Когда поставщик меняет шаблон, даже небольшой сдвиг может создать ошибки, которые проскальзывают при проверке.
Частая ситуация — номер счёта переехал в новое место. В прошлом месяце он был в верхнем правом углу. В этом месяце поставщик поместил его под адрес оплаты или рядом с номером заказа. Если правило всё ещё ищет в старой зоне, оно может не найти ничего. Хуже — оно может схватить PO и пометить его как номер счёта, потому что формат достаточно похож.
Итоги ломаются тем же способом. Многие правила предполагают, что промежуточная сумма, налог и итог идут в фиксированном порядке внизу страницы. Затем поставщик обновляет макет и ставит налог выше промежуточной суммы или добавляет строку скидки между ними. Экстрактор по‑прежнему читает по позиции, а не по смыслу. В результате вы получаете числа, которые выглядят правдоподобно, но лежат не в своих полях.
Изменение фирменного стиля тоже создаёт проблемы. Новый логотип, баннер оплаты или больший шапочный блок могут сместить метки на несколько строк вниз. Слова на месте, но не в зонах, которые ожидает система. Старые правила продолжают искать в неверной области и часто выбирают ближайшее число вместо правильного.
Проверка не замечает сдвиг макета по простой причине: счёт всё ещё выглядит знакомым. Ревьюер узнаёт поставщика, видит данные, которые выглядят полными, и утверждает документ. Он может не заметить, что система взяла дату счёта с одной строки, а срок оплаты — с другой, потому что обе находились рядом с тем же заголовком.
Полезно воспринимать повторных поставщиков как «живые» шаблоны, а не зафиксированные. Когда у того же поставщика начинает сбоить какое‑то поле, проверьте, не сдвинулась ли вся страница. Если одновременно меняются два‑три поля, чаще всего виноват именно layout drift.
Привычки поставщиков, которые путают парсер
Некоторые из самых сложных ошибок возникают из документов, которые человеку кажутся последовательными, но меняются небольшими деталями от одного поставщика к другому. Ревьюеры тоже их пропускают, особенно когда обрабатывают одного и того же поставщика каждую неделю и начинают доверять шаблону.
Даты — классическая проблема. Один поставщик пишет 03/04/2025, другой — 04/03/2025, третий использует 2025.04.03. Если парсер догадывается вместо того, чтобы смотреть на историю поставщика, он может поменять местами месяц и день и всё равно получить валидную на вид дату. Человеческое ревью редко замечает такую ошибку, потому что ничего явно не сломано.
Кредит‑ноты создают другую ловушку. Некоторые поставщики используют почти тот же макет для счётов и кредитов, с небольшой меткой вверху или знаком минус у итоговой суммы. Если система прочитает сумму, но пропустит тип документа, финансы получат начисление вместо сторнирования.
Небольшие привычки — большие проблемы извлечения
Номера заказов (PO) часто оказываются вне самого PDF. Поставщик может помещать PO только в теме письма, имени вложения или в тексте письма. Если рабочий поток проверяет только PDF, этот номер до сопоставления никогда не дойдёт.
Многостраничные файлы рушат предположения тоже. На первой странице может быть имя поставщика и номер счёта, а на второй — налог, доставка или итоговая сумма. Некоторые парсеры относятся к страницам как к отдельным документам. Ревьюер, который движется слишком быстро, может подтвердить первую страницу и пропустить сумму, изменившуюся на последней.
Рукописные пометки усугубляют ситуацию, потому что обычно они появляются рядом с важными полями. Кто‑то кружит налоговую строку, пишет «оплачено 50%» рядом с балансом или добавляет исправленную сумму ручкой. OCR не всегда может понять, является ли пометка комментарием, заменой значения или шумом. Парсер может выбрать неверное число, а ревьюер — довериться напечатанному значению, не заметив рукопись.
Практическое решение — помечать поставщиков, а не только документы. Отслеживайте, кто использует смешанные форматы дат, кто отправляет кредиты в шаблоне счёта и кто разбивает данные по страницам. Ревьюеры ловят больше, когда знают привычки поставщика до открытия файла.
Что делают с текстом низкокачественные сканы
Чистый PDF даёт OCR шанс. Плохой скан исказит страницу ещё до того, как ПО прочитает первое слово. Для человека текст может оставаться читаемым, но машине он превращается в сломанные формы, исчезнувшие промежутки и строки, которые больше не лежат там, где нужно.
Когда страницу подают под небольшим углом, первая проблема часто проявляется в таблицах. Линии строк наклоняются, границы столбцов стираются, и суммы прыгают в другой столбец. Парсер может прочитать цену за единицу как итог по строке или объединить две строки, потому что сетка больше не выглядит как сетка.
Тени дают более тихие ошибки. Серый полосовой участок в сгибе бумаги может скрыть десятичную точку, превратив 108.50 в 10850 или 108 50. Светло‑серые фоны делают то же самое: падает контраст, и OCR начинает домысливать мелкие знаки вместо точного чтения.
Сильно сжатые PDF — ещё одна проблема. Компрессия размывает края, и некоторые цифры становятся похожими друг на друга. 8 превращается в 3, 6 — в 0. Если это происходит в поле налога, количества или итоговой суммы, результат может пройти быструю человеческую проверку, потому что число всё ещё кажется правдоподобным.
Обрезанные страницы лишают контекста. Если скан отрезал верхний правый угол, номер счёта или дата могут исчезнуть. Обрез внизу может убрать условия оплаты или итоговую сумму. Ревьюеры часто фокусируются на заполненных полях, поэтому пустоты из‑за обрезки пропускаются, когда остальная часть страницы выглядит нормально.
Печати и подписи создают другой вид хаоса. Они накладываются поверх печатных итогов, сроков или реквизитов банка. OCR смешивает чернила обоих слоёв и выдаёт текст, который наполовину печатный, наполовину рукописный.
Несколько признаков обычно означают, что скан нужно переделать:
- Итоги с пропавшими десятичными или странными пробелами
- Даты, меняющие формат в счетах одного и того же поставщика
- Пустые номера счётов на страницах, которые в остальном выглядят полными
- Строки позиции, слитые в одну длинную строку
Многие ошибки извлечения начинаются здесь, а не в правилах полей. Если изображение слабое, проверьте исходную страницу в первую очередь, а затем уже захваченные поля.
Как построить шаг проверки, который ловит промахи
Этап проверки работает лучше, когда игнорирует большинство полей. Если каждый счёт отправлять человеку на полную проверку, люди быстро устанут и начнут пропускать те же ошибки, что и система.
Начните с полей, которые могут вызвать платежные или учётные ошибки: итог, дата счёта, название поставщика, сумма налога, номер заказа (PO) и банковские реквизиты. Этот короткий список должен исходить из вашей истории доработок, а не из общего шаблона.
Затем направляйте на проверку только рискованные значения. Итоги, даты и названия поставщиков должны идти на ревью, когда падает доверие (confidence), когда два извлечённых поля расходятся или когда формат выглядит необычно для данного поставщика. Чистый счёт должен проходить с минимальным человеческим вмешательством.
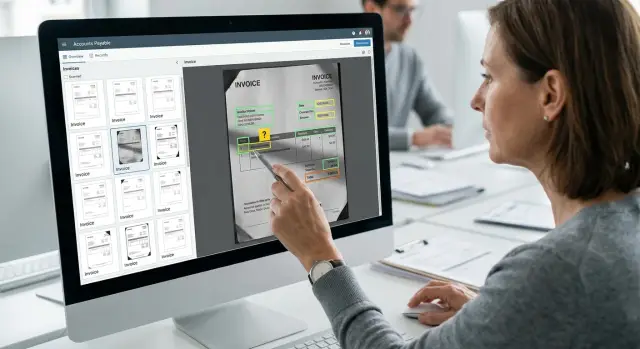
Ревьюерам не нужно рыскать по странице. Показывайте каждое извлечённое значение рядом с точным фрагментом источника или кропом изображения, чтобы сравнение занимало секунды.
Вместо полной проверки документа задавайте узкие вопросы:
- Итог 1,980.00 или 1,890.00?
- Название поставщика совпадает с шапкой и налоговым номером?
- Дата 03/04/2025 или 04/03/2025?
- Система вытянула номер счёта из правильной метки?
Это делает задачу маленькой и концентрацию высокой. Люди гораздо лучше подтверждают одно сомнительное поле, чем перечитывают целую страницу, которая в основном выглядит нормально.
Обычная ошибка выглядит безобидно. Поставщик сдвинул номер счёта из правого верхнего угла в середину и заменил «invoice date» на «bill date». Парсер всё ещё возвращает правдоподобное значение, поэтому широкая проверка пропускает ошибку. Фокусированная проверка даты и номера счёта поймала бы проблему до передачи данных в финансовые системы.
Последний элемент — обратная связь. Когда ревьюер исправляет значение, сохраняйте исправление вместе с изображением счёта, именем поставщика и причиной ошибки. Используйте подтверждённые правки, чтобы корректировать правила, подсказки и шаблоны поставщиков. Если одна и та же ошибка появляется три раза, шаг проверки уже показал, что нужно исправить.
Реалистичный пример из одного AP‑входящего ящика
Финансовая команда ежемесячно получает счёт от одного и того же курьерского сервиса. Шесть месяцев файл выглядит почти одинаково. Логотип в левом верхнем, номер счёта — рядом с вершиной, налог в маленьком сводном блоке, а итог в правом нижнем.
OCR быстро привыкает к этой схеме. То же самое делают и ревьюеры. Со временем люди перестают внимательно читать каждое поле, потому что счёт обычно приходит в одном и том же виде с одними и теми же данными в одних и тех же местах.
И вдруг, в один месяц, поставщик немного меняет шаблон. Они добавляют промо‑баннер вверху PDF, и это сдвигает сводный блок вниз. Сумма налога теперь появляется там, где раньше был итог, а настоящий итог смещается ниже.
Файл всё ещё выглядит чистым. Ничего не повреждено и не подозрительно. Имя поставщика знакомо, номер заказа совпадает, и суммы кажутся правдоподобными на беглый взгляд.
Но экстрактор всё ещё смотрит в старое место для итога. Он читает налог $184.20 и сохраняет это как итоговую сумму. А реальная сумма к оплате — $2,026.20.
Ревьюер открывает запись, видит знакомого поставщика, быстро смотрит страницу и нажимает «утвердить». Так ошибки проскальзывают, даже когда человек проверяет результат. Привычность делает людей быстрее, а быстрые проверки пропускают тихие изменения.
Ошибка проявляется не сразу. Она появляется позже при сверке, когда задолженность в системе не совпадает с выпиской поставщика или движением по банку. Тогда кто‑то должен достать оригинальный PDF, вручную сверить каждую сумму, исправить проводку и объяснить несоответствие.
Этот пример обычный — поэтому он важен. Никто не прислал сломанный скан и никто не ввёл неверную цифру вручную. Обычный поставщик сделал небольшое изменение макета, и и OCR, и ревьюер последовали старой привычке.
Одна дополнительная проверка поймала бы это рано. Система могла бы сравнить промежуточную сумму, налог и итог или помечать счета, когда известный поставщик внезапно меняет позиции полей.
Где команды слишком сильно доверяют системе
Проблема часто начинается с аккуратно выглядящего числа. Балл уверенности 96% кажется безопасным, и команда двигается дальше. Но важнее не сам балл, а тип поля. Если OCR записал срок оплаты как дату счёта или перепутал чистую сумму и налог, высокий балл не защитит от неверной проводки.
Вот почему некоторые ошибки остаются незаметными на виду. Команды обращаются с каждым извлечённым полем одинаково, хотя риск разный. Неправильное название поставщика — это неприятно. Неверные банковские реквизиты, валюта или итоговая сумма — это реальная доработка.
Ещё одна ошибка — ревью всей страницы вместо нескольких значений, которые чаще всего дают сбой. Люди просматривают счёт целиком, видят логотип, позиции и итог и предполагают, что данные в порядке. Такая проверка медленная и всё равно пропускает мелкие ошибки в датах, номерах PO, налоговых ID или условиях оплаты.
Лучше правило проще. Сначала проверьте поля, влияющие на оплату, налоги и матчинг. Сравнивайте помеченные значения с изображением, а не с соседними полями. Обрабатывайте исключения по мере их появления, а не в конце месяца.
Проблемы, специфичные для поставщика, тоже накапливаются, когда их откладывают. Один поставщик всегда ставит номер счёта рядом со ссылкой доставки. Другой меняет футер каждое квартал. Если никто не выделит эти исключения рано, одни и те же неверные предположения повторяются неделями.
Повторное использование шаблонов даёт тихий сбой. Два поставщика могут выглядеть похоже, поэтому кому‑то сопоставляют их к одному шаблону извлечения. В общем случае это работает, а затем ломается, когда один поставщик сдвигает строку НДС, меняет формат десятичных или помещает итог внутрь рамки. Парсер будет делать одну и ту же неправильную операцию каждый раз, а ревьюеры будут доверять результату, потому что он чаще всего выглядит приемлемо.
Очистку изображений тоже пропускают по той же причине. Большинство файлов человеку читаемо, поэтому никто не занимается поворотом, повышением контраста или удалением фона. В результате несколько слабых сканов, фото с телефона или перекошенные PDF проходят дальше и портят очередь проверки.
Если команда хочет меньше промахов, ей стоит меньше доверять и лучше сортировать. Сначала ревьюируйте рискованные поля, разделяйте поставщиков с разным поведением и исправляйте слабые изображения до начала извлечения.
Короткий чек‑лист перед передачей данных в финансовые системы
Быстрая проверка на входе должна ловить мелкие промахи, которые потом создают большую доработку. Большинство ошибок извлечения не драматичны. Это одна неверная цифра в номере счёта, перепутанная дата, отсутствующая валюта или итог, который кажется близким, пока не попадёт в учёт.
Делайте одни и те же проверки каждый раз. Последовательность важнее увеличения числа людей в очереди.
Проверьте номер счёта, дату счёта, валюту и итоговую сумму по изображению документа, а не только по извлечённому тексту. Пересчитайте суммы и убедитесь, что промежуточная сумма, налог, сборы и скидки сходятся с суммой к оплате. Сверьте название поставщика с карточкой поставщика. Если парсер вытащил торговое имя, старое название компании или часть шапки — остановите процесс и уточните.
Проверьте документ на пропущенные страницы, перевёрнутые страницы, искажения и обрезы, которые прячут позиции или итог. Ищите дубликаты перед публикацией, включая близкие совпадения, где поставщик, сумма, период и номер счёта почти совпадают.
Эти проверки терпят банальные ошибки. Скан может потерять последнюю страницу с итогом. Поставщик может писать номера со пробелами в одном файле и через дефис в другом. Строка налога может быть прочитана как часть промежуточной суммы. Так и проходят «чистые» записи.
Проверка математической сверки — обычно самый быстрый тест здравого смысла. Если извлечённый итог 1,280.00, а промежуточная сумма плюс налог — 1,208.00, остановитесь и посмотрите на изображение прежде, чем запись пойдёт дальше.
Контроль дублей тоже требует больше, чем точное совпадение. Две копии одного счета могут отличаться одной буквой из‑за OCR: «I» вместо «1» или потерянный слэш. Если поставщик, сумма и дата близки — удержите документ на ревью.
Плохие данные гораздо труднее править, когда они уже в учётной системе. Пять быстрых проверок на входе экономят больше времени, чем длинная уборка в конце месяца.
Что делать дальше, если промахи накапливаются
Когда ошибки OCR со счетами продолжают появляться, перестаньте считать их случайными. У большинства команд уже есть паттерн — просто он не посчитан.
Начните с простого журнала на 2–4 недели. Отслеживайте, какие поля чаще всего дают сбой, и группируйте эти ошибки по поставщикам. В большинстве команд быстро проявляется небольшой набор повторяющихся «виновников»: номер счёта, итоговая сумма, налог, PO или срок оплаты.
Это разделение важно, потому что решение зависит от причины. Смущённый скан и чистый скан с неверным сопоставлением — разные проблемы, даже если оба заканчиваются неправильным итогом в учёте.
Полезна простая таблица триажа. Отмечайте проблемы сканов: перекосы, бледная печать, обрезанные поля, печати поверх текста. Отмечайте проблемы сопоставления: итоги вытащены из неверного блока, даты прочитаны в неправильном формате, поля шапки перепутаны с позициями. Отмечайте привычки поставщиков: необычные метки, итоги на нескольких страницах, рукописи или повторяющиеся референсы. Отмечайте и ошибки ревьюеров, особенно когда система пометила проблему, а очередь всё равно пропустила документ.
Не перестраивайте весь рабочий поток одновременно. Выберите одну более узкую очередь проверки и протестируйте её. Например, отправляйте только низко‑доверительные счета от пяти самых шумных поставщиков старшему ревьюеру в течение недели. Такой небольшой тест покажет, в модели ли дело, в правилах или в передаче между ними.
Затем напишите простые правила для худших шаблонов в первую очередь. Если один поставщик всегда кладёт номер счёта под «Reference» или печатает итог дважды, добавьте правило для этого шаблона, прежде чем менять всю систему. Несколько ясных правил часто убирают больше боли, чем масштабное изменение модели.
Если виноваты низкокачественные сканы, работайте и с источником. Попросите поставщиков присылать более чистые PDF, установите минимальные требования к сканам или отклоняйте слишком обрезанные и бледные файлы. Ревью не спасёт все плохие входы.
Если проблема охватывает извлечение, логику проверки и передачу данных в остальную часть финансовой системы, внешняя техническая проверка может помочь. Oleg Sotnikov на oleg.is работает со стартапами и малыми‑средними бизнесами над практическими AI‑решениями, инфраструктурой и процессными правками — это пригодится, когда проблема OCR часть более широкой операционной задачи.
Следующий шаг редко «заменить всё». Обычно это короткий список полей, набор поставщиков с явными шаблонными проблемами и одно контролируемое исправление, которое можно измерить уже на следующей неделе.
Часто задаваемые вопросы
Почему OCR пропускает поля, даже если счёт кажется чистым?
Потому что OCR сначала читает символы, а уже потом догадывается о значении. Когда на счёте рядом стоят несколько дат, номеров и сумм, система может поместить правильный текст в неправильное поле — и на первый взгляд всё будет выглядеть нормально.
Что такое «сдвиг макета» (layout drift) в счёте?
Это значит, что поставщик сдвинул метки или значения на странице. Небольшой баннер, увеличенный заголовок или смещённый блок с итогами могут переместить номер счёта, налог или итог в новое место, а старые правила продолжают смотреть в прежнюю область.
Какие поля проверять в первую очередь?
Начните с полей, которые могут привести к ошибкам оплаты или проводок: номер счёта, дата счёта, валюта, итоговая сумма, налог, название поставщика, номер заказа (PO) и банковские реквизиты. Сужайте проверку, чтобы ревьюеры подтверждали спорные значения, а не перечитывали всю страницу.
Может ли высокий показатель уверенности скрывать неверное извлечение?
Да. Высокий балл уверенности означает лишь, что модель уверена в том, что она прочитала — не в том, что она поместила это в правильное поле. Модель может чётко прочитать срок оплаты и при этом сохранить его как дату счёта.
Как привычки поставщиков создают повторяющиеся ошибки OCR?
Поставщики по‑разному формируют даты, кредит‑ноты, ссылки и итоговые строки. Один использует смешанные форматы дат, другой прячет PO в теле письма, третий разбивает итоги по страницам — и одна и та же стратегия парсера даёт повторяющуюся ошибку.
Какие проблемы со сканами больше всего мешают OCR?
Перекошенные страницы, тени, сильная компрессия, обрезанные края, печати и подписи — вот самые частые проблемы. Они искажают цифры, скрывают десятичные точки и ломают таблицы, поэтому стоит проверять качество изображения до того, как винить правила извлечения.
Как проверять многостраничный счёт?
Откройте все страницы и проверьте, где находится итоговая сумма. Часто поставщик и номер счёта на первой странице, а налог, доставка или окончательная сумма — на последней, поэтому быстрая проверка только первой страницы пропускает реальную сумму.
Как поймать дубликаты, когда OCR меняет один символ?
Сравнивайте не только номер счёта. Если поставщик, сумма и период почти совпадают с другой записью, удерживайте документ на ревью — даже если OCR изменила один символ, убрала слэш или перепутала I и 1.
Что нужно фиксировать, если ошибки OCR повторяются?
Ведите простой журнал ошибок в течение 2–4 недель. Фиксируйте, какое поле неверно, кто поставщик, качество файла и что исправил ревьюер — затем группируйте промахи, чтобы увидеть, что вызывает большинство доработок: сканы, сопоставление или шаблоны поставщиков.
Когда исправлять входные данные, когда менять правила и когда привлекать внешнюю помощь?
Если плохие сканы — корректируйте источник; если чистые файлы всё ещё сопоставляются неверно — ужесточайте правила для шаблонов. Когда же ошибка охватывает извлечение, логику проверки и публикацию в учёте, внешняя техническая проверка, например от Oleg Sotnikov на oleg.is, может помочь разобраться в процессе без полной замены всей системы.


