Маскирование PII в подсказках ИИ — до того, как данные покинут вашу сеть
Редактирование PII для подсказок ИИ помогает удалять или маскировать чувствительные поля, логи и вложения и предотвращать утечки до того, как данные покинут вашу сеть.
Содержание
Что идёт не так, когда сырые подсказки покидают вашу сеть
Проблема начинается раньше, чем думают многие команды. Подсказка редко бывает просто вопросом. Она часто включает email клиента, заметку поддержки с полным именем, номер счёта или внутренний комментарий, вставленный в спешке.
Логи усугубляют ситуацию. Один скопированный отчёт об ошибке может содержать API-токены, идентификаторы сессий, внутренние IP-адреса, пути к файлам, трассировки стека или фрагменты записи клиента. Отправитель может хотеть помочь с одной ошибкой, но весь блок уходит за пределы вашей сети.
Ручная чистка звучит разумно, пока люди не становятся занятыми. Команды поддержки, инженеры и операторы работают быстро. Если инструмент ИИ даёт полезные ответы, люди сначала вставляют, а проверяют потом. Именно так приватные данные выскальзывают при обычной работе, а не только в крупных инцидентах.
Как только данные пересекают ваш периметр, контроль быстро падает. Команды безопасности теряют видимость. Аудит занимает больше времени. Юридические и комплаенс-обзоры усложняются, потому что теперь кому‑то придётся ответить на три прямых вопроса: что ушло, кто отправил и было ли это разрешено?
Небольшая оплошность при копировании может раскрыть гораздо больше, чем ожидают. Заметка в тикете может содержать телефон и адрес клиента. Лог для отладки — bearer-токен. Вставленная цепочка писем может раскрыть имена, должности и внутренние заметки. Отчёт о падении может включать локальные имена пользователей и пути к файлам. Даже фрагмент CSV может содержать сотни строк клиентов, тогда как отправитель хотел показать только один пример.
Вложения несут тот же риск. PDF, скриншот или таблица часто содержат текст, который люди не замечают с первого взгляда. Скрытые столбцы, метаданные документа и старые комментарии могут уехать вместе с файлом.
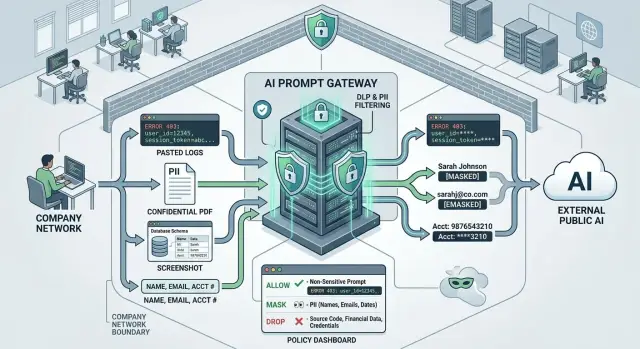
Поэтому редактирование PII для подсказок ИИ должно происходить до того, как данные покинут вашу сеть. Убирать последствия постфактум медленно, дорого и трудно доказуемо. Блокировка или маскирование чувствительных данных на границе менее заметны, но гораздо безопаснее.
Какие данные ловить в первую очередь
Начните с простого правила: ловите всё, что указывает на реального человека или даёт доступ к реальной системе. Команды часто фокусируются на очевидных полях и пропускают вокруг них беспорядочные детали. Подсказка может выглядеть безобидной, но при этом содержать достаточно информации, чтобы идентифицировать клиента, сотрудника или аккаунт.
Сначала — прямые идентификаторы. Имена, email-адреса, номера телефонов, домашние адреса, номера счетов, логины и ID инвойсов обычно не добавляют ничего полезного к ответу модели.
Затем — секреты, не только личные данные. API-ключи, сессионные токены, приватные URL, внутренние хостнеймы, ссылки для сброса пароля и подписанные ссылки на файлы часто проскальзывают через логи, заметки тикетов и вставленные сообщения об ошибках. Одна плохая строка лога может раскрыть больше, чем полный профиль клиента.
Короткая политика работает лучше длинной. Удаляйте поля, которые модели вовсе не нужны, такие как полные имена, телефоны и номера счётов. Маскируйте поля, которые дают контекст, но не должны быть раскрыты, например email, номера заказов или часть адреса. Блокируйте подсказки, содержащие секреты вроде токенов, приватных ссылок или учётных данных. И обращайтесь с свободным текстом осторожно, потому что заметки и история чата часто скрывают личные детали в простом языке.
Свободный текст вызывает большинство пропусков. Тикет поддержки может содержать: "John позвонил с личного номера после того, как не смог войти в портал зарплаты", и в одном предложении будет имя, подсказка к телефону и чувствительная бизнес‑функция. Внутренние комментарии, заметки CRM, вставленные чаты и старые ветки тикетов полны таких деталей.
Полезно также решить, что именно модели действительно нужно. Если задача — суммировать отчёт об ошибке, модели, вероятно, нужен текст ошибки, версия продукта и тип устройства. Ей вряд ли нужна личность клиента, история биллинга или сырые сессионные данные.
Команды, которые делают это правильно, перестают относиться ко всем полям одинаково. Они сохраняют контекст, полезный модели, и убирают детали, создающие риск без причины.
Установите правила: удалить, маскировать или разрешить
Политика редактирования должна отвечать на один простой вопрос для каждого поля: нужна ли модели точная величина, частичная подсказка или ничего вообще?
Обычно это три действия. Удаляйте данные, которые модели не нужны вовсе: полные имена, email, телефоны, адреса, номера счётов и внутренние ID. Маскируйте, когда людям всё ещё нужен намёк — последние четыре цифры карты, первая буква фамилии или часть номера заказа. Разрешайте контекст, который действительно помогает модели: версия продукта, код ошибки, тип устройства, статус заказа или уровень тарифа.
Пишите эти правила по полям, источникам и ролям пользователей. Поле CRM предсказуемо. Вставленная заметка тикета — нет. Серверный лог может содержать токены, IP или скрытые query‑строки. Одно и то же значение может быть допустимо в одном внутреннем рабочем процессе и заблокировано в другом.
Роль тоже важна. Агент поддержки может нуждаться в маскированных данных клиента, чтобы удержать дело в порядке. Модели, возможно, нужны только версия продукта и текст ошибки. Финансовым сотрудникам могут быть нужны суммы счёта, тогда как общему AI‑ассистенту никогда не следует получать налоговые идентификаторы или банковские данные.
Неизвестному тексту нужен запасной план. Если содержимое не сопоставляется с известными полями, считайте его рискованным, пока не докажете обратное. Сканируйте свободный текст, вложения и вставленные логи на предмет email, секретов, длинных числовых строк, токенов авторизации и имён. Если фильтр не уверен, удалите блок, замените его короткой заметкой или отправьте резюме вместо исходного фрагмента.
Одно правило лучше десятка исключений: в сомнении — оставляйте меньше. Политику всегда можно ослабить после тестирования. Вытянуть чувствительные данные из подсказок после того, как люди привыкли их отправлять, намного сложнее.
Постройте поток редактирования шаг за шагом
Начните с карты. Если вы не знаете, откуда приходят подсказки, вы пропустите данные в первый же день. Перечислите каждый источник, который может питать модель: веб‑формы, чаты, тикеты поддержки, заметки CRM, вставленные логи, загружаемые файлы и любые фоновые поля, которые ваше приложение добавляет за кулисами.
Затем пометьте каждое поле простой действией. Четырёх меток обычно достаточно: allow, mask, drop или review. ID тикета может остаться. Email может превратиться в плейсхолдер. Пароль ни в коем случае не должен уходить. Свободная заметка со смешанным содержанием может требовать ручной проверки, если правила неясны.
Система должна проверять данные до того, как подсказка пересечёт границу. На практике это означает два прохода. Сначала — шаблонные проверки для лёгких совпадений: email, телефоны, номера карт, API‑ключи и форматы национальных ID. Затем — осмотр полного текста, чтобы поймать более мягкие случаи, например вставленное предложение с именем или блок логов с целым профилем клиента.
Когда вы маскируете данные, сохраняйте читаемость подсказки. Заменяйте каждый секрет стабильным плейсхолдером, а не удаляйте куски наугад. Если один и тот же email встречается три раза, используйте один и тот же токен, например [EMAIL_1]. Модель всё ещё может следовать сюжету, сравнивать повторяющиеся значения и отвечать на задачу без реальных данных.
Практический поток выглядит так:
- Соберите все входы подсказки в одном месте.
- Классифицируйте каждое поле по политике.
- Просканируйте объединённый текст и извлечённый текст файлов.
- Замените или удалите совпадения стабильными плейсхолдерами.
- Запишите действие в лог, затем отправьте очищенную подсказку.
Держите журнал аудита компактным. Записывайте, какое правило сработало, какое поле изменилось и на какой плейсхолдер оно было заменено. Не сохраняйте исходный секрет снова в логах, отчётах об ошибках или аналитике. Команды иногда строят аккуратный слой редактирования, а потом через пять минут сливают оригинальное значение в отладочный вывод.
Если вы вручную проверяете что‑то одно — проверяйте именно журнал изменений. Он покажет, ловит ли политика реальные данные, не превращая каждую подсказку в бессмысленный набор символов.
Следите за крайними случаями, которые люди забывают
Правило редактирования может выглядеть надёжно на демо и всё же провалиться на грязных входных данных, которые люди присылают каждый день. Большинство промахов происходит из содержимого, которое выглядит безобидно, пока система не раскроет его.
Файлы и изображения
Имена файлов почти ничего не говорят. PDF под именем "report.pdf" может содержать имена, номера счётов и вставленную стенограмму чата. Сканируйте содержимое вложений после извлечения текста, а не до. Если ваш поток проверяет только тип файла или имя, он пропустит реальный риск.
Со скриншотами та же проблема. Команды часто сканируют только простые текстовые поля и забывают, что скриншот дашборда, счета или страницы ошибки может содержать email, телефон или детали сессии. PDF тоже подлые — многие из них по сути изображения в оболочке документа. Запустите OCR для скриншотов и image‑PDF перед тем, как фильтр решит, что можно отправлять из сети.
Трассы стека требуют особой осторожности. Разработчики вставляют их в подсказки, чтобы быстро получить помощь по отладке, но трассы часто включают токены, внутренние хостнеймы, email и локальные пути. Одна строка может раскрыть имя пользователя, имя сервера и секрет, взятый из переменной окружения.
Вставленное содержимое
Таблицы легко недооценить. Одна вставленная ячейка может содержать целый блок записей с переносами строк внутри. Ваш фильтр должен проверять весь полезный груз, а не разбивать по табуляции и полагать, что в каждой ячейке одно аккуратное значение.
Длинные скопированные чаты — ещё одно распространённое упущение. Агенты поддержки и менеджеры по работе с клиентами часто вставляют полный разговор, где смешиваются данные клиента и внутренние заметки. Клиентская сторона может быть безопасна после маскирования, тогда как внутренние комментарии могут раскрыть статус аккаунта, историю возвратов или мнения сотрудников, которые должны оставаться внутри.
Хороший тест‑набор должен включать PDF только из изображений, скриншоты с мелким текстом, трассы стека с секретами и локальными путями, ячейки таблиц со множественными записями и длинные чаты со смешанными публичными и внутренними заметками. Если ваша политика справляется с этим, она гораздо ближе к реальной жизни.
Простой пример из поддержки
Хорошее редактирование на практике выглядит скучно — и это именно то, чего вы хотите. Агент поддержки получает тикет о падении на этапе оформления заказа, копирует сообщение клиента и вставляет часть лога падения в внутреннего AI‑ассистента.
Сырой текст содержит больше, чем нужно агенту. Сообщение клиента включает email и адрес. Лог содержит IP‑адрес и сессионный токен. Ничто из этого не помогает модели объяснить, почему приложение упало, поэтому фильтр удаляет это до того, как подсказка покинет сеть.
Остаётся технический контекст, который модель действительно может использовать: product version 5.14.2, error code AUTH-417 и временной интервал, когда падение произошло.
Слой редактирования меняет чувствительные поля на метки вроде [EMAIL], [IP], [SESSION_TOKEN] и [ADDRESS]. Подсказка остаётся читабельной. Модель видит, что пользователь на версии 5.14.2 столкнулся с AUTH-417 между 14:00 и 14:15, но не видит, кто этот пользователь.
Этого достаточно для полезного ответа. Модель может предположить вероятные причины и дать простые шаги по устранению: проверить сбой обновления аутентификации, сравнить логи за указанный интервал и протестировать тот же сценарий на указанной версии продукта. Агент получает помощь быстро, а личность клиента никогда не уходит к модели.
Именно тут редактирование PII для подсказок ИИ либо срабатывает, либо нет. Удалите слишком много — ответ станет расплывчатым. Удалите слишком мало — вы сливаете данные без причин. Простой allow‑лист для номеров версий, кодов ошибок и временных меток обычно работает лучше, чем попытки угадать всё, что может понадобиться модели.
Команда также должна хранить маскированную подсказку, а не сырую, вместе с ответом модели. Позже ревьювер может заметить пропуски, например формат токена, который просочился через лог, и обновить политику и тесты. Этот цикл обратной связи важнее любых хитрых правил.
Ошибки, которые ломают редактирование на практике
Большинство провалов — обыкновенные вещи. Команда пишет пару regex‑правил для email, телефонов и карт, тестирует их на чистых образцах и считает задачу закрытой. Потом кто‑то пишет: "my wife Anna Petrova at [email protected] used the same card ending 2241" в свободное поле, и правила пропускают половину данных.
Свободный текст быстро ломает аккуратные паттерны. Люди вставляют чаты, заметки тикетов, инструкции по доставке и сообщения об ошибках так, как ни один дизайнер формы не планировал. Если ваши правила проверяют только помеченные поля, чувствительные данные утекают через самую неструктурированную часть подсказки.
Маскирование в форме создаёт ложное ощущение безопасности. UI может скрывать имя клиента или номер счёта в видимых полях, но то же значение может находиться в PDF, скриншоте, CSV‑экспорте или вставленном логе. Как только генератор подсказок упаковывает эти файлы в запрос, замаскированная форма уже не имеет значения.
Нижние окружения создают тихие утечки. Разработчики копируют продакшен‑записи в staging для отладки потока подсказки, затем тест запускает реальные данные в логи модели или инструменты трассировки. Staging кажется временным, но данные всё ещё реальные.
Чрезмерное редактирование создаёт другую проблему. Если фильтр вырезает каждый номер заказа, дату, хостнейм и строку ошибки, модель не сможет отличить один случай от другого. Ответ становится расплывчатым, потому что подсказка потеряла детали, которые делали её полезной.
Пара проверок ловит большую часть проблем. Тестируйте правила на свободном тексте, а не только на структурированных полях. Сканируйте вложения и вставленные логи перед сборкой подсказки. Проверяйте staging и dev‑логи на предмет реальных записей. Сравнивайте вывод модели до и после маскировки. Перезапускайте тесты после любого изменения формы, модели или рабочего процесса.
Правила устаревают быстрее, чем ожидают люди. Появляется новое поле «дополнительные детали», команда продукта начинает присылать изображения или инженер добавляет отладочные файлы. Если никто не ретестит, старые правила продолжают проходить, а новые пути начинают течь.
Редактирование работает, когда команды относятся к нему как к коду. Версионируйте правила, тестируйте их на уродливых реальных примерах и пересматривайте при каждом изменении рабочего процесса.
Быстрые проверки перед включением
Запустите несколько грязных тестов, прежде чем доверять фильтру. Чистые демонстрационные подсказки мало что говорят. Реальный трафик смешивает имена, токены, вставленные логи и странное форматирование в одном запросе.
Начните с трёх простых кейсов. Один должен содержать имена и контактные данные. Один — секреты, такие как API‑ключи, пароли или токены доступа. Один должен смешивать данные клиента с безобидным бизнес‑контекстом — именно здесь редактирование PII для подсказок ИИ часто промахивается.
Затем усложните тест. Добавьте фейковое вложение и вставьте часть трассы стека в тот же запрос. Многие команды тестируют только текстовое поле и пропускают то, что появляется в загруженных файлах, скопированном выводе терминала или скриншотах, конвертированных в текст.
Короткий чеклист поможет держать честность:
- Протестируйте подсказку с именами и прямыми идентификаторами.
- Протестируйте подсказку с секретами и учётными данными.
- Протестируйте смешанные данные, а не изолированные примеры.
- Добавьте одно фейковое вложение и одну вставленную трассу стека.
- Проверьте и редактированную подсказку, и ответ модели.
Не останавливайтесь на «секрет исчез». Модель всё ещё должна получать достаточно контекста, чтобы ответить на бизнес‑вопрос. Если агент поддержки спрашивает, почему заказ провалился, система должна сохранить тип ошибки, название продукта и временную шкалу после маскировки имени клиента, email и платёжных данных.
Этот баланс требует человеческой проверки. Безопасность должна проверить, ловит ли политика то, что никогда не должно покидать сеть. Юридический или privacy‑отдел должен подтвердить, что маскировка соответствует внутренним правилам. Владельцы рабочего процесса должны подтвердить, что результат по‑прежнему работает для команды, которая использует его ежедневно.
Ложные срабатывания тоже важны. Если фильтр слишком часто маскирует безвредные термины, люди начнут обходить его или перестанут доверять инструменту. Трасса стека со всеми удалёнными ID быстро становится бесполезной.
Установите расписание проверок до запуска. Ежемесячно подходит многим командам, а для высокорисковых рабочих процессов нужны более частые ревизии. Анализируйте промахи, лишние маскировки и обходы после изменений в продукте или появлении новых типов вложений. Редактирование — не одноразовая настройка. Оно требует небольших регулярных проверок.
Следующие шаги, которые команда сможет поддерживать
Большинство команд добиваются лучших результатов, начиная по‑маленьку. Выберите один рабочий процесс, где ошибка может причинить вред — тикеты поддержки, вставленные логи или заметки продаж с данными клиентов. Запустите редактирование там сначала, исправьте шероховатости, и только потом расширяйте на другие пути подсказок.
Короткая политика лучше длинного документа, который никто не читает. Постарайтесь уложиться на одной странице и назначьте ответственных за каждое поле. Если email‑адреса относятся к поддержке, номера счёта — к финансам, а ID сотрудников — к HR, запишите это, чтобы ревью не расплывалось.
В политике должно быть указано, какие поля всегда удалять, какие маскировать и как должен выглядеть результат маскировки, какие поля разрешены, потому что AI‑задача их требует, кто утверждает изменения и когда команда пересматривает политику.
Используйте реальные тестовые кейсы, а не чистые примеры. Вставляйте те грязные вещи, которые люди действительно шлют: трассы стека, скриншоты, подписи, стенограммы чатов и длинные логи с именами клиентов, спрятанными в середине. Правило, которое работает на аккуратном демо, часто проваливается на второй странице реальной переписки поддержки.
Затем наблюдайте несколько недель. Считайте три вещи: промахи, ложные срабатывания и обходы. Промахи показывают, где чувствительные данные всё ещё просачиваются. Ложные срабатывания — где фильтр блокирует слишком много и раздражает персонал. Обходы показывают, где люди перестают доверять процессу и начинают копировать текст в побочные инструменты или личные заметки.
Ежедневный процесс должен казаться скучным. Сотрудникам не должно приходиться догадываться, нажимать пять предупреждений или помнить десятки исключений. Если безопасный путь медленнее рискованного, люди будут его избегать.
Если нужен второй взгляд, Oleg Sotnikov на oleg.is может проверить потоки подсказок, правила редактирования и тест‑кейсы в рамках своей работы Fractional CTO. Внешний обзор часто достаточно, чтобы заметить слепые зоны, которые внутренняя команда перестаёт видеть после недели настройки.
Часто задаваемые вопросы
Что такое редактирование PII для подсказок ИИ?
Это означает, что ваша система удаляет или маскирует персональные данные и секреты до того, как отправит подсказку в любую модель. Цель проста: держать данные клиентов, сотрудников, токены и внутреннюю информацию внутри сети, если модель действительно в них не нуждается.
Почему подсказки протекают больше данных, чем ожидают?
Потому что люди редко копируют только ту единственную строку, которая им нужна. Подсказка часто содержит лишний текст из писем, тикетов, логов, скриншотов или файлов, и этот дополнительный текст может включать имена, телефоны, токены, IP-адреса или внутренние заметки.
Какие поля нужно отлавливать в первую очередь?
Начните с всего, что идентифицирует реального человека или даёт доступ к реальной системе. В приоритете — имена, email, номера телефонов, адреса, номера счетов, логины, API-ключи, сессионные токены, подписанные ссылки и внутренние хостнеймы.
Когда удалять данные, маскировать их или блокировать подсказку?
Удаляйте данные, когда модель совсем не нуждается в них (например, полные имена или номера счетов). Маскируйте, когда модель нужна подсказка (например, часть номера заказа). Блокируйте подсказку, если в ней есть секреты вроде токенов, учетных данных или приватных ссылок.
Почему использовать плейсхолдеры вроде [EMAIL_1], а не удалять текст?
Стабильные плейсхолдеры сохраняют читабельность подсказки после очистки. Если тот же email встречается три раза, замена на один и тот же ярлык позволяет модели следовать за контекстом, не видя реального значения.
Нужно ли сканировать вложения и скриншоты?
Да. Файлы и изображения часто скрывают худшие утечки. PDF может содержать комментарии или метаданные, скриншот может показать email или токен, а PDF на основе изображения требует OCR перед тем, как фильтр сможет его проинспектировать.
Хватит ли правил на основе regex для редактирования подсказок?
Нет. Регексы ловят простые паттерны вроде email или телефонов, но свободный текст быстро ломает такие правила. Люди вставляют имена, личные данные и секреты в беспорядке, поэтому нужны полнотекстовые проверки.
Как сохранить полезность подсказок после редактирования?
Сохраняйте технический контекст и убирайте идентификационные детали. Коды ошибок, версия продукта, тип устройства, временные метки и статус заказа обычно помогают модели, тогда как имена клиентов, адреса и сырые сессионные данные — нет.
Как тестировать поток редактирования перед запуском?
Проводите «грязные» тесты, а не аккуратные демо. Используйте примеры с перемешанными данными клиентов, секретами, вставленными трассами ошибок, длинными чатами и фейковыми вложениями, затем проверяйте и редактированную подсказку, и ответ модели.
Как часто нужно пересматривать правила редактирования?
Пересматривайте правила по расписанию и после каждого изменения рабочего процесса. Новые формы, новые типы файлов и дополнительные пути подсказок создают новые риски, поэтому команды должны часто обновлять правила, тесты и логи.


