Настройки пула подключений, которые нужно поправить до всплесков трафика
Настраивайте пул подключений по реальным шаблонам трафика: размер пула, таймаут ожидания и лимиты запросов, чтобы пользователи не столкнулись с замедлениями.
Содержание
Что идёт не так при росте трафика
Значения пула по умолчанию часто кажутся приемлемыми в staging, потому что в тестовой среде редко имитируется поведение production. Небольшой всплеск реальных пользователей быстро меняет картину. Запросов приходит больше одновременно, каждый ждёт немного дольше, и вскоре в приложении не остаётся свободных соединений с базой.
Именно поэтому настройки пула подключений проваливаются под нагрузкой, даже когда у базы ещё есть свободная ёмкость. Проблема обычно начинается на уровне приложения. Потоки или воркеры накапливаются в очереди, время ответа растёт, и одна медленная минута превращается в отставание.
Когда пул заполнен, новые запросы продолжают приходить. Они ждут свободного соединения, а потом ждут ещё дольше, потому что предыдущие запросы уже заняли очередь. Если включаются ретраи, приложение добавляет ещё больше давления, и очередь снова растёт.
Пользователи обычно видят симптомы раньше, чем команда обнаруживает причину. Страницы загружаются медленнее. Оформление заказа или вход в систему занимают несколько секунд. Некоторые операции падают с ошибкой таймаута, а при повторной попытке проходят. Это делает проблему случайной на вид, хотя схема довольно простая.
Часто признаки появляются вместе: времена отклика подпрыгивают даже для простых страниц, доля ошибок растёт в коротких всплесках, повторы увеличивают общий объём работы базы, а CPU может оставаться в норме, пока очереди запросов растут.
Эта последняя деталь сбивает с толку. Команды часто винят базу, потому что пользователи видят ошибки БД, но реальная проблема сидит между приложением и базой. Слишком маленький пул создаёт ожидание. Слишком большой пул тоже вреден — слишком много активных запросов будут конкурировать за одни и те же ресурсы базы.
Разницу обычно видно по тому, куда уходит время. Если запросы проводят большую часть времени в ожидании соединения, узкое место — поведение пула. Если соединение получается быстро, но запросы выполняются медленно, узкое место — скорость запросов или нагрузка на базу.
Размер пула должен основываться на реальных сценариях нагрузки, а не на дефолтах из гайда фреймворка. Хорошие таймауты и разумные лимиты запросов не дадут коротким всплескам перерасти в падение сервиса.
Настройки, которые проверяют в первую очередь
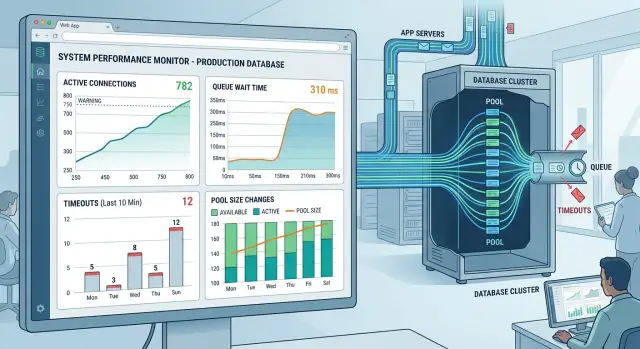
Настройки пула подключений контролируют, сколько запросов одновременно попадает в базу, как долго каждый запрос может ждать и когда старые соединения стоит заменять. По умолчанию в тестах всё может выглядеть безобидно, но при реальном наплыве пользователей это ломается.
Размер пула — число соединений с базой, которые приложение может держать открытыми и повторно использовать. Представьте это как число касс между приложением и базой. Слишком мало — запросы встают в очередь, хотя у базы ещё есть место. Слишком много — приложение накачивает базу работой, которую она не успевает быстро обработать.
Начните с четырёх настроек: pool size, wait timeout, idle timeout и max lifetime.
Pool size — сколько открытых соединений приложение может использовать одновременно. Wait timeout — сколько времени запрос ждёт свободного соединения, прежде чем приложение откажется. Idle timeout — как долго неиспользуемое соединение может простаивать, прежде чем пул закроет его. Max lifetime — как долго соединение может жить, прежде чем пул его заменит.
Wait timeout быстро влияет на пользовательский опыт. Если он слишком большой, запросы зависают и накапливаются, из‑за чего весь сервис кажется застрявшим. Если слишком мал — приложение отбрасывает запросы при кратких всплесках, которые пул мог бы поглотить. Во многих случаях небольшой таймаут работает лучше, чем огромный: он быстро падает и показывает вам узкое место.
Idle timeout и max lifetime решают более тихую проблему. Базы, прокси и сети не любят старые соединения, которые висят бесконечно. Idle timeout очищает неиспользуемые соединения. Max lifetime ротацией предотвращает устаревание соединений, попадание в серверные лимиты или накопление невидимых проблем.
Лимиты запросов лежат выше пула. Пул контролирует доступ к базе. Лимиты запросов определяют, сколько работы каждый запрос может потребовать после получения соединения. Если одна загрузка страницы запускает 25 запросов, большой пул не спасёт вас долго. Ограничьте количество запросов, следите за повторяющимися запросами и прерывайте очень долгие запросы жёстким лимитом.
Команды с экономной инфраструктурой учатся этому быстро. Маленький, хорошо настроенный пул с разумными таймаутами часто лучше, чем огромный пул без ограничений. Дополнительные соединения не исправят медленные запросы, «говорливые» эндпоинты или тяжёлые транзакции — они просто позволят этим проблемам происходить параллельно.
Измеряйте реальную нагрузку
Большинство плохих настроек пула начинают с догадки. Команды копируют дефолтный размер пула, проводят быстрый тест и предполагают, что база выдержит при росте трафика. Обычно это работает до первого часа пик.
Начинайте с чисел из нормального загруженного периода. Не тихого вторника утром и не лабораторного теста с идеальными запросами. Используйте логи, метрики и статистику БД из моментов, когда реальные пользователи, фоновые задания и планировщик одновременно нагружают систему.
Несколько показателей важнее остальных: средняя скорость запросов и короткий пиковый уровень, как долго каждый запрос удерживает соединение, сколько воркеров и плановых задач обращаются к базе и соотношение чтений и записей.
Время удержания соединения (connection hold time) — то, что команды чаще всего пропускают. Запрос может завершиться за 300 мс, но соединение с базой было занято только 40 мс. Бывает и наоборот. Один медленный отчёт может удерживать соединение несколько секунд и блокировать все последующие. Если вы не измеряете время удержания соединения, размер пула остаётся предположением.
Фоновые работы часто скрывают реальную нагрузку. Импорты, отправки писем пачками, прогрев кеша, синхронизации и админ‑отчёты все конкурируют за тот же пул, если вы этого допускаете. Система, которая выглядит нормально при чистом веб‑трафике, может упасть, как только эти задания стартуют в начале часа.
Чтения и записи ведут себя по‑разному. Чтения часто короткие и параллельные. Записи могут вызывать блокировки, более длинные транзакции и ретраи. Если приложение смешивает оба типа в одном пуле, нужно знать баланс, прежде чем менять таймауты или лимиты.
Простой пример проясняет это. Допустим, приложение обрабатывает в среднем 25 запросов в секунду, на пике до 70 в течение двух минут, и каждую минуту запускает восемь воркеров. Если большинство веб‑запросов держат соединение 20–50 мс, пул может оставаться в порядке. Но если одна отчётная задача удерживает шесть соединений по четыре секунды каждая, нагрузка базы при всплеске будет выглядеть намного хуже, чем число веб‑запросов подсказывает.
Используйте реальные загруженные периоды, измеряйте, что действительно трогает базу, и настраивайте от этого. Дефолты — дешёвые догадки. Производственный трафик — нет.
Часто задаваемые вопросы
What usually causes connection pool problems during traffic spikes?
Всплески трафика часто заполняют пул подключений приложения ещё до того, как база данных исчерпает свою сырую ёмкость. Запросы ждут свободного соединения, очереди растут, а ретраи добавляют ещё больше нагрузки.
Поэтому страницы замедляются, хотя загрузка CPU на БД может выглядеть нормальной — приложение тратит время на ожидание, а не на полезную работу.
How can I tell if my pool is too small?
Сначала смотрите время ожидания в очереди. Если запросы проводят много времени, ожидая свободного соединения, вероятно, пул слишком мал для текущей нагрузки.
Пользователи часто видят медленные входы, медленный чек-аут и ошибки таймаута, которые исчезают при повторной попытке. Этот рисунок обычно указывает на давление на пул, а не на случайные сбои.
Can my pool be too large?
Да. Очень большой пул позволяет слишком многим запросам одновременно обратиться к базе, и БД может существенно замедлиться под такой нагрузкой.
Вы можете увидеть временное улучшение времени ожидания, а затем рост времени выполнения запросов, загрузки CPU и конфликтов блокировок. Больше соединений не исправит медленные SQL‑запросы или тяжёлые транзакции.
Which pool settings should I check first?
Сначала проверьте размер пула, таймаут ожидания, таймаут простоя и максимальное время жизни соединения. Эти настройки определяют, сколько запросов доходит до БД, как долго они ждут и когда пул обновляет старые соединения.
Затем посмотрите количество запросов и время выполнения запросов на один запрос. Если один эндпоинт запускает слишком много запросов, настройка пула лишь временно скроет проблему.
What is a reasonable wait timeout?
Для большинства пользовательских запросов держите ожидание соединения коротким. Пара сотен миллисекунд до примерно одной‑двух секунд обычно защищает приложение лучше, чем очень длинный таймаут.
Если позволять ожидать 20–30 секунд, пользователь уже думает, что страница сломалась. Короткий таймаут быстрее выявляет узкое место и держит очередь короче.
How should I choose the right pool size?
Измеряйте реальные пики, а не тесты в спокойной среде. Используйте логи и метрики из периодов, когда пользователи, фоновые задачи и cron‑работы одновременно нагружают систему.
Сосредоточьтесь на скорости запросов, кратковременных пиках, времени удержания соединения и количестве процессов, которые открывают соединения. Время удержания соединения (connection hold time) особенно важно, потому что даже быстрый веб‑запрос может держать соединение дольше, чем кажется.
Should web traffic and background jobs share one pool?
Обычно нет. Фоновые задачи могут вытеснить веб‑трафик и сделать приложение нефункциональным в пиковые моменты.
Перенесите отчёты, экспорты, импорты и другие длительные задания на отдельные воркеры или отдельный пул, если стек это поддерживает. Так авторизация, поиск и оформление заказов будут работать стабильнее.
Do retries help when the pool runs out of connections?
Одна аккуратная повторная попытка помогает при кратковременных блокировках или сетевых сбоях. Больше повторов чаще превращают замедление в повторный штурм, потому что каждый неудавшийся запрос возвращается и снова нагружает систему.
Используйте небольшую задержку с джиттером и остановитесь после одной повторной попытки. Если пул уже под давлением, цикл ретраев удлиняет очередь.
Should I tune the pool first or fix slow queries first?
Сначала исправляйте медленные запросы и «болтливые» эндпоинты, если они удерживают соединения слишком долго. Больший пул лишь даст этим проблемам происходить параллельно.
После этого меняйте размер пула малыми шагами и тестируйте в реальном пиковом окне. Изменяйте по одному параметру за раз, чтобы понимать эффект.
What should I watch after I change pool settings or ship a release?
Сравните одни и те же показатели до и после релиза: время ожидания в очереди, ошибки таймаута, медленные запросы, загрузка CPU и память БД и число соединений. Одного графика недостаточно.
Если время ожидания упало, но медленные запросы и CPU выросли, релиз не решил проблему — он просто переместил бутылочное горлышко в базу данных.


