Модули Terraform против простых стеков для стартапа с пятью сервисами
Модули Terraform против простых стеков: как стартапу с пятью сервисами выбрать более простую схему, двигаться быстрее и избежать скрытых затрат и медленных изменений.
Содержание
Почему этот выбор быстро становится сложным
Стартап с пятью сервисами становится сложнее, чем кажется. Одному сервису нужна база данных. Другому — очередь. Третий запускает фоновые задачи. Очень скоро у каждого сервиса появляются свои секреты, переменные, порядок деплоя, права доступа и state.
Поэтому выбор между модулем и стеком рано или поздно становится непростым.
В первый день общий Terraform-модуль выглядит аккуратно. Вы один раз описываете шаблон, вызываете его пять раз и убираете много повторяющегося кода. Это кажется умным решением, пока сервисы не перестают быть похожими.
Потом различий становится всё больше. API нужен autoscaling и публичный доступ. Worker нужны права на очередь, но не нужен публичный endpoint. Admin-приложению нужны более жёсткие правила доступа. Cron-сервис работает по расписанию, а не постоянно. Preview-окружениям нужны более дешёвые defaults.
Можно и дальше проталкивать всё это через один модуль, но проблема не исчезает, а просто переезжает. В модуле накапливаются переключатели, условные ветки и неудобные названия переменных. Повторяющегося кода стало меньше, но сложность осталась. Просто теперь её хуже видно.
Для стартапов эта скрытая цена особенно болезненна. На раннем этапе всё меняется каждую неделю. Небольшое обновление инфраструктуры должно затронуть один сервис и идти дальше. С общим модулем одно маленькое изменение может провести через один и тот же шаблон все сервисы, даже если реально изменился только один.
Отладка тоже замедляется. Когда деплой ломается, команда уже не начинает с сервиса. Сначала открывают модуль, идут по переменным, смотрят defaults и выясняют, какая именно ветка сработала в этом случае. На такую проблему легко потратить час, хотя простой стек показал бы её за несколько строк.
Если ваша схема всё ещё меняется, дублирование часто обходится дешевле абстракции. Стартап может жить с несколькими лишними строками Terraform. Но обычно он не может жить с медленными изменениями и туманной отладкой.
Как выглядит простой стек
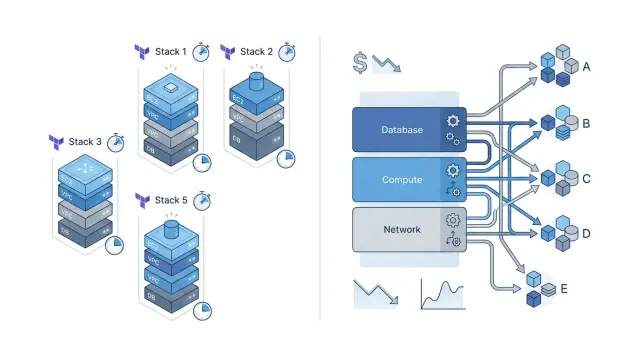
Простой стек держит каждый сервис в своей папке Terraform и со своим state. Если у стартапа пять сервисов, это могут быть пять небольших стеков: web, API, worker, admin и scheduled jobs. Каждый стек описывает только то, что нужно этому сервису, и ничего лишнего.
Да, часть кода повторяется. Но чаще всего это нормально. Можно копировать настройки провайдера, теги, несколько IAM-правил или стандартную log group. На этом масштабе понятные имена важнее, чем хитрое переиспользование. Папка вроде services/api с ресурсами api-prod быстро объясняет, что к чему.
Обычно простой стек включает настройки provider и backend, сами ресурсы сервиса, короткий список переменных и outputs только тогда, когда они действительно нужны другому стеку.
Главное преимущество — локальность изменений. Если worker нужен более длинный timeout для очереди, вы открываете стек worker и меняете его там. Не нужно править общий модуль, проверять, кто его импортирует, поднимать версии и надеяться, что ничего другого по дороге не сломается.
Поэтому простые стеки обычно кажутся спокойнее для маленьких команд. Код, который создаёт сервис, находится рядом с самим сервисом. Ревьюер может открыть одну папку и понять, что произойдёт при plan и apply.
Новые участники команды тоже выигрывают. Им не нужно прыгать между root-файлами, дочерними модулями, фиксированными версиями и скрытыми defaults. Они могут прочитать один стек сверху вниз и за один раз собрать нормальную картину.
У стартапа с пятью сервисами обычно просто не хватает повторяемости, чтобы оправдать тяжёлую абстракцию. Скопировать 30 строк в несколько стеков — это слегка раздражает. Гораздо хуже гоняться за логикой модуля по всему репозиторию.
Если держать файлы в порядке, компромисс остаётся небольшим. Используйте понятные имена, короткие списки переменных и отдельный state для каждого сервиса. Так у вас останется запас на быстрые изменения, а каждое обновление инфраструктуры не станет проектом на весь репозиторий.
Что дают модули
Модули действительно полезны, когда два или больше сервисов устроены почти одинаково. В этом случае один модуль может держать общий шаблон в одном месте и уменьшать расхождение между сервисами.
Но есть и обратная сторона — умственная нагрузка. Простой стек показывает ресурсы прямо перед вами. Модуль прячет их за входными параметрами и outputs, поэтому для понимания одного сервиса часто приходится читать уже два места. Для маленькой команды этот лишний шаг замедляет ревью, отладку и обычные правки.
Модули лучше всего работают там, где сходство настоящее. Сервисы отличаются только именем, размером и парой настроек. Инфраструктурой занимается одна команда. Шаблон повторится несколько раз. Интерфейс модуля остаётся маленьким и понятным.
Версионирование добавляет ещё одну задачу. Когда несколько сервисов завязаны на один модуль, одна правка перестаёт быть одной правкой. Вы обновляете модуль, ставите тег версии, обновляете каждый сервис, запускаете plan и выкатываете всё по одному стеку за раз. Это безопаснее, чем внезапные обновления, но быстрый штрих превращается в релизную работу.
Баг внутри модуля тоже бьёт шире. Один неудачный default, один сломанный output или одно изменение имени может сломать деплой сразу для нескольких сервисов. В простых стеках ущерб обычно остаётся локальным.
Вот почему модули часто выглядят лучше на бумаге, чем ощущаются в ежедневной работе. Они хороши, когда убирают повторение, не скрывая слишком многого. Но это плохая сделка, если они превращают очевидный код в маленький фреймворк, который понимает только один человек.
Если сегодня три сервиса похожи, но скоро, скорее всего, начнут расходиться, пока оставьте копию. Повторение раздражает. Скрытые правила хуже.
Как принять решение
Начинайте с сервисов, а не с абстракции. Выпишите, что делает каждый сервис, кто за него отвечает, какой доступ к сети и базе ему нужен и как он, скорее всего, будет масштабироваться. У стартапа с пятью сервисами обычно больше различий, чем люди ожидают.
После этого посмотрите на части, которые совпадают почти у всех сервисов. Здесь важно быть строгими. Хорошие кандидаты — скучные куски, которые почти не меняются: правила хранения логов, стандартный алерт или один небольшой IAM-паттерн. Если общий кусок меняется каждый спринт, не включайте его в модуль.
Первую версию лучше оставить простой, если различия постоянно всплывают в ревью и деплоях. Обычно это происходит, когда правила именования отличаются по сервисам, сети устроены по-разному, а настройки масштаба и безопасности настолько разные, что всем нужны исключения.
На этом этапе простые стеки читать легче. Новый инженер может открыть одну папку и увидеть реальную форму сервиса, не прыгая между переменными и outputs модуля.
Если вы всё же нашли один стабильный повторяющийся блок, сделайте только для него маленький модуль. Не заворачивайте в модуль весь сервис. Маленькие модули проще тестировать, проще удалять и они реже обрастают странными входами для крайних случаев.
Потом проверьте модуль на одном сервисе, прежде чем распространять его на все остальные. Посмотрите plan. Убедитесь, что код действительно стал короче и понятнее. Если уже сейчас нужны исключения, дополнительные флаги или обходные пути для конкретного сервиса, на этом и остановитесь.
Пересматривайте решение через несколько релизов, а не до запуска. Реальное использование покажет, что действительно повторяется, что стоит денег и что лучше оставить простым.
Простой пример на пять сервисов
Представьте стартап из пяти частей: API, background worker, web-приложение, Postgres и Redis. На таком масштабе отдельные Terraform-стеки обычно читать проще, чем одну схему с общими модулями.
Структура может оставаться очень простой:
apiworkerwebpostgresredis
Каждый стек владеет своими ресурсами, переменными и state. Когда кто-то открывает стек API, он видит только инфраструктуру API. Не нужно просматривать условные блоки, которые предназначены для других сервисов.
Это быстро начинает иметь значение. API может требовать очередь, алерты на всплески запросов и autoscaling, привязанный к трафику. Веб-приложению может хватить небольшого app service, настройки CDN и базового мониторинга. Если оба сервиса сидят в одном большом модуле, команда обычно начинает добавлять флаги вроде enable_queue = true или public_endpoint = false. Через несколько месяцев модуль уже не кажется общим — он просто становится перегруженным.
У worker будет ещё один сценарий. Он масштабируется по другой причине. API растёт, когда резко увеличивается число запросов. Worker — когда накапливаются задачи. Это влияет на размер инстансов, правила масштабирования, алерты и стоимость. Если оставить worker простым, команда сможет менять concurrency задач, не трогая настройки web или логику API.
Postgres и Redis тоже лучше держать в отдельных стеках. Изменения в базе требуют большего внимания, другого подхода к ревью и более медленного выката. Изменение кэша обычно проще и легче заменить. Отдельные стеки делают это различие очевидным.
При этом большинство команд всё равно оставляют немного общего кода. Самый частый пример — теги. Ещё один — monitoring labels. Если каждому стеку нужны одинаковый owner tag, environment tag и несколько стандартных labels, вынесите для этого один крошечный модуль и остановитесь на нём.
Для стартапа с пятью сервисами этого часто достаточно: простые стеки для сервисной инфраструктуры плюс один-два совсем небольших помощника для тех частей, которые и правда одинаковые.
Когда модули действительно помогают
Модуль оправдывает себя тогда, когда нескольким сервисам нужно одно и то же почти в одной форме. Именно в этот момент copy-paste начинает стоить дороже, чем экономит.
Если трём или более сервисам нужен один и тот же шаблон VPC, одинаковая настройка алертов или одна схема базы данных, модуль быстро убирает шум. Но настоящий тест — это исключения. Если каждому сервису нужен свой необычный subnet, своё правило policy или своя настройка масштабирования, модуль превращается в лабиринт флагов.
Названия входных параметров важнее, чем кажется. Хороший модуль использует слова, смысл которых понятен без просмотра исходников. Названия вроде service_name, instance_size или log_retention_days легко доверить. Названия вроде profile, tier или mode часто скрывают слишком много.
Следующий тест — изменения. Полезный модуль позволяет улучшать одно место и постепенно выкатывать изменения. Например, можно добавить более безопасный default, стандартные теги или ещё один алерт, не трогая всех потребителей в один и тот же день. Если одно обновление модуля требует пройтись по всему репозиторию, модуль слишком жёсткий для маленькой команды.
Полезно сначала проверить модуль на одном обычном сервисе, а не на том странном, у которого куча особых правил. Запустите plan, примените его, а потом через неделю сделайте обычное изменение. Такой маленький тест обычно сразу показывает неудобный входной параметр, недостающий output или скрытое предположение.
Для проверки удобно использовать быстрый список:
- Три или больше сервисов используют одинаковую форму ресурса почти без исключений.
- Входные параметры можно назвать простыми словами.
- Модуль можно улучшать, не ломая стабильный интерфейс.
- Один реальный сервис уже проверил его в обычной работе.
Для такой небольшой команды модули должны ощущаться скучными. Если они экономят время и не усложняют следующую правку, оставляйте их. Если для объяснения нужен длинный рассказ, значит вы пришли к ним слишком рано.
Ошибки, из-за которых команды теряют время
Маленькие команды чаще всего спотыкаются о слишком раннюю абстракцию. Они строят общий модуль ещё до того, как первый сервис успевает устояться, и каждая последующая правка превращается в хирургию по модулю.
Ранние сервисы часто сильно меняются. Меняются порты. Разделяются базы данных. Появляются очереди. Меняются правила именования. Если эти предположения живут внутри общего модуля, одно обновление сервиса может разойтись по всем окружениям.
Ещё одна распространённая ошибка — огромный модуль, который делает слишком много. Он создаёт сеть, секреты, compute, logging, IAM и половину правил именования в одном месте. На неделю это выглядит аккуратно. Потом одному сервису нужен диск побольше, другому нельзя иметь публичный доступ, а третьему нужен другой путь для секрета. Небольшая правка превращается в длинное ревью.
Стоимость тоже легко спрятать. Модуль может незаметно включить более крупные инстансы, дополнительные load balancer, более долгий срок хранения логов или NAT gateway в каждом окружении. Terraform выглядит чисто, но счёт через три месяца рассказывает совсем другую историю.
Команды также теряют время, когда пытаются загнать каждый сервис в один шаблон. API, worker, admin-приложение, scheduled job и webhook receiver не обязаны иметь одну и ту же форму. Если шаблон говорит обратное, исключения начинают плодиться. И тогда модуль читать сложнее, чем пять простых стеков.
Худшее время исправлять это — неделя запуска. Рефакторить Terraform, когда на носу трафик, демо или звонки с инвесторами, — плохая ставка. Можно получить drift в state, сломать rollout или потратить полдня на преследование изменения имени, которого вообще не должно было быть.
Более безопасная привычка проста: сделайте так, чтобы один сервис работал хорошо, скопируйте стек для следующих нескольких сервисов, вынесите только то, что действительно одинаковое, и каждый раз, когда переиспользуете код, пересматривайте defaults по стоимости.
Если общая абстракция экономит 30 строк, но добавляет два дополнительных круга ревью, она не помогает.
Быстрые проверки перед рефакторингом
Рефакторинг на один день кажется дешёвым, а на полгода — дорогим. Прежде чем переводить несколько сервисов на общие модули, проверьте, станет ли ежедневная работа проще или просто более абстрактной.
Начните с проверки на людей. Если новый сотрудник не может объяснить, как работает стек, за десять минут с открытым репозиторием, схема уже слишком запутана. Небольшому стартапу должно быть легко читать код. Один сервис, один стек, одно понятное место для изменений.
Ложное сходство причиняет много боли. Два сервиса могут выглядеть похожими и всё равно требовать разных лимитов CPU, правил алертов, секретов, масштабирования или сетевых правил. Если совпадают только несколько тегов и шаблон именования, проще скопировать небольшой блок, чем строить общий модуль, в который должны влезть все сервисы.
Задайте и более жёсткий вопрос: уменьшит ли это работу в следующем месяце, а не только сегодня? Рефакторинг оправдывает себя тогда, когда команде придётся повторять одно и то же изменение достаточно часто, чтобы это дало реальную экономию времени. Если вы ожидаете один проход по очистке и почти не ждёте повторного использования, общие абстракции обычно добавляют больше сопровождения, чем убирают.
Rollback — ещё одна хорошая проверка на прочность. Если один сервис ломается, можно ли откатить только его, не трогая остальные? Если общий модуль требует согласованного релиза, вы создали сцепление. Это нормально для нескольких базовых вещей, например общей сети, но рискованно для app-сервисов, которые меняются с разной скоростью.
Сделайте и проверку по стоимости. Общие ресурсы могут скрывать расходы. Если несколько сервисов сидят на одной базе, очереди или observability-стеке, нужно понимать, что именно создаёт нагрузку. Иначе дешёвый на вид рефакторинг может сделать перерасход гораздо менее заметным.
Для маленькой команды подходит такой фильтр:
- Новый инженер может быстро прочитать репозиторий и объяснить его.
- Каждый общий блок отражает реальное сходство, а не желаемое сходство.
- Изменение экономит повторную работу в ближайшее время.
- Один сервис можно откатить отдельно.
- Стоимость общих частей можно назвать без догадок.
Если не выполняются хотя бы два пункта, лучше ещё немного оставить стеки простыми.
Что делать дальше
Сделайте следующий шаг маленьким. Если команда всё ещё может читать каждый Terraform-файл, спокойно планировать изменения и исправлять ошибки в одном месте, оставьте эту структуру. Стартап с пятью сервисами не нуждается в общих абстракциях только потому, что ими пользуются более крупные команды.
Начните со стека, который команда может объяснить простыми словами. Если один инженер может за 20 минут показать новому коллеге, как связаны сеть, compute, секреты и алерты, значит схема, скорее всего, пока достаточно хороша. Простое решение обычно выигрывает у хитрого, когда релизы выходят каждую неделю.
Переносите код в модуль только после того, как он остаётся одинаковым несколько релизов подряд. Хорошая проверка — скучное повторение. Если вы скопировали один и тот же блок три-четыре раза, и каждый раз он менялся одинаково, значит пора выносить его. Если каждому сервису всё равно нужны свои исключения, оставьте блок в стеке.
Полезно ещё и заранее написать, зачем вообще нужен модуль: какую проблему он решает, какие входы должны оставаться стабильными, кто отвечает за изменения и когда команда должна перестать его использовать. Такая заметка экономит время позже и помогает вовремя отказаться от модулей, которые больше не подходят.
Перед более крупным рефакторингом может помочь внешний взгляд. Oleg Sotnikov на oleg.is делает такую работу для стартапов в роли Fractional CTO и advisor, и короткий разбор обычно быстро показывает, нужен ли вашему Terraform модуль, разделение state или просто меньше лишних частей.
Если на этой неделе вы не сделаете больше ничего, выберите один стек, уберите один запутанный слой и напишите одно короткое правило, когда модуль разрешён. Этого уже достаточно, чтобы следующее решение далось легче.
Часто задаваемые вопросы
С чего стартапу из пяти сервисов лучше начать: с Terraform-модулей или с простых стеков?
Начните с простых стеков. Для стартапа с пятью сервисами отдельные папки и отдельный state обычно помогают быстрее вносить изменения, проще делать ревью и легче искать ошибки.
К модулю можно вернуться позже, когда вы увидите, что один и тот же блок повторяется в нескольких сервисах почти без исключений.
Когда copy-paste лучше, чем общий модуль?
Copy-paste выигрывает, когда сервисы уже отличаются по масштабу, доступам, секретам или процессу выката. В таком случае несколько лишних строк остаются понятными, а общий модуль часто обрастает флагами и скрытыми правилами.
Если форма сервисов меняется каждую неделю, лучше пока держать код ближе к каждому сервису.
Что делает первый Terraform-модуль удачным?
Хорошо начинать с чего-то небольшого и скучного. Например, теги, один шаблон алерта или простой набор IAM-правил часто подходят отлично, потому что такие вещи меняются реже, чем настройки самого приложения.
Не оборачивайте целый сервис в первый же модуль. Именно там быстрее всего начинают копиться крайние случаи.
Сколько похожих сервисов нужно, чтобы модуль действительно имел смысл?
Ориентир — три или больше сервисов с одинаковой формой ресурсов и почти без исключений. Если каждому сервису нужен свой subnet-правило, своя правка policy или своя настройка масштабирования, настоящего сходства ещё нет.
Проверка простая: если для модуля уже нужен длинный README, лучше подождать.
Почему общие модули усложняют отладку?
Потому что форма сервиса перестаёт быть видна в одном месте. Сначала смотрите стек, потом модуль, потом входные параметры, потом defaults, и только после этого становится понятно, что именно построит Terraform.
С простыми стеками проблему обычно видно сразу в папке сервиса.
Стоит ли Postgres и Redis держать в отдельных стеках?
Да, чаще всего Postgres и Redis лучше держать в отдельных стеках. Изменения в базе и кэше требуют другого подхода к ревью, несут другой риск и часто выкатываются по иному графику, чем код приложения.
Отдельные стеки это подчёркивают и уменьшают шанс, что одно изменение в приложении потянет за собой изменения в данных.
Как preview-окружения влияют на это решение?
Preview-окружения часто требуют более скромных defaults и более дешёвых настроек. Если один общий модуль должен поддерживать production, staging и preview для всех сервисов, в нём быстро накапливаются переключатели.
Простые стеки позволяют держать выбор для preview локально, и из-за этого стоимость и поведение проще контролировать.
По каким признакам видно, что модуль стал слишком большим?
Тревожные признаки появляются быстро. Вы всё время добавляете boolean-переключатели, расплывчатые названия входных параметров и исключения для отдельных сервисов только ради того, чтобы ещё один потребитель влез в шаблон.
Если ревью начинают превращаться в археологию по модулю, значит он уже вырос больше, чем нужно.
Как безопасно протестировать новый модуль, не рискуя всем репозиторием?
Сначала попробуйте на одном обычном сервисе. Запустите plan, примените изменения, а потом через несколько дней сделайте одну рутинную правку и посмотрите, остался ли код понятным.
Если уже на первом тесте нужны обходные пути, остановитесь и оставьте стек простым.
Когда стоит привлечь внешнего эксперта для ревью Terraform?
Просите внешнюю помощь до большого рефакторинга, до пикового давления перед запуском или когда команда спорит о структуре вместо того, чтобы выпускать изменения. Короткий разбор обычно показывает, нужен ли вам модуль, разделение state или просто меньше лишних частей.
Если вам нужен такой разбор, Oleg Sotnikov делает эту работу как Fractional CTO и advisor для стартапов.


