Модули C++ в сервисном стеке без переписывания старого кода
Используйте модули C++ в сервисном стеке, оборачивая унаследованные библиотеки за понятными интерфейсами, чтобы снизить риски и оставить проверенный код на месте.
Содержание
Что идет не так, когда старый C++ встречается с новыми сервисами
Старый C++ код может годами работать без проблем, а потом внезапно начать создавать хаос в тот момент, когда несколько новых сервисов вызывают его по-разному. Сама библиотека при этом может быть вполне надежной. Проблемы начинаются на границах.
Во многих унаследованных системах есть допущения, которые никто не записал. Код может ждать только одного вызова за раз. Может хранить состояние в глобальных объектах. Может возвращать сырые указатели, использовать собственные аллокаторы или зависеть от флагов сборки, которые помнит только одна команда. Когда кодом владеет одно старое приложение, это не выглядит страшно. Когда его трогают пять сервисов, два языка и новый конвейер развертывания, ситуация меняется.
Ошибки с памятью часто становятся первым сюрпризом. Библиотека может казаться стабильной, потому что исходное приложение всегда освобождало объекты в нужном порядке. Новый сервис может этого не делать. Тогда появляются медленные утечки, редкие падения или поврежденные данные, которые всплывают только через несколько часов. Проблемы с потоками прячутся так же. Код, который спокойно жил в одном процессе, может начать ломаться, как только современные сервисы вызывают его параллельно.
Тихий ущерб наносят и особенности сборки и выполнения. Одна команда компилирует с одной стандартной библиотекой, другая использует другие флаги, а третья упаковывает зависимость в контейнер, где не хватает системных компонентов. В итоге одна и та же функция ведет себя немного по-разному в зависимости от того, кто ее выложил. На такие ошибки уходят дни, потому что они не падают в одном очевидном месте.
Более серьезная проблема — владение. Когда к старому коду напрямую обращаются многие команды, граница оказывается ничьей. Каждая команда добавляет свои проверки, патчи и обходные пути. Маленькие изменения начинают казаться опасными не потому, что код всегда плох, а потому, что правила вокруг него разбросаны. Одна команда меняет формат входных данных, другая рассчитывает на старые коды ошибок, а третья повторяет запросы, которые вообще не следовало повторять.
Именно поэтому модули C++ в сервисном стеке часто ломаются еще до того, как ломается сам код. У системы нет узкой и управляемой точки входа.
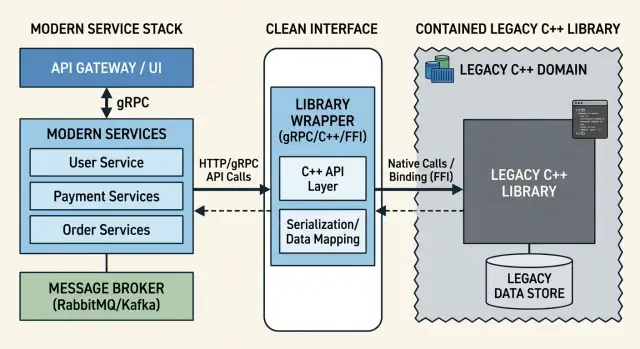
Обертка решает это практичным способом. Она дает одно место, где можно проверять входные данные, ограничивать параллельность, преобразовывать ошибки и скрывать работу с памятью за более простым интерфейсом. Если старая библиотека возвращает десять вариантов сбоя, обертка может свести их к трем исходам, с которыми команда сервиса действительно умеет работать. Если с библиотекой общается только один компонент, изменения перестают расходиться по всему стеку.
Представьте библиотеку для разбора документов, которая работает с 2014 года. Она может по-прежнему хорошо разбирать документы. Но если к ней напрямую обращается каждый сервис, каждый из них наследует и ее острые углы. Обертка позволяет оставить парсер проверенным кодом, а остальному стеку дать более чистые контракты и меньше сюрпризов.
Когда обертка лучше переписывания
Полная перепись на бумаге выглядит аккуратно. В реальных командах она часто съедает время и снова открывает ошибки, которые рабочий код уже решил много лет назад. Если старая C++-библиотека уже умеет обрабатывать странные входные данные, неприятные граничные случаи и неудобные проблемы с таймингом, это результат, за который пришлось дорого заплатить. Выбрасывать его только потому, что остальной стек изменился, обычно плохой обмен.
Вот где модули C++ в сервисном стеке действительно уместны. Старая библиотека продолжает делать тяжелую работу, а обертка дает новым сервисам маленький и предсказуемый интерфейс. Эта обертка может проверять входные данные, превращать странные коды возврата в понятные ошибки и скрывать небезопасные детали вроде сырых указателей, глобальных переменных или правил инициализации, завязанных на состояние.
Перепись еще и требует от команды доказать, что новая версия ведет себя так же, как код, который они могут понимать не до конца. Звучит посильно, пока кто-нибудь не находит правило, спрятанное в ветке десятилетней давности, которое срабатывает только для одного клиента, одного региона или одного редкого формата данных. Тогда перепись замедляется, сроки сдвигаются, а у команды все равно остается две системы для сравнения.
Если бизнесу нужен результат уже в этом квартале, обертка часто становится честным выбором. Новым сервисам обычно не нужна вся библиотека целиком. Им нужен только небольшой ее кусок: возможно, расчет цен, разбор данных, обработка изображений или связь с устройством. Меньшая поверхность дает почти всю выгоду по безопасности, не заставляя ставить успех проекта на идеальную перепись.
Обертка выигрывает, когда выполняются несколько условий:
- Библиотека уже работает в продакшене и ломается понятным образом.
- Сложная логика живет в коде, который никто не хочет заново изучать под давлением сроков.
- Новым сервисам нужны лишь несколько операций, а не весь API.
- Команда может протестировать обертку быстрее, чем доказать корректность переписи.
Это часто встречается в небольших командах. Фракционный CTO или staff engineer может унаследовать проверенный C++-движок, в то время как остальная компания переходит на сервисы на Go, Python или Node.js. Переписывать движок можно месяцами. Обернуть его строгим интерфейсом — вопрос дней или недель, а план отката при этом намного проще.
Хорошая обертка меняет сам разговор. Команда перестает спрашивать: «Как нам заменить все?» — и начинает спрашивать: «Какой самый маленький контракт действительно нужен новым сервисам?» Это важный сдвиг. Он оставляет проверенный код там, где ему место, и выносит работу по безопасности на границу, где новые баги проще увидеть, протестировать и исправить.
Сначала выберите границу
Начинайте с одной бизнес-задачи, а не с груды классов. Если старая библиотека считает цены, конвертирует файлы или проверяет права доступа, пусть обертка отвечает только за эту задачу и ни за что больше.
Это важно, потому что команды часто рисуют границу вокруг того кода, который у них уже есть. Обычно из этого получается тонкая оболочка, которая протаскивает старые архитектурные проблемы в новые сервисы. Более удачная граница следует за бизнес-результатом.
Для модулей C++ в сервисном стеке хорошая первая граница звучит просто: «создать котировку», «проверить документ» или «сформировать отчет». Если фраза звучит так, как ее понял бы product manager, вы близко.
Сначала напишите контракт, потом уже пишите обертку. Сделайте его коротким, но точным.
- Что отправляет вызывающая сторона?
- Что она должна получить в ответ?
- Какие сбои случаются каждый день?
- Какие ошибки означают, что у старой библиотеки плохое состояние?
- Как должны работать тайм-ауты или повторы?
Этот шаг экономит время позже. Когда запрос и ответ описаны ясно, обертка перестает быть черным ящиком и начинает вести себя как обычный сервис.
Случаи ошибок заслуживают такого же внимания, как и успешные сценарии. Не возвращайте расплывчатые ошибки вроде «failed» и не пропускайте наружу непонятные внутренние коды, которые понимает только старая команда. Сведите их к небольшому набору именованных исходов, например: неверный ввод, не найдено, занято, тайм-аут или внутренняя ошибка.
Сложные части C++ держите внутри обертки. Другие сервисы не должны думать о сырых указателях, собственных аллокаторах, шаблонах, привязке к потоку или о том, какой именно поток обязан вызвать очистку. Эти правила принадлежат адаптерному слою, где ими управляет одна команда.
Это также означает, что обертка должна владеть правилами памяти и времени жизни объектов. Вызывающая сторона просит выполнить работу и получает результат. Ей не нужно гадать, кто освобождает буфер, как долго живет объект и можно ли запускать два вызова одновременно.
На границе используйте простые типы данных. Простые поля с понятными названиями: строки, числа, булевы значения, списки и небольшие перечисления. Если другой сервис читает контракт и ему нужен специалист по C++, чтобы его понять, значит граница все еще слишком близка к старому коду.
Есть быстрый тест. Дайте интерфейс коллеге, который никогда не трогал унаследованную библиотеку. Если он может за минуту объяснить запрос, ответ и ошибки, граница, скорее всего, выбрана правильно. Если он начинает спрашивать про указатели или шаблонные типы, отодвиньте линию обратно внутрь обертки.
Стройте обертку шаг за шагом
Начните с узкого обещания. Новым сервисам от старой библиотеки обычно нужно куда меньше, чем исходному коду. Если в библиотеке 40 публичных функций, вашему сервису могут понадобиться только три. Сначала запишите именно их, простыми словами, и только потом переходите к коду.
Этот короткий список становится контрактом для адаптера. Он же защищает от частой ошибки: снова открыть весь старый API, только под новым именем. Если так сделать, вы сохраните всю старую путаницу и просто добавите поверх нее новый код.
Практичная последовательность выглядит так:
- Выберите несколько действий, которые действительно нужны сервису, например «оценить заказ» или «проверить файл».
- Определите простые типы запроса и ответа, которые соответствуют данным сервиса, а не внутренним структурам библиотеки.
- Напишите адаптер, который преобразует эти типы в вызовы старой библиотеки.
- Сведите все ошибки к короткому и последовательному коду и сообщению.
- Покройте адаптер тестами до того, как его начнет использовать какой-либо боевой маршрут.
Адаптер должен хорошо делать скучную работу. Он преобразует поля JSON, перечисления, временные метки и идентификаторы в форматы, которые ждёт библиотека. Потом он возвращает результат обратно в ответ сервиса. Бизнес-решения по возможности держите вне этого слоя. Если обертка начинает копировать половину старых правил, вы случайно строите вторую систему.
С обработкой ошибок нужна особая аккуратность. Унаследованные библиотеки часто возвращают смесь из null, чисел, типов исключений, логов и специальных строк. Сервис долго с этим работать не сможет. Выберите один формат ошибок и придерживайтесь его. Например, возвращайте коды вроде invalid_input, timeout, not_found и internal_error, а также короткое сообщение, которое поможет поддержке и логам.
Тесты должны проверять границу, а не каждую деталь внутри старой библиотеки. Пишите случаи для корректных данных, неверных данных, крайних значений и неприятных сбоев. Если библиотека падает на некорректных данных, тест адаптера должен доказать, что сервис все равно вернет управляемую ошибку. Именно здесь команда получает безопасность.
В модулях C++ в сервисном стеке эта граница важнее, чем сама синтаксическая конструкция модулей. Аккуратная структура модулей помогает, но реальная выгода приходит от одного стабильного интерфейса, которому остальной стек может доверять.
Запуск должен быть маленьким. Переведите на обертку один маршрут, одного воркера или одну периодическую задачу. Смотрите на логи, задержки и количество ошибок. Подправьте шероховатости, потом переносите следующий кусок. Oleg Sotnikov часто продвигает именно такое пошаговое изменение в startup-системах, потому что оно снижает риск и при этом не тормозит движение. Вы оставляете проверенный код там, где он еще работает, и ставите перед ним более безопасную дверь.
Простой пример
У компании есть движок ценообразования, написанный на C++. Он пришел из старого продукта, и команда не трогает правила цен, потому что они до сих пор дают правильные котировки. Проблема не в математике. Проблема в доступе. Новому веб-приложению и мобильному приложению тоже нужны цены, а прямые вызовы библиотеки растащат проблемы сборки C++, риски с памятью и особенности платформы по всему продукту.
Поэтому команда ставит перед движком небольшой сервис котировок. У сервиса одна задача. Он принимает несколько простых входных данных, вызывает старую библиотеку и возвращает чистый результат. Другие команды общаются с сервисом, а не с библиотекой.
Как выглядит контракт
Запрос может оставаться простым:
{
"sku": "PRO-12",
"region": "EU",
"customerType": "business",
"quantity": 25
}
И ответ может быть таким же понятным:
{
"currency": "EUR",
"unitPrice": 19.80,
"totalPrice": 495.00,
"ruleVersion": "2024-10"
}
Такой контракт скрывает старые внутренности. Веб-приложению не важно, каким компилятором собран движок. Мобильному приложению не нужны C++-заголовки или особая обработка среды выполнения. Они отправляют запрос, получают котировку и идут дальше.
Внутри сервиса обертка остается тонкой. Она преобразует входящий запрос в формат, который ожидает движок ценообразования, вызывает старый код, проверяет ошибки и превращает результат в ответ, которому может доверять остальной стек. Правила остаются в одном месте. Рискованные части остаются изолированными.
Такая схема позволяет команде менять внешний стек, не трогая логику цен. Можно перевести фронтенд на новую платформу, добавить поддержку мобильного приложения, запустить сервис в контейнерах или добавить логирование и ограничение частоты запросов. Все это не требует переписывать движок.
В этом и есть практическая сторона модулей C++ в сервисном стеке. Команда оставляет проверенный код там, где ему место, и проводит вокруг него четкую границу. Часто это полезнее, чем полная перепись, особенно когда в старой библиотеке уже накоплены годы исправлений для ценообразования.
Одна деталь очень важна: контракт сервиса должен использовать бизнес-термины, а не C++-термины. «quantity» и «region» понятны. Внутренние структуры, указатели и типы шаблонов не должны выходить наружу. Если это происходит, обертка перестает быть оберткой и начинает тащить старые проблемы в новый код.
Именно поэтому команды часто выбирают оборачивать унаследованные C++-библиотеки, а не заменять их сразу. Движок ценообразования продолжает делать свою работу. Сервис дает остальному продукту более безопасный и простой способ использовать его.
Ошибки, которые создают новый риск
Большинство команд страдает не из-за самой старой библиотеки. Им мешает грязная граница вокруг нее.
Обычно это начинается тогда, когда разработчики начинают экспортировать унаследованные заголовки, макросы и типы во все новые сервисы. В этот момент обертка становится лишь тонким костюмом. Старый код по-прежнему управляет правилами памяти, обработкой ошибок и особенностями сборки по всему стеку.
Если вы хотите более безопасные модули C++ в сервисном стеке, держите интерфейс маленьким и скучным. Новые сервисы должны видеть простые типы запроса и ответа, а не двадцать лет внутренних заголовков.
Вторая ошибка заметна не сразу. Обертка растет и в итоге становится второй копией старой системы.
Так происходит, когда адаптер начинает владеть разбором конфигов, кэшем, правилами логирования, управлением состоянием и половиной бизнес-логики. Тогда никто не понимает, где живет баг. Одна команда отлаживает библиотеку, другая — обертку, и обе отчасти правы.
Держите обертку узкой. Она должна преобразовывать типы, управлять вызовами, обрабатывать ошибки и предоставлять стабильный интерфейс. Если она начинает вести себя как отдельный продукт, урезайте ее.
Разделение бизнес-правил между обеими сторонами создает еще больше проблем. Правило ценообразования, проверка допуска или округление должны жить в одном месте в каждый момент времени. Если унаследованная библиотека применяет одну версию, а обертка добавляет «временную» правку, результаты тихо расходятся.
Такая расхожесть особенно неприятна, потому что тесты в небольших случаях могут все еще проходить. Первыми это обнаружат клиенты.
Операционные ошибки быстро выходят наружу
Команды часто считают, что обертка — это только код, и пропускают поведение сервиса. Вызов библиотеки внутри одного процесса кажется быстрым и предсказуемым. Вызов через сервис — это уже другое дело.
Нужно заранее решить:
- пределы тайм-аута
- правила повторов
- поведение при отказе
- коды ошибок, на которые клиенты могут реагировать
Если эти решения не принять, медленный вызов старой библиотеки может занять рабочие потоки, вызвать дублирующиеся запросы или вернуть частичные данные, которые выглядят валидными.
Еще одна ошибка вызывает хаос на релизе: менять инструменты сборки, публичные API и бизнес-логику в одном и том же развертывании. Если все идет не так, никто не может понять, виноват ли компилятор, транспортный слой или изменение правила.
Более безопасный подход нарочно скучный. Сначала оберните унаследованные C++-библиотеки, не меняя поведение. Потом зафиксируйте тесты на текущих результатах. После этого обновляйте настройки сборки или границы модулей. Логику продукта меняйте позже, отдельным релизом.
Небольшой пример делает это очевидным. Если сервис оформления заказа начинает использовать старый калькулятор доставки, не меняйте в тот же день систему сборки, форму API и правила доплаты. Первый релиз должен быть скучным. Скучные релизы проще доверять.
Короткая проверка перед релизом
Обертка готова к продакшену, когда команда может понятно ее объяснить, протестировать под нагрузкой и безопасно откатить, если она ведет себя плохо. Если хоть одна из этих частей неясна, релиз слишком ранний.
Начните с самого короткого теста. Попросите одного инженера объяснить интерфейс меньше чем за минуту. Он должен суметь сказать, что приходит на вход, что выходит на выходе, что означают ошибки и что вызывающая сторона никогда не должна делать. Если для этого нужна доска и десять оговорок, граница все еще слишком грязная.
Логи важны не меньше кода. Когда запрос падает в 2 часа ночи, никто не хочет полчаса читать сырые C++-трейсы. В логах сервиса должны быть идентификатор запроса, название операции, результат, затраченное время и понятная причина сбоя. Не записывайте в логи приватные данные, но оставьте достаточно деталей, чтобы команда могла отличить плохой ввод, тайм-аут и баг библиотеки.
Нагрузочные тесты должны проверять неприятные случаи, а не только счастливый путь. Прогоните обычный трафик, а потом намеренно замедлите библиотеку. Добавьте короткие всплески. Подержите часть вызовов открытыми дольше обычного. Старый код часто нормально работает при средней нагрузке, а затем разваливается, когда один медленный вызов блокирует пул, забивает очередь или загоняет повторы в цикл.
Откат требует такого же внимания. Если новая обертка пишет данные в новом формате, убедитесь, что старый путь все еще умеет их читать, или сохраните старый формат, пока релиз не устоится. Если обертка меняет побочные эффекты, например биллинг, отправку сообщений или переходы состояния, докажите, что командa сможет отключить ее без дублей и потерь.
Небольшой чек-лист поможет:
- Один человек может объяснить интерфейс, входы, выходы и правила ошибок простыми словами.
- Логи показывают запрос, результат, время и причину сбоя с постоянными идентификаторами.
- Нагрузочные тесты включают медленные вызовы, повторы, давление на очередь и всплески трафика.
- Откат работает без потери данных и без повторения побочных эффектов.
- Одна команда отвечает за исправления, обновления версий и изменения библиотеки после запуска.
Последний пункт экономит много боли. Совместное владение звучит вежливо, но обычно означает, что никто не чинит обертку достаточно быстро. Назначьте одну команду. Дайте ей pager, план версий и последнее слово по изменениям интерфейса.
Именно такую дисциплину релиза Oleg Sotnikov продвигает в AI-first и смешанных стэках: интерфейс должен быть маленьким, сбои — очевидными, а восстановление — скучным. Скучные релизы и есть цель.
Что делать дальше
Начинайте с малого. Для большинства команд самый быстрый выигрыш от модулей C++ в сервисном стеке приходит от одной проблемной библиотеки, а не от большого плана очистки всего кода. Выберите библиотеку, которая тормозит релизы, ломает сборку или делает запуск каждого нового сервиса сложнее.
Пока не добавляйте новые функции. Сначала нарисуйте узкий интерфейс вокруг этой библиотеки и зафиксируйте его для первого релиза. Если команда будет менять обертку каждую неделю, никто не поймет, где должна проходить настоящая граница.
Короткий чек-лист делает это практичным:
- Выберите одну библиотеку с понятной бизнес-ценностью и частыми неудобствами.
- Определите самый маленький интерфейс, который действительно нужен сервису.
- Оставьте старый код внутри обертки, даже если сначала это кажется неудобным.
- Запишите, чем владеет обертка, а что остается на стороне унаследованного кода.
- Сначала запустите один реальный сценарий, и только потом оборачивайте что-то еще.
Эта письменная граница важнее, чем многие ожидают. Простая заметка в репозитории может позже сэкономить часы споров. Пишите прямо: какие типы данных могут проходить через границу, какие ошибки возвращает обертка, какие правила памяти скрыты, и какие части старой библиотеки больше нельзя вызывать напрямую.
Если граница кажется грязной, это сигнал, а не провал. Иногда библиотека слишком много держит в состоянии. Иногда сервис просит слишком много особых случаев. В такой ситуации не спешите переделывать все. Урежьте первую версию, пока ее не сможет поддерживать одна команда без догадок.
Небольшой пример помогает. Если унаследованная библиотека ценообразования трогает файлы, глобальный конфиг и собственные строковые типы, не открывайте все это новому сервису. Оберните ее в маленькую форму запроса и ответа, оставьте работу с файлами внутри и возвращайте простые ошибки, которые сервис может логировать и повторять. Этого часто достаточно, чтобы сделать код безопаснее, не меняя саму логику ценообразования.
Если ваша команда снова и снова кружит вокруг этой границы, внешний взгляд может сэкономить время. Oleg Sotnikov работает как Fractional CTO и помогает компаниям модернизировать софт без месяцев, потраченных впустую на перепись. Он может проверить интерфейс, подсветить риски запуска и помочь вашей команде решить, что должно остаться внутри обертки, а что потом можно вынести наружу.
Когда первая обертка докажет себя в продакшене, повторите тот же подход. Не везде. Только там, где боль действительно есть.


