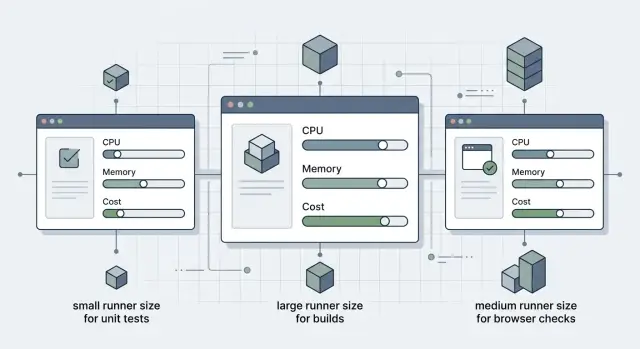
Подберите размер runner’ов CI для каждой стадии и сократите потери
Подберите размер runner’ов CI по стадиям: unit-тесты, сборки и браузерные проверки должны использовать только ту CPU и память, которые им реально нужны.
Содержание
Почему один дефолтный runner тратит деньги\n\nБольшинство команд начинают с одного размера runner’а для всех задач. Это кажется аккуратно и просто в управлении. Но это также быстрее сжигает бюджет, чем многие ожидают.\n\nRunner — это машина, которая выполняет работу CI. Job — это отдельная задача, например запуск unit-тестов или сборка образа. Stage — группа задач, например тесты, сборки или браузерные проверки.\n\nПроблема проста: большинству задач не нужна одинаковая машина. Job с unit-тестами может завершаться за 40 секунд и использовать половину CPU, но вы всё равно платите за весь runner всё это время. Если для быстрых проверок всегда используется та же большая машина, что и для тяжёлой сборки, простаивающий CPU превращается в постоянный месячный платёж.\n\nКоманды часто усугубляют ситуацию: в ответ на одну медленную стадию они делают дефолтный runner больше для всех. Это помогает тяжёлым задачам, но многие другие задачи от этого не выигрывают. Линтинг, короткие прогонки тестов и небольшие скрипты продолжают выполняться на дорогом железе, которое они почти не используют.\n\nОдин дефолтный runner также скрывает проблемы с очередями. Представьте пул из двух одинаковых runner’ов. Долгая сборка контейнера занимает один на 12 минут. Набор браузерных тестов занимает второй на 8. Тем временем пять мелких задач сидят в очереди, хотя каждая из них завершилась бы за ~30 секунд на гораздо меньшей машине. Очередь растёт, разработчики ждут, а команда всё ещё оплачивает слишком большие машины.\n\nВот почему важно подбирать размер runner’а по стадии пайплайна. Это не только про экономию. Когда машина соответствует работе, маленькие задачи перестают конкурировать с тяжёлыми, и пайплайн обычно становится быстрее.\n\nСамое неприятное — насколько обычной выглядит эта трата. Пайплайны проходят. Сборки завершаются. Никто не замечает, что простая тестовая задача проводит большую часть времени на машине гораздо большего размера, чем нужно. Со временем это «тихое» расточительство складывается в заметную сумму.\n\n## Что действительно нужно каждой стадии\n\nВ большинстве пайплайнов выполняется очень разный набор работ, но команды всё равно отправляют каждую задачу на один и тот же runner. В конфиге это выглядит аккуратно, а в реальности — расточительно.\n\nЧтобы правильно подбирать размеры, сортируйте задачи по тому, что их замедляет. CPU — это лишь часть истории. Некоторые задачи ждут старта контейнера, некоторые упираются в память, некоторые проводят большую часть времени в браузере.\n\nUnit-тесты обычно самые простые для переплаты. Многие из них быстро завершаются, используют умеренное количество памяти и больше зависят от короткого времени ожидания в очереди и быстрого старта контейнера, чем от чистой мощности CPU. Если тест работает 90 секунд и половину времени тратит на установку пакетов или поднятие сервисов, большая машина мало что изменит.\n\nСборки другие. Компиляторы, бандлеры, Docker-сборки и большие деревья зависимостей часто требуют больше RAM, локального диска и тёплых кешей. Когда на сборочном runner’е не хватает памяти, задача замедляется, начинает свопиться или падает. Это один из редких случаев, когда больший runner окупает себя.\n\nБраузерные проверки — отдельная категория. End-to-end тесты кажутся дорогими, потому что идут дольше, но большую часть времени «съедает» сам браузер: загрузки страниц, анимации, повторы действий, скриншоты и запись видео растягивают время. Такие задачи обычно нуждаются в стабильном CPU и достаточной памяти, чтобы браузер держался, но не всегда требуют самой большой машины в пуле.\n\nМаленькая команда может заметить это по истории задач за неделю. Unit-тесты могут прекрасно выполняться на лёгком runner’е. Frontend-сборка может потребовать вдвое больше RAM. Playwright-проверки могут оказаться оптимальными на среднем runner’е с меньшей параллельностью. Одна и та же линия — три разные потребности.\n\nБольшая часть потерь происходит потому, что задачи группируют по привычке, а не по поведению. Задайте простой вопрос для каждой стадии: что ограничивает задачу — время старта, память, диск, сеть или сам браузер?\n\nКогда вы так распределите задачи, подбор размеров runner’ов перестанет быть гаданием. Это станет осознанным выбором по затратам, который можно объяснить по строчке.\n\n## Начните с простого базиса\n\nСтартуйте с данных, которые уже есть в вашем пайплайне. Не нужен идеальный отчёт или новый инструмент. Возьмите одну–две недели истории задач из вашей CI-системы и смотрите реальные прогонки, а не догадки.\n\nЭтого обычно достаточно, чтобы заметить закономерности. Большинство команд обнаруживают, что unit-тесты, сборки и браузерные проверки ведут себя по-разному, хотя всё ещё работают на одном размере машины.\n\nСначала сгруппируйте задачи по стадиям. Затем посмотрите среднее время выполнения и обычный разброс для каждой группы. Сборка, которая обычно идёт 6–8 минут, сильно отличается от браузерной стадии, где время может прыгать от 4 до 20 минут из-за ожидания памяти, сети или старта.\n\nИщите четыре сигнала:\n\n- задачи, которые падают с ошибками по памяти\n- задачи, которые достигают лимита времени\n- задачи, которые проводят в очереди больше времени, чем выполняются\n- задачи, которые потребляют большую часть общего времени работы runner’а\n\nЭти сигналы говорят больше, чем простая длительность. Короткая задача с 10 минутами в очереди — это проблема ёмкости. Долгая задача со стабильным временем выполнения, вероятно, нуждается в лучшем размере runner’а. Задача, которая падает из-за памяти, не должна оставаться на маленькой машине только потому, что большинство других задач там влазит.\n\nОставьте первый проход простым. Вам не нужен финансовый моделинг. Цель — найти несколько задач, которые формируют большую часть счета, и те, что ежедневно замедляют разработчиков.\n\nНебольшая команда справится с этим за один день. Они могут обнаружить, что unit-тесты хорошо идут на маленьком runner’е, Docker-сборки нуждаются в дополнительных ядрах и памяти на несколько минут, а браузерные проверки требуют больше памяти, а не больше ядер. Этого достаточно, чтобы начать изменения без переписывания всего пайплайна.\n\nЗапишите один базовый профиль для каждой стадии: среднее время, заметки по падениям и время в очереди. Когда это сделано, изменения размеров runner’ов будут исходить из данных, а не привычки.\n\n## Как шаг за шагом назначать размеры runner’ов\n\nНачинайте с задач, которые вы уже запускаете, а не с характеристик машин. Команды обычно ошибаются, выбирая железо сначала, а рабочую нагрузку потом.\n\nОткройте историю пайплайна за обычную неделю, не за релизную неделю и не за период с инцидентом. Перечислите все стадии и задачи внутри: unit-тесты, линт, сборка приложения, сборка образа, браузерные проверки, деплой. Делайте это просто.\n\nНе создавайте пять классов runner’ов в первый день. Трёх обычно достаточно: small, medium и large. Точные CPU и RAM задайте позже, когда поймёте, какие задачи простаивают, а какие действительно нагружают машину.\n\nОтнесите быстрые частые задачи в small: линт, unit-тесты и лёгкие проверки. Большинство задач сборки поместите в medium — им чаще нужна память, но не всегда большая машина. Оставьте large для дорогих задач: тяжёлые компиляции, сборки контейнеров или большие браузерные наборы, которые действительно их требуют.\n\nЗатем пометьте каждую задачу тегом, чтобы она попадала на нужный runner. В GitLab CI простые теги вроде small, medium и large делают конфиг читабельным.\n\nМеняйте одну стадию за раз и наблюдайте несколько дней. Отслеживайте время выполнения, время в очереди, частоту падений и насколько runner выглядит недогруженным. Это важнее, чем многие думают. Если менять весь пайплайн сразу, будет трудно понять, что помогло, а что навредило.\n\nНе нужно идеальных цифр в первый проход. Если unit-тесты стали на 20 секунд медленнее, но перестали тратить лишний CPU весь день, такая обмена часто приемлема. Если браузерные проверки начали ждать в очереди, исправляйте только ту стадию, а не делайте все runner’ы больше.\n\nЧерез неделю картина обычно ясна. Большинство команд видят, что лишь небольшая часть пайплайна нуждается в medium или large runner’ах, а дефолтная машина была больше, чем нужно.\n\n## Реалистичный пример из практики одной команды\n\nСемичленная продуктовая команда использовала один дефолтный runner для всех CI-задач. Это была большая машина, выбранная несколько месяцев назад после одной медленной Docker-сборки, которая всех раздражала. Это решило проблему сборки, но означало, что дешёвые задачи работали на дорогом железе весь день.\n\nТрата проявлялась в самых простых местах. Unit-тесты быстро завершались, но всё равно работали на том же большом runner’е, что и тяжёлые сборки. Большая часть CPU простаивала.\n\nКоманда перешла на подбор размера runner’ов по стадиям вместо одного универсального. Unit-тесты переместили на маленькие runner’ы с умеренной памятью. Эти задачи в основном проверяли логику приложения и пару моков, поэтому им не нужна была большая мощность. Поскольку runner’ы стали дешевле, команда могла запускать больше тестов параллельно, не увеличивая расходы.\n\nDocker-сборки оставили на больших машинах. Эта стадия действительно нуждалась в дополнительном CPU и памяти. Устанавливаемые зависимости, слои образа и сжатие на больших слотах работали быстрее, поэтому команда платила больше за минуту, но тратила меньше минут в сумме.\n\nБраузерные проверки запустили на средних runner’ах. Команда дала им достаточно памяти для браузера и артефактов, а вместо увеличения CPU подняла таймауты. Это сработало лучше, чем ожидалось: большая часть задержки приходилась на загрузки страниц и настройку тестов, а не на чистую вычислительную мощность.\n\nРелизные задачи тоже изменили: их перенесли в отдельный пул runner’ов, вдали от повседневной работы с ветками. Раньше релиз мог заблокировать обычные пуши и замедлить обратную связь для всех. После разделения разработчики продолжали получать быстрые результаты тестов, даже когда кто-то делал релиз.\n\nИтоговая настройка была простой: small — для unit-тестов и линтинга, medium — для браузерных проверок, large — для Docker-сборок и отдельно пул для релизов и публикаций.\n\nОни не гнались за идеальными цифрами в первый день. Наблюдали время в очереди, частоту падений и суммарные минуты задач две недели, затем корректировали одну стадию за раз. Этого обычно достаточно, чтобы сократить потери, не превращая CI в управленческий проект.\n\n## Когда больший runner оправдан\n\nБольшой runner окупается, когда задача действительно тратит время на тяжёлую работу, а не на ожидание сети или бездействие. Если сборка компилирует большой код, создаёт релизные пакеты или сжимает тяжёлые артефакты, дополнительные CPU и память могут срезать минуты с каждой прогонки.\n\nТо же верно для задач, которые распаковывают большие наборы зависимостей. Установка пакетов может выглядеть просто, но для некоторых языков это тысячи файлов, которые затем распаковываются и обрабатываются. На маленькой машине такая работа тормозит из-за нехватки памяти, свопа или дисковой скорости.\n\nБраузерные проверки тоже могут оправдать большую машину. Headless-браузер, тестовый сервер, скриншоты и запись видео складываются в заметную нагрузку. Если тесты падают только в CI и runner перед стартом уже выглядит загруженным, больший runner может устранить реальный узкий профиль.\n\nОшибка не в использовании большого runner’а. Ошибка — сделать его дефолтным. Unit-тесты, линт и мелкие скрипты обычно хорошо работают на более дешёвых машинах. Если каждая задача попадает в один и тот же размерный пул, вы платите премию даже тогда, когда работа почти не использует железо.\n\nЛучший подход — держать редкие тяжёлые задачи отдельно. Релизные сборки, мобильная упаковка, большие Docker-сборки и полные браузерные наборы можно отправлять в большой пул с жёсткими правилами. Это резервирует дорогие машины для тех задач, которые действительно в них нуждаются.\n\nПеред увеличением мощности попробуйте ещё одну вещь: разбейте задачу. Одна длинная job может объединять установку зависимостей, сборку, упаковку и браузерные проверки в один запуск. Разбиение на две–три задачи часто работает лучше, чем просто давать больше железа.\n\nЕсли тяжёлой оказывается только часть, масштабируйте только её. Сравните оба варианта по времени: один большой runner для всей задачи или несколько меньших с изолированным тяжёлым шагом. Дешёвая опция не всегда очевидна, но быстро проявляется при измерениях.\n\n## Ошибки, которые увеличивают расходы\n\nСамая распространённая трата проста: каждая задача получает самый большой runner. Unit-тесты на 40 секунд не нуждаются в той же машине, что и полная production-сборка или браузерный набор. Когда команды используют один чрезмерный дефолт, они платят премиум за задачи, которые едва трогают CPU.\n\nЕщё одна дорогая привычка — включать параллелизм слишком рано. Пайплайн кажется медленным, и командa разбивает тесты на четыре runner’а. Это может помочь, но только после исправления медленной подготовки. Если каждая задача тратит по две минуты на установку одних и тех же пакетов, загрузку браузеров или сборку одних и тех же зависимостей, параллельность лишь умножает траты.\n\nПромахи кеша скрывают заметную долю затрат. Один неправильный ключ кеша или частое истечение заставляют дешёвую задачу снова и снова скачивать зависимости. Видно в логах: одни и те же слои образа, npm-пакеты или бинарники браузеров загружаются снова и снова. Счёт растёт, а пайплайн всё ещё медленный.\n\nСмесь очень коротких unit-тестов и долгих браузерных сессий создаёт ещё одну проблему. Короткие задачи быстро завершаются, но длинная браузерная задача держит runner занятым дольше. Если оба типа шарят один пул, быстрые задачи ждут за тяжёлыми. Вся линия выглядит недообеспеченной, хотя реальная проблема — плохое разделение работ.\n\nВремя в очереди чаще обвиняют в нехватке CPU, чем следует. Если задачи ждут пять минут перед стартом, большее железо не решит проблему. Узким местом может быть маленький пул runner’ов, неправильные теги, ограничение параллельности или один браузерный runner, за который борются все ветки.\n\nПризнаки обычно очевидны: крошечные тесты идут на том же типе машины, что и сборки; подготовка занимает больше времени, чем сама задача; загрузки повторяются в большинстве прогонов; браузерные проверки блокируют быстрые проверки; или время в очереди растёт, хотя загрузка runner’ов выглядит низкой.\n\nИсправьте эти проблемы прежде, чем покупать больше CPU. Для многих команд это уже даёт заметную экономию без потери покрытия тестов.\n\n## Быстрая проверка перед добавлением CPU\n\nБольшинство медленных CI-задач не сидят в узком месте CPU. Команды ставят большее железо, а потом выясняют, что задача половину времени тратит на скачивание пакетов, слоёв образов или ожидание сервиса.\n\nОткройте несколько недавних прогонов и сравните время подготовки и реальной работы. Если unit-тесты идут 3 минуты, а установка зависимостей занимает 5, дополнительные ядра почти не повлияют. Сначала почините путь скачивания.\n\nОдин медленный набор тестов может исказить всю стадию. Возможно, у вас 20 быстрых тестов и один тяжёлый интеграционный набор, который занимает runner долго после завершения остальных. Вынесите этот набор в отдельную задачу или разделите его, прежде чем масштабировать всю стадию.\n\nОшибки кеша легко пропустить. Изменение lockfile, новый ключ кеша или ошибка пути могут превратить каждую прогонку в «холодный старт». Сравните быстрый и медленный пайплайн и проверьте, реально ли восстановился кеш. Если нет, большой runner лишь временно скроет проблему.\n\nРазделяемые сервисы создают фальшивые проблемы с CPU. Параллельные задачи могут одновременно бить по одному реестру пакетов, тестовой базе или Docker-реестру. Когда четыре задачи тормозят одновременно, runner может быть в порядке, а узкое место — где-то ещё.\n\nБраузерные проверки теряют время иначе. E2E-тесты часто полагаются на фиксированные паузы, поэтому job ждёт даже тогда, когда страница уже готова. Замените длинные sleep явными ожиданиями, сократите повторы и сохраняйте скриншоты/видео только там, где они помогают отлаживать — это может срезать минуты со стадии без изменения размера runner’а.\n\nЕсли после всех проверок CPU остаётся под 100% большую часть времени, тогда большая машина, вероятно, оправдана. Так команды тратят больше только тогда, когда пайплайн действительно в этом нуждается.\n\n## Следующие шаги для более экономного CI\n\nСамый быстрый путь сократить траты в CI — начать со стадии, которая сегодня стоит больше всего. Обычно это долгая сборка, стадия браузерных тестов или задача, которая запускается на каждый pull request. Пытаться оптимизировать все стадии сразу — значит потеряться в деталях и пропустить крупные экономии.\n\nВыберите две метрики до изменений. Одна — цель по скорости, например "проверки pull request завершаются за 12 минут или меньше", и одна — цель по затратам, например "сократить месячные расходы на runner’ы на 20%". Чёткие лимиты не дадут команде гоняться за скоростью там, где никто не ждёт результатов.\n\nДержите план простым. Ранжируйте стадии по месячной стоимости, изменяйте размер самой дорогой сначала, измеряйте неделю и оставляйте дешёвые стадии на маленьких runner’ах, если они не блокируют разработчиков. Запишите размер runner’а для каждой стадии, чтобы никто тихо не вернул всё к одному дефолту позже.\n\nНе считайте подбор размера одноразовым. Изменения в коде, новые тестовые инструменты, увеличившиеся Docker-образы и обновления браузеров постоянно меняют форму пайплайна. Настройка, которая имела смысл три месяца назад, может тихо превратиться в источник потерь или медленных очередей.\n\nЕсли команде нужна вторая точка зрения, Oleg Sotnikov из oleg.is работает со стартапами и малыми компаниями над delivery-пайплайнами, инфраструктурой и AI-first инженерными операциями. Короткий обзор от опытного Fractional CTO часто достаточно, чтобы заметить слишком большие билд-машины, дублирующиеся задачи или дорогие runner’ы, назначенные простым проверкам.