Менеджеры процессов в модульном монолите, которые остаются простыми
Узнайте, когда менеджеры процессов в модульном монолите помогают, как они координируют длинные бизнес‑потоки и когда стоит держать правила внутри одного приложения.
Содержание
Почему одно действие превращается в путаную цепочку
Одно бизнес‑действие редко остаётся внутри одного модуля. Регистрация затрагивает аккаунты, биллинг, почту, права доступа и журналы аудита. Возврат может начаться в заказах, пройти через платежи, обновить склад, уведомить поддержку и записать финансовую операцию.
Сначала это кажется нормальным. Каждый модуль добавляет правило, которое имеет смысл локально. Проблемы начинаются, когда никто не владеет всем потоком.
Возьмём возврат в одном приложении. Один модуль проверяет, завершён ли платёж. Другой проверяет, отправлен ли заказ. Третий блокирует возвраты для помеченных аккаунтов. Служба поддержки добавляет ручной оверрайд. Финансы добавляют правило для частичных возвратов. Вскоре тот же вопрос проверяется в двух‑трёх местах.
Обычно это растёт медленно. Заказы проверяют право на возврат. Платежи проверяют снова. Инструменты поддержки добавляют исключения. Админская форма пропускает одну из проверок. Позже плановая задача пытается исправить несогласованные случаи.
Теперь проблема больше, чем повторяющиеся условия. Реальный поток разбросан по обработчикам, сервисам, слушателям событий и фоновой работе. Чтобы изменить шаг, разработчик должен помнить обо всех местах, которые реагируют на действие. Пропусти одно — и приложение ведёт себя по‑разному в зависимости от того, как начато действие.
Тогда начинают появляться флаги. Вы видите поля вроде "is_manual", "skip_validation" или "needs_review". Они начинаются как быстрые фиксы. Через пару месяцев превращаются в скрытые ветки в потоке, и никто не хочет их удалять.
Модульный монолит не спасает автоматически просто потому, что всё выполняется в одном кодовой базе. В некотором смысле создать беспорядок даже проще, потому что вызов другого модуля стоит дешево. Команды продолжают добавлять локальные проверки и особые случаи, и один бизнес‑поток превращается в длинную цепочку побочных эффектов.
Хороший модульный дизайн держит модули чистыми, но он же должен дать ясного владельца для кросс‑модульного потока. Без владельца простое действие будет расти, пока небольшие изменения не станут рискованными.
Что делают политики и менеджеры процессов
Модульный монолит становится запутанным, когда одно пользовательское действие запускает несколько последующих. Частью правил логично находиться рядом с доменным действием. Другие правила должны следить за тем, что происходит между модулями и решать, что делать дальше.
Политика — это небольшое локальное правило. Она отвечает на бизнес‑вопрос в момент события. Если клиент меняет тариф, биллинг решает, начислять ли пропорциональную плату. Если сумма заказа высокая, продажи могут потребовать ручного одобрения. Эти решения логично держать рядом с модулем‑владельцем, потому что он уже знает договорённости, лимиты и пограничные случаи.
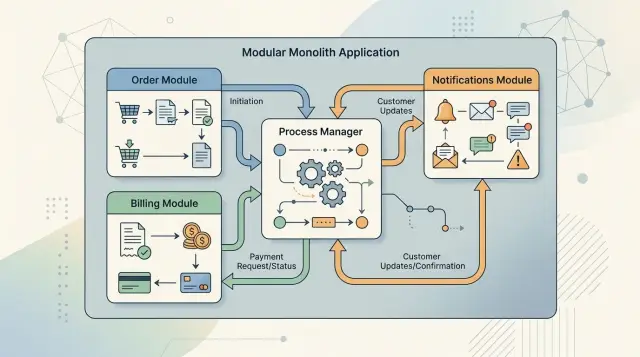
Менеджер процессов решает другую задачу. Он координирует поток, который проходит через модули или через время. Он не заменяет доменную логику внутри модулей. Он слушает события, запоминает текущий шаг и говорит следующему модулю, что делать.
Разделение простое:
- Политика принимает локальное решение внутри одного модуля.
- Менеджер процессов координирует длинный поток через модули.
- Каждый модуль по‑прежнему владеет своими правилами и данными.
Это разделение важно. Если вы вытащите все правила в менеджер процессов, он превратится в гигантского диспетчера, который знает слишком много. Поменяйте одно правило биллинга — и весь поток станет хрупким. Если спрятать все правила внутри модулей, никто не будет владеть потоком от начала до конца.
В одном приложении оба паттерна работают хорошо вместе. Модуль сначала принимает собственное решение, затем публикует событие. Менеджер процессов реагирует только тогда, когда поток пересекает границы модулей или нужно подождать, повторить попытку или остановиться.
Возьмём апгрейд плана. Биллинг решает сумму списания — это политика. После успешного платёжа менеджер процессов говорит модулю доступа открыть новые функции и уведомлениям отправить квитанцию. Если платёж провалился, он фиксирует неудачу и завершает поток.
Менеджер процессов ведёт сам путь. Модули хранят бизнес‑правила.
Куда ставить правила
Путаница начинается, когда один класс пытается выполнять две задачи одновременно: решать правило и запускать рабочий процесс. Сначала это кажется быстрым. Позже любое изменение становится рискованным.
Политика отвечает: "Разрешено ли это?" или "Какой вариант применим?" Менеджер процессов отвечает: "Что будет дальше и когда?" Сохранение этого разграничения упрощает изменения в коде.
Ставьте жёсткие бизнес‑решения рядом с модулем‑владельцем. Правила ценообразования — в модуле ценообразования. Проверки прав — в identity или access control. Если менеджер по продажам может предоставить скидку до 10%, а менеджер — до 20% с одобрением, это политика. Поток заказов должен спрашивать ответ, а не воссоздавать логику.
Время и последовательность — за менеджером процессов. Ожидание платёжного ответа, повтор попытки неудачной почты, создание follow‑задачи через два дня или отмена брони после таймаута — это вопросы потока. Они описывают переход между шагами, а не само правило.
Одно решение — один владелец
Когда владелец неясен, код начинает спорить сам с собой. Модуль заказов проверяет одно правило скидки, выставление счёта — другое, и никто не знает, какое верно.
Чистое разделение выглядит так:
- Политики решают права, лимиты и исход правил.
- Менеджеры процессов реагируют на события и двигают поток вперёд.
- Модули хранят свои данные и предоставляют понятные действия.
- Общее состояние остаётся небольшим и осознанным.
Прежде чем модули начнут делиться состоянием, остановитесь и спросите почему. Общие таблицы и прямые записи кажутся удобными, но быстро стирают границы. Менеджер процессов должен координировать модули, а не тихо превращать их в один большой модуль.
Представьте крупную кастомную коммерческую заявку в одном приложении. Политика ценообразования решает, допустима ли скидка. Политика прав решает, кто может её одобрить. Менеджер процессов ждёт одобрения, напоминает рецензенту через день, повторяет отправку уведомления при ошибке доставки и закрывает заявку, если никто не отреагировал вовремя.
Каждое решение имеет владельца. Каждый шаг — своё место. Это помогает дизайну оставаться понятным после первого релиза.
Постройте первый поток шаг за шагом
Начните с одного результата, который важен для бизнеса. "Одобрить возврат" — достаточно. Если вы можете довести случай от запроса до финального результата внутри одного приложения, у вас прочная база.
Сопоставьте модули, которые реально участвуют в этом результате. Возврат может затронуть Orders, Payments, Risk, Notifications и Accounting. Будьте строгими. Если модуль не принимает решения и не меняет состояние, пока не включайте его.
Затем дайте имена сообщениям, которые двигают работу. Команды просят модуль что‑то сделать. События сообщают, что уже произошло. Пул возврата может включать RefundRequested, CheckRefundPolicy, RefundApproved, PaymentReversed и CustomerNotified. Когда имена соответствуют реальным бизнес‑действиям, продуктовая и поддержка могут проследить поток, не читая код.
Держите состояние процесса в одной явной записи. Не разбросайте его по нескольким таблицам и не надейтесь, что логи заполнят пробелы. Когда возврат застрянет, одна запись должна сказать, где и почему.
Эта запись обычно требует нескольких простых полей:
- process ID и бизнес‑ID, например refund ID или order ID
- текущий шаг и общий статус
- счётчик повторов и время следующей попытки
- последняя ошибка или причина отклонения
- метки времени начала, обновления и завершения
Добавьте таймауты и пути при неудаче до того, как странные случаи накопятся. Решите, что произойдёт, если Payments не ответит за 30 секунд, если Risk отклонит запрос или если возврат успешен, но письмо клиенту не дошло. Это нормальные случаи.
Каждый путь при ошибке должен заканчиваться в явном статусе, а не в неведомости. "WaitingForRetry" понятно. "Something went wrong" ничего не говорит. Если вы делаете повторы, задайте предел. Если нужна ручная вмешательство, пометьте это состояние специально.
Если первый поток кажется немного скучным — это хорошо. Скучные потоки легче менять.
Простой пример: возврат внутри одного приложения
Возврат часто затрагивает несколько модулей, даже когда всё живёт в одной кодовой базе. Поддержка заботится о разговоре с клиентом. Биллинг — о фактах платежа и лимитах. Склад — о запасах. Уведомления — только отправляют сообщения. Кто‑то всё равно должен координировать весь случай.
Вот где менеджер процессов помогает. Он не решает, допустим ли возврат — этим владеет биллинг. Он не решает, можно ли вернуть товар на склад — этим владеет inventory. Менеджер наблюдает за случаем и двигает его вперёд.
Один запрос на возврат — шаг за шагом
Типичный поток может выглядеть так:
- Поддержка открывает запрос на возврат с ID заказа, причиной и тем, кто запросил.
- Менеджер процессов просит биллинг проверить, завершился ли платёж и попадает ли возврат под политику.
- Если биллинг одобрил, менеджер говорит складу отметить товары как возвращённые.
- После каждого изменения состояния уведомления отправляют соответствующее сообщение клиенту и агенту поддержки.
- Менеджер закрывает дело, когда все обязательные шаги завершены, или переводит его на ручную проверку, если что‑то вышло за рамки обычного пути.
Заметьте, что остаётся локальным. Биллинг не вызывает напрямую склад. Склад не решает, возвращать ли деньги. Уведомления не владеют правилом. Каждый модуль отвечает на один понятный вопрос, а менеджер процессов держит порядок.
Это небольшое разделение окупается позже. Если вы добавите проверку на мошенничество, второе согласование для больших сумм или другой шаблон письма, вы измените одну часть вместо того, чтобы вытаскивать логику из трёх модулей.
Работа со состоянием, ожиданиями и повторами
Поток, который может приостанавливаться, нуждается в памяти. Если приложение отправляет сообщение, ждёт два дня и затем проверяет одобрение, просто "pending" недостаточно. Храните текущий шаг, причину остановки и дату следующего действия в одном месте.
Запись состояния важнее изощрённой логики ветвления. Когда кто‑то её откроет, он должен увидеть, что произошло, чего ждёт приложение и кто должен действовать — приложение или человек.
Набор простых полей обычно справляется:
- current_step
- status
- pause_reason
- next_action_at
- last_error
Повторы требуют такого же подхода. Если таймаут срабатывает после отправки письма или создания запроса на платёж, повтор не должен случайно сделать действие снова. Дайте повторяемым операциям стабильный operation ID или пометьте отправку перед следующей попыткой. Если воркер запустится дважды, результат должен оставаться тем же.
Здесь многие команды создают собственный беспорядок. Они прячут временные работы в общем раннере задач с именами вроде "check stuck items" или "daily cleanup". Через месяцы никто не понимает, почему одна запись ждёт или что планирует сделать задача.
Держите ожидание внутри потока. Пусть менеджер процессов ставит next_action_at, а планировщик подбирает только записи с истёкшим сроком. Контекст остаётся со состоянием. Поддержка может открыть одну запись и понять задержку без чтения кода задач.
Когда шаг приостанавливается или падает, записывайте причину простыми словами. "Waiting for manager approval" лучше, чем "blocked". "Bank API timeout" лучше, чем "error". Эта заметка помогает следующему повтору, помогает поддержке отвечать быстрее и помогает разработчикам замечать паттерны.
Хороший тест прост: если человек не может прочитать состояние потока и объяснить паузу одним предложением, поток слишком скрыт.
Ошибки, которые усложняют изменения в потоке
Самый быстрый способ испортить аккуратный рабочий процесс — превратить одного координатора в гигантский мозг. Всё начинается маленько. Один класс обрабатывает одобрение, биллинг, почту и аудиторские логи. Через месяц туда попадают все новые правила. Теперь один файл решает всё, и никто не хочет его трогать.
Менеджер процессов должен координировать шаги, а не хранить все бизнес‑правила. Держите правила ценообразования в биллинге, лимиты возвратов в платежах, состояния клиентов — в аккаунтах. Координатор остаётся простым, когда каждый модуль владеет своим решением.
Ещё одна распространённая ошибка — прямой доступ к таблицам между модулями. Это удобно минут на десять. Затем модуль заказов читает таблицу платежей, обновляет таблицу поддержки и проверяет флаг отгрузки где‑то ещё. Позже одно изменение схемы ломает три несвязанных потока.
Используйте ясные вызовы между модулями. Просите модуль выполнить действие или вернуть факт, которым он владеет. Пусть модуль сам решает, как хранить данные.
События тоже могут стать хаосом. Команды часто пускают события с расплывчатыми именами вроде "status_changed" или "updated". Через полгода никто не знает, кто их публикует, кто слушает и важны ли они ещё. Если у события нет ясного владельца и смысла, оно превращается в шум.
Хрупкий поток обычно видно быстро:
- один координатор растёт без меры
- модули зависят от хранения друг друга
- имена событий мало что говорят
- ошибки останавливают поток без безопасного пути восстановления
- команда добавляет сложные паттерны до того, как простая версия заработала
Четвёртый пункт важнее, чем многие думают. Автоматизация иногда падает. API таймаутится. Запись застревает. Если у людей нет шага для ручного восстановления, они правят базу данных или запускают случайные задачи и надеются. Описывайте, что должны делать поддержка или операторы при провале шага.
Последняя ловушка — добавить сагу, потому что это звучит продвинуто. Большинству команд не нужны распределённые хореографии внутри одного приложения. Если код выполняется в одном монолите и одной базе данных, держите поток локальным, пока простая версия явно не сломалась.
Прежде чем добавлять распределённые саги
Команды часто тянутся к сагам, когда поток начинает казаться запутанным. Обычно это слишком рано. Если одна программа всё ещё обрабатывает работу, разделение потока по сервисам может превратить одну трудность в три более сложные: больше случаев отказа, больше подвижных частей и медленнее отладка.
Начните с формы работы. Если весь поток живёт в одном коде и одной БД, менеджер процессов в монолите обычно достаточен. Вы держите состояние рядом с бизнес‑правилами, смотрите ошибки в одном месте и меняете поток без сетевых контрактов.
Пара проверок поможет принять решение:
- Помещается ли нагрузка, размер команды и темп релизов в один app и одну БД?
- Сколько шагов действительно требуют отложенной координации?
- Приходит ли боль от слабых границ модулей, а не от самого монолита?
- Может ли одна команда проследить ошибку от начала до конца без догадок, кто владеет багом?
- Есть ли у вас реальная причина для разделения, например разные требования к доступности или сильно разные паттерны масштабирования?
Поток возврата — хороший тест. Если биллинг, заказы и уведомления работают в одном приложении, вам, возможно, нужны лишь политика, менеджер процессов и задача повтора. Разделите поток на сервисы слишком рано — и простой возврат потребует контрактов сообщений, идемпотентности, таймаутов и распределённого трассирования.
Для многих команд монолит живёт дольше, чем они думают. Реальный фикс чаще — лучшие границы и ясный поток, а не инфраструктура.
Oleg Sotnikov часто работает со стартапами по этой проблеме: держать архитектуру лёгкой, улучшать границы модулей сначала и сплитить сервисы только при реальной необходимости. Через oleg.is он предлагает fractional CTO и консультации для команд, которым нужен практический обзор архитектуры, дизайна процессов или рабочих процессов с фокусом на ИИ.
Что делать дальше
Выберите один бизнес‑поток, который уже вызывает мелкие проблемы. Возврат, апгрейд аккаунта или одобрение счёта — достаточно. Сначала нарисуйте поток на бумаге. Пропишите каждый шаг, кто принимает решение, что может пойти не так и что должно произойти после повтора.
Этот набросок часто проясняет ситуацию быстрее, чем ещё одна встреча. Видно, какие части — доменные правила, а что требует координатора. Многие команды лезут в код слишком рано, а потом удивляются, почему через месяц поток запутался.
Далее разделите один запутанный поток на две части. Поместите одно бизнес‑решение в политику. Поместите одну более длинную последовательность в менеджер процессов. Держите оба маленькими. Политика должна отвечать на одно правило в одном месте. Менеджер процессов должен перемещать работу от шага к шагу, не превращаясь во второе приложение, спрятанное в первом.
Практический первый проход может выглядеть так:
- выберите часто повторяющийся и часто ломающийся поток
- давайте командам команды и события именами, которыми уже пользуется бизнес
- добавьте логи для каждого шага, повтора, таймаута и ручного исправления
- напишите короткую заметку о восстановлении, чтобы другой разработчик мог справиться с застрявшим случаем
Сделайте это до того, как добавите ещё автоматизации. Если никто в команде не может ответить на вопросы "где живёт это правило?" и "как восстановить этот поток?" за пять минут, проблема — не в масштабе, а в форме.
Будьте честны по поводу объёма. Если один менеджер процессов начинает читаться как огромный скрипт с перемешанными правилами, остановитесь и сократите. Перенесите решения обратно в домен. Оставьте координатору тайминги, порядок и восстановление.


