Обработка сбоев автоматизации для более надежных бизнес‑процессов
Обработка сбоев автоматизации помогает решать, когда повторять, приостанавливать или отменять шаги, чтобы один сломанный инструмент не распространил неверные данные по процессу.
Содержание
Почему один сбой может сломать весь рабочий процесс
Сбои в рабочих процессах редко бывают аккуратными. Одно приложение завершает свою часть, другое зависает по тайм‑ауту, и процесс останавливается на полпути. Вы не получаете один чистый код ошибки. Вы получаете бизнес‑событие, которое произошло только наполовину.
Вот где начинаются реальные издержки. Запись клиента есть в CRM, но биллинг не открыл счёт. Счёт отправлен, но onboarding не создал задачу. Каждая система рассказывает свою версию событий, и люди продолжают работать с тем экраном, которому больше доверяют.
Небольшие рассогласования распространяются быстро. Продажи видят нового клиента и начинают взаимодействовать. Финансы не видят оплаты и шлёт напоминание. Поддержка не получает задачу по настройке, и клиент ждёт. Потом кто‑то перезапускает рабочий процесс и создаёт второе списание или отправляет то же приветственное письмо дважды. То, что выглядело как один сломанный шаг, превращается в дубликаты действий, невыполненные задачи и испуганных клиентов.
Команды обычно усугубляют это, пытаясь держать всё в движении. Бизнес не может остановиться каждый раз, когда один инструмент ведёт себя плохо минуту — люди закрывают пробелы вручную. Они редактируют записи, ведут заметки в таблицах и переписываются, чтобы заполнить пропущенные шаги. Через несколько часов никто не понимает, какая система сейчас содержит правильную версию.
Именно поэтому обработка сбоев автоматизации важна с самого начала. Первый разрыв часто дешев — дороже обходные пути, которые люди будут применять после него. Как только неверные данные попадут в продажи, биллинг, поддержку и отчётность, их исправление потребует времени и суждения.
Раннее прекращение часто кажется раздражающим, но обычно оно дешевле. Приостановленный процесс даёт одну проблему для проверки. Полуполный процесс оставляет десять маленьких проблем, и каждая из них дольше находится, чем исходная ошибка.
Сначала промапьте рабочий процесс, потом задавайте правила на сбои
Большинство команд начинают с повторных попыток. Это обратный порядок. Если вы не распишете процесс шаг за шагом, вы не сможете отличить безопасный сбой от того, который создаст дублирующую работу, или от того, который тихо испортит данные.
Начните с полного пути в том порядке, в котором он реально выполняется. Включите каждую передачу, даже самые скучные: чтение формы, проверка записи в CRM, создание счёта, отправка письма, открытие задачи onboarding. Небольшие пробелы в карте часто дают большие проблемы позже.
Для каждого шага отметьте шесть вещей: что его запускает, из какой системы он читает, какую систему он изменяет, отправляет ли он деньги или сообщения, можно ли его безопасно повторить и кто отвечает за восстановление при остановке. Обычно одной страницы достаточно.
Источник правды важнее, чем многие ожидают. Если имя клиента начинается в CRM, доверяйте CRM по этому полю. Если биллинг отвечает за статус платежа, не позволяйте другому инструменту угадывать или перезаписывать его после сбоя.
Будьте конкретны в побочных эффектах. «Обновить аккаунт» — слишком расплывчато. «Создать клиента в billing», «списать с карты» и «отправить приветственное письмо» дают представление о том, что может пойти не так и как будет выглядеть очистка. Эта детализация отделяет быструю повторную попытку от настоящей починки.
Безопасным повторам нужно уделить особое внимание. Повторное чтение данных обычно безопасно. Отправить тот же контракт дважды — нет. Списать один и тот же счёт дважды — ещё хуже. Отметьте каждый шаг простым «да» или «нет» для безопасности повтора, чтобы во время инцидента не было споров.
Назначьте человеческий план на случай сбоя. Для каждой точки паузы используйте одну роль: финансы для ошибок с оплатой, sales ops для конфликтов CRM и т. п. Если остановка никому не принадлежит, процесс будет висеть, а неверные данные распространятся дальше.
Такая карта — не бюрократия. Это способ задать правила повторных попыток и пауз без предположений.
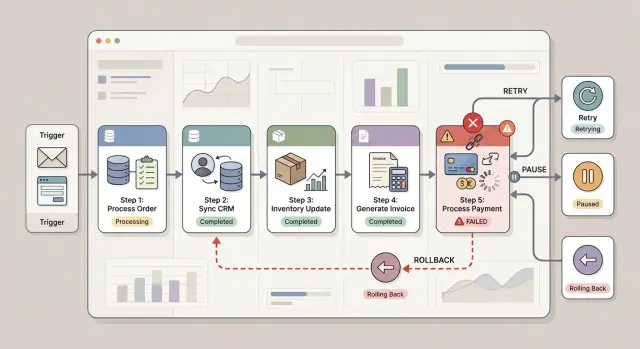
Как выбирать: повторять, приостанавливать или отменять
Хорошая обработка сбоев начинается с простого вопроса: если этот шаг провалился, может ли система попробовать снова, не сделав хуже? Если да — повтор обычно дешевле. Если нет — безопаснее приостановить или отменить.
Используйте повторы для шагов, которые безопасно повторять. Чтение данных, проверка статуса или обновление одной записи без создания дублей обычно подходят. Временный тайм‑аут API, лимит запросов или краткий сетевой сбой не должны втягивать человека в процесс.
Повторы должны иметь ограничения. Установите небольшое число попыток, тайм‑аут для каждого внешнего приложения и короткую паузу между попытками. Три попытки в течение двух минут часто достаточно. Десять попыток в течение часа оставляют висевшие задания и путают всех.
Приостанавливайте процесс, когда неверное действие может навредить клиенту или стоить денег. Биллинг, изменения по контрактам, возвраты, закрытие аккаунта и письма клиенту обычно требуют осторожности. Короткая пауза раздражает, но двойная оплата или ошибочное сообщение — хуже.
Отмена имеет смысл, когда предыдущий шаг уже изменил другую систему. Если процесс создал счёт, открыл аккаунт поддержки или зарезервировал товар, а следующий шаг провалился, может понадобиться компенсационный шаг, который как можно чище отменит предыдущее изменение.
Иногда правильный выбор — полностью остановиться. Если CRM‑ID клиента сохранился некорректно, не продолжайте в биллинг или onboarding. Поздние шаги зависят от точного значения. Неправильный ID может распространиться по трём системам за секунды, и очистка займёт больше времени, чем исходная задача.
Правило простое. Повторяйте безопасные повторы. Приостанавливайте действия, связанные с деньгами, юридией и коммуникацией с клиентом. Отменяйте изменения, которые уже произошли в другой системе. Останавливайтесь, когда последующие шаги зависят от точных данных неудавшегося шага.
Звучит строго — потому что так и есть. Но это экономит время. Один заблокированный процесс — управляемая проблема. Десять процессов, продолжающихся с неверными данными, могут превратить небольшую ошибку в неделю ручной очистки.
Где компенсационные шаги уместны
Используйте компенсации, когда один шаг изменил что‑то реальное, а последующий шаг провалился. В условиях частичных сбоев это часто лучше, чем пытаться откатить весь процесс. Большинство бизнес‑инструментов не поддерживают чистый полный rollback, поэтому нужны маленькие, намеренные действия для отмены.
Хороший компенсационный шаг узкий и легко проверяемый. Если настройка аккаунта провалилась после создания чернового счёта, отмените черновик. Если процесс добавил тег в CRM вроде «ready for onboarding», но onboarding не стартовал — снимите тег. Если система запросила отгрузку, а позже оплата провалилась, аннулируйте запрос на отправку до того, как что‑то уйдёт со склада.
Держите компенсации маленькими. Отменяйте только то, что изменил этот запуск. Логируйте каждое действие отмены с тем же идентификатором прогона. Предпочитайте cancel, void или remove вместо широких delete. Тестируйте каждый компенсационный шаг отдельно.
Идентификатор прогона важнее, чем ожидают многие команды. Когда поддержка проверяет плохой заказ или отсутствующий аккаунт, ей нужно видеть исходное действие и действие отмены, связанные между собой. Без этой ниточки люди начинают догадываться, а догадки — причина, по которой неверные данные остаются в системе неделями.
Держите логику достаточно простой, чтобы один человек мог объяснить её в одном предложении. «Если создание аккаунта провалилось — отменить черновой счёт» понятно. «Запустить скрипт очистки, который пытается исправить биллинг, CRM, доставку и пользовательские записи» рискованно. Большие скрипты часто создают второй беспорядок.
Некоторые действия нельзя вернуть полностью. Если клиент уже получил приветственное письмо или складной работник уже собрал посылку, программно это не удалить. В таких случаях приостановите процесс и передайте человеку с чётким последующим заданием.
Распорядок шагов, который сдерживает сбои
Рабочий процесс ломается дешевле и тише, если вы ставите легко исправимые шаги первыми. Сохраните черновую запись, отметьте статус и залогируйте запрос до того, как совершите публичное или дорогостоящее действие. Если что‑то провалится после этого, у команды будет одно место для проверки и одно понятное решение.
Это особенно важно, когда задействованы деньги, сообщения или внешние системы. Платёж, приветственное письмо или отправленная посылка меняют реальный мир. Откат таких действий медленнее, грязнее и иногда невозможен.
Хороший дефолт прост: сначала создавайте внутреннюю запись, затем зовите внешние сервисы, и отправляйте уведомления клиенту последними. Если биллинг провалится, у вас всё равно останется запись о попытке. Если onboarding упадёт после оплаты, вы точно знаете, к какому аккаунту, платёжной операции и запросу всё привязано.
Сохраняйте ID внешних систем сразу, как только их получите. Если платёжный провайдер вернул charge ID, сохраните его сразу. То же для CRM contact ID, ID тикета поддержки и ID аккаунта в других инструментах. Эти идентификаторы нужны для повторов, возвратов, аудитов и очистки.
Ещё одна распространённая ошибка — запускать следующую ветку до подтверждения, что текущий шаг сработал. Если контакт в CRM всё ещё в состоянии pending, не запускайте параллельно email, billing и onboarding только потому, что API принял запрос. Подождите явного успешного результата. Эта дополнительная пауза часто экономит часы на очистке.
Пронесите один идентификатор прогона через весь поток. Поместите его в внутреннюю запись, в логи и в заметки, которые уходят в другие системы, если это возможно. Когда поддержке нужно отследить плохой запуск, они должны найти всё по одному ID.
Порядок — вот что держит зависимость в своём ряду. При неправильном порядке мелкие ошибки распространяются быстро.
Простой пример: CRM, billing и onboarding
Допустим, клиент покупает ежемесячный план. Процесс начинается с создания контакта в CRM, потому что команде нужен клиентский профиль даже если последующие шаги провалятся.
Далее billing создаёт счёт. Потом provisioning создаёт сам аккаунт, рабочее пространство или подписку. Только после этого отправляйте приветственное письмо. Порядок важен. Не стоит отправлять инструкции по настройке до того, как клиент сможет войти.
Если provisioning провалился, процесс должен остановиться и перевести заказ в состояние паузы. Приветственное письмо остаётся заблокированным, потому что отправка данных доступа для несуществующего аккаунта только создаст тикеты в поддержку.
В этот момент процесс должен либо отменить биллинг, либо пометить счёт на проверку, в зависимости от того, как работает финансовая команда. Если платёж уже прошёл — верните деньги или отправьте на ручную проверку. Если счёт только черновой — пометьте его так, чтобы никто не считал это завершённой продажей.
Посмотрите на другой сценарий. Provisioning сработал, аккаунт активен, но сервис отправки почты упал. Это не повод откатывать аккаунт или отменять платёж. Клиент уже имеет доступ. Повторите отправку письма и оставьте остальное без изменений.
Приостановленный заказ должен попасть в одну команду: operations, support или finance. Они должны проверить, что контакт в CRM совпадает с заказом, выяснить, был ли платёж списан или только создан счёт, проверить, создался ли частичный аккаунт, решить — повторять или возвращать деньги, и выпустить приветственное письмо только после подтверждения работоспособности аккаунта.
Вот как выглядит грамотное восстановление процесса. Одна сломанная зависимость даёт одну обозримую проблему, а не цепочку неверных данных через три системы.
Ошибки, которые быстро распространяют неверные данные
Неверные данные редко начинаются с драматичного краха. Чаще это маленькое правило, которое кажется безобидным и затем повторяется десятки раз.
Одна частая ошибка — повторять платёжный шаг, не проверив, принял ли провайдер первую попытку. Приложение зависает, помечает шаг как провал, повторяет, и клиент списан дважды. Перед любой повторной попыткой по биллингу система должна проверить наличие transaction ID, ответа об успешной операции или иного явного подтверждения состояния.
Другая ошибка — отправлять клиентские письма до завершения настройки. Клиент получает «ваш аккаунт готов», кликает и не видит доступа, плана или данных. Теперь у команды одновременно тикет в поддержку и проблема с данными.
Дизайн статусов тоже создаёт проблемы. Если все ошибки попадают под один общий ярлык «failed», никто не знает, куда смотреть. Ошибки биллинга, задержки синхронизации CRM и тайм‑аута onboarding должны иметь разные состояния. Чёткие имена статусов делают ручное восстановление безопаснее.
Правила тайм‑аутов тоже расходятся между связанными системами. Одна система сдаётся через пять секунд, другая ждёт 45, а третья повторяет в течение десяти минут. Такое рассогласование создаёт дублированные записи, ложные провалы и гонки. Настраивайте эти правила вместе, а не по одному приложению.
Логи важнее, чем многие думают. Когда запуск идёт плохо, людям нужна достаточная детализация, чтобы решить: повторять, приостанавливать или исправлять данные вручную. Записывайте request/transaction ID, последний выполненный шаг, точную ошибку зависимости и любые ручные изменения, сделанные по ходу.
Пропуск ручных заметок — тихая, но дорогая ошибка. Коллега приостанавливает запуск, редактирует запись клиента и ничего не пишет. Через два дня кто‑то другой возобновляет задачу и толкает неверные данные в три системы.
Бырые проверки перед включением
Большинство проблем с обработкой сбоев начинается до первого живого запуска. На диаграмме процесс выглядит чистым, но при повторе появляется второй счёт или при паузе одна система изменена, а другая осталась нетронутой.
Перед запуском пометьте каждый шаг как «безопасно повторять», «только один раз» или «никогда не повторять». Запишите точное изменение, которое делает каждый шаг в каждой системе. Решите, кто получает оповещение, как быстро нужно действовать и когда повторы должны остановиться. Затем определите первое действие оператора после паузы. В большинстве случаев это: проверить последний успешный шаг, подтвердить, изменились ли данные где‑то ещё, и выбрать — возобновить, компенсировать или завершить вручную.
Протестируйте три сценария до включения: один нормальный успех, один временный сбой и один случай с некорректным вводом. Если команда может объяснить следующий шаг в каждом случае без спора, процесс, вероятно, в разумном состоянии. Если нет — исправьте это до поступления реальных данных.
За чем следить после запуска
Большинство проблем с процессами проявляются в первые недели как мелкие раздражения, а не крупные аварии. Шаг чаще оказывается в паузе, повтор работает лишь наполовину, поставщик начинает отвечать медленнее. Если игнорировать паттерн, процесс будет продолжать работать, а неверные данные тихо накапливаться.
Следите за несколькими показателями: частота пауз по шагам, успех повторной попытки после первой ошибки и время восстановления от сбоя до чистого завершения. Эти числа покажут слабое место. Если один API вызывает большинство пауз — исправьте эту зависимость в первую очередь. Добавление логики поверх ненадёжного шага обычно делает бардак сложнее.
Разбирайте неудачные запуски вручную каждую неделю. Читайте логи, проверяйте входы и выходы и ищите повторы. Хотите понять, ломается ли одно и то же поле, могут ли пользователи восстановить процесс сами и оставляют ли компенсационные шаги записи в чистом состоянии.
Будьте строги к шумным зависимостям. Если провайдер биллинга часто тайм‑аутит, или CRM начинает отклонять обновления — решите эту проблему прежде, чем добавлять ветки или последующие шаги. Одна нестабильная служба может потратить часы у остальных частей процесса.
Также имеет смысл убрать шаги, которые добавляют риск и мало пользы. Если ненужная синхронизация создаёт дубли, или обновление статуса вводит пользователей в заблуждение при запоздалой доставке — уберите его. Короткий рабочий процесс часто безопаснее.
Поставщики меняют лимиты, правила полей и шаблоны ответов чаще, чем команды ожидают. Обновляйте правила повторов и пауз при таких изменениях. Процесс, который останавливается рано и восстанавливается за десять минут, гораздо безопаснее, чем тот, который продолжает проталкивать неверные данные в финансы, CRM и onboarding.
Следующие шаги для более надёжной автоматизации
Начните с одного процесса, который уже создаёт ручную очистку. Обычно там легче увидеть стоимость и быстрее экономия времени от улучшений. Обработка заказов, создание счетов, передача лидов и адаптация сотрудников — типичные проблемные места.
Опишите правила на сбои до добавления новых шагов. Решите, какие действия можно безопасно повторять, какие должны приостанавливаться для проверки и какие требуют компенсационных шагов. Если ждать до запуска, люди чаще будут латать ошибки вручную, и плохой паттерн закрепится.
Затем сознательно тестируйте поломки. Отключите одно приложение, отправьте неполные данные, замедлите API и вызовите тайм‑аут от инструмента ИИ. Нужно понять, удерживает ли процесс ущерб или распространяет его.
Держите первую версию маленькой. Один рабочий процесс с понятными правилами повторов и пауз научит больше, чем большой передел по десяти системам.
Если ваш процесс охватывает CRM, billing, поддержку, инфраструктуру и инструменты ИИ, внешний аудит может помочь. Oleg Sotnikov at oleg.is работает как фракционный CTO и советник стартапов по архитектуре продукта, инфраструктуре и практическим операциям с AI — это упрощает обзор рабочих процессов, привязанный к реальной продакшен‑работе.
Часто задаваемые вопросы
What is a partial failure in a workflow?
Частичный отказ происходит, когда один шаг завершается, а последующий — нет. В результате у вас есть «половинчатое» бизнес‑событие: запись в CRM без биллинга или счёт без запуска onboarding. Такое рассогласование требует дополнительной ручной работы, приводит к дублям и путанице в командах.
When should I retry a failed step?
Повторяйте шаг только если повторная попытка не создаст второго реального действия. Обычно это чтение данных, проверка статуса или обновление одной записи. Ограничьте повторы коротким тайм‑аутом и небольшим числом попыток, чтобы задания не висели часами.
When should I pause the workflow instead of retrying?
Пауза нужна, когда дальнейшее действие может стоить денег, изменить юридические условия, закрыть аккаунт или связаться с клиентом. Короткая остановка обычно дешевле, чем неверный платёж или ошибочное письмо. Назначьте одну команду‑владельца, чтобы паузу не пропустили.
What does a compensation step do?
Компенсационный шаг отменяет одно предыдущее изменение из того же прогона. Например: если billing создал черновой счёт, а настройка аккаунта провалилась, отмените черновой счёт. Делайте отмены узкими и привязывайте их к тому же идентификатору прогона, чтобы поддержку было просто трассировать.
What order should I use for workflow steps?
Сначала создавайте внутреннюю запись и состояние, которое команда может проверить и исправить. Затем вызывайте внешние сервисы, а уведомления клиенту отправляйте последними. Такой порядок держит ошибку в границах и даёт одно место для расследования.
How do I avoid duplicate charges and duplicate emails?
Проверяйте, не выполнилась ли первая попытка успешно, прежде чем повторять действия, связанные с оплатой или отправкой сообщений. Сохраняйте ID провайдеров сразу и используйте их для подтверждения состояния. Если нельзя точно доказать, что предыдущая попытка упала, поставьте задачу на паузу и проверьте вручную.
Why should every workflow run have a run ID?
Идентификатор прогона даёт вашей команде возможность проследить весь путь одного запуска через логи и связанные инструменты. Когда что‑то ломается, поддержку достаточно искать по одному ID, чтобы увидеть, что произошло сначала, где произошёл отказ и какие действия пытались выполнить для отката.
Who should own a paused workflow?
Назначьте каждую точку паузы отдельной роли до запуска. Финансы — за платёжные ошибки, sales ops — за конфликты CRM, поддержка или operations — за проблемы с onboarding. Когда кто‑то один владеет остановкой, восстановление идёт быстрее и некорректные данные меньше распространяются.
What should I log to make recovery easier?
Логируйте последний успешно выполненный шаг, точную ошибку, все внешние ID систем и любые ручные изменения коллег. Это даёт следующему оператору контекст для решения: повторять, компенсировать или завершать задачу вручную. «Тонкие» логи превращают небольшую ошибку в долгое расследование.
How should I test failure handling before launch?
Запустите три теста до выхода в прод: один успешный сценарий, один с временным отключением и один с некорректными входными данными. Смоделируйте тайм‑аут, отключите приложение и отправьте неполные данные намеренно. Если команда без спора объясняет следующий шаг в каждом случае — правила, скорее всего, надёжны.


