Общая AI-инфраструктура для команд с несколькими процессами
Общая AI-инфраструктура помогает командам запускать несколько процессов на одной очереди, в одном хранилище и с одной схемой трассировки, пока инструменты и расходы не начали разрастаться.
Содержание
Почему разрастание сервисов начинается так быстро
Большинство команд не ставят себе цель собрать хаотичный стек. Это происходит по одному процессу за раз.
Боту поддержки выделяют свою очередь, хранилище файлов и логи. Потом появляется парсер документов и получает такой же набор. Через неделю кто-то добавляет внутреннего помощника для программирования и повторяет тот же шаблон, потому что так кажется быстрее, чем встраивать его в то, что уже есть.
Сначала каждое решение выглядит недорогим. Ещё один управляемый сервис, ещё одно хранилище, ещё один дашборд. Проблема в том, что счёт растёт даже тогда, когда использование остаётся скромным. Вы снова и снова платите за одни и те же базовые вещи: минимальные платежи за сервис, дублированные данные, сохранённые логи, дополнительные секреты, простаивающие обработчики и сервисы, которые стоят без дела весь день, независимо от того, пользуется ли ими кто-то или нет.
Ещё больше стоит время команды. Для каждой новой очереди нужны права доступа. Для каждого хранилища — правила именования, настройки хранения и очистка. Для каждого дашборда нужны оповещения, владелец и человек, который ещё помнит, что вообще означают графики.
Небольшие команды чувствуют это особенно рано. Один инженер может добавить процесс за полдня, а потом ещё две недели чинить ошибки доступа, обновлять скрипты развертывания и разбираться с оповещениями из инструментов, на которые никто не смотрит регулярно. Сам процесс может быть вполне нормальным. Но стек вокруг него начинает забирать всё внимание команды.
Представьте три типичных AI-процесса: сводки обращений в поддержку, извлечение данных из счетов и внутренние комментарии к ревью кода. Если у каждого своя очередь, своё хранилище, своя трассировка и свой мониторинг, у вас уже три места, где нужно проверять задачи, три места, где искать неудачные файлы, и три разных набора правил доступа. По отдельности это не звучит как что-то огромное. Вместе это превращается в шум.
Именно поэтому общая AI-инфраструктура окупается раньше. Когда команды делят очереди, шаблоны хранения, трассировку и базовые правила доступа, они убирают дублирующую работу ещё до того, как она становится привычкой. Гораздо проще позже разделить одну загруженную очередь, чем распутывать шесть отдельных стеков, которые выросли случайно.
Что входит в общую основу
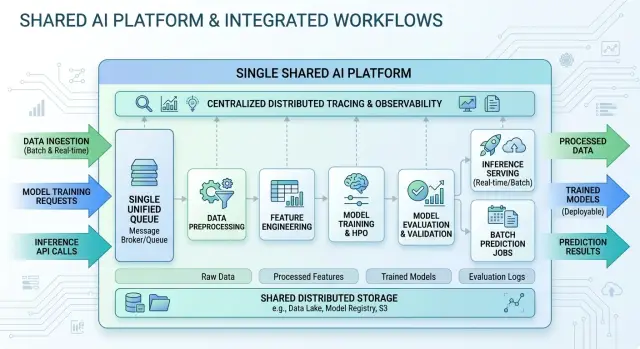
Общая основа — это общий фундамент под несколькими AI-процессами. Это не одно огромное приложение, которое заставляет все команды работать по одному сценарию. Идея проще: повторно использовать скучные части, которые нужны почти каждому процессу, а каждому процессу оставить свою логику.
Проще всего представить очередь. Это как одна общая линия задач. Процесс отправляет задачу, обработчики её забирают, а очередь управляет порядком, повторными попытками и обратным давлением, когда API модели работает медленно или дорого. Задачи не должны выглядеть одинаково, чтобы использовать одну и ту же систему очередей. Можно оставить понятные типы задач, например support-summary, document-extract и code-review. Общая часть — это транспорт и правила работы. Специфичная часть процесса — полезная нагрузка, время ожидания, число повторных попыток и приоритет.
С хранилищем всё так же. Проблемы начинаются, когда каждый процесс придумывает своё хранилище, свой стиль именования и свои правила очистки. Сначала это кажется удобным, но через несколько дней уже никто не понимает, где что лежит. Более аккуратная схема использует один слой хранения с чёткими границами. Один процесс может писать в support/raw/ и support/final/, а другой — в contracts/raw/ и contracts/final/. Хранилище общее, а разделение остаётся очевидным.
Трассировка — это часть, которую команды часто пропускают, а потом жалеют. Вам нужно одно место, где можно проследить запрос через очередь, обработчик, вызов модели и финальную запись в хранилище или базу данных. Когда задача падает, один trace или ID запроса должен быстро отвечать на простые вопросы: слишком долго ли она ждала? Сломался ли вызов модели? Записал ли обработчик не тот файл?
Поведение каждого процесса при этом всё равно может оставаться отдельным. Промпты, версии промптов, выбор моделей, настройки температуры, схемы вывода, правила проверки и шаги согласования не обязаны быть общими. Это разделение важно. Общими должны быть инструменты, а не поведение.
Команда стартапа, которая запускает несколько процессов с участием AI, может использовать одну и ту же очередь, хранилище и трассировку для всех них, при этом полностью раздельно настраивая промпты для ревью кода и извлечение данных из документов. Такая граница помогает расти аккуратно и не превращает каждый процесс в собственное маленькое королевство.
Что стоит объединить сначала, а что разделять позже
Начните с одной базы почти для всего. Большинству команд не нужна отдельная очередь, отдельное хранилище и отдельный инструмент трассировки для каждого нового процесса. Такой подход выглядит аккуратно неделю, а потом превращается в разрастание сервисов.
Для большинства команд первый общий слой должен включать одну систему очередей, один слой хранения и одну настройку трассировки. Эти три вещи решают одни и те же задачи для разборов обращений в поддержку, парсинга документов, внутренних копилотов и фоновых автоматизаций.
Используйте одну очередь, если только процесс не ведёт себя совсем иначе, чем остальные. Если две задачи могут подождать несколько секунд и несколько раз повториться, они могут жить в одной и той же системе очередей. Разделяйте только тогда, когда разница действительно реальна: одному процессу нужен почти мгновенный ответ, у другого гораздо строже правила доставки, у третьего жёсткое разделение данных, а четвёртый создаёт такую нагрузку, что мешает остальным.
Хранилище тоже лучше оставить общим. Секрет не в отдельных инструментах. Секрет в понятных правилах. Именуйте данные по процессу, заранее определите доступ и поставьте пределы хранения до того, как накопится большой объём. Если один поток хранит промпты 7 дней, а другой — результаты 90 дней, это нормально. Для этого не нужен новый продукт хранения.
Трассировку стоит централизовать с первого дня. Когда запрос проходит через API, очередь, вызов модели и обработчик, один trace показывает весь путь. Если каждый процесс логирует по-своему, отладка быстро замедляется. Централизованная наблюдаемость помогает меньше гадать, когда несколько AI-процессов работают на одной production-базе.
Хорошее правило простое: по умолчанию всё общее, а разделение появляется только при реальном ограничении. Обычно это границы безопасности, требования к задержке, правила соответствия или нагрузка, которая явно мешает другим задачам. Всё, что слабее этого, часто оказывается просто предпочтением, замаскированным под архитектуру.
Как настроить это шаг за шагом
Начните с инвентаризации, а не с плана миграции. Запишите все процессы, которые у вас уже есть, даже те, о которых люди не любят говорить. Для каждого укажите, что его запускает, что он читает, что пишет и к каким сервисам или моделям обращается. Пишите простым языком. Если процесс отправляет промпт, сохраняет файл и записывает результат в базу данных, так и напишите.
Когда картина станет полной, выберите одну общую основу. Возьмите одну очередь, один шаблон хранения и один формат трассировки для всех процессов, которые реально могут их использовать. Не проектируйте основу под самый громкий или самый странный процесс. Такой выбор часто создаёт сложный стандарт для всех остальных.
Задайте правила именования до переноса чего-либо. Хорошие имена сокращают время на отладку быстрее, чем ожидает большинство команд. Делайте их простыми и одинаковыми. Названия задач должны говорить, что они делают и какая версия работает. Файлы должны включать название процесса, дату и ID запуска. Ошибки должны использовать короткие повторяемые метки, а не произвольный текст. invoice_extract.v2 говорит гораздо больше, чем processor_new, а model_timeout легче отследить, чем пять чуть разных сообщений об одной и той же ошибке.
Перенесите сначала самый маленький процесс. Выберите тот, у которого низкий риск, понятные входные данные и простой откат. Запустите его на общей базе на целую неделю. Следите за неудачными задачами, количеством повторных попыток, ростом хранилища, покрытием трассировкой и за тем, сколько времени уходит у человека на объяснение проблемы другому человеку. Последняя проверка недооценена. Если никто не может внятно объяснить сбой, значит, система всё ещё слишком запутана.
После этого переносите остальные процессы по одному. Не мигрируйте сразу три, только потому что первый перенос прошёл удачно. Каждый процесс покажет новую недоработку: странные имена файлов, недостающие поля трассировки, правила повторных попыток, которые подходят для одной задачи, но не для другой. Исправляйте эти пробелы по мере появления. К моменту, когда третий процесс окажется на той же базе, у вас должно быть меньше деталей, чище трассировка и гораздо меньше лишнего.
Простой пример с тремя процессами
Представьте небольшую команду с тремя AI-задачами, которые выполняются каждый день. Одна отвечает на обращения в поддержку, другая разбирает загруженные документы, а третья собирает еженедельные отчёты. Если у каждой задачи своя очередь, своё хранилище, свои логи и свой дашборд, беспорядок начинается очень быстро.
Общая схема сохраняет фундамент простым. Все три процесса могут использовать одну и ту же систему очередей с тегами вроде support_bot, document_parser и report_generator. Им не нужны отдельные стеки только ради порядка.
Данные при этом остаются раздельными там, где это важно. Бот поддержки пишет в support/, парсер документов использует documents/, а генератор отчётов — reports/. Одной системы хранения достаточно, потому что пути уже разделяют файлы. Правила доступа всё равно могут быть строгими, но команде нужно управлять только одной политикой хранилища, одним подходом к резервному копированию и одной системой оповещений.
Трассировка работает по тому же принципу. Все три процесса отправляют данные трассировки в одно место, с тегами по названию процесса, клиенту или tenant при необходимости, модели и ID задачи. Когда что-то ломается, команде не нужно прыгать между инструментами, чтобы угадать, где началась задержка.
Допустим, парсер документов начинает тормозить на больших PDF. Трассировка показывает, что время ожидания в очереди нормальное, загрузка файла идёт быстро, а больше всего времени уходит на шаг с моделью. Позже в тот же день бот поддержки начинает падать на одном шаблоне промпта. Та же система трассировки показывает этот сбой рядом с нормальными запусками других процессов.
Такой общий обзор помогает не только в отладке, но и в сравнении. Команда видит, что генератор отчётов падает один раз на 1 000 задач, а парсер — один раз на 50. Она также видит, что ответы поддержки укладываются в 10 секунд, а отчёты по понедельникам стоят в очереди по три минуты. Теперь понятно, что чинить первым. Для этого не нужны три отдельных стека.
Ошибки, которые снова возвращают хаос
Общая схема обычно ломается вполне обычным образом. Команды добавляют одно исключение, потом ещё одно, и аккуратная система превращается в набор обходных путей.
Перегрузка очереди часто становится первой проблемой. Тяжёлый процесс, например парсинг документов или массовое обогащение данных, может забить очередь и замедлить всё, что стоит после него. Тогда задача для пользователя, например чат или разбор обращения, ждёт работу, которая должна была оставаться в фоне. Приоритеты, ограничения скорости и понятные классы очередей решают это заранее, без перехода на совсем новую платформу.
Именование создаёт более тихий, но очень быстро распространяющийся беспорядок. Если один процесс хранит файлы как output.json, а другой делает то же самое, люди путают результаты, перезаписывают артефакты или читают данные не той задачи. Простое правило сильно помогает: каждый сохранённый объект должен включать название процесса, ID запуска и дату. Простые имена — хорошие имена.
С хранилищем начинаются проблемы, когда никто не задаёт правила хранения. Команды оставляют промпты, логи, скриншоты, временные файлы, неудачные результаты и тестовые запуски навсегда, потому что удалять их кажется рискованным. Через несколько месяцев расходы растут, а никто уже не понимает, что вообще ещё важно. Сохраняйте только то, что помогает в отладке, аудитах или бизнес-учёте. Остальное удаляйте по расписанию.
Трассировка теряет большую часть ценности, когда каждый процесс пишет разные поля. Одна команда записывает название модели и задержку. Другая — только успех или ошибку. Третья добавляет собственные метки, которые больше никому не нужны. Позже вы уже не сможете сравнивать запуски или находить медленный шаг между системами. Выберите небольшую общую схему и используйте её везде. Название процесса, ID запуска, tenant или клиент, время ожидания в очереди, модель, расход токенов, стоимость и финальный статус закрывают большинство задач.
Последняя ошибка выглядит безобидной: команда добавляет отдельный инструмент для одного странного случая. Возможно, один процесс получает собственное векторное хранилище, дашборд трассировки или планировщик, потому что «это только для этого проекта». Именно это часто запускает следующую волну разрастания. Перед тем как добавлять новый сервис, спросите себя, сможет ли текущий стек закрыть большую часть задачи с небольшим расширением. Во многих случаях — да.
Проверки перед добавлением ещё одного процесса
Общая схема остаётся аккуратной только если каждый новый процесс проходит один и тот же небольшой набор проверок. Пропустите их один раз — и команда обычно добавит ещё одну очередь, ещё одно хранилище и ещё один стиль логирования.
Начните с очереди. Если текущая система уже поддерживает размер задачи, приоритет и правила повторных попыток, используйте её снова. Разделяйте только тогда, когда новый поток имеет явно другую динамику по времени или сбоям.
Определите, где будут лежать результаты, до того как кто-то напишет код. Храните промпты, ответы, файлы и финальные результаты там, где уже подходят ваши правила именования и сроки хранения. Если процесс создаёт временные данные, задайте очистку до первого тестового запуска. «Потом уберём» обычно означает, что не уберёт никто.
Трассировка требует той же дисциплины. Каждый запуск должен отправлять одинаковый набор основных полей, чтобы можно было сравнивать процессы без догадок. В большинстве команд это означает ID запуска, название процесса, использованную модель, ID tenant или клиента, если он нужен, задержку, стоимость токенов или вычислений и финальный статус.
Короткой предварительной проверки обычно достаточно:
- Используйте существующую очередь, если только задаче не нужна другая приоритетность или изоляция.
- Выберите хранилище для результатов и правило хранения до первого теста.
- Определите поля трассировки, которые должен отправлять каждый запуск.
- Решите, как повторные попытки, сбои и зависшие задачи будут выглядеть в логах и оповещениях.
- Назначьте человека или команду, которые отвечают за очистку и лимиты хранилища.
Особое внимание стоит уделять сбоям. Повторные попытки могут неделями скрывать плохие промпты, сломанные парсеры или циклы из-за ограничений по скорости. Зависшие задачи должны быть видны в одном месте. Если операторам нужно три инструмента, чтобы понять, что сломалось, они будут многое пропускать.
Небольшие команды обычно лучше всего справляются с этим, когда рассматривают каждый новый процесс как арендатора той же самой базы, а не как начало нового стека.
Как понять, что общая схема всё ещё работает
Общая схема продолжает работать, когда новые процессы могут подключаться к той же базе, не делая старые медленнее, шумнее или сложнее в поддержке. Вам не нужен большой набор метрик. Несколько показателей, которые вы проверяете регулярно, расскажут почти всю историю.
Начните с времени ожидания в очереди, общего времени выполнения, роста хранилища и уровня ошибок. Если запросы дольше ждут старта, возможно, один процесс вытесняет другие. Если та же задача теперь выполняется вдвое дольше, общие вычисления или хранилище испытывают давление. Быстрый рост хранилища часто указывает на дублированные файлы, логи, которые никто не читает, или результаты, которые никогда не очищают. Даже небольшой рост уровня ошибок важен, когда несколько процессов зависят от одной и той же очереди, хранилища и трассировки.
Есть и ещё одна проверка, которая не менее важна: мешает ли один процесс другим в часы пик? Ночной поток обработки документов может забить очередь и к утру сделать помощника для клиентов похожим на сломанный сервис. Формально ничего не упало, но пользователи всё равно получают плохой результат. Понятные названия в логах и трассировке сразу показывают причину.
Команды часто пропускают и более тихий сигнал: разовые сервисы. Считайте, сколько отдельных очередей, маленьких баз данных, собственных хранилищ файлов или дополнительных инструментов трассировки люди добавляют каждый месяц. Если это число растёт, значит, к общей схеме всё меньше доверия. Люди строят обходные пути, когда основной путь кажется медленным, непонятным или сложным для изменений.
Короткого ежемесячного обзора обычно достаточно. Спросите, что добавили, чем никто не пользовался, что стало причиной последнего замедления и что можно вернуть в общий стек. Удаляйте неиспользуемые инструменты заранее. Как только у запасного сервиса появляются резервные копии, оповещения и собственная конфигурация, он обычно живёт вечно.
Если время ожидания остаётся стабильным, ошибок мало, хранилище растёт по понятной причине, а команда перестаёт добавлять побочные системы, значит, общая база здорова. Если нет — сначала устраните узкое место, а уже потом добавляйте ещё один процесс.
Что делать дальше
Выберите самую маленькую общую базу и сделайте её стандартом по умолчанию. Для большинства команд в начале достаточно одной очереди для задач, одной схемы хранения для файлов и результатов и одного пути трассировки для каждого запуска. Если кто-то хочет новый инструмент для одного процесса, попросите показать реальное ограничение, а не просто предпочтение.
Напишите короткую политику и храните её там, где её увидят все, кто создаёт процессы. Двух страниц достаточно. Новые проекты должны сначала подключаться к общей схеме и отделяться только тогда, когда есть ясная причина, например жёсткое разделение данных, необычные требования к скорости или доказанная проблема со стоимостью.
Хорошо работает простая стартовая политика:
- Новые процессы используют текущую очередь, если только тесты не покажут, что она не справляется с нагрузкой.
- Команды хранят промпты, результаты и метаданные по согласованному шаблону именования.
- Каждый процесс отправляет одинаковые поля трассировки, включая ID запуска, модель, затраченное время, стоимость и причину сбоя.
- Любой дополнительный сервис должен иметь письменное обоснование, владельца и дату пересмотра.
Такой подход держит инфраструктуру достаточно маленькой, чтобы ею можно было управлять. Он ещё и упрощает адаптацию новых сотрудников. Новый инженер понимает систему за один день, а не бегает по пяти дашбордам и трём инструментам хранения.
Если вашей команде нужен второй взгляд до того, как стек снова начнёт расти, Олег Сотников на oleg.is помогает стартапам и небольшим компаниям с lean AI-first архитектурой, инфраструктурой, автоматизацией и работой в формате Fractional CTO. Такой аудит часто обходится дешевле, чем разбирать кучу лишних сервисов через полгода.
Сделайте на этой неделе один практический шаг: поставьте на паузу новые покупки инфраструктуры для AI-процессов, пока команда не зафиксирует эти общие правила. Одна эта пауза может сэкономить месяцы последующей уборки.
Часто задаваемые вопросы
Что команде стоит сделать общим в первую очередь для AI-процессов?
Начните с одной очереди, одного слоя хранения и одной настройки трассировки. Эти три элемента убирают больше всего дублирующей работы и задают одинаковые правила для всех процессов.
Когда стоит выделять процесс в отдельный стек?
Разделяйте процесс только тогда, когда упираетесь в реальное ограничение. Обычно это строгая изоляция данных, гораздо более низкие требования к задержке, правила соответствия или нагрузка, которая мешает другим задачам.
Могут ли разные AI-задачи использовать одну очередь?
Да. Можно использовать одну и ту же очередь и разделять задачи по типу, приоритету, времени ожидания и правилам повторных попыток. Так операции остаются простыми, а каждый процесс всё равно работает как нужно.
Как не дать общему хранилищу превратиться в хаос?
Используйте одну систему хранения с понятными путями для каждого процесса, например отдельные папки или префиксы. Добавьте простые правила именования, заранее задайте срок хранения и включите очистку в сам процесс, а не оставляйте её на потом.
Какие поля трассировки нам действительно нужны?
Отправляйте одни и те же основные поля в каждом запуске: название процесса, ID запуска, модель, время ожидания в очереди, общее время, стоимость или число токенов, tenant при необходимости и финальный статус. С таким набором можно быстро сравнивать запуски и находить медленные места.
Какой процесс лучше переносить первым?
Переносите сначала самый маленький и безопасный процесс. Выберите тот, у которого понятные входные данные, низкий риск и простой откат, а затем дайте ему поработать на общей базе достаточно долго, чтобы заметить проблемы с именованием, повторными попытками и трассировкой.
Как не дать одной тяжёлой задаче замедлить всё остальное?
Используйте приоритеты, ограничения по скорости или отдельные классы очередей внутри одной системы. Так работа для пользователей останется быстрой, а крупные пакетные задачи будут спокойно выполняться в фоне.
Нужно ли делать общими и промпты с настройками модели?
Нет. Общим должен быть фундамент, а не поведение. Промпты, модели, правила валидации и логика резервного перехода могут оставаться разными, даже если очередь, хранилище и трассировка остаются теми же.
Как понять, что общая настройка всё ещё работает?
Следите за временем ожидания в очереди, общим временем выполнения, уровнем ошибок и ростом хранилища. Ещё считайте, сколько одноразовых инструментов команда добавляет каждый месяц. Если эти показатели растут без понятной причины, общей базе нужно внимание.
Какая простая политика помогает избежать разрастания сервисов?
Напишите короткое правило по умолчанию: новые процессы используют текущую очередь, схему хранения и схему трассировки, пока кто-то не покажет реальное ограничение. Если команде нужен дополнительный сервис, до внедрения должны быть назначены владелец и дата пересмотра.


