Ограничения по скорости для каждого клиента — чтобы одна учётная запись не мешала всем
Ограничения по каждому клиенту не дают тяжёлым аккаунтам поглощать общую ёмкость. Узнайте простые ограждения, правила всплесков и проверки, которые защищают всех пользователей.
Содержание
Почему одна занятая учётная запись вредит всем
Большинство общих систем ломаются не в одном драматичном событии. Они переполняются.
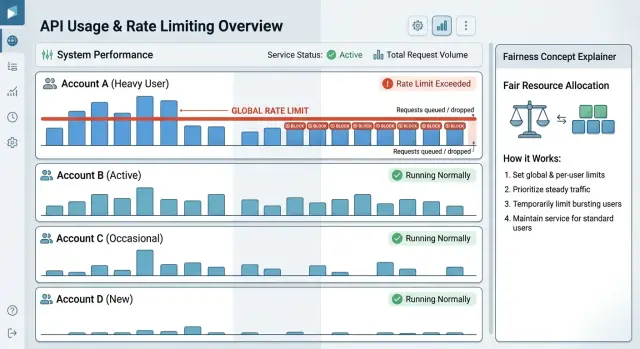
CPU, соединения с базой данных, слоты воркеров, память кэша и квоты на исходящие API — всё это имеет пределы, даже если приложение кажется быстрым большую часть дня. Одна активная учётная запись может за считанные минуты занять большую долю этой ёмкости. Это часто происходит при массовом импорте, шторме повторных попыток, ошибочном скрипте или плановой синхронизации, которая внезапно отправляет гораздо больше запросов, чем обычно. Клиент может ничего не делать неправильно, но его трафик всё равно заполняет очереди и ставит всех остальных в конец.
Как только очереди начинают расти, замедление распространяется. Запросы ждут дольше. Повторные попытки создают ещё больше трафика. Фоновые задания держат ресурсы дольше, чем ожидалось. Давление начинается в одном месте, а затем его чувствует вся система.
Мелкие клиенты обычно замечают это первыми. Они не отправляют достаточно трафика, чтобы перегрузить очередь, поэтому их обычные запросы застревают за чьим‑то потоком. Страница, которая загружалась за секунду, теперь подвисает. Вебхук приходит с опозданием. API‑запрос тайм‑аутится. С их стороны это выглядит случайно и несправедливо, потому что они ничего не меняли.
Службы поддержки видят самую запутанную версию проблемы. Они получают разбросанные жалобы, а не один чистый инцидент. Один клиент сообщает о медленных входах, другой — что экспорты застряли, третий — видит ошибки только в определённые часы. Если смотреть только на общую нагрузку системы, можно пропустить реальную причину, потому что средние значения скрывают, какой аккаунт создал всплеск.
Именно поэтому в многотенантных продуктах важны лимиты на каждого клиента. Они защищают справедливость, устанавливая чёткие ограждения по тому, сколько ресурсов может потреблять один аккаунт одновременно. Это не блокирует здоровый рост. Это останавливает один аккаунт, даже платящий и добросовестный, от того, чтобы он «высасывал» ресурсы у меньших клиентов и превращал единичный всплеск трафика в кучу тикетов в поддержку.
Что ограничивать в первую очередь
Если пытаться ограничить всё сразу, скорее всего вы поставите пределы не там, где нужно. Начните с действий, которые потребляют больше всего CPU, времени в базе данных, слотов воркеров или места на диске. Простой запрос на чтение часто недорог. Массовые импорты, загрузки файлов, генерация отчётов и большие фоновые задачи обычно — нет.
Лимиты по аккаунту работают лучше, когда они отражают стоимость, а не только количество вызовов эндпоинтов. Один аккаунт может сделать 5 000 мелких чтений и почти не нагрузить систему. Другой может запустить 200 экспортов и занять воркеры на минуты. Если оба находятся под одним и тем же лимитом, тяжёлый аккаунт всё равно победит, а меньшие клиенты всё ещё будут ждать.
Простая настройка — отслеживать несколько отдельных счётчиков:
- входящие запросы
- фоновые задания
- загрузки файлов
- запуски отчётов или экспортов
Это даёт гораздо яснее понимание, откуда приходит давление. Это также упрощает работу поддержки. Когда клиент говорит: "мы отправили всего несколько запросов", вы можете проверить, не пришёл ли реальный объём от загрузок или долгих задач.
Записи (writes) требуют более жёстких ограждений, чем чтения. Чтения часто завершаются быстро и могут обслуживаться из кэша. Записи делают больше работы: обновляют базу, запускают проверки, влияют на индексы и часто порождают другие фоновые задачи. Короткий всплеск записей может замедлить весь сервис, даже если общий трафик выглядит нормально.
Не останавливайтесь на общем объёме. Параллелизм важен не меньше, а часто и больше. Десять долгих задач отчёта одновременно могут навредить сильнее, чем тысяча мелких запросов в течение часа. Устанавливайте лимиты по аккаунту на выполняющиеся задачи, параллельные загрузки и активные запуски отчётов. Это остановит один аккаунт от заполнения всех слотов воркеров.
Простое правило работает хорошо: отделяйте дешёвые чтения, строже следите за записями и ограничивайте тяжёлую работу по параллелизму. Аккаунту можно дать щедрый бюджет на чтения, меньший — на записи, и лишь несколько одновременных экспортов. Этого обычно достаточно, чтобы защитить многотенантную справедливость, не сдавливая нормальную работу.
Как установить справедливый дефолт на аккаунт
Начинайте с реального трафика, а не с догадок. Возьмите пару недель запросов по аккаунтам и посмотрите три показателя: обычное почасовое использование, нагрузку в пиковый час и самый большой краткосрочный всплеск, который не вызвал проблем. Эти числа дадут здравый минимум для лимитов на клиента.
Только средние значения вас введут в заблуждение. Один аккаунт может быть тихим весь день, но каждое утро запускать десятиминутный тяжёлый батч. Другой может держаться ровно в течение часов. Если вы выставите один простой лимит по среднесуточным значениям, оба получат неправильное правило.
Группируйте аккаунты перед выбором дефолта. Большинство команд делает это по тарифу, контракту или ожидаемой нагрузке. На практике это обычно означает один общий дефолт для мелких аккаунтов, более высокий потолок для крупных платящих клиентов и отдельный согласованный лимит для специальных контрактов. Это сохраняет справедливость без превращения политики в персональные сделки для каждого клиента.
Держите номер достаточно высоким для обычных пиков. Хороший дефолт переживёт обычную суету: cron‑задачи, рабочие часы, повторные вебхуки и импорты. Если клиент попадает в лимит каждую неделю при обычном использовании, лимит слишком низок, и за это расплатится поддержка.
В то же время оставляйте твёрдый стоп, который защищает всех остальных. Общие системы работают лучше, когда у каждого аккаунта есть место для роста, но ни один аккаунт не может занять весь пул ресурсов.
Правило должно укладываться в одно предложение. Например: "Каждый аккаунт может отправлять до 120 запросов в минуту, с короткими всплесками до 300." Если вашей команде нужен длинный график, чтобы объяснить, кто и что получает, дефолт слишком запутан.
Небольшой пример помогает. Допустим, большинство стартовых аккаунтов держатся ниже 40 запросов в минуту, а их обычные пики доходят до 90. Установка дефолта на 120 даёт им запас, не выдавая при этом значительно больше возможностей, чем нужно. Крупные аккаунты могут перейти на другой уровень, когда их стабильный трафик покажет, что им нужно больше.
Такой подход намеренно скучен. Скучные лимиты легче объяснить, проще мониторить и они реже становятся неожиданностью для клиентов.
Как должны работать правила всплесков
Правила всплесков должны поглощать короткие пики трафика, а не оправдывать длительную перегрузку. Реальный трафик клиентов неравномерен. Плановый импорт, батч‑синхронизация или шторм повторов могут отправить много запросов за несколько секунд.
Поэтому лимит должен состоять из двух частей: небольшой «бэджа» для всплеска и постоянной скорости восстановления. Бэдж позволяет аккаунту превысить обычный темп на короткое время. Скорость восстановления определяет, как быстро аккаунт снова зарабатывает способность отправлять запросы.
Простой пример показывает компромисс. Если аккаунту дают 20 запросов в секунду и бэдж в 100, он справится с кратким всплеском, а затем вернётся к норме. Если бэдж сделать 2 000, лимитер реагирует слишком поздно, и общие воркеры всё равно окажутся перегружены.
Для большинства команд несколько правил держат поведение всплесков в норме. Держите бэдж близким к тому, что воркеры могут проглотить за несколько секунд. Заполняйте ёмкость равномерно, секунда за секундой. Добавьте короткий холодный период после опустошения бэджа. Поставьте твёрдые пределы на очереди, пулы воркеров и доступ к базе данных.
Эта пауза важнее, чем многие ожидают. Некоторые крупные клиенты будут взрываться, паузить, затем снова взрываться в цикле. Без окна восстановления они могут сохранять давление на систему минутами и ухудшать задержки для всех остальных.
Короткого штрафного окна обычно достаточно. Можно замедлить восстановление на 30 секунд после полного расходования бэджа или блокировать новые тяжёлые задания от этого аккаунта, пока очередь не уменьшится. Это может показаться строгим, но гораздо лучше, чем позволять каждому арендатору доводить систему до тайм‑аутов.
Твёрдые потолки защищают те части стека, которые падают первыми. Если общие воркеры заполнены, глубина очереди превысила безопасный порог или пул базы почти исчерпан, прекращайте принимать работу от этого аккаунта. Отдавайте ответ о лимите сразу.
Это особенно важно при экономном управлении инфраструктурой. Хорошие per customer лимиты позволяют клиенту пережить короткий всплеск, не позволяя одному аккаунту потянуть вниз весь сервис.
Простой план развёртывания
Начинайте с реального трафика, а не с догадок. Если вы выставите лимиты слишком рано, либо будете блокировать нормальную работу, либо оставите достаточно места, чтобы один большой аккаунт загнал всех остальных в медленные ответы.
Двух недель — хорошая минимальная выборка. Посмотрите запросы в минуту, кратковременные пики, время суток и какие аккаунты создают наибольшую нагрузку. Разделите устойчивый трафик и внезапные всплески — для них нужны разные правила.
Начните с групп аккаунтов
Большинство команд лучше справляется с несколькими группами аккаунтов, чем с индивидуальными лимитами для каждого клиента. Можно взять один дефолт для мелких аккаунтов, один для растущих и один для крупных контрактов с известными паттернами трафика.
Дайте каждой группе нормальный лимит запросов и предел для всплесков. Нормальный лимит защищает общую ёмкость. Лимит для всплесков даёт клиентам пространство для коротких пиков, не позволяя одному аккаунту долго сидеть на пределе.
Первую версию держите простой. Щедрые правила для всплесков и понятные per customer лимиты легче объяснить и безопаснее поддерживать, чем хитрая логика с множеством исключений.
До выхода в прод проигрывайте в staging трафик, похожий на реальную нагрузку. Затем добавьте одного шумного клиента и дайте ему сильный всплеск. Если мелкие тестовые аккаунты по‑прежнему получают приемлемую задержку, вы близки к цели. Если время в очереди растёт или увеличивается количество ошибок, снизьте бэдж или сократите окно всплеска.
Обычно аккуратный запуск следует такому сценарию:
- включить лимиты для небольшой группы клиентов сначала
- выбрать аккаунты с разными паттернами использования
- просматривать заблокированные запросы ежедневно
- смотреть время в очереди, ошибки и тикеты поддержки вместе
- расширять развёртывание только после стабилизации метрик
Не ждите жалоб. Смотрите дашборд каждый день в первую неделю. Небольшой рост ошибок 429 может быть допустим, если задержки для всех остальных улучшаются, но всплеск тикетов в поддержку значит, что лимиты не соответствуют реальному использованию.
Если один пилотный клиент постоянно попадает под кап, не спешите с глобальным повышением. Проверьте, нуждается ли он в более высоком тарифе, отдельной очереди или улучшенном поведении повторных попыток. Это сохраняет многотенантную справедливость и не превращает одно исключение в новый дефолт.
Пример: у крупного клиента всплеск
В 9:05 в понедельник крупный клиент начинает импортировать накопившийся за выходные объём. Его обычный трафик ровный, затем за несколько минут он вырастает примерно в 10 раз. Импорт легитимен: это не злоупотребление и не баг. Но если все аккаунты делят одни и те же ресурсы без лимитов, это достаточно, чтобы создать проблемы.
Без per customer лимитов импорт может заполнить очереди воркеров, занять большинство соединений с базой и повысить времена отклика для всех остальных. Мелкие клиенты почувствуют это первыми. Страницы будут медленными. Отчёты дольше формироваться. Простой поиск начнёт тайм‑аутиться, потому что один аккаунт использует почти всю систему.
С ограждениями аккаунта та же самая ситуация выглядит иначе. Импорт крупного клиента всё ещё выполняется, но система дозирует его. Вместо того чтобы дать аккаунту захватить все воркеры, система выделяет лишь его долю. Импорт займёт больше времени, но он будет двигаться вперёд. Остальные клиенты смогут загружать дашборды, запускать отчёты и выполнять обычные API‑вызовы.
Правила для всплесков смягчают ощущение жёсткости. Если клиент обычно шлёт 100 запросов в минуту, можно разрешить краткий всплеск до 200 на минуту‑две, а затем вернуть аккаунт к стабильному капу. Это помогает при коротких пиках — например, когда пользователь быстро перелистывает страницы или запускается небольшой батч. Но это не даёт клиенту бесконтрольного способа прогнать двухчасовой импорт backlog.
Представьте последовательность простыми словами. Клиент запускает импорт, трафик растёт и держится высоким, аккаунт достигает лимита и получает «пейсинг», а все остальные продолжают пользоваться продуктом в нормальном режиме.
В этом и есть суть справедливых лимитов. Вы не блокируете платящего клиента за активность. Вы делаете так, чтобы один аккаунт не превращал загруженное утро в инцидент для всей базы клиентов.
Ошибки, которые создают боль для поддержки
Служба поддержки первой почувствует ошибки лимитирования. Входящие переполнит: "почему мой синк остановился?" и "почему только некоторые запросы падают?" Большая часть боли приходит от правил, которые звучат просто, но ломаются в реальном трафике.
Первое подводное камни — один общий потолок для всех клиентов. Маленькая команда, отправляющая 50 запросов в минуту, и большой аккаунт, запускающий импорты весь день, не создают одинаковую нагрузку. Если у них один и тот же предел, маленький клиент редко его заметит, а большой — будет попадать в него постоянно. Поднимите этот потолок для всех — и самый шумный аккаунт снова начнёт поглощать общие ресурсы.
Неограниченные всплески для самых платящих клиентов создают другой хаос. Большие контракты не отменяют физику. Если одному аккаунту позволено сидеть далеко выше обычного уровня, другие арендаторы платят замедлением и случайными 429. Поддержке придётся объяснять, почему чужой трафик повлиял на них.
Фоновые задания — ещё одна распространённая слепая зона. Клиент может щёлкать в приложении, пока плановые экспорты, повторные вебхуки и батч‑синхроны продолжают генерировать работу под тем же аккаунтом. Если вы ограничиваете только фронтенд‑вызовы, аккаунт всё ещё может заливать систему через ранее запущенную работу. Считайте весь трафик, инициированный от одного аккаунта, или давайте каждому типу трафика отдельный бюджет с общим лимитом.
Скрытые лимиты делают любую проблему хуже. Клиенты гораздо меньше злятся, когда видят кап, оставшийся бюджет и время до сброса. Они гораздо сильнее раздражаются, когда первый признак лимита — неудавшийся импорт в середине рабочего дня.
Команды также создают боль поддержки, меняя правила прежде, чем изучат реальный трафик. Новый порог может выглядеть нормально на совещании и при этом блокировать ежедневную синхронизацию клиента в 9:05. Сначала проверьте реальные паттерны запросов, особенно повторные попытки и плановые задания.
Жалобы обычно предсказуемы: "Наш импорт работал вчера и падает сегодня." "Только некоторые запросы возвращают 429." "Дашборд работает, но наша ночная задача умирает." "Мы не знали про лимит всплесков."
Хорошие per customer лимиты кажутся скучными. Клиенты знают правила, всплески ограничены, и один аккаунт не превращает всех остальных в проблему поддержки.
Быстрые проверки перед запуском
Per customer лимиты должны казаться скучными в обычный день. Если клиенты попадают в лимит при рутинном трафике, кап неверен или ваша база слишком близко к краю.
Начните с реальных чисел. Простой тест: сравните обычный пик каждого аккаунта с предлагаемым твёрдым капом. Если клиент обычно пикает на 20 запросах в секунду, а кап — 25, ожидайте жалоб. Если кап 80–100, у обычного трафика запас и поддержка молчит.
Короткие всплески требуют отдельной проверки. Пик должен закончиться быстро, а очередь — опустеть, а не расти минуты подряд. Если аккаунт отправил 10‑секундный всплеск, посмотрите, что было после него. Бэклог должен быстро сокращаться. Если он продолжает расти, ваши правила всплесков слишком свободны или воркеры легко монополизируются.
Один шумный клиент тоже не должен сразу захватить все воркеры. Тут многотенантная справедливость перестаёт быть теорией и становится реальной проверкой перед запуском. Запустите тест: один аккаунт заливает систему, в то время как несколько мелких держат обычный трафик. Маленькие аккаунты должны по‑прежнему получать стабильные ответы, даже если большой аккаунт начинает получать 429.
Перед запуском подтвердите базовые вещи:
- обычный трафик аккаунтов значительно ниже капа
- короткий всплеск заканчивается без долгой очереди после
- один аккаунт не может занять весь параллелизм
- ошибки объясняют лимит и следующие шаги
- у поддержки есть понятная процедура для поднятия лимита
Сообщение об ошибке важнее, чем думают команды. «Rate limit exceeded» недостаточно. Объясните клиенту, что произошло, стоит ли повторять попытку и когда. Если вы отдаёте 429, укажите текущий лимит, окно для повторной попытки и простую формулировку вроде: "снизьте скорость запросов или свяжитесь с поддержкой для рассмотрения повышения".
Дайте поддержке короткий план действий перед развёртыванием. Они должны повышать лимит, когда у клиента стабильный паттерн, он платит за большую ёмкость и не мешает другим. Они должны отказывать, когда клиент создаёт избыточные всплески, игнорирует поведение retry или просит неограниченный доступ. Одна страница с такими правилами экономит много тикетов.
Следующие шаги для вашей команды
Обращайтесь с лимитами как с продуктовым правилом, а не просто как с операционной настройкой. Клиентам нужен понятный язык, и вашей команде — тот же самый внутри фирмы. Если кто‑то попал под лимит в 2:00 ночи, служба поддержки должна знать, что произошло, что может сделать клиент и когда лимит сбросится.
Напишите короткую политику, отвечающую на основные вопросы без жаргона. Скажите, что считается в лимит, как долго действует окно, как работают правила всплесков, что видит клиент при достижении капа и кто может одобрить исключение. Используйте одинаковую формулировку в документации для клиентов, заметках поддержки и в он‑колл ранбуках, чтобы никто не импровизировал в критической ситуации.
Этот небольшой шаг сильно снижает нагрузку на поддержку. Он также делает per customer лимиты предсказуемыми, а не случайными.
После запуска дайте правилам месяц перед изменениями, если только не случится серьёзный инцидент. Одна шумная неделя может ввести в заблуждение. Полный месяц даёт рабочие дни, выходные, биллинговые циклы и хотя бы несколько реальных всплесков.
При пересмотре метрик смотрите на паттерны, а не на отдельные истории. Проверьте, какие аккаунты часто достигают капа, видел ли маленький трафик замедления во время всплесков и приходили ли тикеты от роста бизнеса или от плохого поведения клиента. Если один аккаунт ежедневно сидит рядом с лимитом, это может оправдать более высокий план или другую настройку всплесков.
Не повышайте лимиты только потому, что самый громкий клиент жалуется первым. Повышайте их, когда данные показывают устойчивое легитимное использование и остальная система остаётся здоровой. Если данные не подтверждают изменение, держите ограждение.
Некоторым командам полезен внешний аудит. Oleg Sotnikov на oleg.is работает как Fractional CTO и консультант для стартапов — он помогает решать вопросы трафика, ёмкости и ограждений аккаунтов. Внешний взгляд на лимиты, поведение повторных попыток и очереди может выявить слабые места до того, как клиенты их почувствуют.
Часто задаваемые вопросы
Что такое per customer rate limit?
Он задаёт чёткий предел того, сколько одна учётная запись может использовать в общем сервисе за короткий период. Такой предел не даёт одному импорту, синхронизации или шторму повторных попыток замедлять входы в систему, отчёты и API для всех остальных.
Почему один глобальный лимит недостаточен?
Один общий предел не показывает, кто именно создал всплеск. Одна занятая учётная запись может заполнить воркеры и соединения с БД, в то время как общий трафик выглядит нормально, и мелкие клиенты оказываются в очереди за чужим трафиком.
С чего начать ограничивать?
Начинайте с действий, которые съедают больше всего ресурсов. Массовые импорты, загрузки файлов, экспорты и фоновые задания обычно вредят больше, чем обычные чтения, поэтому сначала ограничьте их.
Должны ли чтения и записи иметь одинаковый лимит?
Нет. Чтения обычно завершаются быстрее и часто идут из кэша, а записи трогают базу данных, индексы и запускают последующие задачи. Для чтений можно дать больше свободы, для записей — более жёсткие рамки.
Почему так важно учитывать параллелизм?
Количество запросов — это только часть истории. Одна учётная запись может запустить несколько долгих задач и заблокировать все воркеры, поэтому нужны ограничения на выполняющиеся задачи, загрузки и прогон отчётов.
Как выбрать справедливый дефолт для аккаунта?
Используйте свои данные, а не догадки. Посмотрите нормальное почасовое использование, нагрузку в пиковый час и самый большой краткосрочный всплеск, который не вызвал проблем. Группируйте аккаунты по тарифам или ожидаемой нагрузке и ставьте предел выше обычных пиков.
Как должны работать правила для всплесков?
Дайте каждому аккаунту стабильную скорость восстановления и небольшой буфер для всплесков. Это пропускает короткие пики, но не даёт одному клиенту оставаться на предельной нагрузке достаточно долго, чтобы заполнить очереди и воркеры.
Что должно происходить, когда аккаунт достигает лимита?
Возвращайте 429 как можно раньше и объясняйте причину. Подскажите, когда повторять попытку, покажите текущий лимит, если возможно, и приостанавливайте новые тяжёлые задания от этого аккаунта, пока нагрузка не спадёт.
Как внедрить это, не нарушив обычную работу?
Разворачивайте пошагово. Тестируйте на реальных паттернах трафика, начните с пилота для небольшого набора клиентов, ежедневно проверяйте блокировки, следите за временем в очередях, ошибками и тикетами поддержки перед широким развёртыванием.
Когда стоит повышать лимит клиента?
Повышайте лимит, когда у аккаунта устойчивая легитимная нагрузка и система в целом остаётся здоровой. Не повышайте только потому, что один клиент громко жалуется; сначала проверьте поведение повторных попыток, паттерны задач и потребуется ли другой тариф или отдельная очередь.


