Модели Pydantic для дрейфа API между Python-сервисами
Модели Pydantic помогают Python-командам рано отбрасывать плохие данные, но если моделировать каждое поле слишком подробно, релизы и ревью замедляются.
Содержание
Как выглядит дрейф API в реальных командах
Дрейф API редко начинается с явной поломки. Обычно всё начинается с одного небольшого изменения, которое на обычном релизе выглядит безобидно. Один сервис отправляет user_id, а другой всё ещё ждёт customer_id, и никто не замечает проблему, потому что названия кажутся достаточно похожими, если смотреть на код бегло.
Такие расхождения часто появляются, когда два Python-сервиса меняются по разному графику. Сервис платежей может переименовать поле, чтобы оно совпадало с новым столбцом в базе, а сервис заказов оставляет старое имя, потому что его релиз только на следующей неделе. Данные по-прежнему проходят через очередь или API-вызов, но одна сторона теперь читает пустое значение или подставляет значение по умолчанию, которое вообще не должно использоваться.
Типы расходятся так же легко. Поле, которое раньше было целым числом, становится строкой, потому что фронтенд-команде нужно сохранить ведущие нули, или потому что партнёрский API присылает всё как текст. Сразу ничего не ломается. Python часто принимает значение, логи выглядят нормально, и релиз уходит. Ошибка всплывает позже, когда другой сервис начинает сортировать, сравнивать или складывать это поле и получает бессмысленный результат.
Необязательные поля наносят более медленный ущерб. Команда добавляет coupon_code как необязательное поле, а через месяц строит логику, которая предполагает, что оно всегда есть в определённом сценарии оплаты. После этого другая команда помечает его как обязательное в своём сериализаторе, потому что во всех недавних тестовых payload'ах оно было. И вот у вас уже три сервиса, у каждого своё представление об одном и том же поле.
Самая неприятная часть — расстояние. Настоящая проблема начинается в одном payload, а заметная ошибка проявляется совсем в другом месте. Сервис регистрации принимает наполовину неверный запрос, сервис профиля сохраняет его, а задача аналитики через шесть часов падает с запутанной ошибкой типа. К тому времени человек, который читает алерт, уже далеко от исходного релиза.
Команды особенно остро чувствуют это, когда работают быстро. Стартап может выпустить пять небольших изменений API за неделю. Каждое по отдельности выглядит разумно. Вместе они превращают контракт между сервисами в угадывание, а угадывание — это и есть точка, где начинается дорогая отладка.
Почему Pydantic рано останавливает плохие данные
Большинство ошибок API возникает ещё до вашей бизнес-логики. Один сервис отправляет "42" вместо 42, добавляет лишнее поле или забывает вложенное значение, а следующий сервис пытается угадать, что имел в виду отправитель.
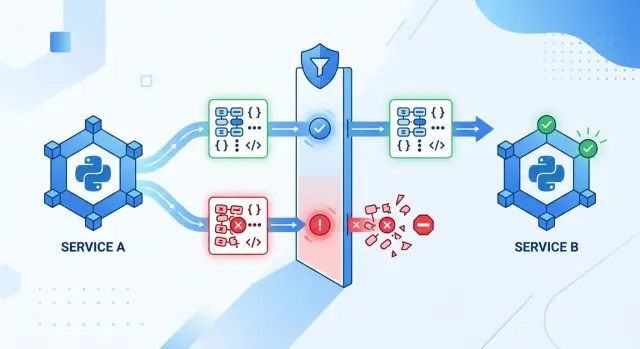
Pydantic решает это на границе сервиса, там, где запросы только приходят. Модель разбирает payload, проверяет каждое поле и либо приводит его к известному виду, либо сразу отклоняет. Поэтому модели Pydantic для дрейфа API так хорошо работают между Python-сервисами. Они останавливают плохие данные до того, как они распространятся дальше.
Это меняет точку отказа в полезную сторону. Вместо странной ошибки глубоко в обработке заказов, биллинга или уведомлений запрос падает на границе. Команда видит понятную ошибку валидации, привязанную к конкретному payload, который её вызвал. Это экономит время, потому что разработчикам не нужно искать плохое значение через пять функций и две очереди.
Строгая проверка особенно помогает в нескольких типичных случаях:
- неверные типы, например строка там, где контракт ожидает целое число
- отсутствующие обязательные поля, особенно во вложенных объектах
- неизвестные поля на публичных эндпоинтах, которые должны отклонять неожиданные данные
Неизвестные поля важнее, чем кажется. Если публичный endpoint молча принимает лишние данные, клиенты начинают опираться на поведение, которое вы никогда не планировали поддерживать. Позже удаление или переименование такого поля становится ломающим изменением. Если на публичных моделях запретить лишние поля, контракт останется компактным и понятным.
Строгий режим Pydantic также уменьшает скрытое приведение типов. Слабый парсер может принять значение, которое выглядит достаточно похожим, и идти дальше. Неделю это кажется удобным, а потом месяцами доставляет проблемы. Если цена приходит как "free", а булево значение — как "yes", лучше, чтобы запрос падал сразу, а не после того, как сервис уже принял решения на основе неверных данных.
Небольшой пример хорошо показывает разницу. Сервис A отправляет событие о пользователе, где user_id — строка, и добавляет лишнее поле debug. Сервис B ожидает целое число и не поддерживает лишние данные. Со строгими моделями сервис B сразу отклонит запрос и вернёт понятную ошибку. Без этой проверки событие может попасть в систему, сломаться позже, а команда начнёт спорить о том, где именно появилась ошибка.
Хорошая валидация держит ошибки рядом с запросом. Это самое дешёвое место, чтобы их найти, объяснить и исправить.
Начните с того контракта, который действительно важен
Большинство команд слишком рано моделируют слишком много. На вид это аккуратно, но на деле часто создаёт больше работы, чем защиты. Более безопасный путь проще: определите запрос и ответ на границе сервиса, а внутренности каждого сервиса оставьте в покое, если только другой сервис по-настоящему от них не зависит.
Контракт Python-сервиса должен покрывать данные, которые проходят по сети. Если Service A отправляет в Service B customer_id, plan и currency, сначала опишите именно эти поля. Если Service B возвращает status и next_billing_date, опишите и их. Это даст вам чистую контрольную точку, где плохие данные будут падать сразу.
Ловушка в том, чтобы тащить внутренние объекты в API-модель. Столбцы базы, вспомогательные флаги, счётчики повторных попыток, подписи для интерфейса и недоделанная бизнес-логика не должны попадать в общий контракт только потому, что они где-то существуют в коде. Как только они входят в модель, другие команды начинают на них опираться, а простые изменения превращаются в координационную работу.
Небольшой пример помогает понять идею. Допустим, сервису биллинга нужны только четыре поля, чтобы создать подписку:
customer_idplan_codetrial_dayscoupon_codeтолько если купон действительно есть
Этого достаточно. Не нужно показывать полный профиль клиента, внутренние заметки отдела продаж, внутренние правила ценообразования или все поля аудита из базы данных.
К необязательным полям нужен такой же подход. Помечайте поле как необязательное только тогда, когда принимающий сервис действительно может обойтись без него, не гадая. Команды часто ставят поле как необязательное, потому что ещё не уверены, или потому что одно старое приложение его не отправляет. Такое решение быстро разносит неопределённость. Поле должно быть необязательным по реальной бизнес-причине, а не чтобы избежать короткого разговора.
Именно здесь строгий режим Pydantic помогает больше всего. Он лучше всего работает на узкой границе, на которую другие сервисы опираются каждый день. На практике это означает меньше неожиданных null, меньше тихих преобразований типов и меньше дрейфа схемы API. Плюс модель остаётся читаемой, а это важнее, чем многие признают. Если другой разработчик не может понять контракт за минуту, он уже слишком большой.
Добавляйте строгую проверку постепенно
Модели Pydantic для дрейфа API лучше всего работают, когда вы ужесточаете контракт маленькими шагами. Если попытаться сразу закрутить все гайки, команды потратят больше времени на исправление шума в модели, чем на реальные поломки.
Начните с одной модели для входящего JSON, на который ваш сервис действительно опирается. Сделайте её маленькой. Если вашему биллинговому сервису нужны только customer_id, plan и price_cents, опишите сначала их и оставьте остальное в покое.
Раскатывайте по слоям
Помогает простой порядок.
- Определите одну входную модель на границе сервиса, где сырой JSON попадает в приложение.
- Включите строгие типы для полей, которые часто вызывают ошибки в деньгах, доступе или состоянии.
- Запрещайте неожиданные поля только на тех маршрутах, где тихие изменения действительно вредят.
- Логируйте ошибки валидации с request id, названием маршрута, именем поля и безопасным примером плохого значения.
- Добавьте тесты и на текущий формат payload, и на старый формат, который вы ещё принимаете во время перехода.
Строгие типы особенно важны там, где Python иначе бы привёл плохие данные. Строка вроде "10", превращающаяся в число, может выглядеть безобидно, пока один сервис не пришлёт "10.0" или "ten". Для рискованных полей — например, цен, идентификаторов, флагов и временных меток — строгая проверка отсекает плохие данные до того, как они распространятся дальше.
С extra="forbid" лучше быть избирательным. Он полезен на эндпоинтах, где лишнее поле может означать, что другой сервис поменял свой контракт и никому не сообщил. Он менее полезен для payload'ов, в которых есть метаданные, не важные для вас пока что.
Логам нужен контекст, чтобы следующий человек мог быстро исправить проблему. Сообщения вроде «валидация не прошла» недостаточно. Хороший лог показывает, какой сервис отправил payload, какой маршрут его отклонил и какое поле сломалось.
Тесты должны проверять изменения во времени, а не только один счастливый сценарий. Оставьте один тест для нового формата payload и один для старого, если вы всё ещё поддерживаете оба. Такая маленькая привычка рано ловит дрейф и делает переходы спокойнее.
Обычно именно такой постепенный подход и нужен маленьким командам. Он даёт реальный контракт, не превращая каждое небольшое изменение payload в маленький пожар.
Простой пример с двумя Python-сервисами
Небольшое расхождение между сервисами может превратиться в реальную ошибку биллинга. Представьте сервис заказов, который отправляет данные оплаты в сервис биллинга после того, как клиент нажал «pay».
Сначала сервис заказов отправляет total как число с плавающей точкой. Это кажется безобидным: 19.99 выглядит как цена. Но сервис биллинга ожидает total_cents как целое число, потому что платёжные системы обычно лучше работают с полными центами.
from pydantic import BaseModel, ConfigDict, ValidationError
class BillingRequest(BaseModel):
model_config = ConfigDict(strict=True)
order_id: str
total_cents: int
currency: str
bad_payload_1 = {
"order_id": "ord_123",
"total": 19.99,
"currency": "USD"
}
bad_payload_2 = {
"order_id": "ord_123",
"total_cents": 1999,
"currency_code": "USD"
}
try:
BillingRequest.model_validate(bad_payload_1)
except ValidationError as e:
print(e)
try:
BillingRequest.model_validate(bad_payload_2)
except ValidationError as e:
print(e)
Первый payload не проходит по двум хорошим причинам. Он отправляет total вместо total_cents и передаёт число с плавающей точкой вместо целого числа. Без строгой проверки payload команда могла бы тихо преобразовать 19.99, а позже столкнуться с проблемами округления.
Второй payload показывает другой вид дрейфа. Кто-то переименовал currency в currency_code в сервисе заказов. Возможно, новое имя там было удобнее. Но сервис биллинга всё ещё ожидает старое поле, и запрос останавливается на валидации.
Именно эта остановка и важна. Код биллинга не должен гадать, что означает payload. Если валидация срабатывает до логики списания средств, сервис отклоняет запрос, логирует точное несоответствие и избегает неправильной суммы или частичной записи об оплате.
Вот где модели Pydantic для дрейфа API действительно оправдывают себя. Они падают быстро, близко к границе, и делают поломку очевидной. Компромисс появляется позже, когда команды начинают моделировать каждое маленькое изменение поля вместо того, чтобы чинить общий контракт, который реально разделяют оба сервиса.
Где строгие модели замедляют команды
Строгие модели быстро ловят плохие данные, но они же делают мелкие изменения дороже. Переименуйте одно поле, разделите одно значение enum или поменяйте формат даты — и двум-трём сервисам может понадобиться обновление в одном и том же релизном окне. Для биллингового события, которое почти никогда не меняется, это нормально. Для внутренних API, которые всё ещё меняются каждую неделю, это уже раздражает.
Многие команды особенно остро чувствуют эту боль, когда изменение payload само по себе маленькое, а процесс вокруг него — нет. Одно дополнительное поле может означать обновление модели, правки тестовых данных, комментарии на ревью и ещё один деплой для потребителя. Сама работа несложная. Просто она постоянно отвлекает людей.
Когда внешние payload'ы грязные
Партнёрские API редко долго остаются аккуратными. Один клиент отправляет userId, другой — user_id, а третий присылает пустую строку там, где ваша модель ждёт целое число. Если ваш сервис использует очень строгие модели Pydantic на входе, команде часто приходится писать обёртки только для того, чтобы привести эти данные к нужному виду до валидации.
Этот слой обёртки может быстро раздуться. Вскоре вы поддерживаете уже не один понятный контракт. Вы поддерживаете контракт плюс кучу правил очистки для каждого странного случая, который присылает партнёр.
Большие модели создают и другую нагрузку. Модель на 60 полей выглядит безопасно на бумаге, но каждое небольшое изменение требует больше времени на ревью, потому что людям нужно проверять значения по умолчанию, алиасы, валидаторы, тестовые данные и допущения downstream-систем. Модель превращается в пункт чек-листа, а не в полезный ограничитель.
На ранней стадии продукта over-modeling особенно мешает. Если функция всё ещё прототип, строгие правила могут слишком рано зафиксировать решения. Команды начинают спорить о каждом необязательном поле ещё до того, как поймут, что именно будут отправлять пользователи. На этом этапе обычно лучше зафиксировать лишь несколько полей, которые влияют на поведение, а остальное какое-то время оставить гибким.
Простое правило помогает: держите центр строгим, а края — свободнее. Проверяйте идентификаторы, значения статусов и поля, которые запускают деньги, безопасность или запись данных. Для полей, которые ещё меняются, оставьте немного свободы, пока форма не перестанет меняться.
Ошибки, которые создают лишнюю работу
Модели Pydantic для дрейфа API приносят максимум пользы, когда команды воспринимают их как небольшой контракт, а не как полную копию реальности. Лишняя работа начинается, когда люди моделируют каждый вложенный объект уже в первый день. Простой event внезапно превращается в шесть файлов, двадцать классов и длинные обсуждения на ревью о полях, которыми никто не пользуется.
Обычно это происходит, когда команда видит один сложный payload и пытается сразу зафиксировать всё. Если сервису B нужны только customer_id, status и total, опишите сначала только их. Остальное оставьте обычным объектом или просто игнорируйте, пока оно не станет важным. Так вы снижаете риск, не превращая небольшое изменение в неделю уборки.
Ещё одна частая ошибка — использовать модели базы данных как API-контракты. Строки в базе меняются по причинам хранения. Payload'ы API меняются по причинам общения между сервисами. Это разные задачи. Если связать их вместе, безобидное переименование столбца может сломать границу сервиса, которую не нужно было трогать.
Обработка ошибок создаёт свой собственный хаос. Когда валидация не проходит, а API возвращает общий 500, никто ничего не понимает. Отправитель повторяет запрос. Получатель пишет стек-трейс. Две команды теряют полдня, гадая, проблема в коде, данных или инфраструктуре. Понятный ответ 400 с деталями по полям быстро экономит время.
Слабая типизация тоже выглядит дружелюбно, пока не начинает создавать горы исправлений. Если принимать строки вместо чисел и дат, каждый сервис придумывает свои правила разбора. Одна команда отправляет "10", другая — "10.00", а кто-то ещё — "next Friday". Модель перестаёт быть контрактом и превращается в скрипт для уборки.
На code review есть понятный тревожный знак: полей становится всё больше, а никто их не читает. Так контракты и захламляются. Лишние поля увеличивают стоимость тестов, документации и миграций. Ещё они мешают заметить реальные ломающие изменения.
Лучший default — намеренно скучный:
- моделируйте только те поля, которые читает потребитель
- держите API-модели отдельно от ORM-моделей
- возвращайте понятные ошибки валидации
- используйте строгие типы для денег, идентификаторов и дат
- удаляйте неиспользуемые поля после короткого ревью
Олег Сотников часто подталкивает команды к такому лёгкому подходу в работе над AI-first разработкой, и это имеет смысл. Строгая проверка должна рано ловить плохие данные. Она не должна превращать каждое сообщение в большой проект по схемам.
Быстрые проверки перед тем, как добавить ещё одно поле
Большинство лишних полей начинается с безобидной просьбы и заканчивается долгосрочным сопровождением. Новое поле меняет тесты, документацию, порядок деплоя и умственную нагрузку для каждой команды, которая работает с этим payload.
Прежде чем добавить его, проверьте, читает ли его кто-то прямо сейчас. Если сегодня его не использует ни один сервис, вы, возможно, закладываете в контракт будущие догадки. Вот так API становятся шире, сложнее для понимания и легче ломаются случайно.
Небольшая пауза помогает больше, чем ещё один быстрый патч:
- Назовите сервис или человека, который читает это поле сегодня.
- Спросите, что произойдёт, если тип окажется неверным. Повлияет ли это на биллинг, проверку доступа или другой чувствительный путь?
- Решите, есть ли безопасное значение по умолчанию, если поля не будет.
- Используйте строгий режим Pydantic только для тех полей, где плохие данные действительно вредят.
- Назначьте одного ответственного за изменения версий, даже если API общий для двух команд.
Второй пункт важнее, чем многие признают. Неверная строка в поле заметок — это неприятно. Неверный тип в price, currency, user_id или role может привести к неправильным списаниям или слишком слабым проверкам доступа. Такие поля заслуживают жёсткой проверки сразу, даже если локальное тестирование станет чуть медленнее.
К значениям по умолчанию нужен такой же подход. Если timezone можно безопасно заменить на UTC, хорошо. Если discount_percent по умолчанию становится 0, это может неделями скрывать ошибку отправителя. Тихие значения по умолчанию кажутся удобными, пока finance не спрашивает, почему изменились суммы.
Именно здесь модели Pydantic для дрейфа API помогают сильнее всего: они делают рискованные части явными. Они помогают меньше, когда команда моделирует с той же жёсткостью каждую необязательную метку метаданных. Если поле только информационное и никакая downstream-логика от него не зависит, более свободная модель часто помогает двигаться быстрее.
Ещё одно правило экономит много сил: изменения версий должны иметь понятного владельца. Кто-то должен решать, когда поле добавляют, когда оно становится обязательным и когда старые payload'ы перестают работать. Без этого обе команды думают, что разберётся другая сторона, и дрейф начинается снова.
Что делать дальше
Выберите один endpoint, который приносит реальную боль, и начните с него. Callback для логина, webhook биллинга или внутренний триггер задачи обычно дают достаточно трафика и достаточно грязных payload'ов, чтобы быстро научиться.
Модели Pydantic для дрейфа API лучше всего работают, когда первая версия остаётся маленькой. Опишите поля, которые ломают downstream-код, а не каждое поле, которое может пригодиться когда-нибудь потом. Если одному сервису нужны только user_id, plan и status, оставьте контракт на этом уровне и пока не усложняйте его.
Практический план внедрения выглядит так:
- Выберите один шумный endpoint с историей плохих payload'ов, пропущенных полей или расхождений в типах.
- Добавьте проверку на границе сервиса и логируйте каждый отклонённый payload с короткой причиной.
- Наблюдайте за этими отклонениями две недели и группируйте их по причинам.
- Уберите или ослабьте правила, которые не предотвращают реальные сбои в продакшене.
Этот этап важен, потому что команды часто переусложняют всё слишком рано. Они добавляют enum'ы для каждого статуса, жёсткие ограничения для строк, которые никто не читает, и вложенные модели для данных, которыми не пользуется ни один отправитель. Неделю это кажется аккуратным, а потом каждое небольшое изменение наверху превращается в лишнюю работу.
Лучший тест простой: остановило ли это правило падение, плохую запись или проблему поддержки? Если нет — убирайте его. Строгая проверка payload'ов должна блокировать дорогие ошибки, а не усложнять обычные изменения.
Если нужен конкретный пример, представьте два Python-сервиса, которые обмениваются обновлениями заказов. Сервис A в пятницу отправляет amount как строку, в понедельник — как число, а иногда вообще пропускает currency, когда включается новый путь кода. Небольшая модель Pydantic ловит это на входе, а логи показывают, какая ошибка встречается чаще всего. У вас появляются факты, а не догадки.
Если ваши контракты Python-сервисов часто дрейфуют, внешний взгляд может сэкономить время. Олег Сотников как Fractional CTO занимается таким планированием контрактов и внедрения, а также имеет сильный опыт в Python-сервисах, production-системах и lean engineering-командах. Обычно достаточно короткого ревью, чтобы выбрать правильные endpoint'ы, установить разумные правила и не устраивать потом большой проект по уборке.


