Миграция с GitHub Actions на GitLab CI без простоев
Планируйте поэтапную миграцию с GitHub Actions на GitLab CI: переносите workflow и секреты безопасно, тестируйте раннеры и держите понятный план отката.
Содержание
Почему миграции ломают доставку
Перемещение CI чаще всего ломается в одном привычном месте: job деплоя. Если этот job перестаёт читать нужную ветку, теряет production-секрет, или попадает на раннер без доступа к Docker, релизы останавливаются, хотя приложение в порядке. Команды часто замечают проблему поздно, когда хотфикс уже в main, а всё ещё нельзя выпустить.
GitHub Actions и GitLab CI на первый взгляд похожи. Оба используют YAML. Оба запускают jobs, передают артефакты и реагируют на push и теги. Эта внешняя схожесть вводит команды в заблуждение: они копируют workflow-файлы и ждут тот же результат. Синтаксис — только часть работы. Сложнее — всё вокруг него.
Скопированный pipeline может упасть из‑за иного event‑модела. Job, который запускался на push в GitHub, может требовать других rules в GitLab, чтобы правильно обрабатывать merge request, теги или деплой по ветке по умолчанию. Артефакты могут перемещаться иначе. Переменные могут разрешаться в другом порядке. Мелочи вроде matrix jobs, ручных approvals или зависимостей job'ов тихо меняют путь релиза.
Обычные точки отказа просты и их легко пропустить. Триггеры срабатывают слишком часто или не срабатывают вовсе. Секреты есть, но job не может их прочитать в нужном окружении. Раннеры не имеют инструментов, сетевого доступа или кешей зависимостей. Шаги отката не переносятся, потому что команда скопировала только «счастливый» путь.
Представьте команду сервиса, которая деплоит на каждый тег. В GitHub Actions workflow собирает образ, логинится в регистр и пушит в прод после одного approval. После быстрого перехода в GitLab сборка по‑прежнему проходит, но deploy job никогда не запускается: правило для тега не совпадает с новой конфигурацией pipeline. На бумаге всё в порядке. На практике — день релиза потерян.
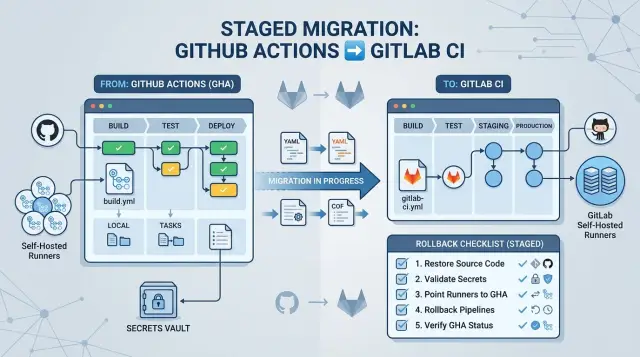
Именно поэтому миграцию не стоит начинать с полного переключения. Цель — не переписать все workflow одновременно. Цель — сохранить доставку «скучной», двигая по частям: сначала низкорискованные pipeline, затем секреты, затем раннеры, и лишь потом production‑деплои с чётким планом отката. Если одна стадия падает, старый путь всё ещё должен доставлять код.
Что документировать в первую очередь
Команды обычно попадают в беду, когда сначала копируют YAML, а потом делают учёт. Безопаснее и надёжнее наоборот: опишите, что сейчас запускается, зачем и к чему прикасается каждый job.
Соберите все workflow‑файлы в один документ или таблицу. Для каждого workflow запишите триггер простым языком: push в main, pull request, создание тега, ручной запуск, расписание или завершение другого workflow. Если что‑то запускается только на релизном теге или hotfix‑ветке — отметьте это. Эти мелкие правила вызывают многие первые пропущенные релизы.
Затем пронумеруйте job'ы по назначению. Держите маркировку простой: build, test, release, deploy, support. Это покажет скрытые связи. Job с именем ci может также публиковать образ. Job release может тихо обновлять changelog, пушить тег и триггерить прод.
Запишите все секреты, переменные, артефакты, кеши и общие actions, которые использует каждый workflow. Укажите, кто владеет секретом, где он хранится и сможет ли job работать без него. Общие actions требуют отдельного внимания: команды часто полагаются на кастомные actions или Marketplace actions, которые делают гораздо больше, чем их имя подразумевает.
Отметьте всё, что касается продакшена, биллинга или данных клиентов. Рассматривайте эти job'ы как отдельную группу риска. Если pipeline может вращать креды, списывать деньги с клиента, запускать миграцию БД или деплоить код, видимый клиентам, ему требуется более тщательный обзор перед перестройкой.
Полезно фиксировать времена выполнения и паттерны падений. Запишите обычную длительность, самые медленные шаги и job'ы, которые иногда падают по причинам, которым никто особо не доверяет. Если билд и тесты обычно занимают 14 минут, а deploy падает на пропавшем кеше два раза в месяц, сохраните эту информацию — она пригодится при сравнении старых и новых pipeline.
Как выбирать первые pipeline для переноса
Начните с job'ов, которые могут падать, не причинив вреда клиентам, продажам или поддержке. Самый безопасный первый шаг — это обычно операции только для чтения: lint, unit tests и preview builds.
Эти pipeline много скажут о настройке раннера, образах, кешах и переменных окружения, но не будут пушить код в прод. Если тестовый job будет вести себя странно один день — команда раздражена. Если ведёт себя странно deploy — команда пропускает окно релиза.
Выберите один репозиторий или сервис с ограниченным влиянием. Внутренний инструмент, low‑traffic API или побочный сервис лучше, чем основной клиентский апликейшн. Нужно что‑то достаточно реальное, чтобы показать пробелы, но достаточно маленькое, чтобы быстро восстановиться.
Лучшие кандидаты: простые pipelines, которые запускаются на каждый pull/merge request, не публикуют пакеты и не триггерят релизы, завершаются за минуты и которыми одна команда владеет от конца до конца.
Держите production‑деплои в старой системе во время первой волны. Это даёт чёткую границу между тестированием поведения CI и доставкой клиентского кода. Также это помогает избежать типичной ошибки: менять логику workflow и механику релиза одновременно.
Отложите расписанные job'ы и релизы по тегам на потом. Ночные синхронизации, скрипты очистки, тегирование версий, генерация changelog и публикация пакетов часто скрывают особые правила, которые всплывают только при их поломке.
Практический порядок: сначала переносите lint и unit tests сервиса, затем добавляйте preview build, затем копируйте логику staging deploy и только после этого беритесь за production. В этом подходе «скучно» — потому что скучно работает.
Сопоставьте job'ы, триггеры и артефакты
Думайте job за job'ом, а не файл за файлом. Для каждого job задайте четыре простых вопроса: что его запускает, что ему нужно, что он производит и что должно произойти перед релизом. Это превращает хаотичную миграцию в набор небольших решений по сопоставлению.
События GitHub редко мапятся один в один. Push остаётся простым, но pull requests превращаются в merge request pipeline, фильтры по веткам требуют внимательного просмотра. Правила для тегов — частая ловушка. Job, который раньше запускался только на version‑тэге, вдруг может запуститься на каждой ветке, если логику скопировать слишком вольно.
Базовый список соответствий помогает:
push-> правила ветокpull_request-> правила merge requestworkflow_dispatch-> ручной job или ручной pipelineschedule-> планируемый pipeline- release tags -> правила для тегов с жёстким шаблоном
Держите имена стадий простыми. "build", "test", "package" и "deploy" лучше причудливых меток: любой может быстро просканировать pipeline и понять, где сработал сбой. Если один GitHub workflow смешивает слишком много задач, разделите его сейчас. Один файл всё ещё может содержать несколько job'ов, но у каждого job должна быть одна ясная цель.
Marketplace actions требуют особого внимания. Некоторые мапятся на встроенные возможности GitLab вроде кешей, артефактов, сборки контейнеров или встроенных переменных. Другие — просто обёртки над shell‑командами. В таких случаях обычные скрипты часто лучше: их легче читать, отлаживать и они реже удивляют при переносе.
Артефактам нужен явный план. Решите, какой job производит результат сборки, как долго GitLab будет его хранить и какие последующие job'ы будут его скачивать. Логи, отчёты тестов, пакеты сборки и деплой‑бандлы не нужно хранить одинаково: отчёт тестов может жить несколько дней, release‑бандл — дольше, чтобы был возможен откат.
Если ваш сервис билдится на каждой ветке, тесты запускаются на merge request, а деплой — только по тегам, опишите это тремя отдельными правилами. Команды часто сводят это в один job и потом тратят дни на поиск странных релизов.
Перенос секретов и переменных безопасно
Секреты — место, где многие команды ломают доставку. Job может выглядеть идеально и всё равно упасть, потому что один токен назван неправильно, имеет неправильную область видимости или нет доступа в целевом окружении.
Начните с полного инвентаря. Не переносите секреты «по памяти». Экспортируйте простую таблицу и сгруппируйте каждое значение по месту использования, по окружению и по тому, делится ли оно между репозиториями.
Большинство команд получает три группы: значения только для репозитория (например, тестовые API‑токены или креды для публикации пакетов), значения по окружению (staging, production DB URLs) и общие значения (Slack‑вебхуки, креды реестра контейнеров или роли облака).
Эта группировка подскажет, что хранить на уровне проекта, что вынести в более высокий общий scope и что держать отдельно, чтобы команда не получила лишний доступ.
Коллизии имён — обычное дело. Одно и то же имя может существовать в двух репо, но ссылаться на разные аккаунты, или расплывчатое API_KEY может означать одно в staging и другое в prod. Переименовывайте до импорта, а не после неудачного деплоя. Простая схема префиксов, например STAGING_, PROD_ или имя сервиса, обычно достаточна.
Production‑значения требуют более строгих правил. Маскируйте их, чтобы логи не печатали их случайно. Защитите их, чтобы только защищённые ветки или теги могли их использовать. Если в процессе деплоя есть ручные approvals, связывайте эти approvals с доступом к прод‑значениям. Утёкший тестовый токен — неприятность. Утёкший production‑токен может остановить релизы на дни.
Сделайте dry run перед реальным cutover. Создайте ветку, запускающую pipeline без деплоя, и проверьте, что каждый job может прочитать, что ему нужно. Проверьте мелочи: имена переменных, файловые секреты, многострочные сертификаты, JSON‑блоки и shell‑экранирование.
Одна команда переместила токен деплоя, пароль регистра и два файла окружения. Pipeline прошёл на первой прогоне ветки, но деплой всё равно упал — потому что production‑переменная была защищена, а ветка — нет. Именно такие ошибки вы хотите поймать в dry run, не в окне релиза.
Держите старое хранилище секретов живым до завершения cutover и нескольких нормальных релизов новых pipeline. Удаляйте старые значения только когда необходимость в откате отпала. Короткий период пересечения безопаснее, чем поспешная зачистка.
Подготовьте раннеры, образы и кеши
Раннеры часто причиняют больше проблем, чем сам pipeline. Если раннер не совпадает с прошлой средой сборки, job'ы падают по мелочам: отсутствует пакет, нет Docker‑сокета, неверная версия Node или Python, недостаточно диска.
Решите, какие pipeline останутся на shared runners, а какие требуют project runners. Shared runners хороши для простых lint, test и build задач в разных репозиториях. Project runners безопаснее для job'ов со специнструментами, приватным сетевым доступом, большими кешами или жёсткими правилами безопасности.
Если вы хостите GitLab сами, project runners часто проще настроить сначала. Они дают больший контроль и упрощают отладку, когда одна команда сталкивается с странной проблемой сборки.
Сопоставьте каждый образ раннера с теми инструментами, которые реально используют ваши job'ы. Не догадывайтесь по имени workflow. Читайте текущие job'ы и выпишите версии рантаймов языков, менеджеров пакетов, Docker, облачных CLI и любых кастомных скриптов.
Малые рассогласования отнимают часы. Если билд в GitHub использовал Ubuntu с Java 17, Node 20 и доступом к Docker, дайте GitLab CI ту же базовую среду, прежде чем сравнивать скорость или надёжность.
Что тестировать перед rollout
Перед тем как команды начнут зависеть от нового раннера, выполните несколько прямых проверок:
- Могут ли job'ы тянуть приватные зависимости и контейнерные образы?
- Могут ли они достучаться до внутренних сервисов, регистров пакетов и тестовых БД?
- Могут ли они собирать Docker‑образы, если это нужно для релиза?
- Достаточно ли CPU, памяти и диска для пиковых задач?
- Могут ли логи, артефакты и отчёты тестов загружаться без таймаутов?
Кеши тоже требуют подготовки. Если сравнивать времена выполнения при холодном кеше, GitLab будет выглядеть медленнее, чем на деле. Заполните зависимости в кеше заранее, прогоните те же job'ы ещё раз и сравните. Используйте те же lockfiles и пути кеша, которым команда доверяет.
Следите за использованием диска из‑за Docker‑слоёв, артефактов и кешей пакетов. Многие сбои миграции выглядят случайными, пока вы не поймёте, что раннер просто закончился по диску посреди билда.
Один запасной раннер помогает больше, чем команды ожидают. Держите его в резерве, настроенным и готовым. Если раннер сломается во время cutover, вы сможете быстро перезапустить job'ы, перевести проект или откатиться, не блокируя всю команду.
Запускайте обе системы параллельно
Безопасный переход редко подразумевает один крупный день переключения. Безопаснее запускать обе системы на одном и том же коммите некоторое время и сравнивать результаты. Каждый push или merge должен запускать оба pipeline, чтобы обе системы видели один и тот же код, тесты и входные данные сборки.
Сначала оставьте GitHub Actions главным для релизов. Пусть GitLab CI выступает теневым pipeline: собирает, тестирует и публикует отчёты, но не деплоит. Это даст реальные данные без риска для трафика клиентов.
Сравнивайте выходы
Зелёного бейджа недостаточно. Сравните, что каждая система реально произвела и сколько времени это заняло.
Проверьте количество тестов и имена упавших тестов. Сравните имена артефактов, размеры и checksums, когда это возможно. Убедитесь, что теги образов и метаданные сборки совпадают. Отслеживайте общее время выполнения и самые медленные job'ы. Обращайте внимание на флаки, которые в одной системе проходят, а в другой падают.
Малые рассогласования важны. Если GitLab пропускает два интеграционных теста или создаёт чуть другой артефакт, это может стать причиной плохого релиза позже. Закройте такие разрывы до переноса любого деплой‑шага.
Когда GitLab даёт два‑три чистых прогона подряд, перенесите один деплой‑таргет, а не все сразу. Начните с низкорискованного таргета: dev‑окружение, внутренний инструмент или небольшой сервис с быстрым путём отката. Держите прод на GitHub, пока первый таргет стабильно не поведёт себя под нормальными изменениями.
После этого передавайте один путь релиза за раз. GitLab может деплоить staging неделю, пока GitHub всё ещё владеет production. Затем GitLab может взять один production‑таргет, а остальные останутся. Звучит медленно, но обычно экономит время: команда перестаёт гоняться за избегаемыми ошибками.
Не передавайте ownership релиза, пока откат не работает в GitLab. Докажите, что команда может быстро переиспользовать предыдущий образ, восстановить последний годный артефакт или зафиксировать более ранний тег за несколько минут. Если вы не можете быстро отменить плохой деплой — вы ещё не готовы переключать финальную кнопку релиза.
Простой пример от одной команды сервиса
Небольшая SaaS‑команда не начинает с самого нагруженного production‑потока. Они начинают с pipeline staging для одного API‑сервиса. Это держит влияние низким и даёт время сравнить результаты до того, как включится реальный клиентский трафик.
Команда сначала копирует только шаги сборки и тестов. Они используют тот же Docker‑образ, ту же команду тестов и те же имена артефактов. Если старый pipeline публиковал чек‑сумму пакета и отчёт тестов, новый тоже должен выпускать те же outputs, а не просто сообщать «pass».
Первая неделя простая. В первые два дня они зеркально запускают build и test job'ы в GitLab CI на каждом коммите. На 3–5‑й день они сравнивают время, количество тестов, digests образов и размеры артефактов между системами. В течение всей недели GitHub продолжает обрабатывать staging‑деплои и остаётся источником истины. После семи стабильных дней они продвигают один staging‑релиз из GitLab и внимательно за ним наблюдают.
Этот релиз — не полный cutover, а контролируемая проверка. Команда подтверждает, что контейнерный образ совпадает, шаг миграции выполняется в том же порядке, и сервис стартует с теми же переменными окружения. Если что‑то не так — они возвращают триггер деплоя обратно в GitHub и продолжают доставлять.
Этот запас отката важен. В их случае GitLab‑раннер оказался без одной системной утилиты, нужной тест‑суите. Тесты падают не из‑за кода, а из‑за отсутствия пакета в образе раннера. Так как деплои всё ещё шли из GitHub, команда исправила раннер, перезапустила pipeline и продолжила работу за несколько минут.
Такой staged rollout по замыслу скучен. И в этом вся суть. Когда build, test и deploy переходят в разное время, одна ошибка не превращается в сломанный релиз.
Ошибки, которые ломают релизы
Большинство сломанных релизов не из‑за синтаксиса YAML. Они из‑за поспешных допущений.
Первая плохая идея — менять слишком много сразу. Если одна команда переносит все репозитории в одну неделю, у никого нет времени заметить тихие сбои. Ночная синхронизация перестаёт работать, approval исчезает или ветка хотфикса больше не следует старому правилу. Каждое упущение кажется маленьким. Вместе они блокируют доставку.
Команды также спотыкаются, копируя видимый pipeline и забывая о скрытом поведении вокруг него. Release job'ы часто зависят от вещей вне YAML: расписанные задачи, ручные approvals перед продом, защиты веток и правила именования, триггеры тегов для версионированных релизов и удержание артефактов, на которые надеются последующие job'ы.
Ещё одна распространённая ошибка — ожидать идеального соответствия каждой GitHub Action. Некоторые actions мапятся на GitLab CI чисто. Другие — нет. Поведение кешей, matrix‑сборки, reusable workflows и сторонние actions часто требуют иной конструкции. Если команда пытается выдавить точную копию, чаще всего получится pipeline, который выглядит знакомо, но работает иначе.
Секреты создают собственный хаос. Люди часто переносят значения и считают задачу выполненной. Потом production‑деплои начинают падать, потому что переменная лежит в неправильной области, или staging‑токен попал в более широкий круг job'ов, чем нужно. Проверьте каждый секрет по‑отдельности: где он хранится, кто может им пользоваться и какая ветка/окружение может его читать.
Одна команда мигрировала сервис, увидела, что основной тестовый pipeline проходит, и удалила старый workflow в тот же день. Два дня спустя не запустилась расписанная очистка базы, потому что никто не воссоздал cron‑триггер. Поэтому заметки по откату важны. Держите старый workflow наготове, запишите шаги переключения обратно и удаляйте его только после нескольких нормальных релизных циклов без сюрпризов.
Чеклист go‑live и дальнейшие шаги
Перед переключением назначьте одного человека на каждый путь релиза. Если API, веб‑приложение и воркер деплоятся по‑разному, для каждого пути нужен ответственный, команда для релиза и шаг отката, соответствующий сервису. Напишите шаг отката простым языком. «Use the last good build» недостаточно, если изменились образы, пакеты или цели деплоя.
Держите финальный обзор в одной таблице: по строке на сервис. Трекьте имя GitLab pipeline, требуемые секреты и переменные, теги раннеров и целевые окружения в одном месте. Многие проблемы при go‑live происходят из мелких разрывов здесь: job ожидает тега, которого нет на раннере, или production‑переменная существует только в одной системе.
Короткий чеклист делает переключение скучным:
- У каждого пути релиза есть владелец и протестированный шаг отката.
- Секреты, раннеры, теги и окружения сверены в одной общей таблице.
- Команда провела хотя бы одну репетицию отката до go‑live.
- Изменения pipeline замораживаются во время финального переключения, кроме срочных фиксов.
- Все знают, какой GitLab pipeline заменяет каждый GitHub Actions workflow.
Проводите drill по откату сознательно, а не в последнюю минуту. Например, задеплойте новый образ в staging, затем откатитесь к предыдущему тегу, используя тот же GitLab job, который вы планируете применять в проде. Засеките время. Если откат занимает 4 минуты на репетиции и 25 минут в проде — это важный сигнал до реального cutover.
Заморозьте правки pipeline для финального шага. Новые job'ы, переименование переменных и смена образов создают шум, когда нужна тишина. Стабильность важнее одной дополнительной мелкой правки. Оставьте рефакторинг и зачистку на неделю после того, как трафик стабильно пойдёт через GitLab.
После go‑live внимательно наблюдайте первые релизы. Смотрите очереди, упавшие job'ы, промахи кеша и длительность деплоя. Если какая‑то команда ещё некоторое время нуждается в старой системе, держите это исключение явным и с ограничением по времени.
Если нужен второй взгляд перед переключением, Oleg Sotnikov at oleg.is помогает стартапам и небольшим командам с обзором GitLab‑настроек, раннеров, планов отката и общей миграцией к AI‑assisted engineering. Иногда внешний обзор ловит одну недостающую переменную или тег раннера до того, как это произойдёт в день релиза.


