Практические ограничители затрат для федеративных стеков моделей
Ограничители затрат для федеративных стеков моделей помогают командам ограничивать расход по задачам, задавать фоллбэки и не допускать, чтобы один шумный поток опустошил бюджет.
Содержание
Почему затраты скачут без предупреждения
Резкие всплески редко происходят из‑за одного большого запроса. Обычно они происходят, когда обычный рабочий поток тихо превращается в пять или шесть вызовов моделей вместо одного.
Хороший пример — ответ службы поддержки. Система может классифицировать сообщение, вытянуть контекст из базы знаний, суммировать переписку, составить черновик ответа, запустить проверку безопасности и переписать ответ в нужном тоне. Каждый шаг по отдельности кажется дешёвым. Вместе они быстро умножают счёт.
Проблема усугубляется в федеративных стеках, где разные модели выполняют разные задачи. Одна задача может стартовать на мелкой модели, передать результат более крупной, вызвать embedding, а затем вызвать ранжировщик. Если такая цепочка срабатывает тысячи раз в день, месячные расходы растут задолго до того, как кто‑то заметит.
Малые ошибки добавляют ещё расходов. Таймаут, лимит по скорости или некорректный ответ часто запускают автоматический ретрай. Это кажется безобидным, пока повторы не складываются на нескольких шагах. Одно действие пользователя превращается в две–три полные попытки, и каждая снова вызывает те же сервисы.
Фоновая работа — ещё один частый источник утечек. Пользователь закрывает вкладку, уходит из чата или обновляет страницу, а задача всё равно продолжает выполняться. Извлечение, генерация, оценка и логирование завершаются, хотя никто никогда не прочитает результат. Команды обычно замечают это только после получения счёта.
Общие бюджеты усложняют управление. Одна загруженная фича может съесть месячную квоту, предназначенную на весь продукт. Тогда поддержка, продажи или внутренние исследования начинают страдать из‑за рабочего потока, который первым оказался шустрым.
Вот почему ограничители затрат важны. В одиночку расходы не кажутся драматичными. Они появляются как пара лишних повторов, длиннее подсказка, фоновый воркер, который не останавливается, и фича, внезапно ставшая популярной. А потом это всё сыплется разом.
Нарисуйте карту рабочих потоков прежде чем ставить лимиты
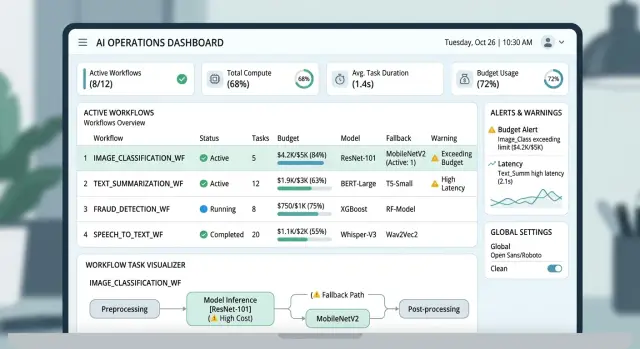
Лимиты не работают, если поставлены не на тот объект. Команда говорит: «мы много тратим на AI», но счёт обычно приходит от небольшого числа повторяющихся действий, фоновых задач или запросов с большими файлами.
Начните с простого инвентаря. Запишите каждую задачу, которая отправляет что‑то модели, даже те, что кажутся слишком мелкими, чтобы иметь значение. Ответы в чате, сводки документов, проверки на спам, тегирование, переписывания поиска, генерация тестов, ночные отчёты и циклы повторов — всё это должно быть на карте.
Затем разделите карту на две группы: задачи, которые запускает человек, и задачи, которые выполняет система сама. Действия пользователя проще объяснять и ограничивать. Запланированные работы — те, что тихо бегают весь уикенд и превращают обычный месяц в кошмар.
Частота важна так же, как и цена модели. Дешёвый вызов, который выполняется 200 000 раз, может нанести больший вред, чем дорогой, используемый пару раз в день. Отметьте потоки, которые выполняются чаще всего, и те, что могут взорваться при росте трафика.
Для каждой задачи зафиксируйте четыре вещи: что её запускает, как часто она срабатывает, какую модель она вызывает и какого размера обычно вход.
Последний пункт — то, что команды часто упускают. Длинные подсказки, полная история чата, PDF, скриншоты, аудиофайлы и большие диффы кода быстро увеличивают токены и время обработки. Бот поддержки, который прикрепляет последние 30 сообщений к каждому ответу, может стоить гораздо дороже, чем команда ожидает.
Дорогостоящая часть часто не та, которую люди предполагают. Команда может сосредоточиться на живом чатботе, тогда как реальный слив — фоновая задача, которая суммирует каждый тикет, выполняется снова после каждого обновления и сканирует вложения. Эта задача может запускаться в десять раз чаще, чем поток чата.
Не полагайтесь только на средние значения. Отметьте рабочие потоки с риском всплеска: импорты, пакетные повторы и задачи, инициируемые загрузкой файлов. Именно там обычно первые выигрыши дают лимиты для шумных потоков.
Когда карта готова, вы должны уметь показать несколько задач, которые формируют большую часть расходов. Это даст вам конкретное место для ограничения вместо расплывчатого обещания тратить меньше.
Решите, сколько стоит каждая задача
У каждого рабочего потока должна быть ценовая метка до выхода в продакшн. Если пропустить этот шаг, самый громкий поток обычно получает больше денег, даже если приносит меньше ценности бизнесу.
Начните с простого вопроса: сколько стоит для бизнеса один успешный запуск? Черновик ответа для рутинного тикета поддержки может стоить пару центов. Вызов модели, который проверяет пункт контракта, отмечает мошенничество или помогает закрыть продажу, может оправдывать более высокий лимит, потому что цена ошибки выше.
Дешёвые повторяющиеся задачи требуют жёсткого потолка. Эти работы выполняются весь день и быстро накапливаются: тегирование тикетов, суммирование коротких заметок, очистка текста, маршрутизация сообщений и простые переписывания поиска. Если один запуск превышает лимит, остановите его, переключитесь на меньшую модель или пропустите необязательный шаг.
Задачи с большей ценностью заслуживают больше свободы, но не безлимитного доступа. Дайте дополнительный бюджет рабочим потокам, привязанным к доходу, юридическим рискам, безопасности или удержанию клиентов. Это не значит, что нужно каждый раз использовать самую большую модель. Это значит установить более высокий предел, потому что потенциал выгоды или ущерба реален.
На практике бюджеты по задачам обычно делят на четыре группы. Низкоценные, массовые задачи получают очень низкий лимит за запуск и строгий откат. Среднеценные задачи — умеренный лимит и не более одного повтора. Задачи, критичные для дохода или риска, получают более высокий лимит и доступ к лучшим моделям при необходимости. Экспериментальные потоки — песочницу с отдельным бюджетом, который не может вытекать в продакшн‑расходы.
Устанавливайте два лимита для каждого потока, не один. Суточный лимит ловит резкий всплеск, например баг в цикле или ошибочный релиз подсказки. Месячный лимит останавливает медленное ползучее перерасходование.
Математика должна оставаться простой. Если поток может выполняться 30 000 раз в день, и вы разрешили $0.02 за запуск, вы уже согласовали до $600 в день. Контроль затрат LLM становится проще, когда у каждой задачи есть такой понятный предел, записанный до прихода трафика.
Задайте пути понижения модели до роста затрат
Путь понижения указывает системе, что делать, когда качество падает или расходы растут. Без него команды часто начинают с мощной модели и оставляют её включённой. Это работает неделю. Потом один шумный поток начинает пожирать бюджет.
Начните с самой дешёвой модели, которая может выполнить задачу достаточно хорошо. Для многих задач это означает, что классификация, маршрутизация, короткие сводки или простые переписывания по умолчанию идут на небольшой модели. Более крупные модели оставляйте для работы, где нужны длинные рассуждения, сложный парсинг или аккуратная стилистика.
Переход на более дорогую модель должен иметь чёткий триггер. Сделайте его измеримым. Эскалируйте только когда первый результат провалил реальную проверку: отсутствуют обязательные поля, уверенность ниже порога, сломан формат вывода или валидатор поймал фактические или политические ошибки.
Это правило важнее списка моделей. Если проверка расплывчата, система будет эскалировать слишком часто, и ваш лимит потеряет смысл.
Пороговые значения расходов должны также толкать задачу в обратную сторону. Если поток достигает 70–80% своего суточного бюджета, последующие запросы должны переходить на меньшую модель, использовать более короткое окно контекста или пропускать необязательные шаги, например вторую стадию переписывания. Результат может быть грубее, но пользователь всё ещё получит ответ, и одна функция не опустошит месяц.
Иногда ни одна модель не вписывается в лимит. Остановите задачу и верните простой статус вроде «требуется ручная проверка» или «достигнут лимит бюджета на автоматическую обработку». Это лучше, чем позволять повторным попыткам и эскалациям бежать, пока счёт не удивит вас.
Простые пути понижения обычно работают лучше: сначала маленькая модель, большая модель только после провала проверки, снова маленькая модель при достижении порога расходов, затем жёсткая остановка, когда безопасной опции не остаётся.
Настройка по шагам
Большинство команд усложняют это с самого начала. На первом этапе не нужен гигантский движок политик. Пара ясных правил вокруг выбора модели, лимитов повторов и условий остановки уже даст большой эффект.
Сначала сортируйте задачи по размеру входа до отправки. Короткие подсказки вроде тегирования, маршрутизации или базовых сводок должны идти на самую маленькую модель, которая проходит ваш порог качества. Запрос из 30 слов вряд ли нуждается в той же модели, что и экспертная проверка контракта.
Проверьте, действительно ли нужен большой контекст. Большие окна контекста дороже, поэтому резервируйте их для задач вроде сравнения нескольких документов или ответов по полной базе знаний. Если задаче нужен лишь один абзац или небольшой фрагмент, сначала обрежьте вход и оставьте её на дешёвой модели.
Затем жёстко ограничьте повторы. Две–три попытки обычно достаточно. Если модель всё ещё не справляется, остановите выполнение, пометьте для проверки и двигайтесь дальше. Бесконечные петли повторов — один из быстрейших способов сжечь бюджет без улучшения результата.
Установите лимиты по токенам и времени для каждого типа задачи. Если поток пересёк любой из этих лимитов, обрывайте его. Не позволяйте одному плохому входу пожрать полдня и кучу токенов. Если извлечение из документа длится дольше 45 секунд или превышает установленный потолок токенов, завершите его и пометьте файл.
Наконец, фиксируйте, почему каждый запрос пошёл туда, куда пошёл. Логируйте имя задачи, использованную модель, размер подсказки, число повторов и правило, которое выбрало эту модель. Когда расходы подпрыгнут, вы увидите, пришло ли это из‑за увеличенных входов, сломанного роутера или того, что поток начал вызывать неправильную модель.
Для этого не нужны навороченные инструменты. Если вы интегрируете эти правила в существующий стек, практическая внешняя проверка может помочь. Oleg Sotnikov на oleg.is работает с командами по маршрутизации AI, инфраструктуре и контролю затрат, и такая настройка обычно важнее ещё одного раунда prompt‑тинга.
Простой пример из команды поддержки
Ящик входящих тикетов — хорошее место, чтобы увидеть эти ограничители в деле. Тикеты приходят весь день, формулировки бывают небрежными, и одно плохое правило маршрутизации может отправить каждое сообщение на самую дорогую модель.
Представьте команду, которая получает 1 500 тикетов в день. Большинство рутинные: сброс пароля, вопросы по оплате, обновления доставки, дубликаты запросов и просто спам. Дешёвый классификатор делает первый проход и присваивает тикету метку, оценку уверенности и примерный уровень срочности.
Первый шаг не нуждается в топовой модели. Надо ответить на два простых вопроса: о чём это, и нужно ли человеку видеть это прямо сейчас? Если модель уверена, тикет остаётся на низкозатратном пути.
Вверх поднимаются только запутанные случаи. Более сильная модель подключается, когда формулировка неясна, клиент злится или тикет упоминает деньги, простои или доступ к аккаунту.
Шаг составления ответа — где команды часто сливают деньги. Если система составляет черновик на каждый тикет, расходы растут быстро, и агенты всё равно выбрасывают многие черновики. Более строгие правила работают лучше: составлять черновик только когда модель очень уверена и запрос распространён.
Тикет по оплате «Мне нужен последний счёт ещё раз» обычно безопасен для автогенерации. Тикет «Вы списали с нас два раза и заблокировали аккаунт» должен пропустить черновик и попасть сразу к человеку с короткой сводкой.
Суточные лимиты особенно важны при пакетной переработке. Допустим, команда поменяла категории и хочет заново обработать 40 000 старых тикетов ночью. Без лимита этот пакет сожрёт недельный бюджет до того, как кто‑то заметит. С лимитом система приостанавливает пакет после достижения порога и возобновляет его в следующем цикле.
Одно правило сохраняет нагрузочный, но низкоприоритетный поток от опустошения месяца. Поддержка работает дальше, срочные случаи получают внимание, а бюджет идёт на тикеты, которые требуют лучшего рассуждения.
Ошибки, которые сжигают бюджет
Большинство команд не теряют деньги из‑за одной большой ошибки. Они теряют их из‑за маленьких настроек по умолчанию, которые никто не ставит под сомнение, пока не приходит счёт.
Самая распространённая — отправлять каждый запрос на самую дорогую модель. Сначала это кажется безопасным. На деле это расточительно. Короткая классификация, проверка тональности или базовая сводка обычно не нуждаются в вашей лучшей модели. Если поток обрабатывает 50 000 мелких задач в день, этот дефолт сам по себе может превратить скромный счёт в болезненный.
Повторы — следующая утечка. Вызов модели падает, таймаут или некорректный формат — система пытается снова. Потом ещё раз с той же подсказкой, тем же большим контекстом и той же дорогой моделью. Без жёсткого лимита один сломанный поток может прожечь месячный бюджет за несколько часов. Двух повторов может быть достаточно. Десяти — нет.
Размер контекста — ещё тихий убийца бюджета. Команды часто отправляют всю историю чата, полные документы или целые JSON‑блоки, когда задаче нужны два поля. Если модели нужен только заголовок тикета и имя продукта, не шлите последние 40 сообщений. Длинный контекст стоит денег при каждом вызове, даже если ничего не добавляет.
Ещё несколько паттернов требуют внимания. Ночные пакетные задания часто выполняются вне поля зрения и обрабатывают намного больше данных, чем дневной трафик. Общие очереди могут смешивать дешёвые и дорогие задачи, что скрывает реальный источник расходов. Одна строка биллинга за всё использование моделей затрудняет понимание, какой поток тратит деньги. Автоматические фоллбэки тоже могут навредить, если они переключаются на более крупную модель вместо более дешёвой.
Ошибка в отчётности проще, чем команды думают. Если финансы видят одну общую строку AI‑расходов, никто не скажет, возник ли всплеск из‑за триажа поддержки, парсинга документов или неудачного эксперимента. Хороший контроль затрат начинается с разделения расходов по задачам, очередям и моделям.
Сделайте расточительство видимым. Когда у каждого потока будет свой бюджет, лимиты и путь отката, шумные потоки перестанут высасывать остальные.
Быстрая проверка перед релизом
Перед запуском протестируйте реальные подсказки на самой дешёвой модели, которую планируете использовать. Примеры подсказок часто выглядят аккуратно. Производственные подсказки — нет. Они длиннее, неряшливее и полны скопированного текста, ошибок OCR и пользователей, которые просят сразу пять вещей.
Этот тест быстро покажет два момента: подходит ли дешёвая модель в большинстве случаев и где она начинает ошибаться. Если она обрабатывает восемь‑девять из десяти реальных кейсов, оставляйте её в первой ступени. Экономную модель держите для подсказок, которые действительно этого требуют.
Обработка ошибок нуждается в таком же жёстком лимите. После трёх неудачных попыток поток должен остановиться, залогировать случай и передать дело или ждать проверки. Если дать задаче продолжать повторы по моделям, один плохой вход превратится в кучу повторных вызовов за минуты.
У каждого потока также должен быть твёрдый денежный лимит, а не просто предупреждение. Предупреждение скажет, что что‑то пошло не так, когда деньги уже потрачены. Лимит останавливает задачу, пока ущерб ещё невелик.
Логи обычно показывают отходы быстрее, чем дашборды. Перед релизом ищите два паттерна: очень большие подсказки и один и тот же вызов, срабатывающий несколько раз. Большие подсказки обычно происходят из‑за плохой обрезки. Повторные вызовы часто связаны с повторами, состоянием гонки или фронтендом, который отправляет одинаковый запрос дважды.
Владение тоже важно. Оповещения нужны с одним понятным владельцем, не командным алиасом и не каналом, который все отключают. Один человек должен получать оповещение, знать правила бюджета и иметь полномочия приостановить поток.
Правила остановки должны быть так же чётки, как и правила маршрутизации. Если лимит, владелец оповещений или лимит повторов расплывчаты, исправьте это до релиза.
Что делать дальше
Начните с рабочего потока, который тратит деньги всплесками. Для многих команд это триаж поддержки, сводки документов или агент, который повторяет одну и ту же работу три–четыре раза. Поставьте твёрдый лимит на этот единичный поток на этой неделе. Даже грубый лимит даёт реальную границу, и это лучше, чем смотреть, как счёт медленно уходит вверх.
Добавьте один фоллбэк прежде чем править подсказки. Многие команды делают это в неправильном порядке: они режут токены, переписывают инструкции и тестируют мелкие формулировки, в то время как дорогой путь продолжает срабатывать в фоне. Если задача пересекает свой бюджет, отправьте её на более дешевую модель, сократите контекст или пропустите дополнительный шаг рассуждения.
Простая еженедельная рутина помогает: проверяйте расходы по задачам, найдите поток с наибольшими суммарными расходами, найдите тот, у которого больше всего повторов, назначьте бюджет, соответствующий реальной ценности задачи, и протестируйте один фоллбэк, чтобы убедиться, что результат всё ещё достаточен.
Это важнее, чем кажется. Ответ поддержки стоимостью пару центов не должен запускать премиальную цепочку с длинным контекстом, инструментами и второй проверкой. То же правило относится и к внутренним задачам. Если тегирование даёт такой же результат на дешёвой модели, оставляйте дорогие варианты для того, что действительно в них нуждается.
Вам не нужен гигантский редизайн, чтобы вернуть контроль. Один лимит, один фоллбэк и одна еженедельная проверка могут быстро сократить отходы. Потом паттерны станет легче увидеть.
Если хотите внешнюю проверку, Oleg Sotnikov на oleg.is консультирует стартапы и небольшие команды по маршрутизации AI, инфраструктуре и операционным издержкам. Короткой проверки часто достаточно, чтобы поймать скрытые повторы, слабые правила маршрутизации и пути отката, которые на бумаге выглядят нормально, но ломаются в продакшне.
Часто задаваемые вопросы
Why do AI costs jump without warning?
Затраты обычно растут, когда одно действие пользователя превращается в несколько вызовов моделей, повторов и фоновых заданий. Отдельный дешёвый шаг остаётся дешёвым, но классификация, извлечение, составление черновика, проверки безопасности и переписывание быстро складываются друг с другом.
What should I map before I set cost limits?
Запишите все рабочие потоки, которые вызывают модель, даже мелкие: тегирование, маршрутизация, сводки и циклы повторов. Для каждой задачи укажите, что её запускает, как часто она выполняется, какую модель использует и какого обычно размера вход.
How do I set a budget for each task?
Прикрепите простую денежную оценку к одному успешному выполнению до запуска. Рутинные, массовые задачи нуждаются в очень низком лимите, тогда как проверки, связанные с доходом, юридическим риском, безопасностью или мошенничеством, могут оправдать более высокий предел.
When should a workflow move to a bigger model?
Переходите на более дорогую модель только когда дешёвая не прошла реальную проверку. Хорошие триггеры — низкая уверенность, пропущенные поля, сломанный формат или валидатор, который ловит плохой результат.
What should happen when a workflow hits its budget?
Не позволяйте процессу тратить дальше, пока счёт не напомнит об этом. Переведите последующие запросы на меньшую модель, сократите контекст, пропустите необязательные шаги или остановите задачу и отправьте на ручную проверку.
How many retries should I allow?
Ограничьте количество повторов. Двух–трёх попыток обычно достаточно; после этого остановите выполнение, зафиксируйте и передайте на проверку вместо бесконечных повторов.
How do I reduce context costs without hurting results?
Обрежьте вход до того, что действительно нужно задаче. Если модели нужен только заголовок тикета и имя продукта, не отправляйте полную переписку, документ или огромный JSON‑блок.
What should I log to catch waste early?
Логируйте имя задачи, модель, размер подсказки, число повторов и правило, которое выбрало этот путь. Эти поля покажут, выросли ли расходы из‑за больших входов, накопления повторов или неверной маршрутизации.
What mistakes drain the budget most often?
Часто деньги тратят отправкой всех запросов на самую дорогую модель, прикреплением лишнего контекста и разрешением бесконечных повторов. Ночные пакетные задания и общие очереди тоже маскируют источники расходов, пока счёт не придёт.
What is the first step I should take this week?
Выберите один шумный рабочий поток и задайте для него твёрдый лимит и один путь отката на этой неделе. Триаж в поддержке, сводки документов и агенты с множественными повторами обычно дают быстрый выигрыш.


