Модель зрелости инженерной команды стартапа для плана найма
Используйте эту модель зрелости инженерной команды стартапа, чтобы оценить дисциплину релизов, ответственность за сервисы и реагирование на инциденты, а затем составить план найма, который подходит вашей команде.
Содержание
Почему найм часто промахивается мимо настоящей проблемы
Многие команды стартапов просят нанять ещё инженеров ещё до того, как разберутся с привычками, которые тормозят их каждую неделю. Запрос звучит разумно. Работы накапливается всё больше, баги не исчезают, релизы кажутся рискованными, и у всех ощущение, что ресурсов не хватает.
Но рост штата часто оказывается самым заметным ответом, а не самым правильным. Команда может добавить двух человек и всё равно выпускать изменения с опозданием, если никто не знает, кто отвечает за каждый сервис, как код попадает в продакшен и кто берёт управление, когда что-то ломается.
Основатели часто не видят здесь всей картины. Они слышат: «нам нужны ещё разработчики», но не видят каждую передачу задачи, каждый откат и каждое растерянное сообщение во время аварии. Поэтому они одобряют найм, чтобы снять боль, которую видят, а настоящая проблема продолжает жить в ежедневной работе.
Один плохой инцидент только усугубляет ситуацию. Болезненный сбой вызывает панику, а паника обычно превращается в запрос на найм. Но если сбой произошёл потому, что алерты игнорировали, ответственность была неясной или никто не доверял релизному процессу, ещё один инженер мало что исправит. Команда просто размажет тот же хаос на большее число людей.
Простой счёт меняет разговор. Вместо споров на стрессе или по ощущениям посмотрите на три сигнала: насколько предсказуемы релизы, есть ли у каждого сервиса понятный владелец и как команда реагирует, когда в продакшене что-то ломается.
Именно здесь помогает модель зрелости инженерной команды. Она отделяет нехватку людей от нехватки процесса. Иногда вам действительно нужен ещё один backend-инженер. Иногда вам нужен чек-лист релиза, один назначенный владелец на каждый сервис и простое правило, кто первым реагирует на инцидент.
Это важно, потому что найм стоит больше, чем зарплата. Новым людям нужны контекст, ревью, доступы и время менеджмента. Если команде уже не хватает дисциплины релизов, ответственности за сервисы и привычек работы с инцидентами, каждый новый сотрудник попадает в путаницу.
Спокойная оценка подсказывает лучший следующий шаг. Вы перестаёте нанимать, чтобы снять напряжение, и начинаете нанимать под реальное ограничение.
Три области для оценки
Большинству команд не нужен длинный аудит. Им нужны три оценки, с которыми можно согласиться за одну встречу, а потом повторять их каждый квартал. Держите всё просто, иначе никто не захочет пользоваться этим второй раз.
Первая область — дисциплина релизов. Это о том, как команда планирует изменения, выпускает их и откатывает, если что-то идёт не так. Команды с хорошей дисциплиной выпускают небольшие изменения, понимают, что именно уходит в продакшен, и могут откатиться без паники. Команды со слабой дисциплиной сваливают слишком много работы в одну кучу, полагаются на память и превращают каждый деплой в напряжённое событие.
Следующая область — ответственность за сервисы. У каждой живой системы должен быть понятный владелец: API, фоновой задачи, интеграции с биллингом или основной базы данных. Владелец не обязан писать каждое изменение. Он должен понимать, как работает сервис, одобрять рискованные обновления, поддерживать актуальные заметки и отвечать за надёжность. Если за систему никто не отвечает, баги быстро начинают переходить от одного человека к другому, а планы найма становятся размытыми.
Третья область — реагирование на инциденты. Посмотрите на три момента: когда команда заметила проблему, кто взял управление и что изменилось после исправления. Быстрое реагирование не означает постоянный героизм. Это значит, что алерты доходят до нужного человека, у команды есть простой путь к действию, и после инцидента она фиксирует один вывод, который снижает вероятность повторения проблемы.
Короткая таблица оценки обычно работает лучше, чем длинная. Задайте простые вопросы:
- Выпускали ли мы небольшие изменения с безопасным путём отката?
- Можем ли мы назвать одного владельца для каждого живого сервиса?
- Когда случился последний инцидент, как быстро мы его обнаружили и что изменилось после него?
Если команда отвечает без споров, оценка, скорее всего, честная. Если каждый ответ начинается с «смотря как», пробелы уже видны. Это сильно облегчает последующие решения о найме.
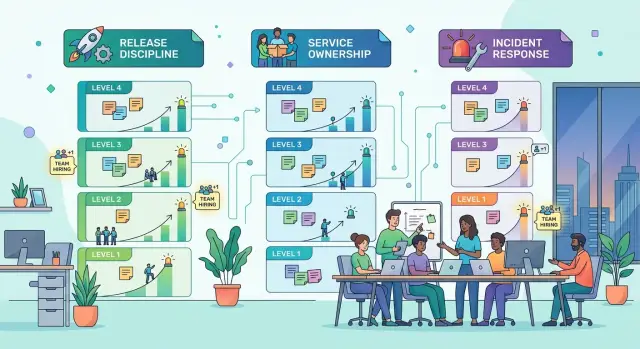
Как выглядят уровни 1–4
Команда не переходит на следующий уровень просто потому, что наняла больше людей. Она растёт, когда ежедневная работа перестаёт зависеть от памяти и героизма. Небольшая команда может дойти до уровня 3. Большая команда может всё ещё вести себя как уровень 1.
-
Команды уровня 1 работают на памяти. Релиз происходит тогда, когда один или два надёжных человека помнят шаги, следят за логами и чинят всё, что ломается. Ответственность за сервисы размыта, поэтому люди спрашивают в чате, кто за что отвечает, или ждут ответа от того же старшего инженера. Когда случается инцидент, команда реагирует быстро, но не спокойно. Она латет проблему и идёт дальше.
-
Команды уровня 2 уже имеют несколько общих рутин. У них может быть чек-лист релиза, базовая передача задач и несколько инструкций. Это помогает, но один человек всё ещё знает странные детали, которые удерживают продакшен в стабильном состоянии. Ответственность начинает появляться, но команда всё ещё сильно опирается на отдельных людей в сложных решениях. Реагирование на инциденты улучшается, потому что люди знают первые шаги, хотя последующие исправления часто буксуют.
-
Команды уровня 3 выпускают изменения в устойчивом ритме. Релизы проходят одинаково каждый раз, с понятными проверками и меньшим числом сюрпризов. У каждого сервиса есть владелец, и все знают, кто принимает решения, кто проводит ревью и кого поднимают по тревоге, когда что-то ломается. Инциденты всё ещё случаются, но команда их фиксирует, устраняет причину и обновляет процесс, чтобы в следующий раз та же проблема причиняла меньше вреда.
-
Команды уровня 4 ищут не только пожары, но и закономерности. Они разбирают неудачные релизы, шумные алерты, повторяющиеся обращения в поддержку и сервисы, которые слишком сильно зависят от одного человека. Затем они меняют систему: добавляют лучшие тесты, делают передачи понятнее и убирают скрытую работу. Хаос не исчезает, но повторяющийся хаос становится редкостью, потому что команда постоянно убирает слабые места.
Переход от одного уровня к другому обычно заметен сразу. Если ваша команда не может выпускать изменения без того, чтобы определённый человек был онлайн, вы не на уровне 3. Если один и тот же сбой возвращается каждый месяц, вы не на уровне 4.
Как оценить команду за одну встречу
Используйте факты, а не память. Одна встреча может дать честную оценку, если принести последние 10 релизов, последние 3 инцидента и простую карту команды, где видно, кто над чем работает. Если люди помнят события по-разному, доверяйте тикетам, логам деплоев и заметкам по инцидентам.
Начните с карты команды. Выпишите каждый сервис, фоновую задачу, приложение и внутренний инструмент. Потом поставьте рядом с каждым один ответственный. Если рядом с одним сервисом стоят два имени, продолжайте разговор, пока не появится один человек, который отвечает за ежедневное сопровождение. Общая ответственность часто скрывает слабую ответственность.
Потом пройдитесь по последним 10 релизам по порядку. Отметьте, где работа стопорилась, кто утверждал релиз и кто подключался, когда что-то ломалось. Вы ищете дисциплину релизов, а не скорость. Команда, которая выпускает медленно, но одинаково каждый раз, в лучшем состоянии, чем команда, которая выпускает быстро только тогда, когда онлайн один старший инженер.
Затем разберите последние 3 инцидента. Запишите, кто заметил проблему, кто взял управление, кто починил и как сработала передача. Это очень быстро делает реагирование на инциденты видимым. Если алерты приходят одному человеку, исправления зависят от одного человека, а обновления делает один человек, оценка должна оставаться низкой.
Простой способ сохранить честность встречи:
- Поставьте каждой области оценку от 1 до 4.
- Привяжите к каждой оценке один реальный пример.
- Снижайте оценку, если пример зависит от того, что один человек спас ситуацию.
- Снижайте оценку, если никто не может назвать владельца за 10 секунд.
- Не обсуждайте найм, пока оценка не станет немного неудобной, но правдивой.
Последний пункт особенно важен. Команды часто слишком рано переходят к ролям: нанять DevOps, нанять QA, нанять ещё одного старшего backend-инженера. Подождите. Если оценка основана на расплывчатых ощущениях, план найма тоже будет расплывчатым. Честная оценка обычно сначала указывает на более маленькое исправление — например, более ясную ответственность, чек-лист релиза или ротацию лидов по инцидентам.
Простой пример на команде SaaS из шести человек
Представьте SaaS-компанию из шести человек с продуктом, который нравится пользователям, стабильным потоком пробных регистраций и дорожной картой, которая только растёт. На бумаге команда выглядит готовой нанять ещё двух разработчиков. На практике она всё ещё хрупкая.
Релизы происходят только тогда, когда оба старших инженера остаются онлайн после выпуска. Никто настолько не доверяет процессу, чтобы нажать кнопку и спокойно уйти. Если один из старших инженеров берёт выходной, релизы замедляются или переносятся. Это не в первую очередь проблема численности. Это проблема дисциплины релизов.
Биллинг тормозит команду по-другому. Когда клиент видит неправильное списание, баг не попадает к одному понятному владельцу. Продукт говорит, что это должна чинить инженерная команда. Инженеры говорят, что проблема началась в правилах тарификации или настройке плана. Тикет ходит по кругу день или два, пока поддержка ждёт. Клиентам всё равно, какая команда коснулась этого последней. Они просто видят неверный счёт.
С реагированием на инциденты всё ещё хуже. Алерты всё ещё приходят основателю, потому что никто не выстроил привычку дежурств. Когда ночью в 2:00 что-то ломается, основатель просыпается, пингует команду и пытается угадать, кто должен ответить. Это может работать при пяти клиентах. Но когда база клиентов растёт, такая схема быстро становится дорогой.
Оценка довольно ясная:
- Дисциплина релизов — между низкой и средней. Команда может выпускать изменения, но только под ручным присмотром старших людей.
- Ответственность за сервисы — низкая. У биллинга нет прямого владельца, поэтому баги кочуют туда-сюда.
- Реагирование на инциденты — низкое. Команда реагирует, но основатель всё ещё остаётся запасной системой.
Это меняет план найма. Добавление ещё нескольких feature-инженеров сейчас, скорее всего, даст больше кода, больше передач и больше релизов после рабочего времени. Сначала команде нужен один сильный лидер. Он должен выстроить рутину релизов, назначить одного владельца на биллинг и создать базовую ротацию дежурств.
После этого новые сотрудники попадут в команду, которая способна их принять. До этого любой найм просто на несколько месяцев спрячeт настоящую проблему.
Как меняется найм на каждом уровне
Слабой команде нужен не тот же самый найм, что и стабильной. Если ошибиться, можно потратить большую зарплату на сильного человека, который всё равно не уберёт ежедневный хаос.
На уровне 1 команда обычно буксует на базовой дисциплине релизов и хаотичном реагировании на инциденты. Один менеджер это не исправит. Часто нужны один-два практичных инженера, которые пишут код, безопасно выпускают небольшие изменения, задают простые правила релизов и документируют, что делать, когда продакшен ломается. Здесь полезнее тот, кто строит систему, а не тот, кто только размышляет о стратегии.
На уровне 2 релизы происходят уже регулярнее, но ответственность всё ещё сосредоточена у нескольких людей. Вот здесь уже начинает иметь смысл тимлид. Он должен распространять знания о сервисах, делать передачи задач чётче и останавливать схему, когда один инженер становится героем на каждый случай. Если контекст не распределяется, команда остаётся хрупкой.
На уровне 3 основная инженерная группа обычно уже работает достаточно хорошо, и тогда начинают окупаться вспомогательные роли. Возможно, сначала вам не нужен ещё один продуктовый инженер. Возможно, вам нужен человек, который сосредоточится на тестировании, надёжности или workflow разработчиков, чтобы команда выпускала быстрее и с меньшим количеством переделок. Часто именно здесь хороший engineering manager или fractional CTO находит лёгкие победы, потому что небольшое изменение процесса экономит часы каждую неделю.
На уровне 4 найм становится, в хорошем смысле, более скучным. Нанимайте под измеряемые узкие места, а не под широкие истории роста. Если цикл выпуска нормальный, но инциденты всё ещё будят людей ночью, нанимайте на надёжность. Если инженеры теряют время на ревью и сборки, нанимайте на улучшение developer workflow. Если качество падает под нагрузкой, добавляйте глубину тестирования.
Простое правило помогает:
- Уровень 1: нанимайте людей, которые помогают выстроить базовые привычки.
- Уровень 2: нанимайте лидера, который распределяет ответственность.
- Уровень 3: нанимайте поддержку вокруг скорости и качества команды.
- Уровень 4: нанимайте под узкое ограничение, которое можно измерить.
Так план найма остаётся привязанным к реальности, а не к надежде.
Ошибки, которые искажают оценку
Команды обычно завышают свою оценку, когда смотрят на намерения, должности или уверенность вместо ежедневного поведения. Эта модель помогает только тогда, когда описывает то, что команда действительно делает в обычный вторник.
Первым делом вводят в заблуждение должности. У человека может быть титул staff или lead, но если релизы всё равно стопорятся, пока не подключится основатель, команда ещё не дошла до уровня, который этот титул обещает. Оценивайте работу, а не визитку. Кто утверждает релизы, кто чинит сломанные деплои и кто может выпускать изменения без спасения — это важнее.
Следующая проблема — общая ответственность. Это звучит здорово, но часто просто скрывает пробел. Если за сервис отвечает «все», никто не принимает финальное решение, когда растёт задержка, взлетают затраты или начинается откат. Настоящая ответственность означает, что один человек может сказать: «Делаем так сейчас», и команда принимает это решение.
Тихие недели тоже могут обмануть. Некоторые команды говорят, что их сервис стабилен, потому что в прошлом месяце не было инцидентов. Это мало что значит, если никто не смотрит алерты, не проверяет ошибки и не разбирает логи. Тишина — не доказательство. Иногда это просто значит, что команда не увидела проблему.
Ещё одна частая ошибка — слишком рано копировать структуру большой компании. Стартапы добавляют уровни, делят команды по специализациям и придумывают менеджерские должности раньше, чем это оправдано нагрузкой. Потом растёт число передач задач, никто не чувствует близости к продакшену, и на бумаге команда выглядит более зрелой, чем есть на самом деле. Команде из шести человек редко нужна та же структура, что и команде из шестидесяти.
Оценка также уезжает вверх, когда в встрече доминирует один громкий менеджер. Уверенность — не доказательство. Лучший способ это остановить — проверять каждое утверждение на недавних примерах:
- Что произошло в последних трёх релизах?
- Кто отвечал за последнюю проблему в сервисе от первого алерта до исправления?
- Кто решил по поводу последнего отката или hotfix?
- Какие алерты кто-то проверяет каждый день?
Если в комнате не могут чётко ответить на эти вопросы, снижайте оценку. Это не жёсткость. Это польза. Честная оценка приводит к лучшим решениям о найме, потому что команда нанимает под реальный пробел, а не под историю, которую ей нравится рассказывать.
Быстрая проверка перед открытием новых вакансий
Эта модель помогает только тогда, когда она останавливает найм на инстинкте. Прежде чем писать вакансию, потратьте 10 минут с командой и проверьте, что на самом деле не хватает: навыка, ответственности или базовых рабочих привычек.
Если вы не можете быстро ответить почти на все эти вопросы, новый сотрудник попадёт в путаницу. Обычно это замедляет команду на месяц или два, а основатели потом удивляются, почему штат вырос, а результат — нет.
Используйте этот короткий чек:
- Может ли команда назвать одного понятного владельца для каждого сервиса или продуктовой области?
- Выпускала ли команда больше одного раза за последний месяц без паники, драм с откатом или срочных ночных правок?
- После последнего инцидента кто-то записал, что изменилось и что команда будет делать иначе в следующий раз?
- Понимает ли каждый новый инженер, кто утверждает релиз и кто принимает финальное решение, когда риск неясен?
- Могут ли основатели объяснить, какой именно пробел, оцененный по шкале, закроет следующий найм?
Последний вопрос — тот, который большинство команд пропускает. «Нам нужен старший инженер» — это не причина. «У нас низкая оценка по ответственности за сервисы, поэтому нам нужен человек, который возьмёт на себя биллинг и снизит зависимость от основателя» — это причина. Такой ответ меняет роль, интервью и первые 90 дней.
Команда из шести человек в SaaS часто может быстро увидеть проблему. Если никто не отвечает за алерты, инциденты кочуют между людьми. Если никто не знает, кто утверждает релиз, небольшие изменения ждут основателя. Если команда выпускает изменения только тогда, когда онлайн все, проблема не в объёме найма. Проблема в слабой дисциплине релизов.
Именно здесь внешний советник или fractional CTO может быть полезен. Хороший специалист не начнёт с должностей или длинной оргструктуры. Он задаст простые вопросы, честно оценит пробелы и свяжет следующий найм с одним исправлением, которое команда почувствует в течение нескольких недель.
Сначала проведите встречу, выберите три исправления и назначьте дату повторной оценки через 60–90 дней. Если после этого та же боль останется, следующий найм будет проще определить и с гораздо большей вероятностью принесёт пользу.
Что делать дальше
Поставьте оценку в календарь уже на этой неделе. Сделайте это вместе с теми, кто каждый день управляет работой: инженерным лидом, продуктовым лидом и тем, кто отвечает за поддержку или операционку. Эта модель помогает только тогда, когда группа сравнивает реальные примеры, а не личные догадки.
Если кто-то говорит, что дисциплина релизов «хорошая», спросите, что было в последних трёх релизах. Пользовались ли чек-листом? Кто-то делал откат? Зависел ли релиз от того, что один человек остался онлайн допоздна? Используйте тот же тест для ответственности за сервисы и реагирования на инциденты. Имена, даты и недавние события очень быстро убирают расплывчатые споры.
Потом выберите только три изменения на квартал:
- одно правило релиза, которому команда будет следовать каждый раз
- один пробел в ответственности, который получит понятного владельца
- одна привычка работы с инцидентами, которую команда будет отрабатывать после каждой проблемы
Не раздувайте масштаб. Команда обычно получает больше пользы от одного хорошего чек-листа релиза, чем от нового сотрудника, который попадает в хаотичный процесс. То же касается ответственности. Если два сервиса всё ещё принадлежат «тому, кто трогал их последним», исправьте это до открытия вакансии backend-разработчика.
Ещё раз проверьте оценку перед тем, как писать новую вакансию. Это экономит деньги и защищает от плохой логики найма. Многие команды думают, что им нужно больше инженеров, когда на самом деле им нужны более чёткие передачи задач, лучшее дежурство или понятнее границы сервисов. Если после нескольких правок процесса оценка вырастет, запланированная роль может измениться, уменьшиться или вообще исчезнуть.
Внешний обзор может помочь, если команда не может договориться об оценке или продолжает считать хаос нормой. Oleg Sotnikov на oleg.is работает со стартапами как fractional CTO и может разобрать релизный процесс, ответственность и привычки работы с инцидентами до того, как вы увеличите штат. Такой взгляд полезен, когда вам нужен простой ответ, проблема в людях, в процессе или в обоих сразу.
Проведите встречу, выберите три исправления и назначьте повторную оценку через 60–90 дней. Если та же боль вернётся, следующий найм будет проще сформулировать и гораздо вероятнее поможет.
Часто задаваемые вопросы
Как понять, нужен ли нам ещё один инженер или лучше наладить процесс?
Начните с трёх оценок: дисциплина релизов, ответственность за сервисы и реагирование на инциденты. Если релизы тормозят, владельцы остаются неясными или один человек каждый раз вытаскивает команду из аварии, сначала исправьте это. Нанимайте тогда, когда оценки показывают реальный дефицит мощности уже после улучшения базовых вещей.
Что стоит оценить в первую очередь?
Оцените дисциплину релизов, ответственность за сервисы и реагирование на инциденты. Эти три области показывают, выпускает ли команда изменения повторяемо, понимает ли, кто отвечает за каждый сервис, и не паникует ли, когда ломается продакшен.
Как выглядит низкая дисциплина релизов?
Обычно вы увидите ручные шаги, ночные деплои и откаты, которые зависят от одного старшего инженера. Команда может всё ещё выпускать изменения, но люди не доверяют процессу настолько, чтобы спокойно сделать релиз и уйти.
Почему общая ответственность — это проблема?
Часто это значит, что никто не принимает финальное решение. Баги кочуют туда-сюда, рискованные изменения слишком долго ждут, а инциденты затягиваются, пока люди выясняют, кто должен действовать. Один назначенный владелец убирает эту задержку.
Как мы можем оценить команду за одну встречу?
Принесите последние 10 релизов, последние 3 инцидента и простую карту сервисов с владельцами. Проходите по реальным событиям, а не по мнениям. Поставьте каждой области оценку от 1 до 4 и привяжите к ней один недавний пример.
Как выглядит уровень 3 на практике?
На уровне 3 команда выпускает изменения в устойчивом ритме, назначает одного владельца на каждый сервис и разбирает инциденты с понятным лидом. Проблемы всё ещё случаются, но команда фиксирует, что произошло, и меняет процесс так, чтобы та же проблема в следующий раз причиняла меньше вреда.
Стоит ли небольшому стартапу использовать модель зрелости?
Да. Небольшая команда часто получает от этой модели даже больше пользы, чем большая, потому что слабые привычки проявляются быстрее. Даже стартап из шести человек может увидеть, что росту мешает зависимость от основателя, размытая ответственность или хаотичные релизы.
Когда стоит нанимать лида вместо ещё одного разработчика?
Нанимайте лидa, когда команда уже более-менее регулярно выпускает изменения, но у нескольких человек всё ещё слишком много контекста. Такой человек должен делиться знаниями о сервисах, выстраивать более чёткие передачи и ломать схему, где один и тот же инженер спасает любую сложную ситуацию.
Какие ошибки заставляют команды завышать свою оценку?
Команды завышают оценку, когда доверяют должностям, уверенности или спокойным неделям. Смотрите на поведение в обычной работе. Если основатели всё ещё утверждают релизы, одни и те же люди просыпаются от алертов или никто не может быстро назвать владельца, снижайте оценку.
Может ли fractional CTO помочь до найма?
Внештатный CTO может проверить релизы, ответственность за сервисы и привычки реагирования на инциденты до того, как вы увеличите штат. Такой взгляд со стороны полезен, когда команда начинает считать хаос нормой или спорит, исходя из стресса. Oleg Sotnikov занимается такой работой и поможет понять, нужен ли вам найм, правки процесса или и то и другое.


