Многоагентные системы против одного агента для задач разработки ПО
Многоагентные системы против одного агента: простой взгляд на трудозатраты настройки, точки отказа, время отладки и пригодность для повседневной разработки ПО.
Содержание
Почему этот выбор быстро усложняется
Команды задают этот вопрос по простой причине: они хотят больше результатов от AI, не удваивая время проверки и не перекладывая работу на старших инженеров.
Звучит просто, пока система не начинает принимать реальные решения. Тогда выбор между одним сильным агентом и несколькими перестаёт быть вкусовщиной и превращается в операционную проблему.
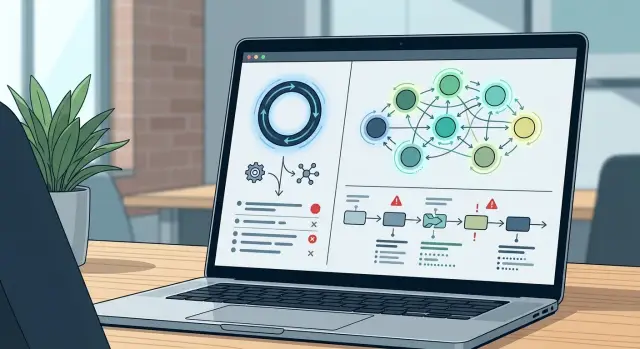
Одна петля агента проще для отслеживания. Запускается одна цепочка промптов, один шаблон памяти ведёт задачу вперёд, и один лог показывает, что произошло. Когда что-то ломается, обычно можно проиграть прогон, поправить промпт или вызов инструмента и быстро протестировать снова.
Многоагентная схема меняет форму работы. Один агент планирует, другой пишет код, третий ревьюит, и, возможно, ещё один работает с инструментами или данными. Каждая передача добавляет ещё один промпт, окно контекста и ещё одно место, где задача может отклониться.
Именно из-за этого дрейфа команды теряют время. Код может выглядеть нормально, а агент-рецензент отвергнуть его по неправильной причине. Планировщик может передать расплывчатые указания. Инструментальный агент может вызвать не тот сервис. Вы уже не исправляете одну ошибку — вы прослеживаете цепочку мелких недоразумений.
По этой причине стоимость отладки растёт быстрее, чем многие ожидают. Больше агентов даёт не только больше вывода: больше логов, больше повторных попыток, больше пограничных случаев и больше неясности, где началась ошибка.
У одной петли есть пределы. Она может застрять на больших задачах, потерять фокус или повторять одно и то же неверное решение. Тем не менее простые системы часто дешевле доверять. Работа Oleg с бережными AI-first операциями указывает в ту же сторону. Меньше движущихся частей обычно значит быстрее исправления, яснее ответственность и меньше потерь времени при сбое.
Что реально делает одна сильная петля агента
Для многих задач разработки ПО один агент достаточен при условии, что вокруг него построен прочный цикл. Агент получает цель, строит план, выполняет работу, проверяет результат и пробует снова при ошибке.
Эта петля важнее, чем многие думают. Хороший одиночный агент не просто один раз пишет код и останавливается. Он может прочесть репозиторий, предложить небольшой план, править файлы, запускать тесты или проверки lint, анализировать вывод об ошибках и сделать ещё один проход, пока контекст остаётся доступным.
С одним промптом, задающим правила, и одной цепочкой памяти, несущей прогон вперёд, работа обычно остаётся связной. Агенту не нужно передавать контекст трем другим агентам или ждать отдельных мнений перед исправлением упавшего теста.
Простой фикс бага показывает это хорошо. Допустим, команда хочет добавить валидацию ввода в API-эндпоинт. Один агент может просмотреть хендлер, обновить логику, добавить тест, запустить прогон, заметить падающий краевой случай, исправить его и отчитаться, что изменено. Для рутинной работы это часто быстрее, чем дробить задачу между специализированными агентами.
Главный выигрыш — прозрачность. Логи, вызовы инструментов, правки файлов и повторные попытки остаются в одном месте. Когда что-то идёт не так, человек может прочитать весь прогон сверху донизу и увидеть, где агент сделал неверное предположение.
Это практично снижает стоимость отладки. Вы тратите меньше времени на состыковку следов от разных исполнителей и больше — на оценку одной цепочки решений. Команды, которым важна надёжность AI-агентов, часто начинают именно с этого, потому что ошибки проще инспектировать и исправлять.
Часто задаваемые вопросы
Когда мне выбрать одного агента вместо многих?
Начните с одного агента, когда задача имеет одну цель, один кодовой репозиторий и ясную точку завершения. Исправление багов, небольшие правки функций и рутинная чистка обычно соответствуют этому формату.
Добавляйте больше агентов только тогда, когда работа действительно делится на отдельные части с чёткими границами. Если вы не можете объяснить разделение в одно предложение, держите одну петлю.
Какие задачи лучше подходят для одного агента?
Одна петля хорошо подходит для исправления бага, добавления простого правила валидации, обновления маршрута, удаления мёртвого кода или подготовки заметок релиза. Один агент может прочитать репозиторий, внести изменение, запустить проверки и исправить первую ошибку, не теряя контекст.
Это делает проверку проще: вы видите одну цепочку решений от начала до конца.
Когда несколько агентов действительно помогают?
Много агентов полезны, когда задача естественно делится. Один агент может собирать факты из логов или документации, а другой — проверять эти находки; или один пишет тесты, а другой запускает их и отмечает слабые места.
Они менее полезны, когда нужно одно грязное изменение, затрагивающее UI, API и логику базы данных одновременно — в таких случаях передачи часто создают больше работы, чем экономят.
Почему многoагентные системы сложнее отлаживать?
Каждая передача добавляет ещё один промпт, ещё одно окно контекста и ещё один шанс потерять детали. Когда что-то ломается, нужно отследить, что получил каждый агент, что он изменил и где появилась неверная предпосылка.
Такой поиск занимает больше времени, чем чтение единого неудачного прогона. Больше вывода не равняется большей ясности.
Сколько агентов должна использовать небольшая команда в начале?
Для небольшой команды попробуйте сначала одну сильную петлю. Запустите её на одной повторяющейся задаче в течение 2–4 недель и держите промпт, инструменты и правила проверки стабильными.
Добавляйте второго агента только если та же самая узкая точка повторяется снова и снова. Не добавляйте роли просто потому, что на диаграмме это выглядит аккуратно.
Какие guardrails важнее всего?
Ограничьте число повторных попыток, сузьте права записи и требуйте человеческого одобрения для рискованных правок: auth, billing, изменения схем или деплои. Эти правила предотвращают превращение мелких ошибок в большие изменения.
Также сохраняйте вывод инструментов и краткие заметки о прогоне — чистые записи помогают ревью быстро заметить дрейф.
Стоит ли позволять разным агентам редактировать один и тот же код?
Нет. Если два агента могут менять одну и ту же логику, вы приглашаете асимметричные предпосылки и сложные откаты.
Делите работу по модулю, владельцу файла или границе API. Дайте каждому агенту узкую область ответственности, чтобы было ясно, кто и зачем что изменил.
Как протестировать воркфлоу агента, не тратя время зря?
Выберите одно скучное задание, которое повторяется каждую неделю. Запустите его с одним агентом, затем отслеживайте время на проверку, частоту ошибок и как часто требуется повторный запуск.
Если коллега не может просмотреть неудачный прогон за пять минут, упростите настройку перед расширением.
Что логировать в каждом прогоне?
Логируйте версию промпта, модель, вызовы инструментов, повторные попытки, затронутые файлы и финальный результат для каждого прогона. Добавьте ID прогона, чтобы любой в команде мог связать один плохой ответ с одной конкретной попыткой.
Без этой трассировки остаётся только гадание, а гадание быстро жрёт время на ревью.
Когда человек должен вмешаться?
Вмешивайтесь, когда агент затрагивает продакшн-настройки, меняет логику авторизации или биллинга, удаляет код, совершает слишком много неудачных повторных попыток или решил не ту задачу. Человеческая проверка нужна также для широких правок, затрагивающих несколько файлов за один проход.
Раннее ревью обходится дешевле, чем исправление дрейфа после того, как он прошёл в тесты, документацию и продакшн.


