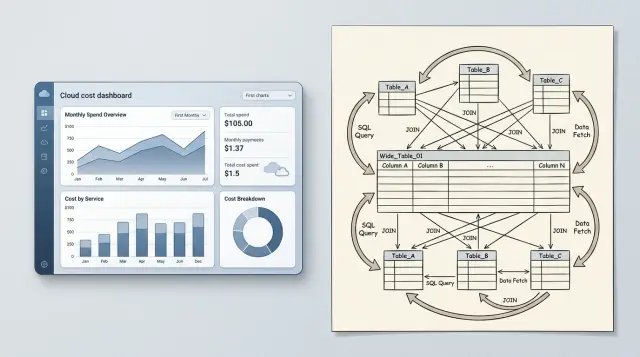
Оптимизация производительности базы данных начинается с модели данных
Оптимизация производительности базы данных часто начинается с небольших правок схемы: более узких таблиц, меньшего числа соединений и меньшего числа дублирующих записей.
Содержание
Почему база данных кажется медленной, даже когда сервер не перегружен
Медленная страница не всегда значит, что серверу не хватает мощности. Очень часто страница запрашивает у базы данных куда больше данных, чем ей нужно, а потом ждёт, пока эти данные прочитаются, будут соединены, отсортированы и отправлены обратно.
Именно поэтому база данных может казаться медленной, даже когда графики CPU выглядят спокойно. Машина не всегда «работает на износ» в очевидном смысле. Она может тратить время на то, чтобы вытаскивать лишние строки с диска, прогонять большие наборы результатов через память или просматривать столбцы, которые страница никогда не показывает.
Панель с показателями — хороший пример. На ней может быть всего шесть чисел, но запрос под капотом читает полные записи, соединяет несколько таблиц и забирает старые данные, на которые никто не смотрит. Страница ощущается медленной, хотя сервер при этом выглядит наполовину простаивающим.
Формы тоже этим грешат. Обычный экран редактирования может загружать полный профиль клиента, историю заказов, внутренние заметки, права доступа и данные аудита только для того, чтобы заполнить десять видимых полей. Отчёты ещё хуже, когда каждый раз при обновлении страницы они заново строят тот же тяжёлый запрос.
Одни и те же паттерны всплывают снова и снова:
- Страницы запрашивают целые строки, хотя им нужны лишь несколько столбцов.
- Запросы соединяют таблицы ради удобства, а не потому, что пользователю прямо сейчас нужны эти данные.
- Приложение повторяет чтения, потому что одни и те же данные хранятся в нескольких местах.
- Отчёты сканируют рабочие таблицы вместо того, чтобы использовать более простые сводные данные.
Покупка более мощного инстанса может на время уменьшить боль. Больше RAM позволяет кэшировать больше страниц. Более быстрые CPU сокращают время части запросов. Но дополнительное железо часто лишь скрывает настоящую проблему, а не решает её.
Если схема подталкивает приложение к слишком объёмным чтениям, лишняя нагрузка растёт с каждым новым клиентом, отчётом и функцией. Сначала растут расходы. Потом растёт задержка. А затем команды начинают винить движок базы данных, хотя ловушку поставила именно модель данных.
Реальные ограничения железа, конечно, существуют. Иногда вам действительно нужны дополнительные IOPS, память или реплики. Но ошибки в схеме выглядят иначе. Сервер не упирается в 100 процентов. Вместо этого обычные действия вроде открытия формы или загрузки дашборда кажутся медленнее, чем должны быть при таком объёме работы на экране.
Обычно это и есть подсказка: пользователю кажется, что он делает маленькую задачу, а база данных в это время обрабатывает гораздо более крупную.
Что делают широкие таблицы с повседневными запросами
Широкая таблица складывает слишком много не связанных между собой полей в одну строку. Такое бывает, когда одна таблица хранит сведения об аккаунте, настройки оплаты, внутренние заметки, маркетинговые флаги, параметры экспорта и старые поля миграций — всё вместе. Сначала это кажется удобным, потому что всё лежит в одном месте.
Проблемы начинаются, когда большинству экранов не нужна большая часть этой строки. Например, странице списка пользователей могут быть нужны только имя, email, статус и последний вход. Если в строке ещё есть десятки редко используемых столбцов, базе данных всё равно приходится перемещать куда больший объём данных, чем запросила страница.
Это быстро накапливается. Чем больше строка, тем меньше строк помещается в память и в каждую страницу данных. Чтения забирают больше байтов с диска или из кэша. Записи тоже становятся тяжелее, потому что каждый insert или update затрагивает более крупную структуру, даже если вы меняете всего одно маленькое поле.
Строки с большим количеством пустых столбцов — ещё один тревожный сигнал. Пустые значения не всегда стоят столько же, сколько заполненные, но они всё равно показывают, что таблица пытается делать слишком много разных задач. То же самое касается столбцов, которые почти никто не читает, полей, оставленных ради одного отчёта, который запускается раз в месяц, или настроек, используемых одним внутренним инструментом.
Типичный паттерн выглядит так:
- одна таблица хранит 70 или 100 столбцов
- половина из них пустая у большинства строк
- одна страница читает 6 столбцов, но снова и снова забирает всю строку целиком
- простые обновления начинают вызывать больше операций ввода-вывода, чем ожидалось
Именно поэтому оптимизация производительности базы данных часто начинается с модели данных, а не с размера сервера. Если вы разделите редко используемые или отдельные по смыслу данные в собственные таблицы, повседневные запросы станут легче. Кэш тоже будет работать лучше, потому что база данных сможет держать под рукой больше полезных строк.
Подумайте об экране профиля клиента. Приложению каждый раз нужна базовая контактная информация, но налоговые детали, юридические заметки, ответы из онбординга и история обращений в поддержку могут появляться лишь время от времени. Если держать всё это в одной широкой строке, частый сценарий постоянно платит за редкий сценарий.
Как в запросы незаметно попадают лишние соединения
Соединение помогает, когда данные действительно лежат в разных местах и запросу нужны обе части одновременно. Заказы и клиенты хорошо подходят под такой сценарий. Вы храните сведения о клиенте один раз, а потом соединяете их, когда экрану нужно имя, email или статус аккаунта.
Проблемы начинаются, когда соединения остаются в запросе задолго после того, как продукт перестал в них нуждаться. Команда добавляет таблицу настроек клиента, таблицу региона, таблицу рефералов и старую таблицу профиля. Через несколько месяцев на странице показываются только номер заказа, сумма и дата, но запрос всё ещё тянет всё подряд. Каждое дополнительное соединение добавляет работу, даже если никто не видит лишние поля.
Такое часто происходит из-за повторяющихся обращений за мелкими кусочками данных. Страница может соединять три таблицы только ради того, чтобы получить подпись, флаг и описание, которые пользователи всё равно никогда не открывают. Иногда разработчики оставляют эти соединения, потому что однажды они понадобились старому админскому экрану. Иногда их по умолчанию сгенерировал ORM, и никто не задался вопросом, нужны ли они вообще.
Старые пожелания по функциям только ухудшают ситуацию. Одна функция добавляет соединение с скидками. Другая — с правилами доставки. Потом поддержка просит добавить маркер мошенничества, а финансовый отдел — метаданные по налогам. Никто ничего не удаляет, и простая таблица заказов превращается в цепочку из шести или семи соединений. База данных всё ещё отвечает, но время отклика растёт, а кэш промахивается чаще.
Полезное правило для оптимизации производительности базы данных простое: держите самые нагруженные пути короткими. Если запрос выполняется весь день, старайтесь, чтобы он был максимально близок к тем таблицам, которые важнее всего. Обычно чем меньше таблиц в самых нагруженных путях, тем лучше.
Обратите внимание на такие признаки:
- запрос соединяет таблицы, чьи столбцы никогда не появляются на экране
- список соединяет детальные таблицы, которые нужны только для экрана с детализацией
- старые необязательные функции оставили после себя постоянные соединения
- одно и то же обращение выполняется при каждом запросе, хотя значение меняется редко
Не нужно уплощать всё в одну таблицу. Нужно просто перестать платить за связи, которыми продукт не пользуется. На практике это часто означает сначала сократить соединения в самых загруженных запросах, а затем перенести редко используемые данные в последующие запросы или предвычисленные поля.
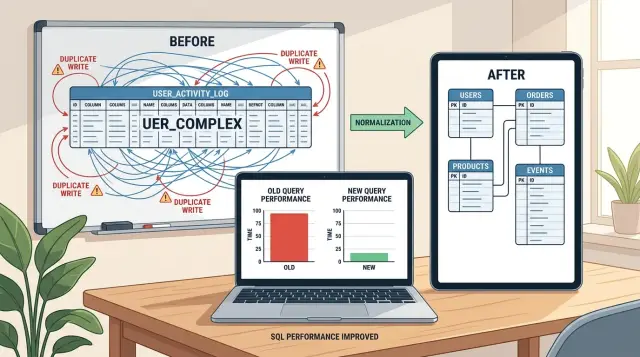
Почему дублирующие записи стоят дороже, чем место на диске
Когда один и тот же факт живёт в трёх местах, любое маленькое изменение становится тяжелее. Имя клиента в таблице users — это нормально. То же самое имя, скопированное в orders, invoices и shipments, превращает одно изменение в четыре записи, четыре точки возможного отказа и четыре места, где потом придётся искать проблему.
Хранилище обычно — дешёвая часть. Дорого обходится не оно. Каждая дополнительная запись добавляет время работы базы данных, обновления индексов, время блокировок, трафик репликации и больше кода в приложении. Сохранение, которое должно завершаться за 20 мс, может превратиться в цепочку обновлений, которая кажется пользователям медленной, особенно когда это делают одновременно многие.
Ещё серьёзнее проблема рассинхронизации. Одна копия меняется, другая — нет, и теперь система спорит сама с собой. Поддержка видит счёт с старым названием компании, на странице аккаунта уже новое, а экспорт для финансового отдела показывает третью версию. Люди перестают доверять данным и начинают проверять всё вручную.
В системах заказов это встречается очень часто. Команды нередко копируют цену товара, название товара, адрес клиента и налоговые поля в несколько таблиц, потому что сначала это кажется удобным. Некоторые копии действительно имеют смысл. Например, итоговую цену продажи стоит сохранить в заказе, чтобы история осталась корректной. Но если вы ещё и храните те же живые данные о клиенте в пяти местах, обычные правки профиля становятся рискованными.
Обратите внимание на такие признаки:
- одна форма сохраняет данные в несколько таблиц
- фоновые задачи исправляют несовпадающие записи
- сотрудники поддержки вносят ручные правки
- отчёты расходятся по одному и тому же клиенту или заказу
- простые изменения требуют больших транзакций
Дублирующие записи вредят оптимизации производительности базы данных, потому что делают сохранения медленнее, а исправления — сложнее. Они ещё и разносят бизнес-правила по всему коду. Разработчик меняет один путь обновления и забывает другой, а потом баги всплывают через несколько недель.
Более чистая модель выбирает одно место для каждого факта и копирует данные только тогда, когда это требует история. Обычно такой подход снижает нагрузку на записи, убирает странные баги и делает будущие изменения намного менее болезненными.
Как пошагово проверить модель данных
Большинство команд сначала смотрит на схемы, но логи запросов быстрее показывают правду. Начинайте с чтений и записей, которые происходят весь день, а не с тех, что выглядят плохо только на бумаге.
Соберите короткий список самых загруженных обращений к базе данных. Посмотрите на две группы: запросы, к которым пользователи обращаются каждую минуту, и записи, которые запускаются обычными действиями вроде регистрации, поиска, оформления заказа или редактирования записи. Если один запрос выполняется 50 000 раз в день, даже маленькая правка может сэкономить много времени.
Затем проверьте, что именно использует каждый экран или каждый вызов API. Широкие таблицы часто разрастаются потому, что команды продолжают добавлять столбцы «на всякий случай». Если страница показывает пять полей, а запрос тащит обратно сорок, отметьте лишние столбцы. То же самое сделайте с полями, по которым никто не фильтрует, не сортирует и не ищет.
Простой процесс проверки помогает держать работу небольшой и честной:
- Составьте список самых загруженных чтений и записей по частоте и времени ответа.
- Сопоставьте каждый запрос с экраном или действием, которое его запускает.
- Отметьте поля, которые приложение никогда не показывает, не использует в фильтрах и не обновляет в этом сценарии.
- Проследите одно действие пользователя от запроса до каждой записи в базе данных.
- Измените одну горячую точку, затем сравните число запросов и время ответа.
Прослеживать одно действие пользователя важнее, чем ожидают многие команды. Один клик по кнопке может записать одни и те же данные в таблицу orders, таблицу audit, таблицу cache и таблицу reporting. Часть этих записей вполне нормальна. Часть осталась от старой функции. Лишнее можно найти только если пройти весь путь целиком.
Первый круг держите узким. Разделите одну перегруженную таблицу. Уберите одно соединение, которое не даёт пользы пользователю. Остановите одну дублирующую запись. Небольшие изменения проще тестировать, и они показывают, какая именно часть модели данных действительно замедляет приложение.
Измеряйте каждое изменение одними и теми же метриками. Проверяйте медианное время ответа, самые медленные запросы, число прочитанных строк и общее число запросов на один запрос пользователя. Так оптимизация производительности базы данных становится не угадыванием, а доказательством. Если одна чистка экономит 20–50 миллисекунд на нагруженном пути, возможно, более крупные инстансы вам вообще не нужны.
Простой пример из системы заказов
Небольшой магазин часто начинает с одной таблицы orders, которая всё растёт. Сначала в ней только ID заказа, ID клиента, сумма и дата создания. Через год в той же строке уже лежат адрес выставления счёта, адрес доставки, разбивка по налогам, данные купона, номера счетов, флаги экспорта, заметки по упаковке, заметки по возвратам и ещё десяток полей, пустых у большинства заказов.
Выглядит удобно, но каждая вставка и каждое обновление становятся тяжелее. Оформление заказа записывает большую строку, потом записывает её ещё раз, когда проходит платёж, потом ещё раз, когда начинается доставка. Если в таблице есть несколько индексов, каждая запись стоит дороже, чем должна.
Тот же поток оформления заказа может ещё и копировать итоги в три места: orders, invoices и дневную сводную таблицу. Теперь одна сумма корзины превращается в три записи ещё до того, как клиент увидит страницу подтверждения. Если меняются налоги, исправляется скидка или платёж не проходит с первой попытки, приложению приходится удерживать эти копии в синхронном состоянии. Это дополнительная работа для базы данных и дополнительный риск для команды.
Административная страница часто делает ситуацию ещё хуже. Простой список заказов нуждается в номере заказа, имени клиента, сумме и статусе. Но запрос соединяет orders, customers, order_items, payments, shipments и invoices, потому что приложение заново собирает одно поле статуса из разрозненных данных. На списке из 100 заказов это может означать очень много чтений только ради того, чтобы вывести «Оплачено» или «Отправлено».
Первые исправления обычно небольшие:
- Оставьте
ordersтолько с теми полями, которые нужны почти при каждом чтении. - Перенесите редкие или узконаправленные поля в
order_metadata,invoicesилиshipments. - Выберите один источник для итогов во время оформления заказа и создавайте снимки для счёта только тогда, когда счёт действительно существует.
- Храните
current_statusвorders, если он нужен админскому списку весь день, а строки оплаты и доставки оставьте как историю.
После этого админский список сможет читать одну более компактную таблицу в большинстве запросов, а страница с деталями будет загружать дополнительные таблицы только тогда, когда кто-то откроет конкретный заказ. Это и есть та оптимизация производительности базы данных, которая часто экономит больше времени, чем более крупный сервер. Сначала она снижает нагрузку на записи, а затем уменьшает стоимость чтения там, где люди сильнее всего чувствуют тормоза.
Ошибки, которые тратят время и деньги
Команды часто тратят деньги не на то исправление, потому что медленная часть кажется невидимой. Более крупный инстанс, новый кэш или новая база данных звучат конкретно. А грязная модель данных — нет. Но многие медленные системы остаются медленными именно потому, что таблицы и запросы продолжают делать лишнюю работу на каждом обращении.
Одна из частых ошибок — слишком рано делить таблицы. На бумаге сильно разнесённая модель выглядит аккуратно. На практике, если приложение каждый раз читает одни и те же части вместе, вы просто создаёте больше соединений, больше планирования запросов и больше шансов на ошибки. Нормализуйте ради причины, а не ради стиля.
Ещё одна дорогая привычка — копировать данные ради удобства и потом никогда не удалять копии. Команда добавляет дублирующие столбцы, чтобы избежать одного соединения, а потом пишет код синхронизации, догрузки старых данных, исправления и обработки крайних случаев. Через несколько месяцев никто уже не доверяет тому, какое поле правильное. Хранилище обычно — дешёвая часть. А вот путаница и лишняя нагрузка на записи — нет.
Некоторые привычки заслуживают особого недоверия:
- Добавлять кэш до того, как исправлены исходные таблицы
- Менять много запросов в одном релизе и терять базовую точку отсчёта
- Держать поля только для отчётов внутри рабочих транзакционных таблиц годами
- Копировать данные в боковые таблицы без плана очистки
Кэши помогают, но часто лишь скрывают проблему проектирования вместо того, чтобы исправить её. Если базовый запрос просматривает слишком много данных или соединяет пять таблиц ради простого экрана, кэш становится заплаткой, которую теперь нужно ещё и поддерживать. Когда кэш промахивается, старая боль всё равно остаётся.
Слишком большое количество изменений запросов одновременно создаёт другую проблему: вы перестаёте понимать, что именно сработало. Хорошая оптимизация производительности базы данных начинается с базовой точки отсчёта. Возьмите один медленный путь, измерьте его, измените один запрос или форму одной таблицы, а затем измерьте снова. Это требует терпения, но экономит недели догадок.
Поля для отчётов заслуживают той же дисциплины. Команды часто добавляют месячные итоги, сводки по статусам или столбцы для выгрузки прямо в рабочие транзакционные таблицы, потому что так быстрее. Потом каждую запись становится тяжелее, индексы растут, а обычные обновления касаются данных, которые приложению почти никогда не нужны в реальном времени. Когда это соответствует паттерну доступа, переносите долгосрочные отчётные потребности в отчётные таблицы, материализованные сводки или плановые задачи.
Дешёвая победа обычно довольно скучная: меньше записей, меньше соединений и меньше дублирующихся данных.
Быстрая проверка перед покупкой нового железа
Больше CPU и RAM могут на какое-то время скрыть проблему в схеме, но редко убирают её. Если страница читает слишком много данных, записывает один и тот же факт в нескольких местах или соединяет таблицы, которые ей не нужны, более мощный сервер просто позволит вам платить больше за ту же ошибку.
Быстрая проверка часто показывает одно недорогое исправление. Иногда оно совсем маленькое — например, убрать 20 старых отчётных столбцов из самой загруженной таблицы или изменить один запрос так, чтобы он читал 6 столбцов вместо 35. Такое изменение может быстро сократить время ответа и отложить счёт за железо на месяцы.
Используйте самый загруженный экран или путь API как тестовый случай. Не начинайте со всех запросов в системе. Начните с пути, который люди открывают весь день.
- Проверьте, читает ли этот путь только те столбцы, которые он показывает или реально использует.
- Проверьте, пишет ли одно действие пользователя одну точку истины, а не две или три копии.
- Проверьте, можно ли убрать из самого медленного запроса одно соединение на горячем пути.
- Проверьте, не лежат ли старые отчётные поля всё ещё в главной транзакционной таблице.
- Проверьте, не снизит ли одно изменение схемы нагрузку настолько, что более крупный инстанс не понадобится.
Простой пример помогает это увидеть лучше. Допустим, на странице списка заказов показываются номер заказа, имя клиента, статус, сумма и дата создания. Если запрос ещё и забирает заметки, полный текст доставки, внутренние флаги, экспортные поля и архивные отчётные столбцы, каждое чтение становится тяжелее, чем нужно. Если к тому же страница соединяет таблицу только ради подписи статуса, которая почти не меняется, вы можете делать лишнюю работу на каждом запросе.
Записи заслуживают той же проверки. Если оформление заказа сохраняет ту же сумму налога в трёх местах «на всякий случай», вы не только тратите больше на хранение. Вы ещё и пишете больше данных, держите блокировки дольше и позже создаёте больше шансов на несовпадающие цифры.
Именно здесь оптимизация производительности базы данных часто и начинается: не с миграции, а с небольшой правки модели данных. Oleg Sotnikov делал такую работу по сокращению затрат на уровне архитектуры для систем под реальной производственной нагрузкой, и этот паттерн встречается часто. Сначала приведите в порядок самый нагруженный путь. Потом уже смотрите, нужен ли вам больший сервер.
Следующие шаги для небольшого проекта по чистке
Хорошая оптимизация производительности базы данных обычно начинается с одного пути, который пользователи открывают каждый день. Выберите экран, отчёт или вызов API, который кажется медленным и встречается часто. Поток оформления заказа, результаты поиска или страница аккаунта лучше, чем редкая админская задача, потому что небольшие выигрыши там легче заметить.
Держите рамки узкими. Одного спринта достаточно для полезной чистки, если вы сосредоточитесь на одном пути запросов и таблицах вокруг него. Если команда попытается исправить все неудобные таблицы сразу, работа расползётся и никто не поймёт, что именно улучшилось.
Хорошо работает такой небольшой проект:
- выберите один медленный запрос и измерьте его текущее время
- проследите чтения и записи, которые стоят за ним
- уберите одну очевидную проблему, например широкую таблицу, ненужное соединение или дублирующую запись
- измеряйте снова после каждого изменения
Такой подход помогает оставаться честными. Если изменение экономит 80 мс на странице, которую люди открывают весь день, это важнее, чем большой рефакторинг без понятного результата.
Перед тем как кто-то снова добавит новые поля или скопирует данные, запишите несколько простых правил. Сделайте их короткими и лёгкими для соблюдения. Например, каждое новое поле должно отвечать на реальную потребность запроса, у дублирующихся данных должен быть назначенный владелец, а денормализованные поля должны появляться только тогда, когда команда может простыми словами объяснить, какую пользу они дают чтению.
Также полезно заранее решить, кто будет утверждать изменения схемы. Не нужно, чтобы один человек контролировал всё, но кто-то должен задавать базовые вопросы до того, как миграция попадёт в продакшен. Зачем здесь это поле? Кто его пишет? Кто его читает? Что сломается, если данные рассинхронизируются?
Если вашей команде нужен второй взгляд, лучше получить его до того, как вы потратите деньги на более крупные инстансы или новую базу данных. CTO на частичной занятости, например Oleg Sotnikov, может вместе посмотреть на модель, паттерны запросов и инфраструктуру. Это важно, потому что медленные системы часто возникают из-за смеси ошибок в схеме и лишних затрат на платформу, а не просто из-за нехватки железа.
Проект по чистке считается небольшим, если у него один цель, один владелец и один срок. Обычно этого достаточно, чтобы убрать лишнее, снизить нагрузку и дать команде лучшие правила для следующего изменения.