Ошибки async в FastAPI, которые замедляют приложения под нагрузкой
Ошибки async в FastAPI могут блокировать запросы, исчерпывать пулы и ломать тесты. Узнайте практические подходы, которые помогают приложениям оставаться отзывчивыми под нагрузкой.
Содержание
Почему async-приложения всё равно зависают
Многие ошибки async в FastAPI начинаются с одного неверного предположения: если маршрут использует async def, приложение будет отзывчивым. Это не так. Async-код помогает только тогда, когда каждая часть пути запроса быстро отдаёт управление обратно. Один медленный вызов может занять worker намного дольше, чем кажется на бумаге.
Это важно, потому что задержки накапливаются. Один запрос может провести 30 мс в ожидании базы данных, 40 мс — в ожидании кеша и ещё 80 мс — в ожидании внешнего API. По отдельности эти цифры не выглядят страшно. Но под нагрузкой они складываются. Десять запросов, которые ждут одновременно, превращают небольшую паузу в очередь, а именно очередь чувствуют пользователи.
Event loop чувствителен к такому поведению. Если один запрос попадает на блокирующую работу, другие запросы не продвигаются, когда должны. Время ответа начинает прыгать рывками. Страница, которая в тестах казалась мгновенной, внезапно висит по две-три секунды, хотя код выглядел нормально во время ревью.
Пользователи замечают это раньше графиков. Они видят медленные логины, крутящиеся кнопки и случайные таймауты. При этом CPU может выглядеть нормальным, память — тоже, а средняя задержка легко скрывает самые плохие запросы. Проблемы с перцентилями и очередями всплывают позже, уже после того, как люди успели почувствовать, что приложение замедлилось.
Локальное тестирование часто этого не показывает. На ноутбуке один человек проходит по happy path, и всё кажется быстрым. В production всё иначе. Реальный трафик — это перекрывающиеся запросы, неровные сетевые задержки, повторы и всплески, которые приходят в одну и ту же секунду.
Простой пример: один endpoint обращается к платёжному сервису, который обычно отвечает за 120 мс. Когда трафик растёт, несколько вызовов начинают занимать 900 мс. Эти медленные запросы удерживают workers, новые запросы встают за ними в очередь, и всё приложение начинает ощущаться вязким. Ничего полностью не сломалось. Просто оно занято не там, где нужно.
Поэтому async-приложения всё равно зависают. Обычно они падают не из-за одной огромной ошибки. Они ломаются из-за маленьких ожиданий, которые накапливаются, пока приложение больше не может их скрывать.
Что блокирует event loop
Async FastAPI-обработчик всё равно может сильно тормозить, если внутри него есть синхронная работа. Поэтому многие ошибки async в FastAPI проявляются только под нагрузкой. Один запрос выглядит нормально. Пятьдесят одновременных запросов делают проблему очевидной.
Самая частая ловушка — sync HTTP-клиент внутри async def. Если маршрут вызывает requests.get() или другой блокирующий клиент, worker ждёт удалённый сервер и тем временем перестаёт выполнять другие корутины. Медленный платёжный API, повторный webhook или даже задержка DNS могут затормозить вообще не связанные запросы.
Некоторые инструменты для баз данных вызывают такую же боль. Снаружи они выглядят async, но драйвер, адаптер ORM или вспомогательная функция всё ещё могут выполнять синхронную сетевую работу или разбор данных. Код читается аккуратно, а event loop в это время простаивает, пока вызов не завершится.
Несколько блокировок прячутся в скучных местах:
time.sleep()останавливает весь worker- чтение и запись локальных файлов могут задерживать запросы
- DNS-lookup может блокировать, если библиотека делает его синхронно
- тяжёлый логинг замедляет горячие пути, особенно с файловыми или сетевыми обработчиками
- CPU-тяжёлая работа вроде изменения размера изображений, разбора больших JSON, обработки PDF или сжатия данных забирает время, которое loop нужен для других задач
Небольшой пример делает это понятнее. Представьте endpoint для загрузки файла, который сохраняет файл, пишет большой audit log, отправляет sync HTTP-вызов стороннему сервису, а затем создаёт миниатюру на Python. Каждый шаг по отдельности может казаться безобидным. Вместе они превращают один запрос в пробку.
Ожидание соединения может выглядеть почти так же, как блокировка event loop, даже если это другая проблема. Если у базы данных или HTTP-пула закончились свободные соединения, запросы всё равно встают в очередь, и пользователи чувствуют зависание приложения. С их стороны эффект тот же: страницы висят, таймауты растут, задержка скачет.
Если путь запроса касается сети, диска или тяжёлой CPU-работы, считайте, что он может блокировать, пока не доказано обратное.
Как проверить путь запроса
Большинство ошибок async в FastAPI проявляются, когда вы проходите один реальный запрос до конца. Возьмите один endpoint и проследите точный путь от route handler до базы данных, кеша, внешних API и кодирования ответа. Простая схема на бумаге часто находит больше проблем, чем чтение файлов по одному.
Пометьте каждый вызов как async или sync. Будьте честны. Если маршрут на async def вызывает sync SDK, sync-метод ORM или локальный file I/O, этот участок может блокировать event loop или заставить перейти в threadpool.
Полезный аудит обычно включает такие остановки:
- функция маршрута и зависимости
- middleware, авторизация и разбор запроса
- база данных, кеш и исходящие HTTP-вызовы
- background tasks, запускаемые запросом
- сериализация ответа и логирование
Что отмечать во время аудита
На каждой остановке запишите две вещи: сколько это занимает времени и где выполняется. Вам нужно понять, ждёт ли запрос настоящего async I/O, сидит ли в загруженном threadpool или прямо блокирует loop.
Небольшой пример делает это очевидным. Допустим, один endpoint загружает клиента из Postgres, проверяет Redis, а затем вызывает billing API. У слоя базы данных async-драйвер, но Redis-клиент sync, SDK для billing тоже sync, а кастомный middleware читает файл на каждом запросе. Такое приложение может выглядеть нормально в локальном тесте, а потом сильно замедлиться при росте трафика.
Проверяйте middleware, startup hooks и background tasks с той же тщательностью. Middleware выполняется на каждом запросе, поэтому даже sync-вызов на 20 миллисекунд быстро накапливается. Startup-код тоже может мешать, если он обновляет данные блокирующим способом и занимает workers во время деплоя. Background tasks не делают блокирующую работу безвредной, если она всё равно выполняется в том же процессе.
Особого внимания заслуживают случайные переходы в threadpool. Они часто появляются из-за sync-зависимостей, helper-функций, старых SDK или обёрток, которые скрывают блокирующий код. Один такой переход не всегда проблема. Пять маленьких переходов в одном запросе — обычно уже проблема.
Если вы можете ответить на вопрос «что где выполняется и сколько это длится» для одного пути запроса, вы уже знаете, что чинить в первую очередь.
Заменяйте блокирующую работу по шагам
Начинайте с вызовов, которые ждут чего-то вне вашего приложения. Многие ошибки async в FastAPI начинаются с одной безобидной строки: sync HTTP-клиента, sync-драйвера базы данных или чтения файла внутри обработчика async def. Если у библиотеки есть настоящая async-версия, сначала переходите на неё. Обычно это даёт наибольший эффект при минимальной переделке.
Практичный порядок помогает:
- Замените sync-сетевые и database-вызовы на async-клиенты.
- Уберите тяжёлую CPU-работу из пути запроса.
- Изолируйте те few sync-вызовы, которые всё ещё нужны, в threadpool.
- Добавьте таймауты, чтобы медленные зависимости не удерживали запросы открытыми.
Первый шаг обычно скучный, и это хорошо. Замените requests на async HTTP-клиент. Используйте async-доступ к базе вместо sync ORM-session, спрятанной внутри async-маршрута. Один блокирующий вызов может остановить event loop для каждого запроса на этом worker.
CPU-работе нужен другой подход. Изменение размера изображений, разбор PDF, большие импорты CSV и сложная генерация отчётов не должны жить в обработчике запроса. Они держат CPU занятым, поэтому async помогает мало. Перенесите эту работу в очередь, отдельный процесс или worker-service. Сначала быстро верните ответ, а потом пусть клиент проверяет статус или забирает результат позже.
Иногда сразу убрать sync-вызов нельзя. Возможно, платежный SDK или внутренняя библиотека поддерживает только sync-код. Тогда оберните его в threadpool осознанно. Считайте это временным мостом, а не базовым дизайном. Если такие вызовы становятся частыми, threadpool превращается в ещё одно узкое место.
Таймауты важнее, чем думает большинство команд. Ставьте их на исходящие HTTP-вызовы, запросы к базе и обращения к кешу. Без таймаута медленная зависимость может накапливать открытые запросы, пока приложение не начнёт ощущаться замёрзшим. Короткий таймаут и понятная ошибка лучше, чем 40 секунд тишины.
Держите обработчики запроса тонкими. Хороший handler должен разобрать входные данные, вызвать один service layer и вернуть ответ. Если маршрут открывает файлы, общается с тремя внешними сервисами, форматирует отчёт и отправляет письмо, он слишком раздут.
Простой пример: endpoint FastAPI принимает загрузку файла, сохраняет метаданные, вызывает внешнее API и строит миниатюры. Отзывчивая версия сохраняет файл, пишет job record, возвращает 202, а затем позволяет worker обработать миниатюры и любую медленную обработку. Пользователь получает быстрый ответ, а приложение продолжает двигаться под нагрузкой.
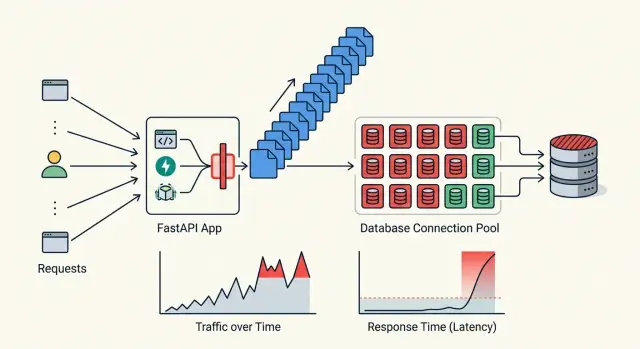
Настраивайте connection pool осознанно
Пул — это ворота для трафика, а не ускоритель. Если задать его слишком большим, приложение может залить базу данных или внешний API и сделать все запросы медленнее. Если задать слишком маленьким, запросы будут ждать, даже когда всё остальное в приложении работает нормально.
Начинайте с системы, у которой самый жёсткий лимит. Если ваша база данных безопасно выдерживает 40 активных соединений, FastAPI-приложению с 8 workers не стоит пытаться открыть по 20 соединений на worker. Такая математика быстро ломает production. Оставляйте запас на миграции, админские инструменты и background jobs.
Не менее важны shared clients. Создайте один database engine и один HTTP-клиент при запуске, а затем переиспользуйте их для каждого запроса. Клиент на каждый запрос сжигает сокеты, не даёт использовать повторно открытые соединения и превращает небольшие всплески трафика в churn соединений.
Исходящие вызовы тоже нуждаются в ограничениях. Если приложение повторяет медленный запрос к стороннему API без лимита соединений, эти повторы начинают накапливаться. В итоге вы ждёте уже не один медленный сервис. Вы ждёте сотни заблокированных задач.
Выбирайте лимиты, которые система выдержит
Простая схема часто работает лучше, чем большая:
- задайте размер пула базы данных по реальной ёмкости базы, а не на глаз
- переиспользуйте один общий async-клиент для каждого сервиса
- ограничьте число исходящих HTTP-соединений и держите количество повторов низким
- поставьте короткие pool timeouts, чтобы запросы быстро падали
- возвращайте понятный 503 или похожую ошибку, когда приложение перегружено
Быстрый провал кажется жёстким, но бесконечное ожидание хуже. Запрос, который таймаутится через 30 секунд, удерживает память, время worker и терпение пользователя. Быстрая ошибка даёт клиенту шанс повторить попытку позже и защищает всё приложение.
Смотрите на время в очереди, а не только на время запроса к БД. SQL-запрос может выполняться 40 мс, но если запрос ждал 900 мс свободного соединения, пользователь всё равно чувствовал медленное приложение. То же правило действует и для исходящего HTTP.
Отслеживайте как минимум три числа: время ожидания слота пула, время реальной работы и количество pool timeout. Такое разделение показывает, нужен ли вам фикс запроса, изменение пула или снижение concurrency.
Простой пример FastAPI под нагрузкой
Одна из частых поломок FastAPI начинается с endpoint для загрузки файла, который выглядит безобидно. Пользователь отправляет файл, приложение сохраняет его, запускает проверку на вирусы, пишет строку в базу данных и возвращает «ok». На ноутбуке это кажется достаточно быстрым.
Проблема начинается, когда маршрут async, а вирусный сканер — нет. Многие команды вызывают sync-сканер из обработчика и считают, что FastAPI всё сгладит. Какое-то время это действительно происходит: работа уезжает в небольшой threadpool.
Где начинается замедление
Теперь добавьте ещё одну проблему: каждый запрос открывает новую session базы данных. Это означает больше churn соединений, больше времени ожидания свободного слота и больше давления на pool. С пятью пользователями вы этого можете не заметить. С пятьюдесятью пользователями, которые загружают файлы одновременно, время ожидания растёт быстро.
Последовательность обычно выглядит так:
- запрос входит в async endpoint
- sync-скан занимает thread
- код базы открывает ещё одну session
- другие запросы накапливаются за обоими лимитами
Сначала threadpool маскирует проблему. Несколько запросов всё ещё завершаются, поэтому приложение выглядит здоровым в базовых тестах. Потом начинаются повторы. Клиенты держат соединения открытыми дольше, workers заняты дольше, и starvation пула становится хуже.
Это легко представить на простых числах. Если скан занимает 2 секунды, а threadpool может запускать 10 сканов одновременно, запрос 11 уже ждёт, прежде чем сделать хоть что-то полезное. Если каждый запрос ещё и создаёт новую session базы данных, пул заполняется работой, которая должна была завершиться гораздо раньше. Приложение не падает. Оно просто становится медленным, а затем непредсказуемым.
Что это исправляет
Чистое решение — вынести сканирование из пути запроса. Сохраните загрузку, верните job ID и пусть worker сканирует файл в фоне. Переиспользуйте database session через нормальный pool вместо создания её с нуля на каждом запросе.
Такое изменение возвращает приложению запас прочности. Запросы на загрузку завершаются быстро, event loop остаётся свободным для новой работы, а pool базы данных обслуживает короткие запросы вместо долгих ожиданий. Это одна из самых частых ошибок async в FastAPI, потому что каждая часть по отдельности кажется небольшой. Вместе они душат загруженное приложение.
Паттерны тестирования, которые ловят зависания заранее
Тесты на один запрос проблему не замечают. Endpoint может вернуть 200 за 40 мс сам по себе и всё равно забить event loop, когда 30 запросов придут одновременно. Многие ошибки async в FastAPI проявляются только тогда, когда приложение делит database pool, HTTP-клиент и медленный upstream API.
Выберите один async-test stack и используйте его во всём проекте. Берите pytest-anyio или pytest-asyncio, а не смесь, которая выросла случайно. Держите одну policy event loop, один стиль async fixtures и один способ создавать test client. Смешанные схемы порождают нестабильные падения и съедают часы.
Какие тесты стоит оставить
- Запускайте concurrency-тест для каждого горячего endpoint. Отправляйте одновременно от 20 до 100 запросов и проверяйте общее время, status codes и то, успевают ли другие запросы завершаться вовремя.
- Добавьте сценарий с медленным upstream. Замокайте одну зависимость так, чтобы она паузила на 2 или 5 секунд, и проверьте, что другие запросы не выстраиваются за ней в очередь.
- Специально доводите pool до exhaustion. Уменьшите pool базы данных или HTTP-клиента в тестовой конфигурации, отправьте больше работы, чем позволяет pool, и убедитесь, что приложение таймаутится или возвращает контролируемую ошибку.
- Ловите блокирующие вызовы. Подменяйте
time.sleep, sync HTTP-вызовы и другие известные блокировки, чтобы тест падал в тот момент, когда кто-то добавит их в async-маршрут.
Один небольшой тест может поймать многое. Заставьте один запрос ждать на fake upstream service, а затем отправьте второй запрос на дешёвый endpoint вроде health или config. Если второй запрос тоже замедляется, скорее всего вы заблокировали loop или слишком долго удерживали слот пула.
Проверка таймаутов так же важна, как и проверка успеха. Не останавливайтесь на «он вернул 504». Проверьте, что приложение отменяет работу, освобождает соединение и пишет понятную ошибку в лог. Если один застрявший запрос удерживает слот навсегда, за него расплачиваются следующие десять пользователей.
Для таких тестов не нужен огромный load rig. Несколько точечных async-тестов в CI ловят зависания заранее, пока исправление — это один небольшой pull request, а не ночной инцидент в production.
Ошибки, которые команды продолжают повторять
Многие ошибки async в FastAPI возникают из-за незавершённых миграций. Команда начинает с async-обработчиков, а потом оставляет один старый sync-драйвер базы данных, потому что «он же работает». Да, работает — пока трафик не растёт и этот один блокирующий вызов не задерживает event loop достаточно долго, чтобы замедлить другие запросы.
Та же каша возникает и с HTTP-вызовами. Если каждый handler создаёт свой AsyncClient, приложение постоянно открывает и закрывает соединения вместо того, чтобы переиспользовать их. Это добавляет latency, тратит сокеты и делает таймауты менее понятными, когда что-то идёт не так.
Background tasks тоже используют не по назначению. Команды переносят медленную работу в BackgroundTasks, отправляют ответ и считают, что проблема исчезла. Она не исчезла. Если задача делает CPU-тяжёлую работу, обрабатывает большие файлы или выполняет блокирующие сетевые вызовы, она всё равно ест ресурсы в том же процессе приложения.
Где обычно начинается проблема
Один маршрут часто собирает всё это вместе:
- async-endpoint, который вызывает sync-библиотеку
- новый database- или HTTP-клиент на каждый запрос
- background task, который длится дольше самого запроса
- размер pool, установленный настолько высоко, что он заливает базу
Большие connection pools выглядят безопасно, но они могут сделать плохой день ещё хуже. Если приложение способно открыть 200 соединений с базой данных, это не значит, что база выдержит 200 тяжёлых запросов с одинаковым качеством. Я видел, как команды «лечили» медленные запросы, повышая лимиты пула, а потом наблюдали, как база тратит всё время на переключение контекста и очереди.
Привычки тестирования тоже мешают это заметить. В кодовой базе может быть идеальное покрытие unit-тестами, и при этом она всё равно зависает под реальной concurrency. Если каждый тест мокает базу, мокает HTTP-сервис и выполняется по одному запросу, вы никогда не увидите churn соединений, starvation пула или блокировку event loop.
Лучший подход прост: держите один async-path для каждого типа I/O, переиспользуйте clients и тестируйте небольшие всплески одновременных запросов на реальных сервисах или близких фейках. Даже 20 параллельных запросов могут выявить проблемы, которые пропускают 2 000 unit-тестов.
Именно такие вещи опытный CTO или advisor замечает быстро во время ревью. Одна схема пути запроса плюс короткий load test часто показывают, почему приложение отлично чувствует себя в staging и липнет в production.
Быстрые проверки перед релизом
Приложение FastAPI может выглядеть нормально в локальных тестах и при этом сильно замедляться в production. Большинство ошибок async в FastAPI возникает из-за нескольких мелких решений, которые накапливаются под нагрузкой: нет таймаута на одном исходящем вызове, новый клиент на каждый запрос или размеры pool, которые не соответствуют реальному трафику.
Используйте короткий pre-release checklist и относитесь к нему как к части code review. Пять минут здесь могут сэкономить часы поиска случайных зависаний позже.
- Поставьте таймаут на каждый исходящий вызов. Это включает HTTP-запросы, вызовы к базе данных, операции с кешем и любую логику повторных попыток в фоне. Если одна зависимость зависнет, ваш запрос должен быстро упасть, а не держать event loop открытым.
- Создавайте shared clients один раз и держите их на весь срок жизни приложения. Переиспользование одного HTTP- или database-клиента убирает лишнюю настройку соединений и делает пулы соединений FastAPI предсказуемыми.
- Настройте лимиты pool осознанно. Подгоните их под число workers, ожидаемую concurrency и жёсткие лимиты вашей базы данных или upstream-сервиса. Больше — не всегда лучше. Чаще это просто переносит узкое место.
- Тестируйте не только happy path, но и сценарии ошибок. Симулируйте повторы, отмену со стороны клиента и очереди запросов, чтобы увидеть, что происходит, когда одновременно накапливаются 20 или 50 запросов.
- Следите за небольшой группой метрик на дашбордах. Queue time, rate таймаутов и число открытых соединений очень быстро показывают, ждёт ли приложение код, зависимость или просто перегружено.
Простой пример: если у вас 4 workers и каждый worker может открыть 50 соединений с базой данных, вы легко можете запросить 200 соединений, даже не заметив этого. Если база разрешает только 100, запросы начнут выстраиваться, таймаутиться или падать рывками. Проблема выглядит случайной, пока вы не посмотрите на цифры.
Команды, которые сохраняют спокойствие в production, обычно делают эти проверки скучными и повторяемыми. Они хранят shared clients в startup и shutdown hooks, ограничивают retries и специально тестируют задержки. Вот как отзывчивые Python-приложения остаются отзывчивыми, когда приходит реальный трафик.
Что делать команде дальше
Выберите один endpoint, который получает реальный трафик, и разберите его на этой неделе. Не начинайте с изменения числа workers или добавления новых серверов. Если один запрос всё ещё блокирует event loop, дополнительные workers лишь временно скроют проблему.
Хорошая первая цель — маршрут, который начинает тормозить первым при росте трафика. Для многих команд это login, search, checkout или dashboard API, который собирает данные из нескольких источников. Проследите этот путь от начала запроса до ответа и отметьте каждый вызов базы данных, HTTP-вызов, чтение файла, sleep и CPU-тяжёлый шаг.
Используйте короткий checklist и держите его практичным:
- Выберите один горячий endpoint и измерьте его обычное время ответа и p95 под небольшой нагрузкой.
- Уберите одну блокирующую библиотеку прежде, чем настраивать concurrency.
- Задайте лимиты pool для базы и HTTP-клиента осознанно, а затем проверьте их под нагрузкой.
- Добавьте один load test в CI до следующего релиза, даже если он совсем небольшой.
Этот порядок важен. Команды часто тратят дни на настройку Gunicorn или Uvicorn, пока один sync SDK, ORM-вызов или файловая операция останавливает каждый запрос за собой. Сначала исправьте блокирующую работу. Тогда настройка pool и числа workers начнёт действительно что-то значить.
Ваш CI-тест не обязан быть сложным. Простой прогон, который несколько минут отправляет ровный поток трафика, может рано поймать очереди, медленное восстановление пула и всплески таймаутов. Если время ответа резко растёт, когда concurrency увеличивается с 20 до 50, у вас появляется понятное место для поиска до того, как это почувствуют пользователи.
Если ваша команда постоянно сталкивается с одними и теми же ошибками async в FastAPI, внешний разбор может сэкономить время. Oleg Sotnikov может провести аудит блокирующих вызовов, лимитов connection pool и тестовой настройки в рамках Fractional CTO support. Это особенно полезно, когда нужен понятный план исправлений без переписывания всего приложения. Если зависания продолжают появляться в production, запишитесь на консультацию и сначала устраните реальные узкие места.


