Облачная VM, контейнерный сервис или bare metal для SaaS
Облачная VM, контейнерный сервис или bare metal: сравните трудозатраты, мониторинг, обновления и обработку сбоев, прежде чем доверять месячной цене.
Содержание
Почему ежемесячный счёт — это только часть стоимости
Дешёвый сервер может быстро стать дорогим, если вашей команде приходится постоянно за ним присматривать. Когда люди сравнивают облачную VM, управляемый контейнерный сервис и bare metal, они часто останавливаются на счёте. Но так теряется время на патчи, бэкапы, неудачные деплои, очистку диска и ночные перезапуски.
Даже стабильному SaaS нужен регулярный уход. Трафик может почти не меняться в обычные дни, но кому-то всё равно нужно обновлять ОС, проверять бэкапы, обновлять секреты, следить за ростом хранилища и держать готовый план отката. Если один вариант экономит $200 в месяц, но добавляет шесть часов ручной работы, это редко оказывается выгодной сделкой.
Во многих случаях инфраструктурные расходы прячутся в рутинной работе. Логи, метрики, alert-ы и проверки бэкапов требуют времени на настройку и поддержание в рабочем состоянии. Некоторые платформы берут часть этого на себя. Другие дают больше контроля, но вместе с ним — и больше обязанностей для команды. Счёт может выглядеть ниже, а реальная стоимость тем временем растёт в фоне.
Инциденты быстро показывают разницу. Bare metal-сервер может казаться дешёвым, пока не сломается диск и процесс восстановления не окажется только в голове одного инженера. Управляемый контейнерный сервис может стоить дороже, но замена, откат и масштабирование часто даются проще. Во время сбоя никого не волнует, какой вариант выиграл в таблице. Всем важно, как быстро команда найдёт проблему и восстановится.
Обновления создают такой же скрытый расход. Изменения версии базы данных, патчи ядра, обновления контейнерного runtime и рост зависимостей нужно планировать заранее. Если ваша схема делает безопасные обновления трудными, потом вы заплатите за это более длинными окнами обслуживания и более высоким риском.
Представьте небольшой SaaS со спокойным трафиком в будни и несколькими загруженными часами каждый день после обеда. Один вариант хостинга дешевле на $150 в месяц, но каждый деплой требует ручных проверок, а бэкапы запускаются через shell-скрипт. Два неудачных инцидента за квартал могут съесть всю экономию.
Чаще всего время команды стоит дороже, чем небольшая разница в цене серверов. Выбирайте тот вариант, который ваша команда сможет патчить, мониторить и обновлять без лишней драмы.
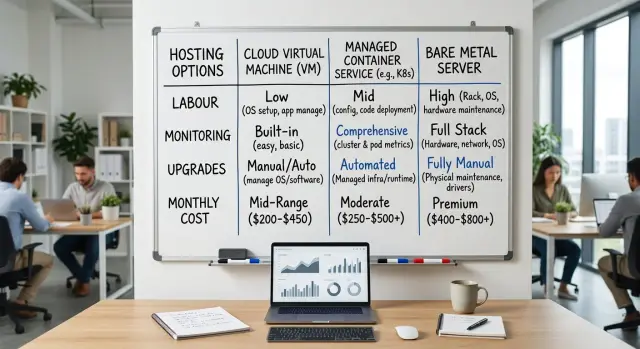
Что меняется между VM, контейнерами и bare metal
Главное различие не в том, где работает приложение. Главное — кто отвечает за рутинную работу после запуска.
VM даёт команде прямой контроль над операционной системой, версиями пакетов, runtime, правилами firewall и расписанием обновлений. Это привычно, особенно если приложению нужны особые настройки или редкие зависимости. Но есть и обратная сторона: ваша команда также отвечает за патчи, укрепление безопасности, проверки бэкапов и мелкие проблемы ОС, которые продолжают возникать каждый месяц.
Управляемый контейнерный сервис снимает часть серверной работы. Обычно вы тратите меньше времени на настройку машины, замену узлов и базовое планирование. Но сам сервис добавляет свои правила для сети, хранилища, деплоев, логов и health checks. Часть работы исчезает, а на её место приходит другая. Если что-то ломается, команде может понадобиться проверить само приложение, образ контейнера и настройки сервиса, прежде чем найдётся причина.
Bare metal отличается ещё сильнее. Вы получаете фиксированное железо и меньше скрытых слоёв со стороны провайдера. Для стабильного SaaS это может сделать производительность более предсказуемой, особенно для баз данных, очередей или долгих фоновых задач. Но одновременно команда берёт на себя больше уровней стека. Нужно самим планировать ОС, обновления безопасности, failover, запас мощности и сроки обновления железа вместо того, чтобы оставлять эти решения облачному провайдеру.
В повседневной работе разница довольно проста. На VM команда управляет сервером и приложением. В контейнерном сервисе команда управляет приложением и учится жить в рамках ограничений платформы. На bare metal команда управляет почти всем, что находится выше стойки. В любом случае кто-то всё равно отвечает за мониторинг, alert-ы, бэкапы и учения по восстановлению.
Именно поэтому реальное сравнение редко видно только в ежемесячном счёте. Основная стоимость прячется в часах, которые команда тратит на поддержание сервиса в здоровом состоянии, безопасные обновления и исправление странных проблем до того, как их заметят клиенты.
Разложите ежемесячную работу команды по пунктам
Стабильный SaaS может выглядеть дешёвым на бумаге и при этом ежемесячно выматывать команду. Недостающая стоимость — это трудозатраты. Если вы хотите честно сравнить варианты, считайте работу людей вокруг серверов, а не только сами серверы.
Начните с задач, которые повторяются независимо от того, спокойный сейчас трафик или проблемный. У большинства команд есть какая-то смесь патчей, бэкапов, деплоев, проверок отката и реагирования на инциденты. Добавьте и мелкие задачи — они быстро накапливаются.
Зафиксируйте базовые вещи: обновления ОС и пакетов, проверки бэкапов и тесты восстановления, деплои и откаты, alert-ы и дежурства, ручные health checks и тикеты в поддержку провайдера.
Затем запишите, кто отвечает за каждую задачу сегодня. Не ограничивайтесь названиями должностей. Назовите конкретного человека или команду, которой действительно приходят alert-ы, кто открывает тикет, кто подтверждает деплой или кто смотрит на дашборд после релиза.
Дальше оцените время в двух сценариях: спокойная неделя и плохая неделя. Спокойные недели показывают базовый уровень. Плохие недели показывают, как выглядит работа, когда неудачный деплой, шумный alert и проблема с хранилищем случаются одновременно.
Именно здесь решение часто меняется. Управляемый контейнерный сервис может убрать часть серверной рутины, но команда всё равно может тратить часы на обновления образов, права доступа и обращения в поддержку. Bare metal может сэкономить деньги при высокой загрузке, но кому-то всё равно придётся разбираться с firmware, заменой компонентов и ночным восстановлением после падения хоста.
Переведите время в деньги. Используйте полную почасовую стоимость, а не только зарплату. Если инженер тратит 6 часов в месяц на рутинное обслуживание и ещё 10 часов в один тяжёлый квартальный инцидент, эти расходы нужно учитывать в сравнении так же, как и счёт от провайдера.
Достаточно простой таблицы. Когда рядом с ценой хостинга появляется стоимость труда, самый дешёвый вариант часто выглядит совсем иначе.
Проверьте мониторинг и дежурства
Низкий ежемесячный счёт перестаёт выглядеть выгодным, если команда не может заметить проблему достаточно рано. Перед сравнением трёх моделей хостинга решите, как вы будете собирать логи, метрики и трассировки, где они будут храниться и кто будет поддерживать эту систему.
Каждый вариант меняет эту работу по-своему. Контейнерный сервис может показывать здоровье кластера из коробки, но трассировки вашего приложения, бизнес-события и сигналы отката всё равно нужно настраивать. VM даёт привычный сервер, но вам всё равно нужно следить за местом на диске, бэкапами, перезапусками процессов и сбоями сети. Bare metal даёт максимум контроля — и одновременно больше способов ошибиться.
Ощущение проблем у клиентов обычно появляется раньше, чем сервер выглядит полностью сломанным. Медленный вход в систему, зависшие фоновые задачи, растущая задержка API и неуспешные платежи часто проявляются первыми. Если команда следит только за CPU и памятью, вы пропустите момент, когда пользователи уже начинают раздражаться.
Настройка должна быстро отвечать на несколько вопросов:
- Изменил ли последний деплой уровень ошибок или время ответа?
- Пользователи сталкиваются с медленными страницами, ошибками запросов или задержанными задачами?
- Растёт ли использование диска и приближается ли к лимиту?
- Проблема в приложении, в сети или на хосте?
Неудачные деплои — хороший тест. Если релиз сломался в 14:15, сможет ли кто-то заметить это за пять минут и откатить изменения до того, как начнут копиться обращения в поддержку? Инструменты вроде Sentry, Grafana, Prometheus и Loki могут дать единый обзор, но только если команда поддерживает их в порядке и делает полезными. Иначе даже хорошее решение превращается в шум.
Общая инфраструктура добавляет ещё один нюанс. На некоторых VM- или контейнерных схемах шумный сосед может съесть I/O или сетевую ёмкость, а графики при этом выглядят лишь слегка плохими. Bare metal снимает именно эту проблему, но не защищает от переполненного диска, сетевого сбоя или расплывчатого alert-а, который будит не того человека.
Назовите людей, которые настраивают alert-ы, и людей, которые на них отвечают. Если это одни и те же двое уставших инженеров каждую неделю, выбирайте вариант, который даёт им меньше движущихся частей, а не просто более низкую цену на бумаге.
Спланируйте обновления до того, как они станут срочными
Работа по обновлениям может изменить результат сильнее, чем ежемесячный счёт. Команды часто считают только сервер и забывают про часы, которые уходят на патчи, тестирование, ожидание и устранение сюрпризов.
Небольшие задержки быстро накапливаются. Старой ОС может не хватить для установки security patch. Старый runtime может помешать работе новой библиотеки. База данных, которую слишком долго не трогали, способна превратить спокойное изменение во вторник в проблему для всей команды.
Ведите один журнал обновлений для трёх слоёв: операционной системы, runtime и зависимостей приложения. На VM это обычно означает пакеты ОС, Docker или runtime языка и библиотеки, которые использует приложение. В контейнерном сервисе всё равно нужно отслеживать базовый образ, версию кластера и пакеты внутри каждого образа. На bare metal добавьте firmware, RAID-инструменты и даты поддержки оборудования.
Стабильный SaaS становится безопаснее, когда можно обновлять по одному узлу за раз. Если у вас два узла приложения вместо одного, можно вывести один из эксплуатации, пропатчить его, проверить и вернуть обратно до того, как вы тронете второй. Это сильно уменьшает зону риска. Односерверные схемы кажутся дешёвыми, но каждое обновление превращается либо в простой, либо в азартную игру.
Оставляйте запас мощности на окна обслуживания. Если обычно сервис использует 70% CPU в будние пики, у вас остаётся не так много пространства, чтобы вывести одну машину из работы и сохранить стабильное время ответа. Многие команды понимают это слишком поздно — во время первого срочного патча.
План отката нужно писать до первого изменения, а не после сбоя. Делайте его коротким и понятным:
- Запишите текущую версию и целевую версию.
- Укажите, как вернуть старый образ, пакет или snapshot.
- Проверьте, где находятся резервные копии и кто их проверил.
- Определите сигнал, по которому нужно откатываться.
- Перечислите быстрые проверки, подтверждающие восстановление.
Отложенные обновления редко остаются изолированной проблемой. Старые зависимости могут заморозить разработку новых функций. Истёкшая поддержка может оставить вас без помощи вендора. Поздний прыжок через несколько версий сразу способен сломать скрипты деплоя, monitoring agents или расширения базы данных.
Здесь варианты расходятся особенно заметно. Контейнерные сервисы убирают часть работы с хостом, но не убирают обновления приложения и образов. VM дают контроль, но вы берёте на себя больше патчей. Bare metal может сократить регулярные расходы при стабильной нагрузке, но добавляет работу с железом и firmware, которую многие небольшие команды недооценивают.
Как сравнивать варианты шаг за шагом
Начинайте с данных своего приложения, а не с прайс-листа. Возьмите 30 дней по CPU, RAM, использованию диска, росту диска и сетевому трафику. Используйте один и тот же временной промежуток для каждого варианта, иначе сравнение быстро станет размытым.
Выбор станет намного понятнее, когда вы разделите нагрузку на две части: та, что остаётся ровной всю неделю, и та, что растёт в рабочие часы или после релизов. У многих SaaS-продуктов есть стабильная база и предсказуемые дневные пики в будни. Если у вас именно так, возможно, нет смысла переплачивать за масштабирование, которое редко бывает нужно.
Сначала оцените базовую схему. Потом добавьте запас безопасности, который нужен на загруженные часы, неудачные деплои и мелкие сюрпризы. Для VM это может означать более крупный инстанс или второй инстанс в резерве. Для контейнерного сервиса — дополнительные узлы и плату за платформу. Для bare metal — второй сервер, запасные детали или мощность, которую вы специально не используете.
Не останавливайтесь на стоимости хостинга. Добавьте часы, которые команда тратит каждый месяц на патчи, исправления после деплоя, изменение размера ресурсов, обновления образов и on-call проблемы. Схема, которая экономит $400 в месяц, но съедает 15 часов инженера, часто оказывается дороже.
Учитывайте плохой день
Проведите один тест на день сбоя для каждого варианта. Спросите, что произойдёт, если сервер сломается во вторник в 11 утра, закончится место на диске или релиз повредит production. Посчитайте и прямые расходы, и время команды:
- Часы инженеров на поиск проблемы и восстановление.
- Время поддержки на ответы клиентам.
- Работа над продуктом, которая сдвинется, потому что команда бросила всё.
- Возвраты, кредиты или застопорившиеся продажи.
Потом сделайте ещё одну проверку: может ли ваша текущая команда справиться с этим без героизма? Если у вас два разработчика и нет full-time ops-специалиста, самый дешёвый вариант на бумаге может оказаться худшим по факту. Для стабильного SaaS лучшим обычно становится тот вариант, который команда может спокойно поддерживать в обычную неделю и быстро чинить в тяжёлую.
Пример: стабильный SaaS с пиками в будни
Представьте небольшой SaaS-продукт для финансовых или операционных команд. Одна и та же база клиентов заходит каждый будний день, в основном с 8 утра до 6 вечера. Ночью трафик спокойный, а выходные тихие. Команда выпускает обновления раз в неделю, поэтому для неё важны две вещи: uptime и быстрый откат, если релиз пошёл не так.
В такой схеме чистая стоимость вычислений редко говорит всю правду. Использование CPU и памяти может оставаться предсказуемым, но логи, трассировки и события ошибок часто растут быстрее самого приложения. Команда может сэкономить $300 на хостинге, а потом потратить гораздо больше времени на шумные alert-ы, чистку retention у логов или исправление медленного процесса отката.
Облачная VM часто хорошо подходит под такой сценарий, когда приложение стабильное, а команда небольшая. Одна или две VM легко понять, легко отлаживать и легко snapshot-ить перед релизом. Если что-то ломается в среду днём, команда обычно может быстро откатиться, не разбираясь в слишком большом количестве движущихся частей.
Контейнерный сервис начинает выглядеть разумнее, когда еженедельные релизы происходят достаточно часто и скорость деплоя важнее простоты настройки. Откаты обычно становятся аккуратнее. Масштабирование под дневные пики тоже проще. Но теперь команда отвечает за большее количество операционной работы вокруг сборки образов, описаний сервисов, секретов и отладки runtime.
Bare metal может победить по ежемесячной цене, когда нагрузка стабильна и предсказуема. Для такой работы это привлекательно. Но экономия быстро исчезает, если никто в команде не хочет разбираться с проблемами железа, обновлениями ядра или планированием замены оборудования.
Один нюанс часто и решает выбор: стоимость мониторинга. Если объём логов растёт каждый месяц, а вычисления остаются ровными, проблема не в CPU. Проблема в логировании. Команда, которая уже умеет настраивать retention, делать sample traces и отделять полезные логи от шума, может дёшево работать и на контейнерах, и на bare metal. Команде без такой привычки обычно лучше выбрать более простой вариант, даже если счёт за сервер немного выше.
Для такого продукта с упором на будни время сотрудников важнее железа. Быстрый откат, чистый мониторинг и здравый подход к обновлениям обычно важнее, чем попытка выжать последний процент экономии на вычислениях.
Ошибки, которые искажают сравнение
Команды часто сравнивают облачную VM, контейнерный сервис и bare metal, глядя только на первый счёт. Это звучит разумно, но обычно приводит к неверному выбору. Стоимость инфраструктуры складывается из трёх частей одновременно: арендованной мощности, инструментов поддержки и часов, которые команда тратит на то, чтобы всё оставалось спокойным и стабильным.
Одна из частых ошибок — использовать цены из прайс-листа так, будто вы будете платить их всегда. Для стабильной нагрузки часто подходят reserved instances, committed use discounts, годовые контракты или индивидуальные условия. Если сравнивать bare metal только с on-demand ценами облака, облачная сторона может выглядеть хуже, чем есть на самом деле.
Ещё одна ошибка — забывать о дополнительных счетах. Бэкапы, snapshots, object storage, network egress, хранение логов, метрик, трассировок, alert-ов и трекинга ошибок могут быстро сложиться в значительную сумму. Сервис, который кажется дешёвым на уровне вычислений, может стать дорогим, если учитывать восстановление и мониторинг.
Управляемые сервисы тоже вводят в заблуждение. Они убирают часть работы, но не всю. Команда всё равно отвечает за правила деплоя, реагирование на инциденты, поведение при масштабировании, секреты, контроль доступа, проверку затрат и планирование мощности. Если приложение тормозит каждый будний день в 2 часа дня, облачный провайдер не отладит это за вас.
Обновления и откаты создают ещё одно ложное сравнение. Команды оценивают счастливый сценарий, а потом забывают о трудозатратах на смену версий, пересборку образов, изменения базы данных, проверки совместимости и учения по откату. Платформа, которая экономит $400 в месяц, не является дешёвой, если каждое обновление сжигает два рабочих дня инженера и повышает напряжение на дежурстве.
Bare metal искажается в другую сторону. Цена сервера может выглядеть отлично для стабильной нагрузки, но только если у вас есть запас на сбои. Если одна машина несёт слишком много трафика, вам нужны запасная мощность, план failover, проверенные бэкапы и способ заменить железо без паники. Без такого запаса низкая цена — это в основном иллюзия.
Простой тест помогает: сравните каждый вариант с реальными часами работы, реальными инструментами поддержки и с учётом одной плохой недели. Обычно именно там начинается честное сравнение.
Короткий чек-лист перед принятием решения
Стабильному SaaS не нужна сложная scoring model. Ему нужны несколько честных ответов. Если вы не можете дать их за одно короткое совещание, значит, перед выбором между облачной VM, контейнерным сервисом и bare metal вам, вероятно, нужны дополнительные данные.
Начните с нагрузки. Нужно понимать обычную неделю, а не только среднее за месяц. Средние цифры скрывают проблемы. Сервис, который на бумаге выглядит спокойным, всё равно может дать болезненный пик в один загруженный час, и именно этот час решает, нужен ли вам больший запас, более быстрое масштабирование или более простое планирование мощности.
Потом посмотрите на трудозатраты, потому что именно здесь многие команды обманывают себя. Спросите, кто будет патчить ОС, runtime и базу данных, и когда это будут делать. Если ответ звучит как «кто-нибудь сделает это в субботу», значит, схема уже стоит дороже, чем показывает счёт. Для небольшой команды спокойное обслуживание, которое помещается в обычные рабочие часы, часто лучше, чем погоня за самой низкой ежемесячной ценой.
Короткий чек-лист помогает:
- Измерьте обычный трафик, пик в рабочие часы и частоту таких пиков.
- Запишите, кто патчит каждый слой стека и сколько времени это обычно занимает.
- Проверьте, сможете ли вы заметить плохой деплой за несколько минут, а не после писем от клиентов.
- Протестируйте путь отката до того, как он понадобится.
- Подумайте, останется ли эта схема разумной через 12 месяцев роста.
Мониторинг тоже заслуживает пристального внимания. Если деплои могут ломаться тихо, проблема не в хостинге как таковом. Вам нужны health checks, логи, alert-ы и простой способ сравнивать состояние до и после релиза. Команды, которые держат инструменты вроде Grafana, Prometheus, Loki и Sentry лёгкими и хорошо настроенными, обычно тратят меньше времени на тушение пожаров.
Если вам нужно второе мнение перед миграцией, Oleg Sotnikov на oleg.is помогает стартапам и небольшим компаниям разбирать компромиссы в инфраструктуре, настраивать мониторинг и снижать операционные расходы без усложнения стека.
И наконец, подумайте на год вперёд. Может быть, bare metal дешёв сегодня, но будет ли он удобен вашей команде, когда появится больше клиентов, больше деплоев и более жёсткие требования к uptime? Выбирайте тот вариант, который команда сможет спокойно обслуживать, безопасно патчить и быстро откатить, если что-то пойдёт не так.
Что делать дальше
Выберите один сервис, который вы уже запускаете каждый день, и используйте его как тестовый кейс. Подойдёт worker для биллинга, API backend или клиентский dashboard. Не начинайте со всего стека сразу. Один реальный сервис покажет, где более дешёвый на бумаге вариант на практике обходится дороже по времени.
Запишите текущую схему до любых изменений. Укажите ежемесячную стоимость хостинга, кто с ней работает, как часто ломаются деплои, сколько alert-ов срабатывает и сколько времени занимают обычные обновления. Если senior engineer тратит два часа каждую неделю на мелкие инфраструктурные проблемы, эти часы нужно учитывать. Это часть счёта.
Хорошо работает простой 30-дневный тест:
- Перенесите или смоделируйте один сервис на том варианте, который хотите проверить.
- Отслеживайте трудозатраты каждую неделю, а не только расходы на облако.
- Записывайте каждый инцидент, alert и ручное исправление.
- Отмечайте, что оказалось легко обновить, а что создало риск.
Через месяц разберите заметки вместе с теми, кто действительно обслуживает сервис. Финансы видят счёт, а инженеры — скрытую стоимость. Если более дешёвый вариант породил шумные alert-ы, сложные деплои или неудобные обновления, это важнее, чем небольшая ежемесячная экономия.
Держите таблицу простой. Вам достаточно нескольких колонок: прямые расходы, время инженеров, количество инцидентов, время восстановления и сложность обновлений. Обычной таблицы хватит. Смысл в том, чтобы сравнивать хостинг так, как это происходит в реальной работе.
Если команда небольшая, внешняя оценка может сэкономить время. Oleg Sotnikov может проверить компромиссы на прочность, заметить трудозатраты, которые вы могли упустить, и предложить следующий шаг, подходящий для стадии продукта и размера команды. Такой разбор особенно полезен до начала миграции, а не после того, как новая схема уже создаст новые операционные проблемы.
А потом примите одно решение — для одного сервиса, опираясь на один месяц данных.
Часто задаваемые вопросы
Что стоит сравнивать в первую очередь при выборе между VM, контейнерным сервисом и bare metal?
Начните с реальной нагрузки и ежемесячных задач команды, а не с прайс-листа. Возьмите данные за 30 дней по CPU, RAM, диску, сети, проблемам с деплоями, проверкам бэкапов и дежурствам, а потом сравните эти трудозатраты с счётом за хостинг.
Когда облачная VM — правильный выбор для SaaS-приложения?
VM хорошо подходит, когда приложение работает довольно ровно, а команде нужна простая схема, которую легко отлаживать и откатывать. Вы получаете прямой контроль над сервером, но команде всё равно нужно патчить ОС, проверять резервные копии и заниматься обычной серверной рутиной.
Когда контейнерный сервис лучше, чем VM?
Выбирайте контейнерный сервис, когда скорость деплоя, более аккуратные откаты и простое масштабирование важнее, чем максимальная простота стека. Вы будете меньше заниматься настройкой машин, но команде всё равно придётся управлять образами, настройками сервиса, секретами и проблемами runtime.
Когда bare metal действительно может сэкономить деньги?
Bare metal часто работает лучше всего, когда нагрузка остаётся стабильной, требования к производительности предсказуемы, а ежемесячная экономия достаточно велика, чтобы оправдать более ручную работу. Он перестаёт выглядеть дешёвым, если команда не готова заниматься аппаратными сбоями, обновлениями firmware и планированием замены.
Как учесть время команды в реальной стоимости?
Считайте часы, которые люди тратят на патчи, исправления после деплоя, тесты бэкапов, настройку alert-ов и реагирование на инциденты, а потом умножайте это время на полную почасовую стоимость. Схема, которая экономит пару сотен долларов в месяц, всё равно может оказаться хуже, если каждую неделю съедает время инженеров.
Какой мониторинг нужен перед выбором хостинга?
Следите не только за CPU и памятью, а за тем, что первым ощущают клиенты. Вам нужно быстро видеть влияние деплоев, рост ошибок, медленные страницы, зависшие задачи, рост диска и сигналы для отката, чтобы успеть среагировать до лавины обращений в поддержку.
Как планировать обновления и откаты?
Ведите один простой журнал обновлений для ОС, runtime и зависимостей приложения, и заранее пропишите шаги отката. Если можно держать два узла вместо одного, можно поочерёдно патчить их, проверять и не расширять зону риска.
Какие ошибки делают сравнение дешевле, чем оно есть на самом деле?
Команды часто смотрят только на первый счёт и игнорируют дополнительные расходы вроде бэкапов, хранения логов, трассировок, egress и времени инженеров в плохую неделю. Ещё одна типичная ошибка — считать только удачный сценарий и забывать, что происходит, когда деплой ломается или сервер падает днём.
Как проверить варианты, не перенося всё сразу?
Попробуйте сначала один сервис, а не весь стек. Проведите тест на 30 дней, фиксируйте прямые затраты, время инженеров, alert-ы, инциденты, время восстановления и сложность обновлений, а потом разберите заметки с теми, кто реально обслуживает систему.
Стоит ли привлекать внешнюю помощь перед миграцией?
Если команда небольшая или уже перегружена, внешний взгляд может уберечь от дорогого переезда. Oleg Sotnikov помогает стартапам и небольшим компаниям оценивать компромиссы в инфраструктуре, настраивать мониторинг и сокращать операционную работу ещё до начала миграции.


