Ограничение запросов в Nginx vs правила Cloudflare: что выбрать
Ограничение запросов в Nginx и правила Cloudflare по-разному останавливают вредный трафик. Узнайте, как выбрать правильный уровень, не скрывая ошибки и не мешая поддержке.
Содержание
Почему неправильный уровень создает проблемы
Плохой трафик не приходит с ярлыком. Всплеск ботов, наплыв на запуске и баг продукта в первые минуты могут выглядеть почти одинаково: больше запросов, больше попыток входа, более медленные страницы и раздраженные пользователи. Если баг во фронтенде заставляет приложение повторять неудачные запросы, ваши собственные пользователи могут выглядеть как атакующие.
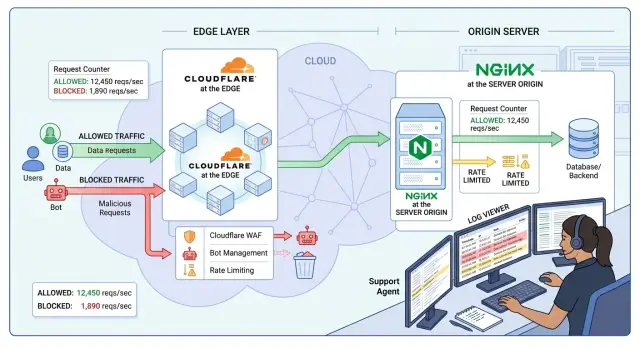
Именно поэтому важен уровень, на котором вы ставите правило. Cloudflare видит трафик раньше, чем он попадет на ваши серверы. Nginx видит его ближе к приложению, где у вас уже есть пути запросов, заголовки, статус upstream и тайминги, которые объясняют, что пошло не так. Если заблокировать слишком рано, можно остановить поток, но потерять подсказки, которые показали бы, что приложение сломалось.
Типичный сбой выглядит так. Пользователи пишут, что вход в систему «просто крутится» или выдает общий error. Поддержка смотрит в приложение и не видит явного падения. Инженеры видят меньше запросов, чем ожидали, потому что Cloudflare отфильтровал много из них на границе. Команда тратит час на поиск бага в auth, хотя реальной причиной было правило трафика, которое задело настоящих пользователей за офисным IP или за gateway мобильного оператора.
Обратная проблема не лучше. Если полагаться только на Nginx, вредный трафик все равно может ударить по origin достаточно сильно, чтобы скрыть следы. Логи переполняются, CPU растет, а настоящие ошибки тонут в шуме. Поддержка получает туманные жалобы вроде «не работает checkout», а команда приложения пытается отделить реальные сбои от ответов rate limit.
Пользователи не сообщают про сетевые уровни. Они говорят: «сайт сломан». Скриншоты и ошибки браузера часто выглядят одинаково, будь то заблокированный запрос, таймаут или неудачный релиз.
Цель простая: быстро останавливать очевидный мусор и при этом сохранять достаточно деталей, чтобы увидеть баги продукта. Если выбрать не тот уровень для не той задачи, можно уменьшить проблему с трафиком и одновременно сделать инцидент гораздо труднее для понимания.
Что Cloudflare и Nginx действительно видят
Cloudflare стоит перед вашим сервером, поэтому видит запрос еще до того, как origin потратит на него CPU, память или время базы данных. Это делает его сильным первым фильтром для очевидного мусора. Он может анализировать IP клиента, путь запроса, метод, заголовки, страну, признаки бота и то, как часто один и тот же клиент обращается к одному и тому же endpoint.
Чего он не может знать полностью, так это что именно ваше приложение сделало бы с этим запросом. Cloudflare видит запрос и ответ, который вернулся, но обычно не знает логику сессии, состояние пользователя, feature flags или причину сбоя upstream-сервиса.
Nginx видит трафик позже, после того как запрос доходит до вашего origin. Звучит как слабое место, и иногда так и есть. Но у Nginx гораздо более ясный обзор того, что происходит внутри вашего стека. Он может видеть, какой upstream обработал запрос, был ли таймаут у приложения, вернул ли backend 429 или 500, и медленный ли один маршрут, когда остальная часть сайта работает нормально.
Коротко это выглядит так:
- Cloudflare видит шаблоны на границе еще до того, как ваш сервер начинает обрабатывать запрос.
- Nginx видит, что запрос делает с вашим origin, после того как он проходит дальше.
- Оба могут анализировать cookie запроса.
- Ваш origin обычно знает, что эти cookie на самом деле означают.
Именно с cookie команды часто путаются. Cloudflare может сопоставлять значение cookie, если браузер его отправляет. Но это все равно не дает полной картины. Ваше приложение может знать, что сессия истекла, пользователь уже прошел MFA или аккаунт входит во внутренний allowlist. Этот контекст живет ближе к приложению.
Upstream-ошибки тоже меняют решение. Представьте всплеск входов во время запуска. Если Cloudflare блокирует первым, поддержка может увидеть только, что пользователей проверяли или блокировали. Если всплеск видит Nginx, вы можете узнать что-то полезнее: приложение в порядке, но session store работает медленно, или один endpoint для входа выдает 502 под нагрузкой.
Вот практическое разделение. Фильтрация трафика на edge лучше всего подходит для широких и дешевых решений. Ограничение на origin лучше, когда важно поведение продукта. Если поддержке нужно отличить вредный трафик от сломанного потока входа, Nginx обычно дает более ясный ответ.
Сначала разделите трафик на группы
Большинство ошибок в rate limit начинается с одного неверного предположения: весь нежелательный трафик ведет себя одинаково. Это не так. Бот, который скрейпит каждую страницу, скрипт, который слишком быстро повторяет запросы, сломанный мобильный клиент и реальный клиент, который постоянно обновляет медленную форму, поначалу могут выглядеть похоже.
Прежде чем трогать Cloudflare или Nginx, разделите трафик на несколько простых групп. Есть вредоносные боты, которые бьют по страницам, проверяют пути или игнорируют обычное поведение браузера. Есть шумные скрипты, которые отправляют слишком много запросов, потому что их плохо написали. Есть сломанные клиенты, которые зацикливаются после таймаута, ошибки токена или неудачного релиза. И есть реальные пользователи, которые могут коротко дать всплеск, но все равно должны получить чистый путь.
Это разделение показывает, где останавливать каждую группу. Вредоносных ботов обычно нужно останавливать на edge. Если Cloudflare блокирует их до того, как они попадут на ваши серверы, вы экономите ресурсы origin и получаете более чистые логи. Шумные скрипты требуют более внимательного подхода. Если шаблон широкий и очевидный — блокируйте на edge. Если трафик зависит от путей приложения, состояния пользователя или поведения авторизации, Nginx часто лучше, потому что видит запрос в контексте.
К сломанным клиентам нужен особый подход. Они не всегда враждебны. Жесткая блокировка может скрыть баг продукта и увести поддержку в неверную сторону. Начните с мягкого лимита, понятных логов и ответа, который команда сможет объяснить. Если новый релиз приложения вызывает шторм повторов, поддержка должна уметь сказать: «версия 4.2 слишком быстро повторяет запросы, и сервер замедляет их», а не гадать, что сломалось раньше — CDN, API или приложение.
Первую версию держите скучной. Одно правило на edge для очевидного мусора. Одно правило на origin для чувствительных endpoint вроде входа или сброса пароля. Одна короткая заметка для поддержки: кого блокируют, где это происходит, как долго это длится и что видит пользователь.
Небольшим командам обычно лучше подходят простые правила. Чем меньше движущихся частей, тем проще объяснять, разбирать и исправлять инциденты.
Когда Cloudflare — лучший первый фильтр
Cloudflare имеет больше смысла, когда вы хотите остановить плохой трафик до того, как он съест CPU сервера, заполнит логи или вызовет замедления, похожие на баг продукта. Если запрос даже не доходит до origin, команде остается меньше шума и меньше ложных тревог.
Лучше всего это работает для шаблонов, которые легко заметить заранее: шумные бот-волны, повторные запросы из одних и тех же сетевых диапазонов, очевидные блокировки по странам или трафик, который снова и снова совпадает с одним и тем же плохим путем и шаблоном заголовков. Это прежде всего проблемы edge, а не приложения.
Cloudflare обычно лучше подходит, когда большие всплески бьют по многим URL сразу, боты скрейпят публичные страницы намного быстрее обычных пользователей, атакующие приходят из мест, которые вы не обслуживаете, или запросы повторяют один и тот же пустой или фальшивый набор заголовков снова и снова.
Это помогает и тогда, когда один всплеск может повлиять на общую инфраструктуру. Если несколько сервисов сидят за одним origin, остановить плохой трафик раньше обычно безопаснее и дешевле.
Цена этого — видимость для поддержки. Edge-правила могут вызывать путаницу, если никто не понимает, почему они сработали. Делайте их простыми и узкими. Называйте правила по поведению, а не по догадке. «Block repeated requests to /wp-login from non-user browsers» гораздо лучше, чем «bot defense rule 7».
Хорошее edge-правило должно позволять поддержке ответить на три вопроса меньше чем за минуту: какой шаблон его сработал, каких пользователей или регионов это может коснуться, и где команда может проверить совпадение. Если на это уходит больше времени, правило слишком запутанное.
Когда Nginx — лучший выбор
Nginx лучше подходит для ограничения запросов, когда правило зависит от того, что делает приложение, а не только от того, откуда пришел запрос. Если вам нужны разные лимиты для /login, /search, /checkout или приватного API, origin обычно дает более чистый контроль.
Это важно, когда обычный трафик и плохой трафик на edge выглядят одинаково. Клиент, который пять раз ошибся в пароле, обновляет результаты поиска или повторяет checkout после медленного ответа, может несколько секунд выглядеть шумным. Nginx может оценить этот трафик ближе к пути приложения и шаблону запроса, так что вы сможете оставить публичные страницы открытыми, а ужесточить только те маршруты, которые действительно создают нагрузку или злоупотребления.
Ограничение на origin хорошо подходит для endpoint входа, где повторные попытки должны быстро замедляться, для маршрутов поиска, которые боты забивают похожими запросами, для действий checkout, где дублирующие POST создают боль для поддержки, и для API-маршрутов, где нужен один лимит для анонимных пользователей и другой для вошедших в систему.
Nginx также логичнее, когда поддержке нужно сравнить заблокированные запросы с ошибками приложения. Если пользователь говорит: «Я нажал оплатить дважды, а потом получил ошибку», ваша команда может посмотреть логи origin и увидеть заблокированный запрос рядом с логом приложения, таймаутом upstream или ошибкой базы данных из того же момента. Это резко сокращает обмен сообщениями.
Особенно полезно это тогда, когда проблема может оказаться багом продукта, а не злоупотреблением. Edge-фильтры могут остановить трафик, но они же могут скрыть шаблон, который вызвал проблему. На origin вы увидите, заблокировал ли Nginx всплеск потому, что по маршруту ударил бот, или потому что фронтенд слишком агрессивно повторял один и тот же запрос после бага.
Когда команда работает на минимуме, это еще важнее. Одно место для просмотра логов лучше, чем гадать по разным уровням, пока пользователи ждут, а поддержке нужен ответ.
Безопасный порядок запуска
Сначала наблюдайте за трафиком, а уже потом что-то блокируйте. Логируйте маршрут, код ответа, количество запросов и способ сгруппировать посетителей, например IP, сессию или API token. Смотрите обычные пики несколько дней. Многие команды думают, что их атакуют, хотя на самом деле у них медленный endpoint, петля повторов или всплеск в день релиза.
Если сравнивать Nginx rate limiting vs Cloudflare rules, самый безопасный путь — маленький и скучный. Выберите один маршрут с понятным шаблоном злоупотребления, например вход или сброс пароля. Добавьте там одно узкое правило и оставьте остальное в покое. От одного реального правила вы узнаете больше, чем от десяти предположений.
- Сначала измерьте объем запросов, уровень ошибок и нагрузку на сервер.
- Включите одно правило для одного маршрута с порогом, который можно объяснить.
- Возвращайте простое сообщение вроде «Слишком много запросов. Подождите 30 секунд и попробуйте снова».
- Добавьте короткую заметку для поддержки с маршрутом, порогом, ожидаемым сообщением для пользователя и местом, где смотреть логи.
- Проверьте ложные срабатывания, всплески 429 и тикеты поддержки, прежде чем добавлять следующее правило.
Эта заметка для поддержки важнее, чем многие ожидают. Если клиент не может войти, поддержке нужно понять, сломан ли продукт или запрос заблокировало правило. Короткая заметка может сэкономить около 20 минут на тикете и не дать инженерам гоняться за не тем багом.
Следите за первым запуском внимательно. Если CPU немного падает, а жалоб на вход становится больше, возможно, правило ловит нормальное поведение офисных сетей, мобильных операторов или менеджеров паролей. Сначала исправьте это. Потом расширяйте правила, по одному маршруту за раз.
Реалистичный пример со входом в систему в день запуска
Запуск может сломаться двумя очень разными способами, и поначалу они выглядят почти одинаково. Пользователи говорят, что вход не работает. Поддержка получает скриншоты. Инженеры видят всплеск. Сложность в том, чтобы отличить плохой трафик от проблемы продукта.
Представьте стартап, который открывает доступ к новой функции в 9:00 утра. За первые десять минут на endpoint входа приходит 12 000 запросов. Около 3 000 — от реальных людей, которые получили письмо о запуске. Остальные 9 000 приходят от ботов, пытающихся старые пароли, дешевых proxy и скриптов, которые бьют по форме, не загружая остальную часть сайта.
Если мусорный трафик составляет большую часть всплеска, блокируйте его на edge. Cloudflare может остановить очевидный мусор до того, как он попадет на ваш сервер, базу данных или session store. Это сохраняет скорость страницы входа для реальных пользователей и избавляет команду от поиска причин роста нагрузки, который вы сами не хотели создавать.
Теперь перевернем пример. Запуск действительно популярен, и трафик в основном реальный. Баг в auth flow замедляет ответы с 300 мс до 8 секунд. Люди нажимают кнопку снова. Мобильное приложение повторяет запросы. Браузеры отправляют их еще раз после таймаута. В итоге каждый реальный пользователь создает пять или шесть попыток входа.
Вот где ограничения на origin помогают больше. Nginx может защитить endpoint входа от шторма повторов, пока вы все еще видите сбой на уровне приложения. Если Cloudflare блокирует первым, поддержка может решить, что проблему вызвала атака, хотя на деле это медленный запрос к базе или сломанная проверка token.
Когда начинаются жалобы, проверьте оба уровня вместе. Посмотрите события Cloudflare, чтобы понять, не выросло ли число проверок или блокировок в ту же минуту, когда начались обращения. Проверьте логи Nginx на 429 по пути входа. Сравните это с ошибками приложения, задержкой auth и медленными запросами к базе за тот же промежуток.
Это разделение важно. Если Cloudflare заблокировал большую часть плохих запросов, настройте edge-правило. Если Nginx и приложение показывают рост повторов от реальных сессий, сначала чините поток входа и держите origin-лимит достаточно жестким, чтобы не допустить полного падения.
Ошибки, которые путают пользователей и поддержку
Путаница обычно начинается тогда, когда команда считает весь трафик одинаковым. В решении Nginx rate limiting vs Cloudflare rules неправильный выбор часто сильнее бьет по поддержке, чем по атакующим. Страница входа, поле поиска, poller API и загрузка файлов ведут себя по-разному, значит и порог у них не должен быть один.
Если поставить один низкий лимит для всех путей, нормальные пользователи упрется в него первыми. В дни запуска это еще хуже. Человек может дважды обновить страницу входа, ваш фронтенд может отправить фоновый запрос, а мобильное приложение — повторить попытку после таймаута. В итоге пользователь видит блокировку, а поддержка — никакой ясной причины.
Еще одна частая ошибка — сначала блокировать, а потом смотреть. Это кажется безопасным, но скрывает реальный шаблон. Сначала логируйте частоту запросов, пути, коды статуса и user agents. Посмотрите короткий отрезок реального трафика, прежде чем ставить жесткую блокировку. Очень часто оказывается, что всплеск создает ваше собственное приложение.
Петли повторов причиняют больше вреда, чем многие ожидают. Мобильное приложение с плохой обработкой сети может отправлять один и тот же запрос пять раз за несколько секунд. Такой же эффект может дать баг фронтенда, если он повторяет каждое неудачное promise. Если игнорировать эти петли, можно обвинить плохой трафик, хотя источник — ваш код.
Смешанные ответы создают еще одну проблему для поддержки. Если Cloudflare проверяет часть запросов, а Nginx возвращает 429 для других, пользователи сообщают, что «сайт сломан», и поддержка не может понять, пришла проблема от bot rule, ограничения на origin или шторма повторов со стороны клиента.
Держите ответы согласованными. Если rate limit обрабатывается на обоих уровнях, по возможности используйте одинаковый код статуса, похожий текст ответа и один и тот же request ID в логах. Тогда поддержка сможет сопоставить тикет с событием, а не гадать.
Что проверить перед включением правил
Маленькие слепые зоны создают большую часть боли. Правило может блокировать плохой трафик и все равно устроить хаос для поддержки, если никто не понимает, где произошла блокировка и почему.
Сделайте несколько коротких тестов на реальных запросах, прежде чем включать что-то для всех пользователей. Отправьте один запрос, который должен пройти, один, который должен попасть под мягкий лимит, и один, который должен вызвать жесткую блокировку. Потом проверьте, что записывает каждая система.
- Посмотрите логи origin после блока на edge. Если Cloudflare остановил запрос до того, как он дошел до Nginx, в логах приложения будет тихо.
- Проверьте, как поддержка видит rate limit по сравнению с ошибками продукта. 429 от правила трафика не должен выглядеть как сломанная форма входа или случайный 500.
- Протестируйте shared IP. Один офис, школа, коворкинг или мобильный оператор может держать много реальных пользователей за одним адресом.
- Сравнивайте события edge и ответы origin рядом, чтобы история совпадала.
Тест с shared IP особенно важен. Если вы ограничиваете только по IP, один активный клиент может заблокировать всех остальных в том же офисе. Вход и регистрация страдают от этого постоянно. Более удачный первый шаг — ограничивать по пути, методу, аккаунту, сессии или признаку бота, если он у вас есть.
Поддержке тоже нужен быстрый способ отличать контроль трафика от бага продукта. Используйте разные коды статуса и понятный текст ошибки. Если Cloudflare возвращает 403 или 429, а ваше приложение тоже использует 429 для собственного throttling, отметьте это в runbook и в макросах для тикетов. Иначе команда будет тратить время на несуществующий баг.
И последнее: сравнивайте числа. Если Cloudflare показывает 8 000 заблокированных запросов, а Nginx — только 200 попыток, эта разница должна иметь смысл. Если смысла нет, значит, мониторинга слишком мало для безопасной фильтрации трафика на edge.
Что делать дальше
Назначьте владельца для каждой проблемы с трафиком, прежде чем добавлять еще одно правило. Команды попадают в неприятности, когда оба уровня пытаются решать одну и ту же задачу или когда никто не знает, какой именно уровень заблокировал запрос.
Практичное разделение простое. Широкую фильтрацию ботов, блокировки стран, проверки reputation IP и большие потоки трафика отправляйте в Cloudflare. Шаблоны запросов, которые зависят от поведения приложения, держите в Nginx или в самом приложении. Проверки личности пользователя, блокировки аккаунтов и злоупотребление token держите ближе к origin. И самое главное — оставляйте в логах достаточно деталей, чтобы поддержка могла понять, вызвал сбой баг или правило.
Напишите короткий runbook и не усложняйте его. Одной страницы достаточно. В нем должно быть указано, кто первым смотрит Cloudflare, кто смотрит логи Nginx, какие коды статуса могут увидеть пользователи и как безопасно отключить плохое правило. Продукту тоже стоит отмечать, какие запуски или кампании могут изменить обычный трафик, чтобы инженерная команда не приняла успех за злоупотребление.
Для этой темы лучший следующий шаг — не новая теория, а маленькая карта трафика. Проведите один запрос от edge до origin, отметьте все места, где его можно заблокировать, и запишите, кто отвечает за каждый шаг.
Если вашей команде нужен второй взгляд, Oleg Sotnikov на oleg.is проверяет такие схемы для стартапов и небольших команд в рамках своей работы Fractional CTO и инфраструктурного консультирования. Короткий разбор пути трафика, конфигурации Nginx и edge-правил часто помогает уменьшить шум для поддержки и сделать инциденты проще для объяснения.
Часто задаваемые вопросы
В чем реальная разница между правилами Cloudflare и ограничением запросов в Nginx?
Cloudflare останавливает запросы на границе сети, еще до того, как ваш сервер потратит на них CPU, память или время базы данных. Nginx применяет ограничения на origin, где можно видеть пути запросов, ошибки upstream и время работы приложения. Ставьте очевидный мусор на Cloudflare, а правила, зависящие от приложения, — на Nginx.
Когда лучше сначала блокировать трафик в Cloudflare?
Начинайте с Cloudflare, когда шаблон легко заметить заранее. Сюда хорошо подходят бот-волны, повторные запросы к плохим путям, трафик из стран, которые вы не обслуживаете, и фальшивые шаблоны заголовков, потому что вы останавливаете их еще до того, как они дойдут до вашего origin.
Когда Nginx — лучшее место для ограничения запросов?
Nginx лучше подходит, когда важен сам маршрут. Если /login, /search, /checkout или приватному API нужны разные лимиты, Nginx дает больше контекста и помогает проще сравнивать ответы 429 с ошибками приложения и медленными upstream.
Нужно ли использовать Cloudflare и Nginx вместе?
Да, но разделяйте задачи. Пусть Cloudflare отсеивает широкий мусор и большие всплески, а Nginx защищает чувствительные маршруты, зависящие от поведения приложения. Если оба уровня пытаются решать одну и ту же проблему, пользователи получают смешанные ошибки, а поддержка теряет время.
Может ли Cloudflare использовать cookie для ограничения запросов?
Cloudflare может сопоставлять значения cookie, которые отправляет браузер. Но он все равно не знает, что эти cookie означают внутри вашего приложения, например истекшую сессию, состояние MFA или внутренний список разрешенных. Правила, зависящие от состояния пользователя, лучше держать ближе к origin.
Почему реальные пользователи попадают под ограничение запросов?
Много ложных срабатываний дают общие IP-адреса. Один офис, школа, коворкинг или мобильный оператор могут скрывать за одним адресом много обычных пользователей. Повторные попытки, менеджеры паролей и медленные страницы тоже делают реальных людей шумными на несколько секунд.
Как безопаснее всего внедрять ограничения запросов?
Сначала наблюдайте за трафиком, и только потом что-то блокируйте. Затем выберите один маршрут с понятным шаблоном злоупотребления, задайте один порог, который можно объяснить, возвращайте простое сообщение и проверьте ложные срабатывания, прежде чем расширять правило. Маленькие изменения учат гораздо лучше, чем большой набор правил.
Что поддержка должна проверить первым делом, если пользователи говорят, что вход не работает?
Проверьте одну и ту же минуту на обоих уровнях. Посмотрите события Cloudflare на предмет резких блокировок или проверок, проверьте логи Nginx на 429 по этому маршруту и сравните это с ошибками приложения, задержкой auth и замедлением базы данных. Так станет ясно, виноваты правила трафика или сам продукт.
Какой статус-код лучше возвращать при ограничении запросов?
Используйте 429 Too Many Requests для throttling, когда это возможно, и старайтесь держать сообщение одинаковым на обоих уровнях. Если Cloudflare возвращает 403 или 429, а ваше приложение тоже использует 429, зафиксируйте это в runbook и в шаблонах для тикетов, чтобы поддержка отличала правило трафика от проблемы приложения.
Когда стоит попросить эксперта проверить мою настройку?
Просите помощь, когда уровни начинают перекрывать друг друга, ложные срабатывания растут или команда не может объяснить, где именно произошла блокировка. Короткий разбор пути трафика, конфигурации Nginx и edge-правил часто быстро убирает лишний шум для поддержки. Oleg Sotnikov предлагает такой разбор в рамках своей работы Fractional CTO и инфраструктурного консультирования.


