Очереди Node.js vs workflow-движки: когда нужны надёжные рабочие процессы
Очереди Node.js vs workflow-движки: узнайте, где повторные попытки, задержки и цепочки задач начинают ломаться, и когда надёжные рабочие процессы экономят время и уменьшают простои.
Содержание
Почему простые задачи начинают ломаться
Сначала простая задача кажется безобидной. Пользователь регистрируется, ваше приложение Node.js кладёт в очередь задачу «отправить приветственное письмо», и воркер отправляет его через несколько секунд. Такую схему легко объяснить, легко запустить и часто достаточно для первой версии.
Проблемы начинаются, когда одна задача превращается в цепочку. После регистрации вам может понадобиться создать пробный аккаунт, записать данные для биллинга, отправить письмо, уведомить отдел продаж и подождать день, прежде чем отправлять follow-up. Каждый из этих шагов по отдельности не выглядит сложным. Вместе они образуют уже не просто фоновую задачу, а процесс.
Слабое место проявляется, когда воркер останавливается на середине. Представьте, что он создал запись для биллинга, а потом упал до отправки письма. Пользователь уже существует, аккаунт может быть готов лишь частично, и никто не знает, должен ли следующий повторный запуск начать с начала или продолжить с середины. Обычная очередь обычно знает только то, что задача не удалась. Она не помнит всю историю того, что уже произошло.
Повторные попытки делают это ещё хуже. Если воркер пробует снова с самого начала, он может создать дубликаты. В итоге появляются две записи биллинга, два уведомления в Slack или два приветственных письма. Команды часто закрывают это проверками вроде «если статус уже done, пропусти шаг», но такие проверки быстро расползаются и со временем плохо поддерживаются.
Почти сразу база данных заполняется флагами вроде:
- email_sent
- trial_created
- crm_synced
- followup_scheduled
- retry_count
На вид эти флаги практичны, но они разбрасывают истину по разным задачам, таблицам и коду воркеров. Один коллега смотрит логи очереди. Другой проверяет запись пользователя. Третий изучает cron-задачу, которая чистит старые повторы. Люди перестают доверять системе, потому что каждая ошибка требует ручного расследования.
Вот в этот момент фоновые задачи Node.js перестают казаться простыми. Код по-прежнему работает через очередь, но настоящая проблема уже другая: оркестрация рабочего процесса — порядок шагов, состояние, повторы и восстановление после сбоев. Как только всё это нужно каждую неделю, обычный раннер задач начинает стоить дороже, чем экономит.
Что хорошо делает библиотека очередей
Библиотека очередей отлично подходит, когда работа короткая, отдельная и легко повторяется. У большинства приложений таких задач хватает. Пользователь загружает изображение, запрашивает сброс пароля или создаёт счёт — и приложение может передать эту работу воркеру, вместо того чтобы заставлять пользователя ждать.
Это уже решает типичную проблему фоновых задач Node.js. Ваш веб-сервер остаётся быстрым, потому что передаёт медленную работу дальше и возвращается к обработке запросов. Пользователь быстро получает ответ, а воркер завершает задачу чуть позже.
Очереди также хорошо поглощают всплески нагрузки. Если зарегистрировались 10 пользователей, ничего особенного не происходит. Если после запуска или кампании зарегистрировались 10 000, очередь сгладит этот всплеск, чтобы на приложение, базу данных и внешние API не пришёлся удар одновременно.
Простая очередь особенно хорошо подходит для таких задач:
- отправить одно письмо
- уменьшить размер одного изображения
- сгенерировать один PDF
- синхронизировать одну запись с другим сервисом
- позже удалить старые временные файлы
Повторы — ещё одна сильная сторона. Если задача упала из-за таймаута у почтового сервиса или временной ошибки API, воркер может попробовать ещё несколько раз. Многие сбои короткие и несложные, поэтому небольшая политика повторов решает их без лишнего проектирования.
Отложенные задачи тоже делаются легко. Можно запланировать напоминание на два часа позже, отправить follow-up завтра или запустить очистку ночью. Для этого не нужна полноценная оркестрация рабочих процессов. Часто достаточно просто отложенной задачи.
Главное преимущество — понятность. Хорошие воркеры очередей остаются небольшими. Одна задача делает одну вещь, записывает результат и завершается. Так код легче читать, проще тестировать и меньше раздражает при отладке.
В выборе между Node.js queues vs workflow engines очереди обычно выигрывают на старте. Если каждая задача может идти сама по себе, а нескольких повторов хватает для большинства сбоев, очередь помогает сохранить простоту, не загоняя команду в тяжёлую инфраструктуру.
Что добавляет движок рабочих процессов
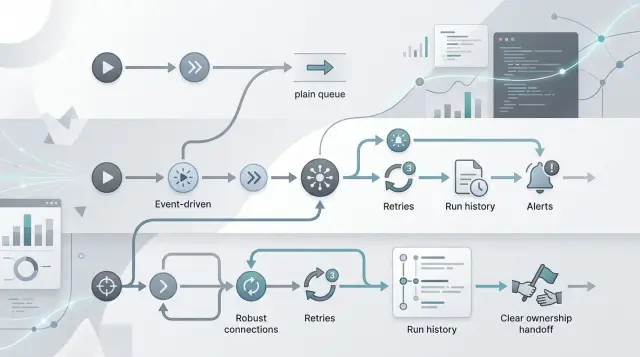
Движок рабочих процессов следит за всем процессом, а не только за следующей задачей. Это меняет подход к системам с несколькими шагами, повторами, ожиданиями и участием пользователя. В споре Node.js queues vs workflow engines именно здесь разница становится по-настоящему заметной.
С очередью команды обычно разбивают работу на отдельные задачи, а потом отслеживают состояние в коде приложения, флагах базы данных или кастомных таблицах. Движок рабочих процессов хранит прогресс каждого шага в одном запуске. Если шаг 3 завершился, а шаг 4 упал, система знает, где именно она остановилась и что уже было сделано.
Это особенно полезно, когда воркер падает или деплой прерывает процесс. Движок надёжного выполнения рабочих процессов может продолжить работу после перезапуска, не проигрывая весь поток заново и не гадая, что произошло в прошлый раз. Так вы избегаете дублей писем, повторных списаний и неудобных скриптов для ручной чистки.
Он также намного лучше справляется с ожиданием. Некоторая работа не заканчивается за секунды. Иногда нужно подождать таймер, одобрение менеджера, подписанный документ или внешний callback от платёжного провайдера. Очередь тоже может это делать, но командам часто приходится самим строить вокруг неё логику таймаутов, polling-задачи и конечные автоматы. Движок рабочих процессов уже умеет засыпать, ждать и продолжать позже.
Ещё одно большое отличие — ветвление. Реальные бизнес-процессы почти никогда не идут по прямой. Один клиент проходит проверку, другому нужен ручной просмотр, а третий выходит из процесса на середине. Движок рабочих процессов держит все ветки в одном месте, поэтому логика остаётся читаемой, а не расползается по обработчикам, cron-задачам и коду повторов.
Простой пример хорошо это показывает. Допустим, SaaS-приложение создаёт аккаунт, отправляет письмо для подтверждения, ждёт до 24 часов, пока пользователь подтвердит действие, подготавливает ресурсы, а затем просит финансовый отдел проверить более крупные тарифы. Если подтверждение так и не пришло, запуск заканчивается одним образом. Если финансовый отдел отклоняет тариф, — другим. Если приложение перезапустилось в середине, workflow продолжает работу с последнего завершённого шага.
История полного запуска часто оказывается той частью, которую команды особенно ценят позже. Поддержка видит, когда каждый шаг начался, был приостановлен, повторён, упал или завершился. Разработчики могут разбирать повторы и сбои без склеивания логов из нескольких воркеров. Одно это уже может сэкономить часы, когда в продакшене что-то ломается.
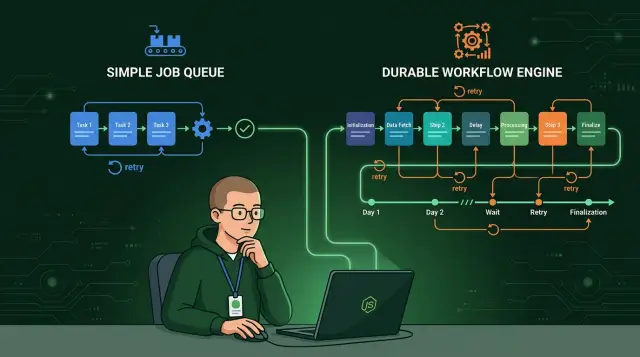
Очередь помогает выполнять задачи. Оркестрация рабочих процессов помогает управлять жизнью процесса.
Где очередей уже недостаточно
Очередь хорошо работает, когда одна задача делает одну вещь и быстро завершается. Уменьшить изображение, отправить письмо, сгенерировать PDF — и готово. Проблемы начинаются, когда эта «задача» превращается в полноценный бизнес-процесс с множеством шагов, общим состоянием и долгими ожиданиями.
Одна из частых точек отказа — когда поток пересекает границы сервисов. Один шаг разговаривает со Stripe, другой обновляет вашу базу данных, третий вызывает ERP, а четвёртый ждёт, пока человек что-то одобрит. Очередь может продвигать каждый шаг вперёд, но команде приходится склеивать всю историю вместе при помощи правил повторов, таблиц статусов, отложенных задач и кастомного кода.
Долгие паузы делают трещины очевидными. Если клиент должен подписать контракт завтра или система склада отправит callback через три часа, простые фоновые задачи Node.js начинают казаться неудобными. Команды часто подменяют состояние workflow дополнительными строками в базе, cron-проверками и кучей логики «если статус = X». Это работает какое-то время, а потом кто-то задаёт поддержку простой вопрос: «где это сейчас?» — и никто не доверяет ответу.
Сбои — вторая переломная точка. Если шестой шаг падает после того, как второй уже списал деньги, а четвёртый уже зарезервировал товар, просто прогонять всю цепочку заново опасно. Можно вручную добавить проверки идемпотентности и компенсирующий код, но именно в этот момент надёжное выполнение рабочих процессов начинает оправдывать себя. Движок хранит состояние, знает, какой шаг завершён, и продолжает с нужного места.
Небольшой пример всё проясняет. Допустим, поток заказа делает так: списывает депозит, резервирует товар, отправляет контракт, ждёт подписи, а потом передаёт заказ в доставку. Если подпись так и не приходит, может понадобиться отменить резерв и вернуть депозит. Это уже не одна задача. Это процесс, где время, деньги, склад и юридический статус двигаются с разной скоростью.
Вот где проходит настоящая граница в Node.js queues vs workflow engines. Если работа короткая, изолированная и легко повторяется, оставайтесь на очереди. Если процесс длится часы или дни, затрагивает несколько систем, и людям нужен надёжный статус на каждом шаге, движок рабочих процессов позже сэкономит много болезненного кастомного кода.
Как выбрать для своего приложения
Выбор в споре Node.js queues vs workflow engines становится проще, когда вы перестаёте думать о инструментах и начинаете описывать саму работу. Запишите весь путь на бумаге: что запускает процесс, что делает каждый шаг, где он хранит данные и что считается завершением.
Потом отметьте все места, где поток ждёт. Сюда входят ожидание callback от платёжки, ответа email-сервиса, одобрения человека, стороннего API или отложенного запуска до завтрашнего утра. Ожидание меняет характер задачи. Короткая работа может лежать в очереди. Долгий процесс нуждается в памяти.
Следующая проверка — сбой. Если ваше приложение падает на середине, что произойдёт, когда оно снова поднимется? Запишите это шаг за шагом. Если ответ звучит как «надеемся, повтор решит проблему», обычной очереди, скорее всего, уже не хватает.
Некоторые шаги можно безопасно выполнить дважды. Другие — нет. Отправить одно и то же приветственное письмо дважды неприятно. Списать карту дважды — уже серьёзная проблема. Отметьте шаги, которые не должны происходить больше одного раза, а потом подумайте, как вы будете соблюдать это правило при повторах, перезапусках и деплоях.
Вот короткий чек-лист:
- Если работа стартует, завершается и повторяется за секунды, очереди обычно достаточно.
- Если процесс ждёт внешние события или долгие таймеры, движок рабочих процессов часто безопаснее.
- Если вам нужно видеть точное состояние после падения, надёжное выполнение рабочих процессов начинает окупаться.
- Если один неудачный шаг требует компенсации или осторожного повторного прогона, выбирайте инструмент, который хранит историю, а не только статус задачи.
Перед тем как решиться, проверьте один неприятный сценарий. Убейте воркер в середине выполнения. Верните таймаут от зависимости. Отправьте одно и то же событие дважды. Такой маленький тест расскажет вам больше, чем любой список функций.
Моё мнение простое: используйте очередь для коротких, независимых фоновых задач Node.js. Используйте движок рабочих процессов, когда процесс имеет устойчивое состояние, долгие ожидания и строгие правила для повторов и сбоев. Небольшие команды очень много выигрывают, если принимают это решение заранее, особенно когда приложение начинает работать с деньгами, данными клиентов или внешними системами.
Простой пример, который показывает разницу
Представьте магазин на Node.js, который обрабатывает запросы на возврат денег. Первый шаг простой: создать тикет в поддержке и отправить клиенту письмо с подтверждением. Для такой задачи очередь подходит отлично. Если воркер остановится на середине, он может повторить попытку. Если письмо уйдёт дважды, получится небольшой беспорядок, но не денежная проблема.
Поток меняется, когда возврат должен одобрить человек. Небольшие возвраты могут проходить сразу, а крупные иногда ждут менеджера. Такая пауза может длиться пять минут или два дня. Очередь может обрабатывать части этого процесса, но команды часто в итоге распыляют его между cron-проверками, флагами статусов, отложенными задачами и кастомными правилами повторов. Возврат уже не живёт в одном месте.
Теперь добавим рискованный шаг: провести возврат через платёжного провайдера и вернуть товар на склад. Эти действия нельзя запускать дважды. Если вызов платёжной системы таймаутится уже после того, как провайдер отправил деньги, слепой повтор может сделать второй возврат. Если товар вернётся на склад дважды, складской учёт быстро станет неверным.
Движок рабочих процессов справляется с этим лучше, потому что хранит одну надёжную запись всего запуска возврата. Этот запуск знает:
- кто запросил возврат
- одобрил ли его менеджер
- завершился ли уже платёжный шаг
- изменился ли уже складской остаток
- что должно произойти, если приложение перезапустится
Пауза на одобрение — часть того же запуска, а не отдельный трюк вокруг очереди. Когда менеджер нажимает «одобрить», workflow продолжает работу с точного места, где остановился. Если воркер Node.js падает, workflow возобновляется с сохранённым состоянием. Вам не нужно собирать историю заново из логов, полей базы данных и незавершённых задач.
Вот практическая разница. Очередь отлично подходит для изолированной работы вроде отправки письма, уменьшения изображения или очистки кэша. Workflow окупается, когда один бизнес-процесс растягивается во времени, требует участия человека, взаимодействует с внешними системами и включает шаги, которые должны произойти только один раз. В таком случае хранить всю историю в одном запуске намного дешевле, чем потом разгребать последствия.
Ошибки, которые команды совершают в начале
Команды обычно попадают в неприятности, когда фоновая задача перестаёт быть одной изолированной работой и превращается в последовательность с бизнес-состоянием. Код по-прежнему выглядит небольшим. Но сценарии сбоев — уже нет.
Одна из частых ошибок — связывать задачи очереди в цепочку и передавать состояние через самодельные таблицы. Задача A пишет строку, задача B читает её, задача C обновляет ещё один флаг — и вскоре три разных места считают себя источником правды. После нескольких изменений продукта уже никто не может сказать, заказ в ожидании, сломан или наполовину завершён.
Держать прогресс только в памяти — ещё одна ранняя ловушка. На одном локальном процессе это работает, поэтому кажется нормальным. Потом Node.js перезапускается, контейнер переезжает или прилетает деплой — и воркер забывает, что уже произошло.
Тогда простая работа превращается в угадайку. Приложение уже отправило письмо? Уже зарезервировало товар? Уже вызвало billing API? Если ответ живёт только в RAM, вы на самом деле ничего не знаете.
Повторы могут создать ещё большие проблемы
Повторы кажутся безобидными, пока в игру не входят деньги. Воркер списывает деньги с клиента, а потом падает до того, как сохранит успех. Очередь видит сбой и запускает шаг ещё раз. Теперь клиент получил двойное списание, а у поддержки очень тяжёлое утро.
Именно здесь повторные попытки и сбои перестают быть мелкой инженерной деталью. Любой шаг, который переводит деньги, создаёт отправление или запускает действие во внешнем сервисе, нуждается в идемпотентности, таймаутах и понятном правиле восстановления.
Команды часто затыкают дыры cron-задачами, которые каждую минуту ищут «застрявшую» работу. Какое-то время это помогает, но одновременно скрывает реальную проблему. Система не понимает своё состояние, поэтому отдельный скрипт пытается угадать его позже.
Такие cron-очистки тоже быстро стареют. Один медленный downstream-сервис — и задача очистки помечает нормальную работу как зависшую. Одно изменение схемы — и скрипт восстановления начинает пропускать строки.
Правила восстановления должны существовать до продакшена
Многие команды откладывают ручные правила восстановления до первого серьёзного инцидента. Это неверный порядок. До запуска кто-то должен знать, какие шаги можно повторять, какие нужно останавливать и когда должен подключаться человек.
Полезное простое правило: если для завершения обычных бизнес-процессов вашей команде нужны админские скрипты, ручные правки базы или cron-задачи для спасения потоков, обычные фоновые задачи Node.js уже работают на пределе. Обычно именно тогда надёжное выполнение рабочих процессов начинает окупаться.
Быстрая проверка перед выбором
Очереди подходят, пока работа не должна переживать время, сбои и человеческие задержки. Если ваши фоновые задачи Node.js длятся несколько секунд, затрагивают одну систему и безопасно повторяются, библиотека очередей обычно сохраняет простоту. Разница в большинстве решений Node.js queues vs workflow engines становится заметной, когда один запуск может стоять часами, проходить через несколько систем или требовать аккуратного восстановления после сбоя.
Перед выбором задайте несколько прямых вопросов:
- Процесс ждёт человека, клик по письму, webhook или медленный внешний API? Короткие задачи хорошо живут в очереди. Долгие паузы часто требуют собственной системы отслеживания состояния.
- Если воркер умрёт на середине, сможет ли приложение восстановить точный шаг, на котором оно остановилось? Если нет, кто-то потом будет воссоздавать это состояние наугад.
- Может ли повторная попытка отправить одно и то же письмо дважды, списать деньги дважды или создать дублирующие записи? Как только появляются побочные эффекты, повторы перестают быть мелочью.
- Нужна ли вам читаемая история каждого запуска? Логи помогают инженерам, но поддержке нужен понятный таймлайн, а не гора строк из логов.
- Может ли кто-то ответить на вопрос «Где застрял этот клиент?» без открытия логов и без обращения к разработчику? Если нет, стоимость поддержки быстро растёт.
Простой сценарий регистрации показывает разницу. Создать аккаунт одной задачей легко. Но если процесс создаёт аккаунт, ждёт подтверждения по email, подготавливает рабочее пространство, вызывает биллинг и повторяется вокруг нестабильных API, обычная очередь начинает обрастать заплатками. Команды добавляют таблицы статусов, флаги повторов, задачи таймаутов и скрипты ручного восстановления. На первый день такой код редко кажется сложным. Сложным он становится через полгода.
Надёжное выполнение рабочих процессов начинает окупаться, когда сама система помнит прогресс, повторяет нужный шаг и показывает полную историю запуска. Это ещё важнее, если клиенты или служба поддержки должны видеть статус, не читая логи.
Если вы ответили «да» на три или больше из этих вопросов, движок рабочих процессов, скорее всего, сэкономит вам время раньше, чем вы ожидаете. Если почти на все вопросы ответ «нет», оставьте очередь и сохраняйте простоту.
Что делать дальше
Начните с одного процесса, который уже доставляет боль. Выберите то, что команда проверяет слишком часто: повторные попытки биллинга, онбординг клиентов, генерацию документов или синхронизацию со сторонним API. Запишите каждый шаг на одной странице и посчитайте все передачи между вашим приложением, очередью, внешними сервисами и поддержкой.
Этот подсчёт важен. Поток из двух понятных шагов обычно остаётся простым. Поток из восьми шагов, трёх повторов и одного ручного исправления уже подсказывает, что ему нужен более жёсткий контроль.
Оставляйте простые задачи в очереди, если они остаются короткими и изолированными. Многие фоновые задачи Node.js отлично подходят под такой формат. Отправка одного письма, уменьшение изображения, очистка устаревших данных или генерация одного отчёта не требуют надёжного выполнения рабочих процессов, если задачу можно без вреда запустить заново.
Сначала переносите длинные или хрупкие потоки. Движок рабочих процессов начинает окупаться, когда процесс длится минуты или дни, ждёт внешние события, разговаривает с несколькими системами или оставляет команду в догадках после сбоя. Именно тогда выбор между Node.js queues vs workflow engines становится практическим, а не теоретическим.
Короткая проверка поможет не расползтись по объёму:
- Опишите весь поток и отметьте все повторы, таймауты и ручные шаги.
- Отметьте, какие задачи можно запускать дважды без вреда, а какие нельзя.
- Переносите сначала самый длинный или самый проблемный поток.
- Сравните стоимость миграции со временем поддержки, неудачными запусками и жалобами клиентов.
Не переносите всё сразу. Команды часто переоценивают масштабы после одного болезненного инцидента и уносят все задачи в более тяжёлую систему. Это добавляет работы там, где она не нужна. Оставляйте скучные задачи в очереди. Переносите только те потоки, где состояние, повторы и восстановление уже стоят команде реальных денег или времени.
Если хотите второе мнение, Oleg Sotnikov может посмотреть вашу архитектуру как Fractional CTO или советник для стартапов. Он работает со стартапами и небольшими командами над архитектурой ПО, инфраструктурой и AI-first разработкой, так что обычно быстро видит, где достаточно простой очереди, а где оркестрация рабочих процессов спасёт вас от повторяющихся сбоев.