Многомодельная оркестрация для текста, кода и поиска
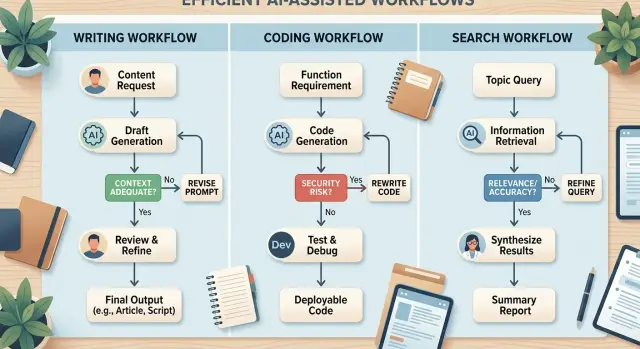
Многомодельная оркестрация работает лучше, когда разделять написание, изменения в коде и поиск по уровню риска, контексту и требованиям проверки, вместо того чтобы заставлять одну модель делать всё сразу.
Содержание
Что ломается, когда одна модель управляет всем потоком
Одна модель поначалу может выглядеть хорошо. Она пишет аккуратный текст, отвечает быстро и кажется подходящей для всего. Проблема проявляется, когда один воркфлоу требует одновременно трёх очень разных задач: актуальные факты, изменения в коде и поиск по документации, логам или прошлым решениям.
Первая ошибка — ложная уверенность. Модель может создать отшлифованное обновление для пользователей и при этом упустить недавнюю деталь о продукте или выдумать её, потому что промпт не включал последние факты. Ответ звучит правдоподобно, и люди доверяют ему слишком быстро. Это делает ошибку дороже, чем неидеальный черновик, который явно требует правки.
Код ломается по-другому. Та же модель может рефакторить файл за секунды и при этом сломать тесты, пропустить крайние случаи или изменить поведение за пределами запроса. Быстрый вывод даёт команде ощущение безопасности, когда стоит притормозить. Один аккуратный дифф может скрывать час отладки.
Размер промпта усугубляет проблему. Команды часто впихивают заметки по продукту, правила программирования, результаты поиска и инструкции по стилю в один длинный промпт. Модель начинает размывать приоритеты. Она следует гайду по стилю и забывает правило по тестам. Отвечает на вопрос пользователя и пропускает доказательства в логах. Самая важная инструкция оказывается похороненной.
Потом начинается цикл исправлений. Кто-то вручную правит те же факты. Кто-то прогоняет тесты и патчит такой же хрупкий код. Кто-то проверяет документацию снова, потому что модель уверенно сослалась не на тот источник. Эта уборка отнимает больше времени, чем команды ожидают.
Небольшое изменение продукта делает этот паттерн очевидным. Допустим, команда хочет обновить текст биллинга, изменить правило на бэкенде и подтвердить поведение по внутренним документам. Одна модель может попробовать сделать всё сразу, но, скорее всего, она хотя бы в чём-то ошибётся. Поэтому рабочий процесс лучше разбивать по типу ошибок, а не по удобству.
Когда одна модель ведёт весь поток, команда не получает один согласованный разум. Она получает один набор «слепых зон», повторяющихся на каждом шаге.
Сортируйте задачи по стоимости ошибки в первую очередь
Начните с оценки стоимости ошибки. Этот выбор сильно упрощает проектирование оркестровки, потому что не всем задачам нужен одинаковый уровень внимания.
Низкорисковая работа относится к первой корзине. Это черновики, идеи заголовков, краткие заметки, первичные поисковые запросы или ранние комментарии в коде. Если модель промахнётся, вы потеряете несколько минут.
Следующая корзина — то, что люди действительно увидят или запустят. Сюда относится продакшен-код, письма клиентам, ответы саппорта, релизные заметки и всё, что меняет продукт или влияет на доверие. Слабый ответ здесь может привести к багам, запутать пользователей или сбить команду с курса.
Высокий риск — это узкая, но контролируемая зона. Логика биллинга, правила безопасности, контроль доступа, юридические формулировки, соответствие требованиям и решения по обработке данных находятся здесь. Модель может помочь, но не должна принимать окончательное решение в одиночку.
Простое правило работает хорошо. Низкий риск — ошибка дешёва и легко исправима. Средний риск — результат доходит до пользователей или влияет на доставку. Высокий риск — ошибка может стоить денег, раскрыть данные или привести к юридическим проблемам.
Человеческая проверка нужна там, где ошибки становятся дорогими. Для низкорискового черновика достаточно быстрого просмотра. Для продакшен-кода проверяйте дифф, тесты и план отката до релиза. Для биллинга, безопасности или юриспруденции владелец области должен проверять каждое окончательное изменение.
Небольшие команды могут сразу применить этот подход. Одна модель делает черновик спецификации. Другая пишет идеи тестов. Более сильная модель для работы с кодом готовит изменения. Затем человек проверяет рисковые части перед деплоем. Это обычно работает лучше, чем просить одну модель делать всё, потому что воркфлоу уважает стоимость ошибки вместо того, чтобы притворяться, что все задачи одинаковы.
Подбирайте модель по потребностям контекста
Спросите просто: сколько контекста требует задача и какого рода он?
Модель, которая пишет короткий статус, не нуждается в тех же входных данных, что модель, которой нужно проследить баг через правила продукта, таблицы БД и старые решения в коде. Если одна модель делает обе задачи, она либо будет пропускать детали, либо будет слишком дорогой для рутинной работы.
Для задач, зависящих от длинной памяти о продукте, используйте модель с большим окном контекста. Это чтение спецификации, сравнение с текущим поведением, проверка прошлых решений и одновременное удержание нескольких файлов в голове. Здесь команды тихо теряют время: модель забывает одно правило, а затем пишет аккуратный ответ, который ломает что-то небольшое, но дорогое.
Актуальные факты — другая история. Если ответ зависит от текущих документов, версий пакетов, изменений в политике или внешних исследований, сначала запускайте поиск или инструмент извлечения. Эти инструменты лучше там, где факты могли измениться. Соберите материал и передайте краткое резюме в следующий шаг.
Изменения в коде требуют модели для работы с кодом. Если нужно править, делать диффы, чинить тесты или разбирать стектрейсы, берите ту модель, которая хорошо понимает структуру кода и вывод инструментов. Общая текстовая модель может объяснить баг, но хуже справится с патчем и проверкой прогонов тестов.
Дешёвые модели тоже важны. Держите мелкие задачи небольшими, чтобы они не съедали бюджет, предназначенный для рискованных работ. Суммарные задачи, переписывание сообщений коммитов, извлечение acceptance-criteria, классификация запросов в саппорт и краткие передаточные заметки — хорошие кандидаты.
Такой раздельный подход хорошо работает в командах. Консультант или временный CTO может настроить одну модель для удержания контекста продукта и репозитория, второй шаг для сбора свежих документов и модель для кода, которая делает изменение и проверяет тесты. Передача остаётся короткой. Каждая модель делает то, что у неё лучше получается, а дорогая модель появляется только там, где ошибка стоит реального времени или денег.
Выбирайте точки передачи и проверки
Воркфлоу усложняется, когда каждый шаг сваливает в следующий огромный кусок текста и надеется на лучшее. Каждый шаг должен выдавать один понятный результат: резюме, черновик, патч, план тестов или короткий ответ от поиска. Когда у вывода одна цель, следующий шаг знает, что делать, и человек может быстро проверить результат.
Держите передачи маленькими. Передавайте только тот контекст, который нужен следующей модели для выполнения своей задачи. Шаг по работе с кодом может требовать тикет, список файлов и одно правило, которое нужно соблюдать. Ему обычно не нужен весь чат, старые неудачные черновики и страницы заметок поиска.
Меньшие передачи также уменьшают затраты. Больше контекста часто создаёт путаницу, а не лучший результат. Шаг поиска может вернуть три доверенных фрагмента, и шаг программирования использует их вместо сырых результатов поиска.
Короткие структурированные заметки помогают больше, чем длинные объяснения. Сохраняйте решения в формате, который можно просмотреть за секунды: что шаг завершил, какие факты использовал, какое принятое решение, что осталось открытым и что нужно следующему шагу. Думайте об этом как о квитанции для воркфлоу. Когда что-то идёт не так, видно, где путь изменился, без перечитывания всех промптов.
Точки проверки ставьте там, где ошибка дорогая. Останавливайтесь до того, как модель пишет в продакшн-код, отправляет ответ клиенту или превращает неуверенные результаты поиска в факты. Проверка может быть простой: соответствует ли вывод задаче, использует ли утверждённые источники и не выходит ли за рамки?
Лёгкая продуктовая команда может разнести один запрос так: одна модель суммирует баг-репорт, другая ищет по документации и прошлым ишью, модель для кода делает патч. Поток приостанавливается, если поиск не нашёл надёжного источника или патч затрагивает файлы за пределами согласованной области. Эта пауза обычно экономит больше времени, чем исправление плохого мёржа позже.
Строьте воркфлоу шаг за шагом
Выберите один результат, по которому можно объективно судить. Небольшая фича — хороший старт: добавить фильтр на дашборд или изменить одно API-ответ. Если цель расплывчата, все последующие шаги тоже станут расплывчатыми и модель начнёт гадать.
Затем разделите работу по типу задачи, а не по удобству. Один шаг делает черновик изменения и перечисляет крайние случаи. Другой пишет или редактирует код. Отдельный шаг проверяет факты, ищет в документах или сравнивает вывод с правилами в репозитории. Вот тогда оркестрация становится практичной, а не декоративной.
Дайте каждому шагу правило прохождения
Каждый шаг нуждается в одном ясном критерии успеха, который можно прочитать за секунды.
Шаг написания проходит только если он называет действие пользователя, ожидаемый результат и один крайний случай. Шаг программирования проходит только если тесты проходят и дифф остаётся внутри согласованных файлов. Шаг поиска проходит только если он берёт ответ из утверждённого источника: внутренней документации, логов или кода.
Это важно, потому что модели ошибаются по-разному. Текстовая модель может написать чистый план и при этом упустить жёсткое ограничение. Модель для кода может решить задачу, но изменить слишком много. Модель поиска может вернуть правдоподобный ответ и при этом взять его из неверного места.
Добавляйте повторы с оглядкой
Повторы полезны, когда они исправляют известную ошибку. Если шаг программирования часто забывает файл тестов, перезапустите его с текстом ошибки и шаблоном файлов. Если поиск терпит неудачу из-за слабого запроса, перепишите запрос один раз и попробуйте снова.
Не добавляйте петли повсюду. Они скрывают плохие промпты, тратят деньги и делают медленные воркфлоу ещё медленнее.
Отслеживайте стоимость, время выполнения и уровень ошибок с первого дня. Измеряйте каждый шаг отдельно, а не только весь поток. Это облегчает поиск слабых мест и держит выбор модели привязанным к реальным данным.
Олег Sotnikov часто работает с экономными AI-first командами, где маленькие команды выпускают под жёсткими ограничениями по стоимости и доступности. Та же привычка помогает и здесь. Если один шаг часто падает, сначала исправьте этот шаг, а не меняйте весь процесс.
Простой пример: от брифа до релиза
Небольшая SaaS-команда хочет добавить опцию экспорта, чтобы клиенты могли скачать отфильтрованные записи в CSV. Запрос кажется простым, но комбинирует текст продукта, изменения в коде, покрытие тестами и правила пакетов. Если одна модель возьмётся за всё, ошибки быстро накапливаются.
Команда разбивает задачу по типам работ. Одна модель пишет, одна проверяет текущие факты, одна вносит изменения в приложение, а человек делает финальную проверку.
Сначала продакт-менеджер даёт сырые заметки модели для написания: кто нуждается в экспорте, на каком экране он будет, какие колонки включать и что делать при пустых данных. Модель превращает это в короткую спецификацию с понятными acceptance-criteria.
Далее шаг, ориентированный на поиск, читает спецификацию и проверяет документацию по пакету экспорта, недавние заметки о релизах и ограничения по кодировке, размеру файла или поддержке в браузерах. Он отмечает полезную деталь: в недавнем обновлении пакета изменилось поведение по умолчанию для разделителя.
Затем модель для кода получает короткую спецификацию и заметки поиска. Она добавляет кнопку экспорта, подключает бэкенд-эндпоинт, обновляет тесты и прогоняет тест-сьют.
После этого модель для кода пишет краткое резюме изменений. Ей не нужно описывать каждый файл. Достаточно сказать, что изменилось, что прошло и на что человеку стоит обратить внимание.
Наконец, ревьюер проверяет дифф, пробует экспорт в приложении и сравнивает результат с исходным требованием. Если файл открывается корректно и фильтры работают, он утверждает. Если разделитель или поведение для пустого набора не соответствует, отправляет назад на один шаг, а не на весь цикл.
Это важно. Команда не гонит задачу обратно к автору текста, если код в порядке и только настройка пакета оказалась неверной. Исправляют слабое место и движутся дальше.
Это близко к тому, как работают опытные технические команды. Олег использует ту же идею в AI-усиленной разработке: давайте каждой модели узкую задачу, держите передачи чёткими и поручайте человеку одобрять те части, которые могут сломать продукт для пользователей.
Ошибки, которые создают лишние затраты и плохой результат
Большинство сломанных AI-воркфлоу терпят неудачу по простым, предсказуемым причинам. Команды тратят слишком много на неправильный шаг, доверяют черновику слишком рано или прячут простые правила там, где модель не может их применить.
Одна типичная ошибка — просить модель угадывать свежие факты. Если задача зависит от текущих документов, состояния репозитория, истории тикетов или живого поиска, сначала получите этот контекст. Иначе модель заполнит пробелы уверенным вымыслом. Слабый шаг поиска часто лучше отполированного неверного ответа.
Ещё одна вредная привычка — кидать весь репозиторий в каждый промпт. Это кажется безопасным, но обычно ухудшает точность. Большинству задач нужна узкая вырезка: файлы, которые изменяются, один соседний тест и, может быть, один похожий паттерн в кодовой базе. Лишний контекст добавляет шум, тратит токены и облегчает модели взять не ту деталь.
Команды также теряют время, пропуская тесты, потому что черновик выглядит правильным. Код может читаться чисто и при этом ломать миграцию, пропускать крайний случай или менять поведение старого эндпоинта. Если воркфлоу пишет код, он должен запускать проверки: тайпчек, юнит-тесты, линт или дымовой тест.
Дизайн промптов вызывает тихие провалы. Некоторые команды прячут все правила внутри одного гигантского системного промпта: не трогать биллинг, спрашивать перед редактированием авторизации, не менять сгенерированные файлы. Длинные промпты превращаются в обои. Размещайте жёсткие правила ближе к действию. Пусть маршрутизатор решает доступ к инструментам, дайте шагу программирования локальные ограничения и сделайте ревью-шаг блокирующим для небезопасного вывода.
Стоимость растёт, когда каждая задача идёт к самой дорогой модели. Часто это не решение, а настройка по умолчанию. Оставьте премиальные модели для рискованных изменений кода, сложного рассуждения или финального ревью. Дешёвые модели справятся с суммарными задачами, очисткой поиска или выборкой файлов.
Более безопасная настройка сознательно «скучная». Получите факты перед запросом ответа. Передавайте только тот контекст, который нужен шагу. Запускайте проверки после каждого изменения кода. Держите правила короткими и прикрепляйте их к шагу, который их использует. Сохраняйте премиальные модели для рискованных задач.
Такой набор обычно даёт лучший результат за меньшие деньги, и когда что-то идёт не так, команда видит где и почему.
Быстрая проверка перед запуском
Пять коротких вопросов ловят большинство проблем воркфлоу до того, как они превратятся в потраченные токены, плохой результат или сломанный деплой.
Спросите, какой шаг сейчас нуждается в свежей информации. Версии пакетов, API-документы, данные продукта и статус инцидентов меняются быстро. Направляйте такие шаги через поиск или инструменты извлечения, а не полагайтесь на память модели.
Спросите, какой шаг может навредить продакшену. Изменения схемы, инфраструктуры, логики авторизации, правил биллинга и автоматики для клиентов требуют человеческой проверки до выполнения.
Спросите, включает ли каждая передача только тот контекст, который нужен следующему шагу. Длинная история чата, полные логи и лишние файлы повышают стоимость и часто ухудшают результат. Короткое бриф-резюме, нужные файлы и одна ясная цель работают лучше.
Спросите, есть ли у каждого шага одна ясная проверка. Поисковый шаг может требовать проверки релевантности. Шаг кода — тестов. Шаг написания — фактической проверки. Если у шага нет проверки, плохой результат может пройти дальше незамеченным.
Спросите, кто проверяет рисковые части. Решите это до старта воркфлоу. Если некому смотреть финальные изменения в базах данных или скриптах деплоя, процесс пойдёт по накатанной.
Небольшой пример делает это очевидным. Если один поток ищет текущие правила API, пишет код и готовит релизные заметки, каждому элементу нужен свой контроль: поиск — свежие данные, код — тесты, заметки — быстрая фактпроверка.
Команды часто пропускают это, потому что поток выглядит простым на бумаге. Затем одна модель получает слишком много контекста, делает одно неверное предположение, и ошибка проходит через всю цепочку. Двухминутная проверка в начале дешевле, чем откат, тикет в саппорт или растерянный клиент.
Что делать дальше
Выберите один воркфлоу, который команда уже выполняет каждую неделю. Хорошие кандидаты — повторяющиеся задачи: превращение заметки продукта в тикет, ревью пулл-реквеста или сбор источников перед черновиком. Пропишите весь поток на бумаге сначала. Если пропустить этот шаг, вы, скорее всего, будете править промпты для процесса, который изначально был неправильным.
Запишите каждый шаг простым языком. Отметьте, кто делает его сейчас, какой вход нужен, что может пойти не так и насколько дорогой будет ошибка. Это даёт прочную базу, потому что вы сможете отделить низкорисковое написание от рискованных изменений кода или фактических проверок.
Достаточен простой первый проход. Пометьте шаги, которые требуют поиска, кода или длинного контекста. Обведите те, где ошибка создаёт переработку или риск для клиента. Назначьте человека, который будет проверять рисковые шаги. Затем отслеживайте потраченное время, повторы и стоимость модели после каждого прогона.
Через пару прогонов сфокусируйтесь на трёх числах: переработка, задержка и стоимость. Переработка показывает, неправильна ли маршрутизация. Задержка — замедляют ли передачи команду. Стоимость — оправдывает ли дорогая модель своё место или просто сжигает бюджет.
Исправляйте маршрутизацию прежде, чем полировать промпты. Слабая передача создаёт больше проблем, чем неуклюжая формулировка. Если шаг поиска пропускает источники, или шаг программирования постоянно просит допконтекст, перенесите задачу на более подходящую модель или измените то, что передаёте между шагами.
Держите тест маленьким. Прогоните воркфлоу на 5–10 реальных задачах и сравните результат с обычным процессом. Простые правила ревью работают лучше. Человек должен утверждать продакшен-код, публичные заявления и всё, что увидит клиент.
Если нужен внешний обзор, Oleg Sotnikov на oleg.is может помочь как fractional CTO. Он работает со стартапами и небольшими командами по программной разработке, инфраструктуре и дизайну воркфлоу AI-усиления; такой обзор полезен, когда у вас уже есть одна задокументированная процедура и неделя–две результатов.
Часто задаваемые вопросы
Почему нельзя доверить весь воркфлоу одной модели?
Потому что одна модель склонна повторять одни и те же «слепые зоны» на каждом шаге. Она может написать отшлифованный текст, упустить свежий факт, а затем внести изменение в код на основании этого неверного предположения. Разделение задач позволяет подобрать инструмент для каждой работы и снизить такие ошибки.
Как определить, какие задачи требуют большего контроля?
Начните с оценки стоимости ошибки. Черновики и сводки — низкий риск. Текст, видимый пользователям, и продакшен-код — средний. Биллинг, безопасность, юриспруденция и работа с персональными данными — высокий. Это даёт простое правило, где усиливать проверки и вводить обязательную человеческую валидацию.
Когда нужна модель с большим контекстом?
Спросите, от чего зависит задача. Если нужно длинное «памятование» по продукту или одновременно много файлов — берите модель с большим окном контекста. Если нужны текущие документы или изменение пакетов — сначала получите эти факты через поиск, а затем передавайте короткое резюме модели.
Стоит ли запускать поиск перед тем, как спрашивать модель?
Когда ответ может измениться со временем. Текущая документация, недавние релизы, состояние репозитория, история тикетов и инциденты живут в поиске. Пусть сначала ищут, а затем следующий шаг работает с коротким проверенным резюме.
Какую модель лучше использовать для изменений в коде?
Для правок кода, патчей, тестов и разбора стектрейсов используйте модель для работы с кодом. Общие текстовые модели хорошо объясняют проблему, но часто пропускают крайние случаи или вносят слишком большие изменения. Держите шаг программирования узким и запускайте проверки.
Сколько контекста нужно передавать между шагами?
Передавайте как можно меньше, но достаточно: тикет, файлы в зоне изменений, одно–два важных правила и факты, которые нужны следующему шагу. Когда в промпте оказывается весь чат, логи и черновики, растут расходы и падает точность.
Где должна происходить проверка человеком?
Останавливайтесь там, где ошибка дорого обходится. Перед изменениями в продакшн-коде, отправкой клиентского текста или превращением неуверенных результатов поиска в факты должен быть человек. На практике ревьюер проверяет дифф, тесты и то, что задача осталась в рамках.
Полезны ли повторы (retries) или они только сжигают токены?
Помогают, если вы знаете, что именно сломалось. Если шаг по программированию забывает файл тестов, перезапустите его с сообщением об ошибке и шаблоном файлов. Если поиск вернул мало — перепишите запрос и попробуйте ещё раз. Не заводите циклы повсеместно, иначе вы спрячете плохую маршрутизацию и потратите деньги.
Что измерять в многомодельном воркфлоу?
Измеряйте переработку, время выполнения и стоимость для каждого шага. Переработка показывает, где маршрут неверен. Время — где передачи тормозят процесс. Стоимость — оправдывает ли модель свою цену или просто тратит бюджет.
Какая первая задача хороша для тестирования?
Выберите повторяющуюся задачу, которую команда хорошо знает: превращение заметки в тикет, проверка источников перед черновиком или небольшое изменение с тестами. Пропишите шаги, добавьте одну проверку на шаг и сравните 5–10 прогонов с привычным процессом.


