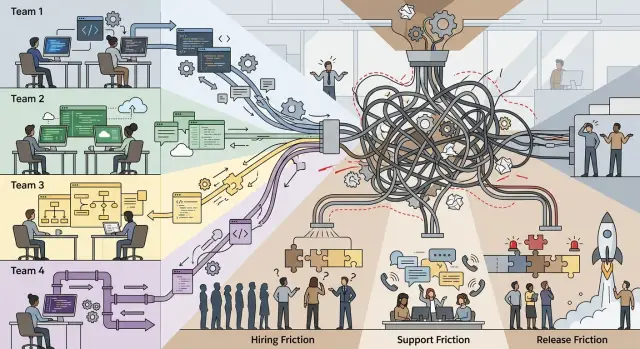
Несколько техстеков: когда свобода команд тормозит компанию
Несколько техстеков могут помочь одной команде двигаться быстрее, но часто повышают затраты на найм, поддержку и релизы для всей компании.
Содержание
Почему сначала это кажется нормальным
Когда в компании десять человек, чаще выигрывает самое быстрое решение. У одной команды горит дедлайн, она хорошо знает язык и выпускает задачу за три недели вместо шести. В моменте это обычно правильный выбор.
У другой команды может быть другая проблема, и она делает другой выбор по вполне разумным локальным причинам. Возможно, им нужна быстрая работа с данными. Возможно, они уже знают инструмент, который подходит под задачу. Они не пытаются создать хаос. Они пытаются просто сделать свою работу.
На раннем этапе почти никто не чувствует общую цену. Те же несколько инженеров могут прыгать между кодовыми базами, отвечать на вопросы в чате и чинить проблемы без большого процесса. Объём поддержки небольшой. Найм идёт достаточно медленно, чтобы всё ещё быть управляемым. Релизы не затрагивают сразу много команд.
Поэтому несколько техстеков поначалу выглядят безобидно. Лиды чувствуют доверие. Руководители видят, что фичи выходят. Клиентам всё равно, какой фреймворк создал экран, которым они пользуются каждый день.
Скрытая цена молчит, потому что компания ещё не доросла до неё. Каждый новый стек приносит свои библиотеки, шаги сборки, привычки тестирования, скрипты деплоя и странности. Это почти не мешает, пока всё ещё есть один-два человека, которые помнят вообще всё.
Простой пример показывает, почему на старте это кажется нормальным. Команда A делает внутренний инструмент на Node, потому что так можно быстро двигаться. Спустя несколько месяцев команда B выбирает Python, потому что он лучше подходит для работы с данными. Обе команды выпускают задачи. Никто никого не блокирует. Со стороны оба решения выглядят умными.
Торможение проявляется позже, не в день, когда решение было принято. Оно появляется тогда, когда компании нужно быстрее нанимать, поддерживать больше систем и выпускать изменения через несколько команд без задержек. То, что казалось локальной скоростью, превращается в дополнительную работу, которую никто не планировал.
Где начинает проявляться торможение
Проблемы начинаются, когда компания вырастает больше чем до одной-двух команд. Каждая команда всё ещё может двигаться быстро сама по себе, но общая цена растёт. Редко увидишь один большой сбой. Обычно это медленный найм, запутанная поддержка и планы релизов, для которых в комнате слишком много людей.
Первыми это часто чувствуют рекрутеры. Если одна команда использует Go, другая Node.js, а третья Python с другой облачной схемой, на каждую вакансию нужен свой поиск, свой скрининг и часто свой интервьюер. Для каждой роли это сужает пул кандидатов. Найм, который должен быть простым, превращается в три отдельных поиска.
Потом это чувствуют менеджеры. Им сложнее перекидывать людей между задачами, когда нагрузка растёт или сроки сдвигаются. Инженер, который мог бы помочь с багом или фичей, всё равно должен потратить время, чтобы разобраться в новом процессе сборки, тестовой среде, деплое и устройстве сервиса. На бумаге людей достаточно. На практике они заперты в отдельных островках.
Поддержка тоже становится тяжелее. Одна и та же проблема выглядит по-разному в каждом стеке. Логи лежат в разных местах, алерты работают по разным правилам, а у каждого приложения своя странная схема локальной разработки и исправлений в production. Саппорт и platform-команды тратят больше времени на то, чтобы вспомнить, как всё устроено, чем на саму проблему.
Межкомандные проекты замедляются по той же причине. Общая авторизация, биллинг, отчёты или клиентские данные звучат просто, пока системы не совпадают. Потом команды добавляют адаптеры, дополнительные проверки и кастомные этапы релиза только для того, чтобы всё продолжало общаться.
Именно так локальная скорость превращается в тормоз для всей компании. Компания не проигрывает потому, что один инструмент плохой. Она проигрывает потому, что слишком много инструментов мешают людям помогать друг другу.
Найм становится сложнее, чем кажется
Нанимать легко, когда компания делает ставку на небольшое число инструментов. Роль понятна, интервью сфокусировано, а менеджеры знают, какие навыки им нужны. Когда в компании несколько техстеков, этот простой процесс начинает ломаться.
Каждый дополнительный стек сужает пул кандидатов. Сильный инженер может хорошо подойти одной команде, но не знать половину инструментов, которые используются в компании. Тот, кто отлично работает с Go, может не захотеть работу, где время от времени нужно помогать с Rails и .NET. Фронтенд-разработчик может очень хорошо знать React, но всё равно ему понадобятся месяцы, прежде чем он сможет помочь с сервисом на Kotlin, который принадлежит другой команде.
Этот разрыв видно в процессе найма. Если под каждый стек нужен свой ревьюер, интервью быстро становятся длиннее. Одному кандидату может понадобиться backend-ревьюер, фронтенд-ревьюер и человек, который понимает схему деплоя. Время в календаре расползается. Хорошие кандидаты часто принимают другое предложение ещё до того, как ваша команда завершает процесс.
Растущая компания чувствует это очень практично. Представьте стартап с 35 инженерами, разделёнными на четыре стека. Один менеджер ищет Python-инженера, другому нужен специалист по Node.js, а третьему — человек, который может поддерживать старую PHP-систему и одновременно помогать с новой работой. Вместо того чтобы нанимать крепких универсалов, менеджеры начинают охотиться за редкими узкими специалистами. Потом они ещё и конкурируют друг с другом за одних и тех же людей.
Цена не заканчивается после письма с оффером. Новым сотрудникам нужно больше времени, чтобы стать полезными сразу в нескольких командах, если у каждой свой набор тестовых инструментов, привычек релиза и паттернов кода. Даже умные инженеры остаются заперты внутри одной зоны, потому что не могут безопасно перепрыгивать в остальную часть кодовой базы.
Поэтому стандартизация техстека важна раньше, чем думают многие команды. Цель не в том, чтобы все команды были одинаковыми. Цель в том, чтобы нанимать достаточно широко, чтобы сильные инженеры могли приходить, быстро входить в работу и помогать там, где компании они нужнее всего.
Поддержка расползается по слишком многим инструментам
Боль поддержки начинается тогда, когда у простого алерта больше нет одного очевидного места, где всё проверить. Один сервис пишет логи в одно место, другой использует другую панель, а у третьего свой скрипт деплоя, которому доверяет только одна команда. Компания всё ещё выпускает код, но поддержка с каждым месяцем становится медленнее.
Первой страдает on-call работа. Инженер просыпается из-за инцидента и должен вспоминать, какое приложение использует Grafana, какое прячет детали в cloud console, а какое требует ручной проверки в пайплайне GitLab. Десять лишних минут во время аварии на бумаге кажутся мелочью. В два часа ночи это уже дорого.
Большая проблема — передачи между командами. Баг начинается во frontend, проявляется в API и заканчивается в фоновой задаче, которую другая команда написала на другом стеке. Никто не может уверенно проследить весь путь, поэтому тикет ходит от команды к команде. Каждая передача добавляет задержку, а пользователям всё равно, какая команда владела промежуточным шагом.
Общие исправления тоже перестают быть простыми. Патч безопасности, изменение логирования или правило повторной попытки звучат как одна задача. В компании с несколькими техстеками это превращается в четыре чуть разных задачи с четырьмя шансами что-то пропустить. Одна команда обновляет быстро, другой нужен кастомный обходной путь, а третья ломает production, потому что та же идея по-разному ведёт себя в её фреймворке.
Потом мелкие проблемы начинают ждать одного человека, который знает эту схему. Этот человек становится узким горлышком, даже если не просил об этом. Если он в отпуске, на встречах или уходит из компании, мелкая поддержка может зависнуть на дни.
Oleg Sotnikov часто видит такой паттерн в растущих командах. Локальные решения выглядят безобидно, пока поддержка не затрагивает все системы сразу. Цена — это не только расползание инструментов. Это более медленная реакция на инциденты, более длинные циклы исправления багов и слишком много знаний о компании, запертых в нескольких головах.
Релизы превращаются в координационную работу
Выпустить одну фичу через три команды иногда дольше, чем её сделать. Так бывает, когда у каждой команды свой процесс сборки, тестирования и деплоя, даже если каждая отдельно работает хорошо.
Одна команда пушит код два раза в день. Другая ждёт еженедельного окна релиза. Третьей нужны ручные проверки от ops, прежде чем что-то попадёт в production. По отдельности ни одно из этих решений не выглядит ужасно. Но если сложить их вместе, релизы превращаются в ожидание.
Проблема становится хуже, когда изменение проходит через границы сервисов. Небольшое обновление авторизации, биллинга или прав доступа часто затрагивает больше одной кодовой базы. Разработчики не просто заканчивают свою часть и идут дальше. Они ждут, пока другая команда сольёт изменения, прогонит тесты в другом пайплайне и задеплоит по другому графику.
Растущая компания обычно чувствует это в нескольких очевидных местах:
- Pull request остаётся открытым, потому что зависимый сервис ещё не готов.
- QA снова и снова проверяет одно и то же в разных окружениях.
- Менеджеры релиза тратят время на то, чтобы выяснять статус, а не выпускать продукт.
- Мелкие баги не попадают в релиз, потому что один из пайплайнов упал слишком поздно.
Откат — это момент, когда боль становится особенно заметной. Если сервисы ведут себя по-разному, у команды нет одного понятного плейбука на случай сбоя. Одна команда откатывает через feature flag. Другая заново деплоит предыдущий контейнер. Третья вручную откатывает изменение в базе данных. Время идёт, пока клиенты ждут.
Одна из причин, почему несколько техстеков обходятся дороже, чем кажется, — это не сам выбор инструмента. Настоящие расходы появляются в координации: встречи, передачи, повторное тестирование, freeze на релизы и ночные исправления, которые должны были быть рутиной.
Простой пример это хорошо показывает. Допустим, компания меняет flow ценообразования. Команда веб-приложения выпускает изменения через GitHub Actions, команда API использует runners GitLab, а команда биллинга до сих пор деплоит по ручному чек-листу. Код может быть готов к среде, но релиз уезжает на следующую неделю, потому что последний dependency не попадает в своё окно.
Команды часто винят планирование, когда дата релиза сдвигается. Иногда планирование и правда нормальное. Но чаще проблема в том, что у компании нет общей формы релиза. Если шаги сборки, правила тестов и способы отката слишком разные, любое межкомандное изменение превращается в кастомную работу.
Стандартный процесс не означает, что каждый сервис обязан использовать один и тот же язык или фреймворк. Это значит, что у команд должен быть достаточно общий путь релиза, чтобы изменения двигались предсказуемо, а исправления не зависели от того, кто случайно был онлайн ночью.
Простой пример из растущей компании
Представьте софтверную компанию с тремя продуктовыми командами и примерно 25 людьми. Руководство даёт каждой команде свободу выбирать свои инструменты. Одна команда делает клиентские фичи на TypeScript и Next.js, другая пишет backend-сервисы на Go, а третья занимается внутренними процессами на Python.
Сначала это выглядит разумно. Каждая команда двигается быстро, потому что никто не ждёт корпоративного правила, общего шаблона или долгого спора о стандартизации техстека. Обновления по roadmap выходят вовремя, и каждая команда чувствует себя продуктивной.
Проблемы начинаются, когда клиентские проблемы перестают помещаться внутри одной команды.
Клиент открывает тикет: его аккаунт обновился, но новые возможности не включились. Поддержка проверяет экран биллинга, потом профиль пользователя, потом фоновую задачу, которая применяет изменения тарифа. Баг проходит через три сервиса, которыми владеют три разные команды.
Теперь support не может решить проблему одним понятным маршрутом. Одна команда смотрит логи приложения в одном месте, другая использует другой процесс деплоя, а третья по-другому называет события. Никто не делает плохую работу, но издержки на поддержку ПО растут, потому что компании нужно соединить три маленьких мира, чтобы ответить одному клиенту.
То же самое происходит с продуктовыми изменениями. Простой запрос вроде добавления продления free trial для определённых пользователей звучит небольшим на планировании. На практике одна команда меняет логику checkout, другая — права доступа к аккаунту, а третья — административный инструмент, через который support применяет оффер.
Одно изменение затрагивает несколько кодовых баз, тестовых сред, календарей релизов и владельцев. То, что выглядело как задача на два дня, превращается в неделю координации, повторных проверок и ожидания совпадающих релизов.
Именно здесь несколько техстеков перестают ощущаться как свобода команд и начинают ощущаться как тормоз для компании. Локальная скорость реальна, но она остаётся локальной. Как только работа пересекает границы команд, почти всегда следуют сложность релизного процесса и затраты на найм инженеров: каждая общая задача становится медленнее, а каждому новому человеку нужно больше времени, чтобы стать полезным.
Как задать правила по техстеку и не заморозить команды
Свобода работает лучше, когда у людей есть стандарт по умолчанию, а не пустой лист. У команд по-прежнему остаётся пространство для работы, но компания больше не платит за случайные решения через несколько лет.
Начните с простого инвентаря. Запишите все языки, фреймворки, базы данных, инструменты фоновых задач, схему хостинга и путь деплоя, которые люди используют сегодня. Большинство компаний думают, что у них пять или шесть вариантов стека. Когда они всё перечисляют, обычно оказывается в два-три раза больше.
Потом отметьте те варианты, которые сильнее всего стоят компании за пределами исходной команды. Стек может быть быстрым для одной группы и всё равно создавать проблемы позже, если найм занимает больше времени, on-call требует специальных знаний, или релизы зависят от одного человека, который знает странную схему.
Хороший набор правил обычно небольшой:
- Выберите один стандартный backend-язык и один стандартный frontend-фреймворк для новых продуктов.
- Выберите одну-две базы данных, которые покрывают большинство обычных случаев.
- Выберите один стандартный путь деплоя с одинаковым CI/CD-паттерном и настройкой мониторинга.
- Разрешайте исключения только тогда, когда команда письменно объясняет причину, ожидаемую пользу и кто будет поддерживать решение.
- Раз в квартал или раз в полгода пересматривайте полный список и осознанно убирайте старые варианты.
Речь не о том, чтобы загнать все команды в одну форму. Речь о том, чтобы сделать простой выбор безопасным выбором. Если команде нужен инструмент вне стандарта, она должна показать, почему выигрыш стоит дополнительных затрат на найм и поддержку.
Одно правило для стартапов работает хорошо: новые задачи используют стандартный стек, если только команда не может указать на реальное ограничение, а не на предпочтение. «Мы уже знаем этот инструмент» — обычно слабая причина. «Этому клиенту нужна офлайн-синхронизация, а наш стандартный стек не справляется» — гораздо сильнее.
Oleg Sotnikov часто помогает компаниям внедрять AI-first разработку, не давая затратам расти в том же темпе. Здесь работает та же идея: держите стандартный путь компактным, делайте исключения заметными и убирайте старые инструменты, пока они не стали постоянным балластом.
Так команды получают немного свободы, но несколько техстеков не превращаются тихо в корпоративную норму.
Ошибки, которые усиливают расползание стека
Проблема нескольких техстеков редко начинается с плохой идеи. Обычно всё начинается с разумного сокращения пути. Команде нравится язык, она хорошо знает фреймворк или хочет быстро выдать один проект. Один-два раза это нормально. Проблемой это становится тогда, когда предпочтение команды начинают считать бизнес-необходимостью.
«Мы знаем этот инструмент» — это не то же самое, что «компании нужен этот инструмент». Если причина — в удобстве, цена проявится позже в найме, поддержке и релизах.
Другая частая ошибка — вечно держать старые инструменты, потому что миграция кажется болезненной. Команды избегают одного большого переезда, а потом платят небольшой налог каждый месяц. Кому-то нужно патчить старые сервисы, поддерживать странные скрипты сборки и отвечать на вопросы о коде, к которому никто не хочет прикасаться.
Один проект по очистке часто стоит меньше, чем годы постоянного мелкого трения.
Срочные задачи усугубляют проблему. Когда каждый авральный проект стартует с нуля, команды хватают то, что кажется самым быстрым на этой неделе. Одна группа выпускает на Node.js, другая использует Go, а третья добавляет Python, потому что у подрядчика уже есть готовый код. По отдельности каждое решение разумно. Вместе они создают больше CI-пайплайнов, больше правил деплоя и больше людей, которые могут поддерживать только одну часть продукта.
Растущей компании стоит хотя бы определить несколько стандартов:
- Какие языки и фреймворки использовать в новых проектах.
- Когда команде можно просить исключение.
- Кто отвечает за общие инструменты и шаблоны деплоя.
- Когда старые стеки нужно выводить из эксплуатации.
Противоположная ошибка — попытаться загнать всё в один стек сразу. Обычно это создаёт больше сопротивления, чем пользы. Команды перестают доверять правилу, потому что оно игнорирует реальные различия между продуктами, сроками и потребностями клиентов.
Лучший подход скучный, и именно поэтому он работает. Сначала задайте стандарт для новых задач. Оставьте короткий список исключений. Переводите старые системы тогда, когда всё равно трогаете их по другой причине, или когда стоимость поддержки становится слишком высокой, чтобы её игнорировать.
И наконец, многие компании выбирают стандарты, но пропускают то, что делает их удобными. Они пишут правило и останавливаются. Нет документации, нет стартовых репозиториев, нет обучения, нет примеров. Команды возвращаются к тому, что уже знают.
Правило на слайде ничего не делает. Короткая внутренняя инструкция, рабочий шаблон и один человек, который поможет в первую неделю, дадут гораздо больше. Если команда просит новый стек, задайте два вопроса: какую проблему стандарт не решает и кто будет поддерживать это решение через год.
Быстрая проверка перед тем, как добавить ещё один стек
Вот так несколько техстеков и проникают в компанию: каждое решение кажется маленьким само по себе. Одна команда хочет двигаться быстрее, для одной фичи нужна особая библиотека, один инженер хорошо знает инструмент. Счёт приходит позже, когда другим людям приходится это поддерживать, тестировать, защищать и деплоить.
Короткая пауза перед утверждением помогает гораздо больше, чем длинная расчистка потом.
- Проверьте, кто сможет поддерживать это после рабочего времени. Если чинить в 10 вечера может только один человек, команда на самом деле ещё не поддерживает это решение. У вас есть слабое место.
- Проверьте, сможете ли вы нанять людей под это за свой бюджет. Некоторые стеки выглядят простыми для внедрения, но найти под них сильных специалистов оказывается дольше и дороже.
- Проверьте, понадобится ли другой команде читать или менять код. Если позже к нему могут прикоснуться data-, support-, infra- или product-инженеры, привычные инструменты обычно экономят время.
- Проверьте, не создаёт ли это новый путь деплоя, тестирования или безопасности. Новый runtime, система пакетов, CI-job или схема секретов добавляют работу в каждый релиз, а не только в этот.
- Проверьте, укладывается ли бизнес-выгода в одно предложение. «Это сокращает обработку счёта с 15 минут до 3» — понятно. «Так чище» — не слишком сильная причина сама по себе.
Небольшой пример хорошо показывает компромисс. Если команда добавляет новый язык для одного внутреннего сервиса, первый вариант она может выпустить быстро. Через шесть месяцев другой команде нужно изменить этот сервис, security нужен новый сценарий сканирования, а релизной команде приходится поддерживать ещё один шаблон деплоя. Первая выгода была реальной, но постоянная цена — тоже реальна.
Одно правило работает хорошо: если новый стек добавляет новую проблему с наймом, новое дежурство on-call и новый рабочий процесс релизов, относитесь к нему как к решению для всей компании. Если вы не можете ясно объяснить бизнес-выгоду, лучше оставайтесь на том, что команда уже знает.
Что делать дальше
Начните с карты на одной странице. Запишите все стеки, которые используются, кто за них отвечает, что они запускают и где создают боль. Пишите просто: задержки найма, блокеры релизов, нестабильные передачи, пробелы в on-call или инструменты, которые понимает только один человек. Вам не нужен идеальный аудит. Вам нужен ясный взгляд на то, где несколько техстеков уже отнимают время.
Потом выберите самое шумное место и исправьте его первым. Растущая компания обычно получает больше пользы от одного аккуратного исправления, чем от широкой программы стандартизации, которую никто не доводит до конца. Если три команды используют разные способы выпускать один и тот же тип сервиса, начните с этого. Если поддержка постоянно мечется между frontend, backend и infra из-за разных инструментов, исправьте именно это.
Простой план часто выглядит так:
- Составьте список каждого стека, его владельца и той боли, которую он создаёт сейчас.
- Выберите одну область, где одна и та же работа делается слишком многими разными способами.
- Задайте стандартные инструменты для новых проектов и для общих сервисов, таких как логирование, CI, алерты и деплой.
- Разрешите командам просить исключения, но заставляйте их объяснять дополнительные затраты на найм, поддержку и релизы.
Стандарты важнее, чем жёсткие запреты. Большинство команд будут следовать стандарту, если он экономит им время и если путь к нему удобный. Напишите короткую внутреннюю заметку о том, каким должен быть стандартный backend, frontend, база данных, тестовая схема и путь деплоя для новых задач. Сделайте её достаточно короткой, чтобы люди действительно её прочитали.
Если всё упирается в бесконечные споры, помогает внешний взгляд. Oleg Sotnikov через oleg.is работает со стартапами и небольшими компаниями над практичными решениями по техстеку, поддержкой Fractional CTO и AI-driven workflow для разработки. Полезная часть здесь — не большой переписанный проект. Полезно получить ясные рамки, которые снижают трение при найме, издержки на поддержку и задержки релизов.
Цель не в одном стеке для всей компании. Цель — в меньшем числе избежимых решений, меньшем числе передач и в таком процессе релизов, которому люди могут доверять.
Часто задаваемые вопросы
Иногда нормально, если команды используют разные техстеки?
Да, если причина реальная, а выгода понятна. Несколько исключений не навредят.
Проблемы начинаются тогда, когда каждая команда выбирает всё с нуля просто потому, что так быстрее. Задайте стандартный техстек для новых задач, а исключения разрешайте только тогда, когда стандарт действительно не подходит.
Нам всего 20–30 человек. Уже нужны правила по техстеку?
Скорее всего, да. Вам не нужна громоздкая политика, но нужны стандартные варианты ещё до того, как привычки разойдутся слишком далеко.
Как только работа начинает пересекать несколько команд, издержки растут быстро. Если подождать, пока начнут страдать поддержка, найм и релизы, исправлять ситуацию будет гораздо сложнее.
Почему найм замедляется, когда каждая команда выбирает свои инструменты?
Потому что больше техстеков означает больше узких вакансий, больше сценариев собеседований и меньший пул кандидатов на каждую роль. Руководители перестают нанимать сильных инженеров, которые могли бы вырасти внутри продукта, и начинают искать точные совпадения.
Это же замедляет вход в работу. Новый сотрудник может помочь одной команде, но ему нужно больше времени, прежде чем он сможет переключаться туда, где компании он нужнее всего.
Почему из-за нескольких техстеков поддерживать тикеты сложнее?
Проблемы поддержки появляются, когда одна клиентская проблема затрагивает несколько систем, которые работают по-разному. Логи лежат в разных местах, команды по-разному называют события, а у каждого сервиса свой процесс исправления.
Тикет начинает ходить по командам вместо того, чтобы решиться за один проход. Это тратит время и запирает слишком много знаний в голове у нескольких людей.
Почему релизы сдвигаются, хотя каждая команда сама по себе работает быстро?
Локальная скорость не гарантирует скорость всей компании. Одна команда может выкатывать изменения дважды в день, другая ждёт еженедельное окно, а третья всё ещё использует ручные проверки.
Когда изменение проходит через несколько таких команд, оно превращается в координационную работу. Люди ждут слияния, прогонов тестов, согласований и разных способов отката вместо того, чтобы просто выпускать фичу.
Что стандартизировать в первую очередь?
Начните с общего пути. Стандартизируйте логи, мониторинг, CI, шаги деплоя и базовые варианты backend и frontend для новых задач.
Такие изменения быстрее снимают ежедневное трение, чем долгие споры о языках. И они сразу делают поддержку и релизы более предсказуемыми.
Как разрешать исключения и не устроить хаос?
Оставьте один основной путь и просите команды обосновывать исключения простым языком. Пусть они объяснят бизнес-причину, ожидаемую пользу и кто потом будет это поддерживать.
Если причина — в основном привычка или личный вкус, отклоняйте запрос. Так вы сохраните свободу для реальных потребностей, не превращая предпочтения в политику.
Нужно ли сразу переписывать старые сервисы на один стек?
В большинстве случаев — нет. Принудительное переписывание добавляет риски и съедает время, которое команды могли бы потратить на продукт.
Переводите старые сервисы только тогда, когда поддержка уже слишком дорогая, найм под этот стек постоянно буксует или код всё равно нужно менять по другим причинам.
Что проверить перед тем, как утвердить новый стек?
Сначала смотрите на поддержку вне рабочего времени, найм и влияние на релизы. Если чинить может только один человек, если нанимать дорого и сложно, или если появляется новый путь тестов и деплоя, то это уже не локальное решение одной команды.
Когда новый стек приносит все три вида затрат, относитесь к нему как к решению для всей компании, а не как к быстрому локальному обходному пути.
Кто должен отвечать за правила по техстеку?
Назначьте одного технического владельца стандартов. В небольшой компании это часто CTO или Fractional CTO, который работает вместе с инженерными лидами.
Этот человек должен поддерживать актуальность стандарта, разбирать исключения и убирать старые варианты, пока они не накопились в лишний балласт. Общие правила не работают, если за них никто не отвечает.


