Метрики разработки для основателей — не только story points
Метрики разработки для основателей нужно смотреть не по story points, а по lead time, change failure rate, нагрузке поддержки и надёжности — чтобы раньше замечать проблемы с доставкой.
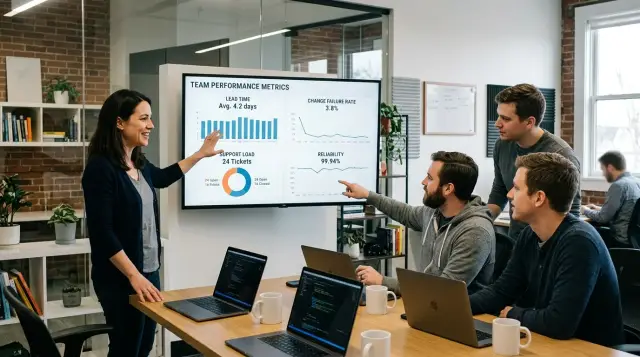
Содержание
Почему story points дают основателям смазанную картину
Story points помогают команде планировать спринт. Они не показывают основателю, становится ли продукт легче доставлять, сложнее поддерживать или более раздражающим для клиентов.
Первая проблема проста: очки — не настоящая единица измерения. Одна команда помечает задачу как 3 points, другая называет ту же работу 8. Даже внутри одной компании шкала меняется, когда люди приходят, уходят и меняют подход к оценкам.
Из‑за этого тренды ненадёжны. Основатель может увидеть рост velocity и решить, что доставка ускорилась. Иногда команда просто стала мягче оценивать. И обратное тоже случается: аккуратная команда может выглядеть медленнее по бумагам, хотя на деле поставляет более качественную работу.
Points также скрывают то, что обычно больше всего волнует основателей. Они не показывают, как долго работа ждёт, прежде чем кто‑то начнёт её. Не показывают, ломают ли релизы что‑то. Не показывают, сколько инженерного времени уходит на тикеты поддержки, срочные исправления и повторные жалобы клиентов.
Небольшая продуктовая команда может закрыть 40 points за спринт и при этом раздражать пользователей, если баги попадают в продакшн, а поддержка постоянно отрывает разработчиков от запланированной работы. Другая команда может завершать меньше points, но выпускать чистые изменения каждую неделю без драм. Для бизнеса вторая команда обычно в лучшем положении.
Короткая карточка показателей работает лучше, чем огромный дашборд. Измеряйте, сколько времени занимает доставка изменений до пользователей, как часто релизы ломаются, сколько времени уходит на поддержку и насколько стабильно ведёт себя сервис день ото дня. Эти числа проще сравнивать с течением времени, их сложнее «подправить», и они гораздо ближе к реальным бизнес‑результатам.
Они также задают лучшие вопросы. Если lead time растёт — где работа застревает? Если нагрузка поддержки скачет — что постоянно ломается? Это даёт основателям то, чего story points редко дают: ясный обзор скорости, риска и влияния на клиентов.
Четыре числа, которые стоит отслеживать
Основателям не нужна стена графиков. Четыре числа рассказывают большую часть истории: как быстро движется работа, как часто изменения идут не так, куда утекает инженерное время и можно ли доверять продукту.
Lead time — это показатель скорости. Он показывает, сколько времени проходит от начала работы до продакшна. Если он постоянно растёт, значит что‑то замедляет команду, даже если количество тикетов выглядит стабильно.
Failure rate — это показатель риска. Он показывает, как часто релизы порождают баги, откаты, хотфиксы или инциденты. Команда, которая быстро шлёт изменения, но часто их ломает, двигается с скрытой ценой.
Support load — это показатель фокуса. Он показывает, сколько инженерного времени уходит на клиентские проблемы, триаж багов, срочные исправления и внутреннюю помощь. Когда нагрузка поддержки растёт, запланированная продуктовая работа обычно замедляется.
Reliability — это показатель доверия. Он показывает, что на самом деле ощущают клиенты: аптайм, минуты инцидентов, сломанные потоки и медленные пути, которые важны. Если надёжность падает, пользователи почувствуют это ещё до того, как это отразится в роадмапе.
Эти числа хорошо работают вместе, потому что каждое проверяет остальные. Команда может снизить lead time за счёт упрощений, но тогда вырастет failure rate. Можно защищать надёжность, релизя очень медленно — тогда lead time покажет эту компромиссию.
Не реагируйте слишком остро на одну тяжёлую неделю. Один сбой, большой запуск или один шумный клиент могут исказить картину. Тренды за последние 6–8 недель важнее.
Lead time показывает, как быстро работа действительно движется
Lead time отражает, сколько времени проходит от момента запроса на изменение до момента, когда пользователи действительно могут им пользоваться. Это делает его намного полезнее, чем story points. Клиенты не чувствуют оценки — они чувствуют, как долго ждут.
Важна не только общая величина, но и её разбиение. Работа обычно тратит время в четырёх местах: ожидание начала, разработка, ожидание ревью или QA и ожидание релиза. Когда основатели смотрят на lead time в таком разрезе, бутылочные горла легче заметить.
Команда может написать код за один день, а затем потерять ещё четыре дня на шаги ревью и релиза. Это не проблема скорости кодирования. Это проблема передачи.
Медленные ревью растягивают доставку сильнее, чем многие ожидают. Один старший инженер, который ревьюит всё, может стать узким местом. То же самое с ручным QA, неясным одобрением продукта или процессом релиза, который проходит раз в неделю.
Небольшой пример делает это очевидным. Команда исправляет клиентскую проблему за шесть часов. Затем работа ждёт два дня ревью, день тестирования и ещё один день до следующего релизного окна. Основатель видит «быстрое исправление», которое фактически дошло до клиента за четыре дня.
Отслеживайте медианный lead time, а не только среднее. Один большой проект может исказить среднее и сделать команду медленнее, чем она обычно есть. Медиана показывает, что испытывает обычная единица работы.
Если хотите ещё один уровень детализации — разбивайте lead time по типу работы. Исправления багов, небольшие продуктовые изменения и крупные проекты движутся с разной скоростью. Это даст более чистое представление о том, где именно утекает время.
Failure rate показывает, как часто изменения идут не так
Failure rate отвечает на простой вопрос: когда команда выпускает что‑то в продакшн, как часто это вызывает проблемы?
Считайте релиз неудачным, когда он создаёт баг, требует отката или вызывает хотфикс. Держите правило простым и применяйте его одинаково каждый раз. Если у всех разное понимание, число теряет смысл.
Не ограничивайтесь только крупными отказами. Маленькие проблемы в продакшне тоже важны, особенно если они отрывают инженеров от запланированной работы. Ошибка в оплате, затрагивающая пять клиентов, сломанный поток регистрации в одном браузере или поспешный патч после деплоя — всё это должно учитываться.
Практичное определение обычно включает релизы, которые привели к откату, хотфиксу в течение дня‑двух, жалобе клиента, или внутреннему алерту поддержки, связанному с этим релизом.
Один плохой день может сделать число драматичным, поэтому сравнивайте failure rate по неделям или месяцам. Это сглаживает шум. Если команда выпустила 20 изменений в этом месяце и 5 из них вызвали проблемы в продакшне, failure rate = 25%. Это гораздо удобнее для обсуждения, чем спор о том, был ли один бурный вторник исключением.
Когда failure rate растёт, причина часто скучная. Команда торопилась попасть в дедлайн. Тесты не покрыли рискованные пути. Кто‑то смерджил изменение без достаточного ревью. Основателям не нужно разбирать каждый баг, но стоит спросить, что изменилось в рабочем процессе.
Низкий failure rate не означает медленную команду. Здоровые команды часто достигают и скорости, и стабильности, отправляя более мелкие изменения, проверяя рискованные части и избегая хаотичных релизов.
Если вы отслеживаете одну метрику качества в месяц — пусть это будет она. Она показывает, реальный ли это прогресс скорости или просто переработка в красивой упаковке.
Support load показывает, куда уходит инженерное время
Работа поддержки часто прячется между запланированными задачами. Спринт может выглядеть полным продуктовой работой, но инженеры всё равно теряют часы на срочные исправления, ответы клиентам и триаж багов.
Считайте это время специально. Если не считать — story points будут делать команду медленнее, чем она есть на самом деле.
Вам не нужны идеальные данные. Примерного недельного итога вполне достаточно, чтобы понять, потребляет ли поддержка 5% времени команды или 35%. Эта разница меняет всё.
Небольшая команда может планировать 40 часов на фичи, а затем тратить 14 часов на помощь пользователям и погоню за багами. Продуктовая работа не замедлилась из‑за отсутствия дисциплины — её съела поддержка.
Полезно разбить эту работу на два бака. Первый — это пользовательские обращения: проблемы с входом, запутанные потоки, сломанные импорты, неотправленные письма. Второй — внутренние дефекты: проблемы, которые команда находит через тестирование, алерты или ревью до того, как пользователи сообщат.
Это разбиение показывает, где начинается боль. Большой объём пользовательских обращений часто указывает на слабую надёжность или запутанную часть продукта. Большой объём внутренних дефектов обычно указывает на качество релизов, слабые тесты или поспешные передачи.
Следите за повторениями, а не только за суммами. Десять тикетов по десяти разным вещам — это хаос. Десять тикетов про одну и ту же ошибку в чек-ауте указывают на одну корневую проблему, которую стоит исправить раз и навсегда.
Повторяющиеся типы тикетов обычно происходят из малого числа причин: ненадёжная интеграция, неясные шаги установки, плохие сообщения об ошибках или один хрупкий сервис. Отслеживайте топ повторяющихся проблем каждый месяц. Если одна проблема возвращается — перестаньте латать её по‑поводу и решите корень.
Reliability показывает, что чувствуют клиенты
Клиентов не волнует, сколько тикетов команда закрыла на этой неделе. Их волнует, что приложение загружается, что чек‑аут работает, письма приходят и данные на месте, когда они возвращаются.
Поэтому одного аптайма мало. Сервис может показывать высокий аптайм и при этом раздражать людей, если самые медленные страницы тянут время, регистрация ломается на мобильных, или фоновые задачи молча падают и не отправляют счета или подтверждения.
Большинству небольших команд нужно всего несколько проверок надёжности. Следите за аптаймом основного сервиса. Следите за медленными страницами или медленными API‑вызовами на ключевых путях. Следите за сломанными потоками: регистрация, чек‑аут, вход или экспорт отчётов. Следите за упавшими фоновыми задачами: синки, письма, импорты или биллинговые прогоны.
Держите цели достаточно простыми, чтобы любой мог объяснить их в одном предложении. Например: «чек‑аут работает без ручных исправлений», или «биллинговые письма уходят вовремя», или «главная панель загружается достаточно быстро для обычного использования». Если команда не может просто объяснить цель — показатель, вероятно, слишком абстрактен.
Надёжность — это тот момент, когда технический шум превращается в бизнес‑боль. Ненадёжная биллинговая задача сдвигает выручку, сломанный вход рушит доверие, медленный отчёт добавляет тикеты в поддержку.
Обычно именно эту метрику основатели чувствуют первыми в объёме поддержки, риске оттока и тоне клиентов. Пользователи редко говорят: «ваша метрика надёжности упала». Они говорят: «ваш продукт ненадёжен», и начинают искать альтернативы.
Как начать измерять, не создавая лишней работы
Хорошая инженерная отчётность не требует нового внутреннего проекта. Начинайте с малого. Выберите одну продуктовую область или одну команду, где работа уже видимо движется от идеи к релизу. Если пытаться мерить всю компанию сразу, люди будут тратить время на бесконечные споры об исключениях вместо того, чтобы что‑то узнать.
Напишите правила подсчёта простым языком до того, как откроете дашборд. Релиз считается, когда код попал в продакшн. Неудача считается, когда изменение вызвало клиентскую проблему, откат или срочный фикс. Нагрузка поддержки — это время на тикеты, баги и прерывания. Надёжность — продукт работал так, как ожидали клиенты.
Используйте инструменты, которые уже есть. Большинству команд достаточно данных из логов деплоя, тикетной системы и заметок по инцидентам. Для старта не нужен новый аналитический стек.
Базовая настройка достаточна: вытяните даты релизов из логов деплоя или релизных заметок, посчитайте тикеты поддержки и оцените потраченное на них время, зафиксируйте инциденты и хотфиксы в одном месте, затем обновляйте числа раз в месяц в общей таблице. Первая версия будет немного грязной — это нормально. Согласованность важнее точности на старте.
Просматривайте метрики раз в месяц, а не каждую неделю. Ежемесячный обзор даёт основателям достаточно сигнала, не превращая измерение в постоянный спор. Для каждой метрики фиксируйте одно действие. Если lead time растёт — возможно, согласования идут слишком медленно. Если поддержка занимает два дня в неделю — одна слабая фича требует глубокого исправления, а не очередного латания.
Держите 6–12 недель истории перед принятием крупных решений. Один плохой месяц может быть вызван большим релизом, отпусками или одним шумным инцидентом. Несколько месяцев последовательного отслеживания придают числам контекст.
Простой пример из небольшой продуктовой команды
Возьмём маленькую SaaS‑команду из пяти инженеров. Они релизят каждую неделю, и по бумагам всё выглядит нормально: количество закрытых тикетов держится. Основатель легко может подумать, что темп команды не изменился.
Числа говорят иначе. В январе средний lead time — четыре дня от начала работы до попадания кода в продакшн. К марту он вырастает до семи дней. Никто не добавил больше работы. Pull request'ы начали просто висеть в ревью примерно по два дня, прежде чем кто‑то к ним вернётся.
Это замедление бьёт сильнее, чем кажется. Фичи приходят позже, исправления багов ждут дольше, инженеры теряют время на переключение обратно на старую работу. Это говорит основателю больше, чем любые story points.
Потом команда пытается ускорить релизы. Они убирают пару проверок и перестают делать один ручной биллинговый тест перед деплоем. Два недели релизы выглядят быстрее. Потом failure rate прыгает с ~10% до 25%. Каждый четвёртый релиз теперь вызывает баг, откат или срочный фикс.
Большая часть боли проявляется в поддержке. Сломанный биллинг начинает дважды списывать некоторым пользователям и блокировать других при апгрейде. Тикетов поддержки становится 48 в неделю вместо 15. Два инженера тратят часть дня на ответы, проверки логов и патчи вместо запланированной работы.
Надёжность падает так, что клиенты это чувствуют. Неудачные платежи, запутанные счёта и задержки с апгрейдами выглядят для пользователей как одна проблема: «продукт ненадёжен». Команда продолжает лечить симптомы, но тикеты возвращаются.
Поворот наступает, когда они решают корень проблемы, а не каждую отдельную жалобу. Они чистят логику состояния биллинга, возвращают проверку релиза и добавляют один тест на сломанный путь. В следующем месяце нагрузка поддержки падает, failure rate снижается, и операции с биллингом становятся стабильными.
Именно поэтому эти четыре числа хорошо работают вместе. Lead time показывает замедление. Failure rate показывает рискованные релизы. Support load показывает скрытую цену. Reliability показывает, доверяют ли пользователи продукту.
Ошибки, которые совершают основатели при чтении чисел
Эти метрики помогают, когда основатели используют их, чтобы понять систему. Они перестают помогать, когда превращаются в табло достижений.
Первая ошибка — превращать командные метрики в индивидуальные оценки. Если одного инженера обвиняют в lead time, failure rate или support load, люди начинают защищаться вместо того, чтобы исправлять процесс. Они дробят тикеты, чтобы выглядеть быстрее, избегают рискованной работы или молчат о проблемах.
Ещё одна ошибка — сравнивать команды с очень разной работой. Команда, выпускающая мелкие дизайн‑изменения, обычно будет двигаться быстрее, чем команда, работающая с платежами, безопасностью или старой инфраструктурой. Это не значит, что одна команда лучше. Это значит, что работа несёт разный риск.
Lead time создаёт ещё одну ловушку. Некоторые основатели давят, чтобы он уменьшался каждый месяц, а затем удивляются росту багов. Если команда пропускает тесты, сокращает ревью или шлёт полупроверенные изменения, lead time упадёт по неправильной причине. Быстрая доставка важна только если изменения остаются рабочими после релиза.
Support load тоже зарывается в абстрактные баки вроде «прочее» или «обслуживание». Это скрывает реальную цену. Если инженеры тратят большую часть недели на ответы клиентам, исправление повторяющихся багов или уборку после сломанных релизов — это не фоновой шум. Это формирует скорость роадмапа.
Одна шумная неделя может сбить с толку основателя. Один инцидент, плохой деплой или крупная клиентская проблема может исказить картину. Смотрите тренд сначала, затем спрашивайте, что изменилось в системе, а не кого винить.
Числа лучше читаются вместе. Рост lead time плюс рост нагрузки поддержки обычно означает, что команда тянет назад старые проблемы. Меньший lead time при росте failure rate обычно означает, что команда ускорилась, пожертвовав безопасностью.
Короткий ежемесячный чек и следующий шаг
Раз в месяц основатель должен потратить 20 минут с инженерным лидом и пройти те же четыре числа. Обычно этого достаточно, чтобы рано заметить проблемы, не загружая команду отчётами.
Держите обзор простым. Подвинулся ли lead time вверх или вниз? Сколько релизов вызвали баги или потребовали хотфикс? Сколько инженерного времени ушло на поддержку? Какой инцидент больше всего навредил пользователям и почему?
Эти вопросы связывают инженерную работу с бизнес‑реальностью. Если lead time и нагрузка поддержки растут вместе — возможно, команда тратит много времени на старые проблемы. Если failure rate растёт после ускорения релизов — нужны лучшие тесты или более мелкие релизы.
Держите scorecard на одной странице. Используйте одни и те же определения каждый месяц. Добавляйте короткую заметку рядом с каждым числом, чтобы позже никто не спорил о том, что изменилось.
Небольшая продуктовая команда может делать всё это в таблице и по напоминанию в календаре. Им не нужен новый инструмент, проект дашборда или долгие митинги.
Если команде нужна помощь в настройке практичного scorecard, опытный Fractional CTO может упростить первый вариант. Oleg Sotnikov, через oleg.is, работает со стартапами и небольшими компаниями над архитектурой продукта, инфраструктурой и AI‑ориентированной доставкой ПО, поэтому такая лёгкая отчётность естественно встраивается в его работу. Начните с этих четырёх метрик на следующие три месяца, затем сверяйте тренд с реальными релизами, тикетами поддержки и инцидентами.


