Обработка backpressure в Node.js для маршрутов загрузки и экспорта
Обработка backpressure в Node.js помогает загрузкам и экспортам не забивать RAM. Разберём работу потоков, временных файлов и передачи задач в очередь, которые выдерживают нагрузку.
Содержание
Что идёт не так, когда большие запросы попадают в один процесс
Один процесс Node.js может отлично выглядеть в тестах, а потом упасть, когда в неподходящий момент прилетает одна большая загрузка или экспорт. Проблема начинается тогда, когда приложение читает данные быстрее, чем успевает записать их куда-то ещё — на диск, в object storage, в базу данных или в сокет клиента.
Когда это происходит, данные накапливаются в памяти. Буферы растут, сборщик мусора работает активнее, а время ответа начинает плавать. Если таких запросов приходит несколько одновременно, RAM быстро подскакивает, и процесс может заметно замедлиться или даже упасть.
Небольшие запросы эту проблему скрывают. Изображение на 200 КБ или короткий JSON-экспорт завершается так быстро, что лишняя буферизация почти не заметна. А вот загрузка видео на 4 ГБ или длинный CSV-экспорт на 800 000 строк — уже совсем другая история. Такая работа длится достаточно долго, чтобы любое несоответствие между скоростью чтения, записи и сети превратилось в давление на память.
Загрузки и экспорты ломаются по-разному, но схема одна и та же. При загрузках сервер может читать тело запроса в память, пока антивирусная проверка, изменение размера или передача дальше не успевают за ним. При экспортах приложение может собрать весь файл в RAM ещё до отправки, хотя клиент скачивает его гораздо медленнее, чем сервер создаёт.
Один медленный клиент может всё ухудшить. Если ваш код генерирует строки CSV так быстро, как база данных их отдаёт, а браузер читает в разы медленнее, процесс превращается в комнату ожидания. Каждый лишний кусок данных лежит в памяти, пока сокет не сможет принять следующий.
Без хорошей обработки обратного давления в Node.js один тяжёлый запрос может задеть и остальной трафик. Проверки здоровья начинают истекать по таймауту. Остальные пользователи ждут дольше. Процесс, который казался стабильным на обычных API-запросах, внезапно начинает вести себя плохо при работе с файлами.
Цель проста: держать память ровной и поведение предсказуемым. Большие загрузки должны проходить через процесс маленькими кусками. Большие экспорты должны покидать процесс маленькими кусками. Когда работу нельзя завершить в рамках обычного запроса, приложение должно передать её дальше, а не делать вид, что один процесс способен переварить всё.
Как работает backpressure в Node.js
Backpressure — это простая идея о том, что данные могут приходить быстрее, чем ваш код успевает отправить их дальше. Маршрут загрузки может читать байты от клиента быстрее, чем сервер пишет их на диск. Маршрут экспорта может получать строки из базы быстрее, чем клиент успевает скачивать ответ. Когда этот разрыв по скорости растёт, память заполняется буферизованными кусками.
Хорошая обработка обратного давления в Node.js держит этот разрыв под контролем. У каждого потока есть сторона чтения и сторона записи. Сторона чтения забирает данные откуда-то — например, из HTTP-запроса или курсора базы данных. Сторона записи отправляет данные куда-то — например, во временный файл, object storage или HTTP-ответ. Проблемы начинаются тогда, когда чтение идёт на полной скорости, а запись тормозит.
Node даёт потокам встроенный способ справляться с этим. Когда записываемый поток получает больше данных, чем готов удержать, write() возвращает false. Это поток говорит: «подожди немного». В этот момент читающая сторона должна притормозить. Когда записывающая сторона догоняет, она отправляет событие drain, и чтение может продолжиться.
Если вы используете pipe() или pipeline(), Node обычно сам управляет этим циклом паузы и возобновления. Именно поэтому конвейеры потоков намного безопаснее, чем загрузка всего файла в память через буферы или сбор кусков в массив. При правильном pipeline данные проходят через процесс небольшими частями, а не накапливаются.
highWaterMark определяет, когда поток начинает оказывать сопротивление. Думайте об этом как о пороге внутреннего буфера, а не о волшебном решении. Большое значение может отсрочить сигнал тревоги, но оно же может сделать всплески памяти сильнее. Большинству команд стоит воспринимать его как небольшой инструмент настройки, а не как ответ на обработку больших запросов.
Медленный клиент хорошо показывает это на экспортных эндпоинтах. Ваш код может быстро генерировать строки CSV, но сетевой сокет отправляет их медленно. Если поток ответа начинает тормозить, а код игнорирует это, процесс продолжает складывать строки в память. Если же код уважает поток, Node замедляет источник данных, и процесс остаётся стабильным.
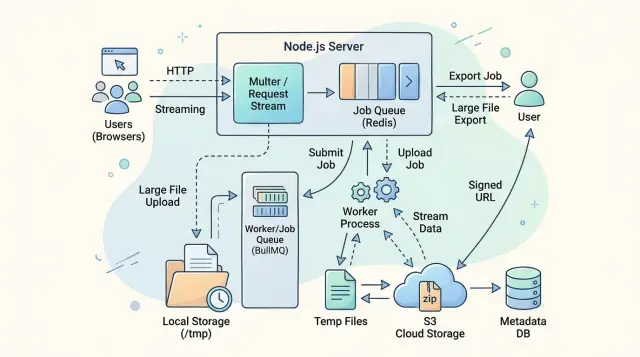
Что выбрать: потоки, временные файлы или очередь
Выбирайте самый простой путь, который удерживает память на ровном уровне. На практике это значит: используйте поток, когда работа может идти за один проход; временный файл, когда одним и тем же данным нужно пережить несколько этапов; и очередь, когда HTTP-запрос не должен тащить на себе всю задачу целиком.
Прямое потоковое выполнение лучше всего подходит для загрузок, которые идут от клиента к одному месту назначения без большой дополнительной обработки. Если приложение читает загруженный файл и сразу пишет его в object storage, в другой сервис или в компрессор, который умеет замедлять входящий поток, память обычно остаётся стабильной. Это самая чистая форма обработки обратного давления в Node.js: медленный получатель заставляет быстрого отправителя подождать.
Временные файлы помогают тогда, когда поток превращается не в простой pipe. Проверка на вирусы, определение типа файла, создание миниатюры, валидация CSV или повторная попытка после сетевой ошибки часто требуют одни и те же байты больше одного раза. Запись на диск сначала стоит некоторого I/O, но это часто дешевле, чем держать буфер на 500 МБ в памяти или просить пользователя загружать файл заново после сбоя на третьем шаге.
Очереди подходят для долгих экспортов и медленной работы с внешними системами. Если экспорт занимает 40 секунд, забирает данные кусками, собирает zip и загружает результат, веб-запрос не должен нянчиться с этой задачей всё время. Положите её в очередь, верните идентификатор задачи и дайте воркеру сделать тяжёлую работу. Так один тяжёлый экспорт не заставит все остальные запросы в том же процессе тормозить.
Простые правила передачи задачи
Большинству команд хватает нескольких скучных правил:
- Используйте прямой поток, если следующее место назначения может читать примерно с той же скоростью, с которой вы получаете данные.
- Используйте временный файл, если у задачи несколько этапов, возможен повторный запуск или нужно читать один и тот же файл ещё раз.
- Используйте очередь, если работа может пережить сам запрос, занимает больше нескольких секунд или зависит от сервиса с ограничением по скорости.
- Уходите от прямой обработки запроса, если размер файла или объём экспорта превышает комфортный для вашего процесса лимит.
Небольшой пример делает разделение понятнее. Загрузка изображения на 20 МБ, которая сразу идёт в хранилище, должна быть потоковой. Таблица на 300 МБ, которой нужны проверка, парсинг и повтор после нестабильного вызова стороннего сервиса, сначала должна попасть во временный файл. Полный экспорт аккаунта, который может выполняться несколько минут, должен стать задачей в очереди, даже если сам итоговый файл не очень большой.
Правила лучше задать до того, как трафик вырастет. Ограничения по размеру, по времени и по скорости внешних систем дают приложению чёткую точку передачи. Без этого каждый маршрут сначала выглядит как простой обработчик запроса, а потом постепенно превращается в проблему с памятью.
Безопасный поток загрузки по шагам
Когда ломается маршрут загрузки, обычно причина простая: обработчик читает данные быстрее, чем диск или object storage успевает их принимать. Хорошая обработка обратного давления в Node.js держит память ровной, перемещая байты маленькими порциями, рано отклоняя плохие загрузки и удаляя частичные файлы, если что-то пошло не так.
-
Проверьте запрос, прежде чем начать запись. Посмотрите на авторизацию,
content-lengthи заявленныйcontent-type. Если маршрут допускает файлы до 100 МБ, а заголовок говорит о 2 ГБ, сразу отклоняйте запрос. Если важен тип файла, проверьте и первые байты. Заголовки врут чаще, чем кажется. -
Сразу пишите тело запроса в место назначения. Это может быть временный файл, постоянный диск или поток object storage. Не собирайте всю загрузку в
Bufferтолько потому, что так проще парсить. Используйтеstream.pipeline()или аналогичный путь, который соединяет поток запроса с записью и позволяет Node сам управлять давлением между ними. -
Пусть медленная сторона задаёт скорость. Если запись на диск замедляется, записываемый поток сигнализирует, что ему нужна пауза. Правильный pipe или pipeline уважает этот сигнал и перестаёт тянуть новые данные, пока запись не догонит. В этом и разница между стабильным маршрутом и процессом, который разгоняется до 2 ГБ RAM на нескольких больших загрузках.
-
Чистите все неудачные сценарии. Если клиент отключился, если поток записи дал ошибку или валидация провалилась после нескольких кусков, закройте потоки и удалите частичный временный файл. Незавершённые файлы легко пропустить в тестах, а в продакшене они тихо забивают хранилище.
Хороший маршрут загрузки также разделяет «принятие байтов» и «обработку файла». Сначала сохраните файл, а потом передайте антивирусную проверку, изменение размера изображения или парсинг CSV в очередь, если работа занимает время. Oleg Sotnikov часто подталкивает команды именно к такому разделению, потому что оно не позволяет одному Node.js-процессу делать слишком много одновременно.
Небольшой пример всё делает ясным. Пользователь загружает видео на 600 МБ через медленное соединение. Сервер проверяет лимит, пишет тело запроса во временный файл, делает паузу при просадке диска и удаляет файл, если вкладка браузера закрывается на середине. Запрос остаётся скучным, а именно этого и нужно добиваться.
Безопасный поток экспорта по шагам
Экспорты ломаются, когда один запрос пытается собрать весь файл в памяти ещё до отправки первого байта. Более безопасный подход держит объём данных в памяти маленьким, ставит жёсткие ограничения на то, что может запросить один клиент, и выносит тяжёлую работу из веб-процесса.
Начните с формы запроса. Требуйте чёткие фильтры, фиксированный диапазон дат и ограничение по строкам. Если кто-то просит «все данные» за несколько лет, не оставляйте это в живом запросе. Отклоните, сузьте или отправьте в фоновую задачу.
Хорошо работает простая схема:
- Разрешайте live-экспорты только тогда, когда запрос достаточно мал, чтобы завершиться быстро. Например, CSV только за последние 30 дней с лимитом, скажем, 50 000 строк.
- Забирайте строки кусками или через курсор. Как только приходит очередная порция, форматируйте её и сразу пишите в ответ.
- Следите за backpressure. Если
write()возвращаетfalse, перестаньте тянуть новые строки, пока не сработаетdrain. - Переносите большие или медленные экспорты в фоновую задачу. Пусть воркер пишет файл во временное хранилище, а потом сообщает пользователю, где его забрать, когда всё будет готово.
Именно этот средний шаг важнее всего для обработки обратного давления в Node.js. База данных, CSV-форматер и HTTP-ответ работают на разной скорости. Если клиент скачивает медленно, а код продолжает читать строки, память растёт очень быстро. Когда вы ждёте drain, процесс остаётся спокойным вместо того, чтобы накапливать буферизованные данные.
Для очень больших экспортов держите запрос коротким. Возвращайте идентификатор задачи, endpoint статуса или простое сообщение «мы уведомим вас, когда всё будет готово». Воркер может сохранять прогресс — например, количество обработанных строк, текущее состояние и размер файла, — чтобы интерфейс показывал что-то полезное.
Временные файлы помогают, потому что дают воркеру фиксированное место для записи, не держать весь экспорт в RAM. Они же упрощают повторные попытки. Если задача ломается на середине, можно удалить частичный файл, залогировать ошибку и начать заново чисто.
Есть ещё одно правило, которое легко забыть: удаляйте старые экспортные файлы. Задайте срок жизни, чистите их по расписанию и ограничьте число экспортных задач, которые один аккаунт может запускать одновременно. Так один активный клиент не заполнит диск и не займёт всех воркеров.
Реалистичный пример
Загрузка при слабом соединении
Клиент начинает загружать видео на 2 ГБ из поезда, где мобильный интернет то пропадает, то снова появляется. Соединение то ускоряется, то замедляется. Если маршрут загрузки читает быстрее, чем успевает писать, память растёт, и процесс Node.js начинает бороться сам с собой.
Более безопасный маршрут сразу передаёт тело запроса во временный файл. Поток записывает куски на диск по мере их поступления, а backpressure замедляет чтение, когда диск или файловая система не успевают. Память остаётся ровной, потому что процесс никогда не пытается удержать всё видео целиком.
Временный файл особенно полезен в момент, когда запрос ещё активен и ненадёжен. Если пользователь отключится на середине, приложение удалит частичный файл и пойдёт дальше. Если загрузка завершится, приложение сможет проверить размер, тип и контрольную сумму, прежде чем делать тяжёлую обработку.
После этого включается передача в очередь. Проверка видео, создание миниатюр и транскодирование не должны жить в цикле запроса. API сохраняет файл, создаёт задачу и возвращает понятный статус. Пользователь сначала видит стабильный прогресс загрузки, а потом простой статус «обрабатывается». Остальные запросы остаются быстрыми, потому что одно большое видео больше не блокирует тот же процесс.
Экспорт в загруженный рабочий день
Теперь сотрудник финансового отдела просит выгрузить заказы за шесть месяцев в CSV в 16:55, как раз когда остальные люди ещё работают в приложении. Вот где команды часто делают плохой выбор. Они выбирают всё сразу, собирают в памяти огромную строку, а потом пытаются отправить её одним ответом.
Лучше потоково читать строки из базы и записывать их во временный CSV-файл. Такой файл помогает, когда экспорт достаточно большой, чтобы выйти за пределы памяти, но всё ещё достаточно маленький, чтобы завершиться на одном воркере быстро. Пользователь подождёт немного, а потом скачает готовый файл без лишней нагрузки на приложение.
Если экспорт может занять несколько минут или вытянуть миллионы строк, очередь подходит лучше. Приложение принимает запрос, создаёт задачу экспорта и позволяет воркеру собирать CSV вне веб-процесса. Пользователь видит «подготовка экспорта» вместо зависшего индикатора или таймаута.
Когда обработка обратного давления в Node.js работает хорошо, люди замечают именно спокойные части. Прогресс идёт. Статусы имеют смысл. Большая загрузка или экспорт кажется медленнее маленького, но не делает остальной продукт сломанным.
Ошибки, которые вызывают скачки памяти
Большинство скачков памяти появляется из-за работы, которую сервер вообще не должен делать в RAM. Большая загрузка или экспорт может оставаться стабильной, когда процесс передаёт данные маленькими кусками. Опасность начинается тогда, когда код держит в памяти целые файлы, целые наборы результатов или слишком много задач одновременно.
Первая ошибка — буферизовать всё тело запроса перед записью куда-либо. Часто это происходит случайно из-за удобного middleware, самописных сборщиков на req.on("data") или парсеров, которые сначала читают всё, а потом уже действуют. Один файл на 500 МБ может выглядеть нормально в тестах. Пять загрузок одновременно могут загнать один процесс Node.js в бесконечный цикл сборки мусора или даже в падение.
Ещё одна частая проблема — выполнять все тяжёлые шаги внутри пути запроса. Команды принимают загрузку, потом распаковывают её, парсят, проверяют, меняют размер и, возможно, сжимают снова, прежде чем ответить. Каждый шаг может создать ещё одну копию тех же данных. Память растёт быстро, а клиент всё это время держит соединение открытым.
Экспорты ломаются похожим образом. Маршрут запрашивает все строки, складывает их в массив, превращает массив в CSV или JSON и отправляет только после того, как готова последняя строка. Это значит, что процесс держит одновременно строки базы, отформатированный результат и часто ещё и буферы компрессии. Для больших отчётов этого достаточно, чтобы потребление памяти экспортным эндпоинтом из безопасного превратилось в неприятное.
Несколько промахов усугубляют ситуацию:
- Сервер игнорирует события
abortedилиcloseи продолжает работать после ухода пользователя. - Временные файлы остаются на диске после сбоев, и повторные попытки накапливаются.
- Очередь принимает неограниченное число задач или неограниченный общий объём данных.
- Один воркер берёт слишком много крупных задач одновременно.
Параллельность обычно вреднее, чем размер файла. Если одной тяжёлой задаче нужно 150 МБ на парсинг, буферизацию и чтение из базы, шесть задач могут съесть почти 1 ГБ, и это ещё без учёта самого Node.js. Поэтому правила передачи в очередь так важны. Поставьте жёсткий лимит на активные задачи, отклоняйте или откладывайте излишек и держите большие работы подальше от веб-процесса.
Хорошая обработка обратного давления в Node.js — это в основном дисциплина. Используйте поток, когда можете; пишите во временное хранилище, когда нужно; останавливайте работу, когда клиенты отключаются; и относитесь к лимитам очереди как к защите, а не как к необязательной детали.
Быстрые проверки перед релизом
Хорошая настройка обработки обратного давления в Node.js должна вести себя спокойно под нагрузкой. Если в один процесс попадает загрузка на 5 ГБ, RAM должна оставаться примерно в привычных пределах, а не расти вместе с размером файла. Это первая проверка, и она быстро ловит много плохого кода загрузки.
Запустите один тест на загрузку с маленьким файлом, а потом ещё один — с гораздо большим. Следите за памятью процесса в обоих случаях. Если память растёт почти линейно с размером загрузки, значит, где-то всё ещё слишком много данных буферизуется в пользовательском пространстве.
Медленные клиенты создают другую категорию проблем. Пользователь может начать загрузку, потерять соединение и оставить после себя наполовину записанный временный файл. Приложение должно заметить сломанный поток, закрыть файловые дескрипторы и удалить этот временный файл в пределах понятного таймаута. Если очистка происходит только на счастливом пути, использование диска будет незаметно расти всю неделю.
Экспорты требуют той же дисциплины. Когда база данных тормозит, ваш маршрут экспорта не должен продолжать вытягивать строки как можно быстрее и складывать их в память. Он должен ставить паузу, снижать скорость чтения или передавать работу в очередь. Если замедление долго не проходит, лучше отклонять новые экспорты или ставить их в очередь, чем делать вид, что процесс выдержит бесконечное давление.
Короткий список перед выпуском помогает больше, чем длинный дизайн-документ:
- Загрузите файл намного больше обычных тестовых данных и проверьте, что RAM остаётся почти ровной.
- Замедлите соединение клиента и убедитесь, что приложение удаляет брошенные временные файлы.
- Искусственно замедлите базу данных и проверьте, что экспортные задачи ставятся на паузу, быстро падают или корректно уходят в очередь.
- Проверьте правила воркеров: максимальный размер, максимальное время выполнения и число повторных попыток.
- Откройте дашборд и убедитесь, что он показывает RAM, открытые файлы, глубину очереди и возраст задач.
Эти правила для воркеров важнее, чем многие ожидают. Задача без лимита по размеру может съесть диск. Задача без ограничения по времени может зависнуть навсегда. Правило повторных попыток без потолка может превратить один неудачный экспорт в пятьдесят новых неудачных экспортов.
Дашборды должны отвечать на простые вопросы за несколько секунд. Память ползёт вверх? Открытых файлов становится всё больше и они не уменьшаются? Глубина очереди застряла? Некоторые задачи намного старше остальных? Если вы не можете быстро ответить на эти вопросы, первый инцидент в продакшене будет казаться медленнее и запутаннее, чем должен.
Что делать дальше
Начните с цифр, а не с догадок. Измерьте самый большой файл, который принимает ваше приложение, самый крупный экспорт, который люди реально запрашивают, и уровень памяти, до которого доходит ваш процесс Node.js в эти моменты. Один день с реальными числами может сэкономить недели случайных исправлений.
Первую версию держите простой. Вам не нужна идеальная система в первый же день. Вам нужны понятные границы, которые говорят приложению, что делать, когда запрос остаётся маленьким, становится большим или превращается в задачу, которую вообще не стоит выполнять внутри самого запроса.
Запишите эти правила там, где их увидит команда:
- Стримьте небольшие и средние загрузки прямо в хранилище, когда клиент успевает за скоростью.
- Сбрасывайте более крупные payload’ы во временный файл, когда память начинает расти.
- Передавайте длинные экспорты в очередь, если они занимают больше времени, чем должен занимать обычный запрос.
- Отклоняйте файлы или диапазоны экспорта, которые выходят за ваши лимиты.
- Настройте таймауты и правила очистки для незавершённой работы.
Потом протестируйте неприятные сценарии. Маршрут может выглядеть нормально с одним быстрым клиентом на ноутбуке и всё равно развалиться в продакшене. Запустите одну медленную загрузку, потом ещё две. Начните два больших экспорта, пока одна загрузка всё ещё не закрыта. Следите за памятью, использованием временного диска, временем запросов, глубиной очереди и очисткой после отмены запросов.
Небольшая команда может сделать это с помощью короткого чек-листа. Выберите три размера файлов, два размера экспорта и один профиль медленной сети. Повторяйте одни и те же тесты после каждого изменения. Если память резко растёт или не возвращается назад, остановитесь и исправьте это до добавления новых функций.
Если вы работаете над обработкой обратного давления в Node.js, эта дисциплина важнее, чем хитрый код. Большинство скачков памяти происходит из-за отсутствия лимитов, размытых правил передачи задач или слишком вежливых тестов.
Если вашей команде нужен ещё один взгляд со стороны, Oleg Sotnikov может помочь спроектировать такие потоки, провести ревью архитектуры Node.js и укрепить production-операции без лишнего стека инструментов. Это особенно полезно, когда загрузки, экспорты, очереди и инфраструктура уже выглядят запутанными, а нужны простые правила, которые выдерживают нагрузку.


