Крупное обновление Postgres с логической репликацией
Спланируйте крупное обновление Postgres с логической репликацией: измеряйте лаг, отрепетируйте переключение, защитите записи и держите план отката наготове.
Содержание
Почему это обновление всё ещё может провалиться
Логическая репликация снижает риск крупного обновления Postgres, но сама по себе не делает переход безопасным. Репликация может работать днями без ошибок, а переключение всё равно может сорваться. Копировать строки — самая простая часть. А вот переключить живой трафик так, чтобы не потерять записи и не запутать приложение, обычно и оказывается самой сложной задачей.
Большинство проблем всплывает в мелочах. Новая версия Postgres может изменить планы запросов, поведение extension, значения по умолчанию и производительность под нагрузкой. Реплика может выглядеть здоровой, хотя одна медленная таблица отстаёт, один sequence уехал, или один фоновый воркер всё ещё пишет в старый primary.
Самый большой риск — в потоке записи. Чтения можно перевести первыми, и всё будет выглядеть нормально. С записью так не работает. Если приложение отправит даже несколько секунд трафика в старую базу после начала переключения, можно получить пропавшие заказы, дублирующиеся задачи или пользователей, которые видят данные в обратную сторону.
Ещё одна ловушка — лаг. Команды часто проверяют только то, что репликация вообще идёт, и на этом останавливаются. Этого мало. Нужно понимать, успели ли скопироваться все важные таблицы, видны ли недавние записи на target и готовы ли значения sequence для новых inserts.
Что проверить до построения replica
На схеме крупное обновление выглядит просто. На практике логическая репликация переносит только часть картины. Прежде чем что-то строить, запишите, что работает на текущем кластере и что новый кластер обязан повторить.
Начните с версий, extensions и возможностей базы. Проверьте версию source Postgres, затем перечислите все установленные extensions и их версии. Убедитесь, что target-версия поддерживает тот же набор extensions, типы данных и возможности таблиц, включая partitioning, generated columns, identity columns и custom collations. Маленькие различия здесь позже превращаются в неудачные синхронизации.
Затем посмотрите на сами таблицы. Логическая репликация лучше всего работает там, где у каждой опубликованной таблицы есть primary key. Обновления и удаления должны надёжно находить нужную строку на subscriber. Если у таблицы нет primary key, возможно, придётся добавить его или выставить replica identity full. Это работает, но обычно делает репликацию медленнее и тяжелее.
Некоторые объекты требуют отдельной обработки. Sequence не выравниваются через обычную логическую репликацию, поэтому их последние значения нужно захватить и применить ближе к cutover. Large objects тоже требуют отдельного внимания, потому что логическая репликация переносит их не так, как строки таблиц. Важны и schema changes. Если во время окна миграции команда будет запускать DDL, source и target могут быстро разъехаться.
Проверки ресурсов скучные, но именно они спасают от неприятных сюрпризов. Первичное копирование может сильно нагрузить диск, CPU и сеть на обоих кластерах. Убедитесь, что source выдержит эту нагрузку без вреда для production-трафика, а на target хватает места для данных, индексов, WAL и кратких всплесков нагрузки.
Заранее назначьте ответственных и зафиксируйте это. Определите человека, который может остановить записи приложения, человека, который проверит финальный lag, человека, который обновит connection settings или маршрутизацию трафика, и человека, который скажет go или no-go. Команды постоянно пропускают этот шаг, а потом 20 минут ждут подтверждения в самый неудобный момент.
Как настроить логическую репликацию
Постройте target-кластер на новой версии Postgres до того, как коснётесь production-трафика. Задайте ему ту же locale, encoding и базовые настройки, которые вы хотите сохранить после обновления. Кластер, который выглядит "почти так же", всё равно может сломаться, если отличие окажется в неправильном месте.
До старта репликации скопируйте структуру, а не данные. Создайте на target роли, права, схемы и нужные extensions, чтобы subscriber мог спокойно принимать входящие изменения. Если extension есть на source, но нет на target, сначала исправьте это. То же самое сделайте с default privileges, custom types и любыми таблицами, которые принадлежат ролям, ещё не созданным на target.
Логическая репликация переносит строки, а не всю настройку базы. Schema-only dump часто оказывается самым безопасным способом загрузить таблицы, индексы, ограничения и views в новый кластер. Сохраните этот скрипт вместе с точными настройками, которые вы меняли на обеих сторонах. Во время репетиции записывайте каждую команду, каждый параметр и каждое исправление. Память начинает подводить поздно ночью.
Выбирайте таблицы осторожно
Не добавляйте все таблицы в первый проход по умолчанию. Разделите их по тому, как они себя ведут. Обычные таблицы приложения обычно можно копировать сразу. Очень большие таблицы могут потребовать отдельного окна для backfill. Загруженные таблицы с записями требуют более строгой проверки lag. Таблицы кэша или аудита иногда безопаснее пересобрать позже. Значения sequence всегда требуют отдельного шага.
После этого создайте publication на source для таблиц, которые нужно реплицировать, а затем создайте соответствующий subscription на target. Начните с малого в staging. Убедитесь, что inserts, updates и deletes приходят правильно. Только после этого расширяйте охват. Если используете row filters или отдельные publications по схемам, делайте названия простыми и понятными. Простые имена уменьшают шанс ошибки во время cutover.
Прогоните всю последовательность минимум один раз до production. Засеките время initial copy, измерьте lag при обычной нагрузке и отметьте таблицы, которым нужен особый подход. Письменный runbook лучше, чем гениальный план, почти всегда.
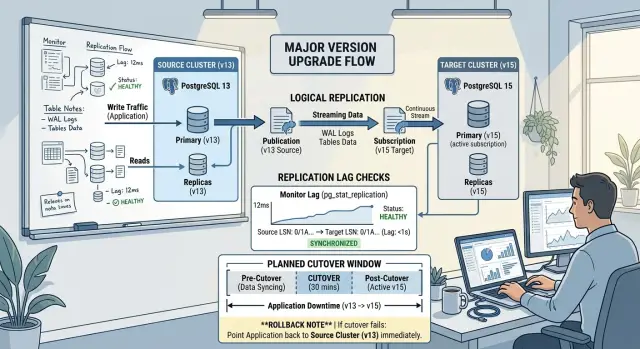
Как следить за lag и состоянием синхронизации
Во время обновления команды часто смотрят на один зелёный статус и пропускают настоящую проблему. Логическая репликация может выглядеть здоровой, хотя одна нагруженная таблица всё ещё отстаёт, одно копирование таблицы ещё идёт, или sequence уже уехал настолько, что после cutover сломает inserts.
Следите за lag двумя способами. Измеряйте временной лаг между изменением на source и тем же изменением на subscriber. Если ваши инструменты могут оценивать backlog в байтах, держите его на той же панели. Время показывает, что почувствуют пользователи. Байты показывают, успеет ли subscriber догнать после всплеска записей.
Синхронизация на уровне таблиц не менее важна, чем общий статус subscription. Проверяйте, закончила ли каждая таблица начальное копирование и перешла ли в обычную репликацию. Одна горячая таблица может отставать, а сама subscription при этом всё ещё будет выглядеть нормально. В Postgres для этого помогают представления вроде pg_stat_subscription и pg_subscription_rel, которые показывают и apply-сторону, и состояние каждой таблицы.
Полезен простой ритм. Во время тестов проверяйте временной лаг и backlog в байтах каждые несколько минут. Смотрите состояние копирования по таблицам, пока все важные таблицы не перейдут в стабильную репликацию. Каждый день сравнивайте row counts на самых загруженных таблицах. Перед каждой репетицией записывайте значения sequence на source и target. И самое главное — заранее зафиксируйте, какой lag для запуска допустим.
Row counts помогают поймать тихие дыры в данных, которые графики lag не показывают. Начните с таблиц, которые меняются весь день, например orders, events, sessions или invoices. Для средних таблиц подойдут точные counts. Для очень больших таблиц дополнительно смотрите и свежие диапазоны, чтобы не доверять одному общему числу.
Дрейф sequence нужно проверять отдельно. Логическая репликация обычно не держит значения sequence в том же состоянии, как ожидают многие команды. Если target sequence отстаёт от source, inserts могут сломаться сразу после переключения записи. Отрепетируйте не только проверку, но и саму коррекцию.
Зафиксируйте целевое условие запуска в письменном виде. "Почти догнали" — это не цель. Лучше правило простое: lag ниже 2 секунд в течение 30 минут, все важные таблицы завершили копирование, row counts совпадают на самых загруженных write-таблицах, а sequence либо не показывают дрейфа, либо уже были продвинуты на target.
Как провести cutover
Хороший cutover начинается с тайминга. Выберите спокойный период, когда трафик низкий, а ваша команда бодрствует, доступна и сидит в одном чате. Сообщите пользователям или внутренним командам, что записи ненадолго приостановятся, даже если вы ждёте, что пауза займёт всего несколько минут.
Когда окно начнётся, сознательно остановите записи приложения. Не надейтесь на "трафика почти нет". Переведите приложение в maintenance mode, отключите фоновые задания, приостановите workers и заблокируйте любые admin tools, которые всё ещё могут менять данные. Затем дождитесь, пока логическая репликация применит всё и lag станет нулевым.
Это как раз та часть, где нужна выдержка. Если хотя бы один сервис продолжит писать, числа поплывут, и переключение очень быстро станет грязным.
Прежде чем направить что-либо на новый кластер, выполните короткий набор финальных проверок. Сравните row counts для самых важных таблиц. Проверьте sequence, особенно на загруженных таблицах с inserts. Посмотрите статус репликации на ошибки применения или пропущенные изменения. Просмотрите логи приложения и базы на странности за последние несколько минут.
Counts не обязаны совпасть по каждой таблице в огромной системе до переключения, но критические таблицы должны совпадать. Sequence важнее, чем думают многие команды. Если sequence отстаёт от реального максимального ID, первый insert после cutover может упасть.
Когда проверки пройдены, переключите соединение приложения на новый кластер и возвращайте записи в контролируемом порядке. Сначала основной app, потом workers, затем scheduled jobs. Следите за первыми запросами, первыми inserts и первыми фоновыми задачами. Держите открытыми dashboards и систему ошибок, и пусть один человек вслух сообщает о проблемах по мере их появления.
Ожидайте несколько сюрпризов. Пропущенная строка подключения, устаревший secret или один worker, который всё ещё смотрит на старый кластер, могут съесть 20 минут.
Не выключайте старый кластер сразу. Оставьте его в режиме только для чтения, пока не появится доверие к новому. Так у вас останется безопасная точка отсчёта для проверок, а откат станет намного менее болезненным, если что-то сломается.
Как подготовить план отката
Rollback работает только тогда, когда вы защищаете старую базу с первого дня. Держите старый кластер онлайн, без изменений и готовым снова принять трафик. Не спешите убирать настройки репликации, cleanup jobs или пути доступа только потому, что cutover уже начался.
Быстрый fallback держится на дисциплине. У старой базы должна оставаться та же схема, тот же connection path, который можно восстановить, и достаточная мощность, чтобы снова выдержать production-нагрузку. Если сломать эту страховку во время окна обновления, rollback превратится в rebuild.
Заранее задайте жёсткое окно принятия решения об откате до переключения. Обычно это 15–30 минут. Этого хватает, чтобы увидеть реальный трафик, но не создать слишком большой хвост post-cutover writes, который придётся потом разбирать при возврате.
Решите, кто принимает решение
Один человек должен владеть решением go или no-go. Назначьте его до открытия окна. Это может быть DBA, engineering lead или Fractional CTO, но не групповое голосование в тот момент, когда уже срабатывают alerts.
У этого владельца должен быть короткий список триггеров для отката. Сделайте их измеримыми: ошибки приложения держатся выше согласованного лимита несколько минут, write latency резко растёт и не приходит в норму, ломаются sign-in или checkout, проверки данных показывают пропавшие строки, или replication workers ведут себя не так, как ожидается.
Подумайте о записях, которые, возможно, придётся восстановить
Вот этот шаг команды часто пропускают. После cutover новые записи попадают на обновлённый кластер. Если вы откатитесь назад, эти записи сами по себе не вернутся в старую базу.
Вам нужен способ восстановления ещё до начала cutover. Некоторые команды просто приостанавливают записи на короткий период проверки. Другие ставят writes в приложении в очередь. Более гибкий вариант — логировать каждую запись, которая попадает на новый кластер, чтобы потом при необходимости воспроизвести эти изменения на старом.
Проведите одну репетицию с именами и временем. Если переключение сломается в 2:07, кто перенаправляет трафик, кто блокирует новые записи, кто проверяет данные и кто объявляет rollback? Чёткие ответы экономят время, когда окно становится напряжённым.
Типичные ошибки при таких обновлениях
Большинство крупных обновлений Postgres ломается из-за банальных вещей, а не из-за экзотики. Команды запускают реплику, видят, что строки двигаются, и думают, что самое сложное уже позади. Обычно именно тогда и начинается настоящий риск.
Первая ошибка — не провести полную репетицию на данных, похожих на production. Маленькая staging-база не показывает проблем, которые возникают с большими таблицами, длинными транзакциями, загруженными write-path или фоновыми заданиями, которые меняют строки весь день. Если тестовый прогон занимает 20 минут, а production нужно несколько часов на догоняние, ваш план cutover — это фантазия.
Хорошая репетиция использует реальные размеры таблиц или что-то очень близкое к ним, включает write-трафик во время синхронизации, прогоняет самые загруженные пути чтения и записи, проверяет sequence после inserts и включает тайминг для cutover и rollback.
Sequence регулярно подводят команды. Логическая репликация копирует изменения таблиц, но значения sequence требуют отдельного внимания. Всё может выглядеть нормально, пока первая вставка после cutover не получит ошибку дублирующегося ключа, потому что новый primary всё ещё выдаёт старые ID. Это не редкость. Это один из самых частых способов испортить в целом чистое переключение.
DDL changes создают другой тип проблем. Во время окна репликации кто-то добавляет колонку, меняет default, создаёт индекс или переименовывает что-то маленькое и вроде бы неважное. Старая и новая базы расходятся, а приложение замечает несовпадение в самый неподходящий момент. Заморозьте schema changes или ведите их с настоящей дисциплиной.
Ещё одна ошибка — проверять только спокойные таблицы. Команды открывают пару admin screens, читают несколько строк и считают задачу завершённой. Потом ломается горячий путь: checkout, signup, webhook ingestion, job queues или то, что получает нагрузку каждую секунду. Именно эти пути заслуживают первых и самых жёстких тестов, потому что они быстро показывают lag, locks и проблемы с sequence.
Последняя ошибка — называть план "zero downtime" до того, как измерены реальный lag и задержка переключения. Если репликация отстаёт на 12 секунд, а приложению нужно ещё 30 секунд, чтобы безопасно сменить подключения, у вас не zero downtime. У вас короткий outage или период устаревших чтений. Назовите это честно, измерьте и заранее задайте ожидания, прежде чем кто-то пообещает плавный релиз.
Простой пример всего процесса
Небольшая SaaS-компания запускает подписочное приложение со стабильными записями весь день: новые регистрации, строки счетов, обновления аккаунтов и фоновые задачи. Команда хочет крупное обновление Postgres с логической репликацией, потому что даже короткий простой ударит по поддержке и биллингу.
Они поднимают новый кластер, копируют базовые данные, запускают логическую репликацию и проводят полную репетицию за несколько дней до реального переключения. Тестовый трафик выглядит нормально, и поначалу всё кажется успешным. Lag падает до нуля, row counts совпадают, и команда уже почти готова подписать план.
Потом на одной загруженной таблице начинают падать inserts. Новые invoices пытаются использовать уже существующие ID. Проблема в drift sequence. Логическая репликация перенесла изменения таблицы, но не передала текущие значения sequence так, как ожидала команда.
Эта репетиция меняет план. Они добавляют финальный шаг синхронизации sequence после того, как репликация догонит, и пишут небольшой smoke test, который создаёт пользователя, создаёт счёт и обновляет подписку. Если любой insert возвращает ошибку duplicate ID, они останавливаются.
В ночь cutover они ставят на паузу фоновые задания, блокируют новые записи в приложении примерно на минуту и ждут, пока lag станет нулевым. Затем они переключают трафик приложения на новую базу и снова открывают записи. Lag репликации по-прежнему нулевой, но приложение всё равно выдаёт несколько ошибок.
Проблема была не в метрике lag. Она просто не охватывала всё. Один сервер приложения продолжал использовать старое подключение и попал в invoices path до того, как команда завершила последнюю проверку sequence на новой стороне.
Поскольку они заранее спланировали rollback, решение осталось небольшим и быстрым. Они держали старую базу готовой, ограничили первые несколько минут обычными действиями клиентов и оставили email jobs, exports и webhooks на паузе. Когда появились ошибки в invoices, они вернули приложение на старую базу, очистили stale connections и проверили только несколько записей на новой стороне.
Когда второе переключение сработало, они сделали короткий разбор. Зафиксировали точное время остановки и возобновления writes, сохранили графики lag и количество ошибок приложения, внесли исправление sequence в runbook и оставили старый кластер на определённое окно возврата. В итоге у них получилось не просто успешное обновление, а процесс, который можно повторить.
Финальные проверки и следующие шаги
Обновление проходит намного спокойнее, когда команда работает по одной странице, а не по памяти. Держите короткий runbook для репетиции и отдельную копию для go-live. Если план живёт только в чате, люди пропускают шаги, когда давление растёт.
На этой странице должны быть владелец каждого действия, запланированное время, точная команда для запуска и сигнал, который говорит команде продолжать. Там же нужны и чёткие точки остановки. Если lag репликации не возвращается к нулю, smoke-тесты падают или write-трафик всё ещё идёт в старый primary, остановитесь и исправьте это до переключения.
Сохраняйте доказательства по ходу работы. Храните вывод терминала, скриншоты, результаты запросов и заметки по smoke-тестам в одном общем месте. Позже эти материалы помогут ответить на два главных вопроса: действительно ли replica успела догнать и нормально ли повело себя приложение после переключения?
Будьте строги к таймингам. Если репетиция показала, что приложению нужно 4 минуты, чтобы чисто переподключиться, не обещайте 30 секунд в production. Команды попадают в неприятности, когда предполагают, что на более загруженном дне переключение будет быстрее.
Финальная проверка перед запуском может быть простой. Если lag показывает ноль ожидающих изменений, row counts совпадают по нужным таблицам, а ваши smoke-тесты для login, checkout или обработки job проходят на новом primary, можно двигаться дальше с разумной уверенностью. Если какого-то из этих пунктов нет, вы всё ещё гадаете.
Следующий шаг — снова прогнать весь процесс и убрать всё расплывчатое. Замените шаги вроде "проверить репликацию" на точный запрос, ожидаемый результат и человека, который подтверждает выполнение.
Если вам нужен внешний взгляд до обещания почти безостановочного cutover, Oleg Sotnikov на oleg.is помогает стартапам и небольшим командам как Fractional CTO и advisor. Второй взгляд на runbook, rollback plan и шаги cutover помогает заметить слабые места до того, как они превратятся в outage.
Часто задаваемые вопросы
Делает ли логическая репликация крупное обновление Postgres безопасным?
Нет. Логическая репликация снижает риск, но именно переключение записи чаще всего и ломается. Вам всё равно нужны проверки лага, синхронизация sequence, smoke-тесты и план отката.
Что нужно проверить до создания нового кластера?
Сначала сопоставьте extensions, роли, схемы, locale, encoding и возможности таблиц. Ещё проверьте, что source выдержит нагрузку от копирования, а на target хватит места для данных, индексов, WAL и всплесков трафика.
Можно ли реплицировать таблицы без primary key?
Да, но обновления и удаления тогда становятся сложнее и медленнее. Если можете, добавьте primary key; если нет — используйте replica identity full и будьте готовы к большей нагрузке во время синхронизации.
Как понять, что replica действительно догнала?
Не доверяйте одному зелёному статусу. Проверьте time lag, backlog, состояние копирования по каждой таблице, row counts на самых загруженных таблицах и свежую запись, которая уже видна на target.
Sequence копируются автоматически?
Не в том виде, как многие ожидают. Logical replication переносит изменения строк, а значения sequence нужно проверять отдельно ближе к cutover и при необходимости продвигать на target до начала новых inserts.
Стоит ли разрешать schema changes во время миграции?
Обычно нет. Одна небольшая DDL-правка может развести source и target, а приложение заметит это в самый неудобный момент. Заморозьте schema changes на время окна или вносите каждое изменение на обеих сторонах в одном и том же порядке.
Какой порядок cutover самый безопасный?
Сначала остановите записи, затем поставьте на паузу workers и jobs, дождитесь, пока lag станет нулевым, выполните финальные проверки и только потом переключайте приложение на новый кластер. Сначала верните основной app, затем workers и scheduled jobs, чтобы быстро поймать старые подключения.
Кто должен принимать решение о go или no-go?
Назначьте одного владельца до начала окна. Этот человек смотрит на письменные проверки и быстро принимает решение; групповой спор только съедает время, когда уже пошли alerts.
Когда нужно делать rollback?
Откатывайтесь, если ошибки приложения долго остаются высокими, write latency не приходит в норму, smoke-тесты не проходят или проверки данных показывают пропавшие строки. Окно отката лучше определить до переключения, чтобы команда не тянула время и не создавала ещё больше writes для восстановления.
Зачем нужна полная репетиция перед go-live?
Потому что маленький staging-тест скрывает проблемы, которые появляются с большими таблицами, busy workers и длинным временем догоняющей синхронизации. Репетиция позволяет замерить копирование, проверить исправление sequence и убедиться, что cutover и rollback работают под нагрузкой.


