Мобильные офлайн-очереди для форм, повторов и устаревших правок
Мобильные офлайн-очереди помогают приложениям сохранять действия при слабом соединении, избегать двойных отправок и обрабатывать устаревшие правки по понятным правилам повторных попыток.
Содержание
Почему слабое соединение ломает поведение приложения
Слабое соединение ломает главное обещание мобильного приложения: «Я нажал «Сохранить», значит, оно должно сохраниться один раз». В хорошей сети это кажется очевидным. В поезде, в углу склада или в бетонной лестничной клетке тот же самый тап может зависнуть, провалиться без понятного сообщения, а потом сработать ещё раз, когда пользователь нажмёт кнопку второй раз.
Так и начинаются дубликаты. Сотрудник на выезде отправляет одну и ту же форму осмотра дважды, потому что кнопка выглядела зависшей. Клиент платит два раза, потому что приложение продолжало крутиться и не дало внятного ответа. Пользователю всё равно, проблема в телефоне, API или таймауте. Он видит только приложение, которое ведёт себя странно.
Устаревшие данные причиняют другой вред. Кто-то открывает запись в 9:00, теряет сигнал, редактирует её офлайн и сохраняет. В 9:05 коллега обновляет ту же запись на другом устройстве. Когда первый телефон снова подключается, его более старая версия может перезаписать более новую, если приложение примет позднюю синхронизацию, не проверив, какая правка должна победить. В итоге система хранит неверное значение, а никто этого не замечает, пока ошибка не начинает стоить времени или денег.
Слабый сигнал делает обе проблемы более вероятными, потому что запросы не ломаются аккуратно. Запрос может дойти до сервера, успешно выполниться там, а на телефоне всё равно выглядеть сломанным, потому что ответ так и не вернулся. Или он может истечь по таймауту, повториться и создать вторую копию того же действия. Именно в этом грязном промежутке и нужны офлайн-очереди.
Пользователи быстро теряют доверие, потому что такие ошибки воспринимаются лично. Когда форма пропадает, отправляется дважды или показывает вчерашние заметки сразу после редактирования, люди перестают полагаться на приложение. Они делают скриншоты, ведут бумажные копии или звонят кому-то, чтобы подтвердить каждое изменение. Как только пользователи начинают придумывать обходные пути, приложение уже проигрывает.
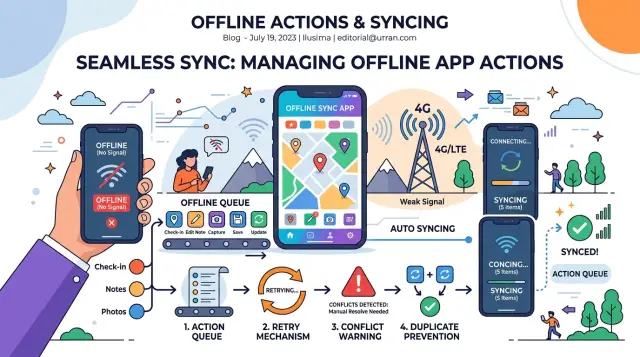
Что на самом деле хранит офлайн-очередь
Офлайн-очередь — это список действий, которые приложению ещё нужно отправить. Это не копия всей базы данных и не то же самое, что экран, который редактирует пользователь. Думайте о ней как о списке дел для сети.
Это разделение важно. Когда пользователь нажимает «Сохранить», приложение должно сначала записать изменение в локальное хранилище, чтобы экран обновился сразу. Синхронизация с сервером должна происходить после этого, в фоне, когда соединение достаточно хорошее. Если смешать эти шаги, пользователи решают, что работа пропала, хотя на самом деле приложение просто ещё не синхронизировало данные.
Каждый элемент очереди должен быть небольшим и понятным. В большинстве приложений одному элементу нужны тип действия, ID записи, время изменения, данные, необходимые для повторного выполнения, и локальный ID действия, чтобы приложение могло отслеживать именно эту попытку.
Простой пример помогает понять это лучше. Техник обновляет запись задания 842 в подвале без сигнала. Приложение сразу сохраняет правку на телефоне. Потом оно добавляет в очередь элемент вроде «обновить запись 842, установить статус “завершено”, создано в 10:43». Когда телефон снова подключается, приложение отправляет это действие позже.
Пользователю также нужно видеть статус каждого элемента очереди. Скрытые очереди порождают обращения в поддержку. Видимый статус сохраняет спокойствие и помогает понять, что делать дальше. На практике большинству приложений хватает нескольких простых состояний: сохранено на устройстве, ожидает синхронизации, синхронизируется, синхронизировано, не удалось или требуется проверка.
Этот небольшой кусочек обратной связи предотвращает много плохого поведения. Если человек видит «ожидает синхронизации», он с меньшей вероятностью нажмёт «Сохранить» ещё три раза или отредактирует ту же запись на другом устройстве и создаст mess с устаревшей правкой.
Как структурировать элементы очереди, чтобы они оставались понятными
Хорошие офлайн-очереди следуют одному простому правилу: каждое действие в очереди должно легко распознаваться позже. Если два сохранения выглядят почти одинаково, приложение начнёт гадать. Именно так начинаются дублирующиеся отправки и грязные баги синхронизации.
Давайте каждому действию свой client ID в момент, когда пользователь нажимает кнопку или меняет поле. Этот ID принадлежит действию, а не записи. Если пользователь сохраняет одну и ту же форму дважды при слабом соединении, приложение сможет понять, это одна и та же ожидающая операция, показанная на экране два раза, или две разные операции, которые нужно обрабатывать по-разному.
Используйте стабильный record ID с самого начала, даже до того, как сервер узнает о существовании записи. Если кто-то создаёт новый отчёт о расходах офлайн, приложение должно сразу создать локальный ID записи и использовать его для всех последующих правок. Не полагайтесь на позицию в списке, состояние экрана или логику «последнего черновика». Такие упрощения ломаются, как только пользователь снова открывает приложение или редактирует два черновика одновременно.
Большинству элементов очереди нужны несколько полей: action_id для точного пользовательского действия, record_id для того, что меняется, action_type вроде create, update или delete, а также версия схемы или приложения, чтобы рабочий процесс синхронизации мог безопасно воспроизводить старые элементы после изменений в приложении.
Держите create, update и delete отдельно. В интерфейсе они могут выглядеть похоже, но при синхронизации ведут себя по-разному. Для create часто нужна вся запись. Для update можно отправить только изменённые поля. Для delete может хватить только ID и проверки версии. Если запихнуть всё в одну универсальную форму, рабочий процесс синхронизации станет труднее понимать, а баги будут прятаться дольше.
Сохраняйте версию схемы вместе с каждым элементом очереди. Это маленькое поле приносит больше пользы, чем многие команды ожидают. Если в новом релизе переименовали поле или изменили формат хранения дат, рабочий процесс синхронизации сможет распознать старые элементы и преобразовать их перед отправкой.
Представьте полевое приложение для продаж с плохим сигналом на складе. Менеджер создаёт смету local-481, меняет цену, а затем добавляет заметку. Очередь хранит три ID действий, привязанных к одному стабильному ID записи. Спустя несколько часов приложение всё ещё может воспроизвести эти действия по порядку, не перепутав одну правку с другой.
Заранее задайте правила конфликтов до начала синхронизации
Если одну и ту же запись можно изменить в двух копиях, приложению нужен правило до начала синхронизации. Без него слабый сигнал превращается в тихую потерю данных. Техник может отредактировать наряд вне сети, пока в офисе кто-то меняет тот же наряд онлайн. Оба изменения логичны. Но выживет только одно, если не решить заранее, как обрабатывать конфликты.
Некоторые изменения можно объединить без участия пользователя. Самый простой случай — разные поля. Если один человек обновил номер телефона, а другой изменил время визита, приложение может собрать обе правки в одну запись. Сюда хорошо подходят и данные, которые только добавляются, например комментарии, фотографии или пункты чек-листа, потому что каждый новый элемент может оставаться отдельным.
Приложение должно остановиться и спросить пользователя, когда две правки затрагивают одно и то же поле или меняют смысл записи. Статус — частый пример. Если на сервере у записи стоит «завершено», а в кэше — «в работе», приложению нужно сделать паузу. Покажите оба значения и попросите пользователя выбрать одно или открыть запись на проверку.
Используйте один понятный способ обнаружения такого конфликта. Большинство приложений сравнивают значение, которое клиент видел последним, с тем, что сейчас хранится на сервере. Обычно для этого нужен номер версии, server-side updated_at timestamp или hash содержимого, когда важна точная проверка.
Номера версий обычно надёжнее временных меток. Часы на устройстве могут расходиться, а слабое соединение способно задерживать запросы так, что проверки по времени становятся запутанными. Клиент должен отправлять последнюю известную версию вместе с каждой отложенной правкой. Если версия на сервере изменилась, приложение не должно тихо её перезаписывать.
Удалённые записи нуждаются в отдельном правиле. Кэшированные данные часто случайно воскрешают их. Если пользователь редактирует запись офлайн после того, как кто-то другой удалил её на сервере, самый безопасный вариант — заблокировать синхронизацию и показать понятное сообщение. В некоторых продуктах, например в черновиках заметок, вы можете разрешить приложению создать запись заново. Но это должно быть осознанным решением, а не побочным эффектом.
Для многих приложений хватает одного набора правил: объединять разные поля, ставить паузу при правках одного поля и считать удаление жёсткой остановкой, если только восстановление не является частью продукта.
Постройте поток повторных попыток шаг за шагом
Поток повторной попытки начинается ещё до того, как приложение вообще пытается что-то синхронизировать. Когда пользователь нажимает «Сохранить» при слабом сигнале, приложение сначала должно записать действие в локальное хранилище. Если соединение пропадёт через секунду, приложение всё равно сохранит точное изменение и сможет отправить его позже.
После этого пометьте действие как поставленное в очередь и покажите этот статус простыми словами. Короткое сообщение вроде «Сохранено на этом устройстве. Ожидание синхронизации.» работает лучше, чем бесконечный спиннер. Люди нажимают дважды, когда им кажется, что ничего не произошло.
Последовательность должна оставаться скучной:
- Создавайте элемент очереди сразу, как только пользователь подтверждает действие.
- Сохраняйте порядок связанных элементов, если они влияют на одну и ту же запись.
- Когда приложение снова получает рабочее соединение, отправляйте первый ожидающий элемент и ждите ответа, прежде чем отправлять следующий связанный.
- Обновляйте статус элемента после каждого ответа.
- Удаляйте только те элементы, которые сервер принял.
Временные сбои тоже должны оставаться скучными. Если сервер не отвечает вовремя или возвращает кратковременную ошибку, оставьте элемент в очереди и попробуйте позже. Делайте паузу всё дольше после каждой неудачной попытки, чтобы приложение не долбило сеть и не разряжало батарею.
Пример из рабочего дня помогает представить это лучше. Техник обновляет сервисный отчёт в подвале с плохим сигналом. Приложение сохраняет отчёт локально, показывает его как ожидающий и отправляет, как только телефон снова подключается наверху. Если сервер принимает его, приложение удаляет этот элемент. Если другой сотрудник уже изменил тот же отчёт, приложение помечает конфликт и оставляет локальную правку видимой, а не заставляет её исчезнуть.
Именно такой порядок и делает офлайн-очередь спокойной, а не рискованной.
Как повторять попытки, не создавая дубликаты
Повторы помогают при слабом соединении, но слепые повторы создают хаос. Пользователь нажимает «Сохранить», телефон рвёт запрос, а приложение отправляет его снова через несколько секунд. Если сервер считает оба запроса новыми, появляются дублирующиеся заказы, дублирующиеся заметки или два обращения в поддержку вместо одного.
Самое безопасное решение начинается ещё до повторной попытки. Каждому create-действию нужен idempotency token, созданный на устройстве в момент первой отправки формы. Приложение должно сохранять тот же самый token для всех повторов этого элемента. Если первый запрос дошёл до сервера, а потерялся только ответ, сервер может сопоставить token и вернуть исходный результат, а не создать вторую запись.
Это особенно важно для create-действий. Update-действия обычно требуют стабильного record ID плюс проверки версии, а create-действия нуждаются в собственной идентичности ещё до того, как сервер присвоит свою.
Повторяйте только те ошибки, которые можно исправить
Некоторые сбои проходят сами. Другие — нет. Приложение должно знать разницу.
Повторяйте таймауты, обрывы соединения, лимиты запросов и кратковременные ошибки сервера. После каждой неудачи делайте паузу немного дольше. Простая схема backoff вроде 2 секунд, потом 5, потом 15 часто достаточно хороша. Останавливайтесь после небольшого лимита, например после трёх-пяти попыток. Не повторяйте ошибки проверки данных. Если формат email неверный или отсутствует обязательное поле, пользователь должен исправить это сам.
Этот лимит на повторы очень важен. Без него один плохой элемент очереди может крутиться бесконечно, разряжать батарею и блокировать более новые задачи позади него.
Когда повторы останавливаются, не скрывайте неудачный элемент. Оставьте его видимым в приложении с простым статусом вроде «Требуется проверка» или «Не удалось отправить». Дайте пользователю открыть его, исправить данные и попробовать ещё раз или сознательно отменить действие.
Представьте, что сотрудник на выезде отправляет отчёт о задаче в подвале с плохим сигналом. Приложение отправляет отчёт, теряет ответ и повторяет попытку дважды. Поскольку отчёт сохраняет тот же idempotency token, сервер хранит один отчёт, а не три. Если отчёт не проходит из-за отсутствующей обязательной фотографии, приложение прекращает повторы и показывает проблему, чтобы сотрудник мог всё исправить.
Простой пример из обычного рабочего дня
Техник заканчивает ремонт в подвале многоквартирного дома. Сигнал падает до одной полоски, а потом исчезает. Он открывает сервисный отчёт, добавляет две фотографии щитка, пишет короткую заметку о плохо закреплённом соединителе и просит клиента подписать экран.
Приложение не пытается протолкнуть всё через плохое соединение. Оно сначала сохраняет каждое изменение на телефоне. Фотографии, заметка и подпись попадают в локальную очередь вместе с ID задания, временем правки и request ID, уникальным для этого телефона. Эта деталь важна. Если он нажмёт «Сохранить» дважды, потому что экран кажется зависшим, сервер всё равно сможет считать обе попытки одной и той же правкой, а не создать дублирующий отчёт.
Пока он ещё под землёй, коллега в офисе открывает то же задание. Она добавляет свою заметку: «Клиент также сообщил о мерцании света в коридоре». Её обновление попадает на сервер первым, потому что у неё стабильное соединение.
Через десять минут техник выходит наружу, и приложение начинает синхронизацию. Вот тут очередь и показывает свою пользу. Сервер видит, что локальный черновик основан на более старой версии задания. Вместо того чтобы молча заменить офисную заметку, он останавливает эту часть синхронизации и показывает понятный конфликт.
Экран не должен вываливать на него стену текста. Он должен показать две заметки рядом, сделать различие очевидным и позволить ему оставить одну, объединить обе или отредактировать финальную версию перед отправкой. При этом приложение может спокойно загрузить фотографии и подпись, потому что они не конфликтуют.
Это обычный пример из рабочего дня, но он показывает самую суть. Слабое соединение не обязано приводить к потерянным правкам, двойным отправкам или запутанным повторам, если приложение сохраняет изменения локально, синхронизирует их по порядку и спрашивает решение до того, как перезаписать чужую работу.
Ошибки, которые приводят к двойным отправкам и устаревшим правкам
Большинство двойных отправок начинается с короткой задержки. Пользователь нажимает «Сохранить», две секунды ничего не происходит, и он нажимает ещё раз. Если приложение отправляет оба действия, сервер может создать два заказа, две заметки или два платежа. Решение просто в теории: сразу блокируйте это действие, показывайте, что нажатие было зарегистрировано, и передавайте idempotency token вместе с элементом очереди, чтобы сервер мог отклонить дубликат.
Время рождает другой класс багов. Многие команды сравнивают правки по времени устройства, потому что так кажется проще. Это быстро ломается, когда на одном телефоне часы отстают на пять минут, на другом меняется часовой пояс или пользователь восстанавливает старую резервную копию. Для конфликтов устаревших правок доверяйте версиям сервера, номерам ревизий или временным меткам сервера. Не позволяйте телефону решать, какая правка победит.
Ещё одна частая ошибка появляется после перезапуска. Пользователь заполняет форму в поезде, теряет сигнал и закрывает приложение. Если приложение хранит очередь только в памяти, эта работа исчезает. Хорошие очереди записывают ожидающие элементы в надёжное хранилище, загружают их при запуске и сохраняют достаточно метаданных, чтобы безопасно повторить попытку.
Сообщения об ошибках часто только усугубляют ситуацию. «Что-то пошло не так» ничего не объясняет. Пользователь нажимает ещё раз, редактирует снова или сдаётся. Лучше сказать, что именно произошло: элемент всё ещё ожидает, сервер отклонил поле или приложению нужно, чтобы пользователь просмотрел конфликт. Понятная формулировка предотвращает панические нажатия.
Самая рискованная ошибка — очищать локальные правки до того, как сервер подтвердит успех. На коде это может выглядеть аккуратно, но так можно стереть единственную хорошую копию. Держите локальное изменение до тех пор, пока сервер не примет его. Затем пометьте элемент очереди как завершённый и обновите локальную запись подтверждённой версией.
Один распространённый сценарий делает это очень наглядным. Менеджер по продажам обновляет адрес клиента в подземной парковке при слабом сигнале. Приложение показывает спиннер, она нажимает дважды и уезжает. Если приложение хранит одну отложенную правку с уникальным request ID, сохраняет черновик после перезапуска и ждёт подтверждения от сервера, прежде чем заменить локальные данные, эта правка остаётся в безопасности. Если нет, она может вернуться к дублирующей записи или старому адресу.
Краткая проверка перед релизом
Релиз с офлайн-очередями не готов только потому, что код синхронизации один раз сработал на вашем телефоне. Он готов тогда, когда люди могут потерять сигнал, нажать дважды, закрыть приложение, снова открыть его и всё равно получить один понятный результат.
Начните со статуса, который видит пользователь. Если форма исчезает сразу после отправки, люди решают, что она не сработала, и повторяют действие. Показывайте простой статус для каждого элемента: в очереди, отправляется, не удалось или требуется проверка. Этот маленький кусочек интерфейса предотвращает множество двойных отправок ещё до их появления.
Перед запуском проверьте несколько базовых вещей. Каждому create-действию нужен свой request ID, и приложение должно сохранять его между повторными попытками. Очередь должна переживать принудительное закрытие, перезагрузку и обновление приложения без потери статуса элементов. Пользователи должны с первого взгляда различать записи в очереди, отправленные, неудачные и конфликтные. Экраны конфликтов должны чётко показывать обе версии, даты, изменённые поля и очевидное следующее действие. И команда должна тестировать всё на медленных, нестабильных сетях, а не только на офисном Wi‑Fi.
Request ID важнее, чем многие ожидают. Если пользователь трижды нажмёт «Отправить» в лифте с плохим сигналом, сервер всё равно должен создать одну запись. Если приложение отправит тот же ID ещё раз, сервер сможет считать это тем же самым действием, а не новым.
Восстановление не менее важно. Убейте приложение в середине отправки. Перезапустите телефон. Включите авиарежим, а потом верните сеть. Очередь, которая забывает, что делала, создаст и устаревшие конфликты правок, и пропущенные обновления, а иногда и то, и другое.
Проверка конфликтов тоже должна быть на простом языке. Не показывайте два куска JSON или расплывчатое сообщение «ошибка синхронизации». Покажите «Ваша правка» и «Версия сервера», выделите изменённые поля и дайте людям выбрать, что оставить.
Хороший тест-кейс прост: сохраните заметку клиента офлайн, измените её ещё раз до синхронизации, а затем дайте другому устройству изменить ту же заметку первым. Если ваше приложение может чётко объяснить такой случай, значит, с обработкой повторных попыток, скорее всего, всё в порядке. Если не может — продолжайте тестировать.
Что делать дальше
Выберите один сценарий, где плохая синхронизация приводит к реальному ущербу. Формы — хороший старт. Заявки на согласование — тоже. Если приложение теряет отчёт, создаёт два заказа или сохраняет старую правку поверх новой, сначала исправьте именно этот сценарий, прежде чем распылять логику очередей на весь продукт.
Первую версию держите маленькой. Одна очередь, одна форма элемента, один понятный набор правил конфликтов. Команды часто попадают в неприятности, когда пытаются поддержать все крайние случаи сразу и получают поведение, которое никто не может объяснить.
Практичный план короткий: выберите одно рискованное действие, опишите правила повторных попыток и конфликтов простыми словами, протестируйте на реальных телефонах при слабом сигнале и перезапусках приложения, а потом сначала выпустите на небольшую группу. После этого смотрите, что ломается в логах и на устройствах.
Простой язык важнее, чем многие команды думают. Пишите правила вроде: «Если одна и та же форма отправилась дважды, оставьте одну запись». «Если кто-то редактирует более старую версию, покажите конфликт и попросите обновить данные». «Если сервер не отвечает вовремя, повторите попытку до трёх раз с тем же request ID». Когда правило легко прочитать, его проще реализовать и протестировать.
Используйте не лабораторный, а реальный рабочий сценарий. Попросите человека заполнить форму в парковке, переключаться между Wi‑Fi и мобильной сетью, закрыть приложение, а потом открыть его снова через десять минут. Такой тест быстро находит баги. Эмуляторы на компьютере помогают, но редко показывают странные сбои, с которыми люди сталкиваются вне офиса.
Считайте результаты после релиза. Отслеживайте дублирующиеся запросы, количество конфликтных экранов, число повторных попыток и возраст очереди. Если одно действие лежит в очереди 40 минут, пользователи это заметят, даже если синхронизация в итоге сработает.
Если вашей команде снова и снова сложно с дизайном очередей, правилами устаревших правок или поведением повторных попыток, короткий архитектурный разбор может сэкономить недели переделок. Oleg Sotnikov в oleg.is работает как fractional CTO и startup advisor, и такие задачи по архитектуре приложений — часть его повседневной работы.


