Машины состояний для более безопасной многошаговой автоматизации с ИИ
Машины состояний для ИИ делают повторные попытки, согласования и побочные эффекты заметными, чтобы команды могли быстро находить скрытые сбои и разбираться с поломанными запусками без догадок.
Содержание
Почему промпт-цепочки ломаются в реальной работе
Промпт-цепочки выглядят аккуратно на доске. Шаг 1 что-то читает, шаг 2 принимает решение, шаг 3 действует. В реальной работе все куда менее аккуратно.
Бизнес-процессы останавливаются. Данных не хватает. Люди отвечают с опозданием. Внешние системы ломаются в самый неподходящий момент. Простая промпт-цепочка обычно предполагает, что каждый шаг выполняется один раз, по порядку и без путаницы. Это предположение быстро рушится.
Один пропущенный шаг может увести весь поток не туда. Если модель извлекла неверный ID клиента, следующий промпт все равно может подготовить письмо, открыть тикет или сформировать платеж. Цепочка продолжает двигаться, потому что знает только то, что произошло на последнем шаге. Она не знает истинного состояния задачи.
Повторы создают вторую проблему. Они звучат безопасно, но часто скрывают ошибку вместо того, чтобы показать ее. Если модель не успела ответить вовремя, скрипт может снова запустить тот же промпт, а потом повторить и следующее действие. Снаружи задача выглядит завершенной. Внутри система могла отправить два письма или создать два тикета в поддержку.
С человеческим согласованием в промпт-цепочках тоже все быстро усложняется. Многие команды воспринимают согласование как еще одно сообщение в последовательности. Это работает, пока кто-то не одобрит не в том канале, не ответит слишком поздно или не изменит запрос после того, как модель уже пошла дальше. Тогда у цепочки нет понятного места, где ждать, возобновляться или отклонять изменение.
Побочные эффекты — это то, где небольшие ошибки становятся дорогими. Как только AI-система отправляет счет, обновляет CRM, оформляет возврат или меняет запись клиента, вам нужен ясный способ понять, что произошло и произошло ли это уже один раз.
Небольшой пример показывает проблему. AI проверяет счет, просит менеджера подтвердить его и потом отправляет его в бухгалтерию. Если сообщение с подтверждением потеряется и сработает логика повторной попытки, система может запросить подтверждение дважды, сохранить один ответ и отправить счет дважды. Сбой остается скрытым, потому что каждый промпт видит только свой кусок процесса.
Вот почему промпт-цепочки хорошо выглядят в демо, но в продакшене ведут себя шатко. Они слишком легко движутся вперед и мешают остановить, проверить или откатить неудачный шаг.
Что добавляет машина состояний
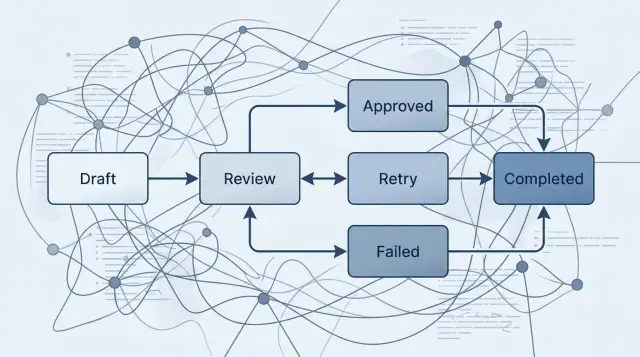
Промпт-цепочка знает, что спросить дальше. Но обычно она не знает, где находится, почему остановилась и что делать после плохого результата.
Машина состояний дает работе карту. Каждый шаг получает понятное имя, например drafted, waiting_for_review, approved, sent или failed. Когда что-то идет не так, вам не нужно строить догадки по логам и истории промптов. Вы видите текущее состояние и действуете от него.
Еще одно изменение — дисциплина. Запуск переходит дальше только тогда, когда это разрешает правило. Если модель дала слабый ответ, workflow может перейти в retry_requested вместо того, чтобы тащить плохой результат в следующий шаг. Если человеку нужно подтвердить платеж, запуск остается в waiting_for_approval, пока это подтверждение не появится.
Хорошая машина состояний также хранит причину каждого перехода. Сохраняйте результат, который вызвал переход, того, кто его одобрил, ошибку, которая остановила процесс, и момент, когда система сделала паузу. Этот след важен позже, когда кто-то задаст простые вопросы: почему этот заказ остановился? Почему модель пробовала три раза? Почему письмо так и не ушло?
Большинству команд нужны четыре контроля сильнее, чем они ожидают: повторная попытка после ошибки модели, отмена до того, как случится побочный эффект, возобновление после решения человека и явный сбой, если правило нарушено. Это не редкие случаи. Это обычные условия работы.
API зависают. Люди уходят офлайн. Модели возвращают неверный формат. Машина состояний исходит из того, что это произойдет, и дает каждому случаю безопасное место для остановки.
Если вы когда-нибудь видели, как AI-задача отправляет одно и то же сообщение дважды или останавливается на середине без понятной причины, вот недостающий элемент. Цель не в том, чтобы добавить больше процесса. Цель в том, чтобы сделать workflow таким, который можно проверить, поставить на паузу, откатить и которому можно доверять.
Спланируйте рабочий процесс до того, как строить его
Большинство сбоев начинается не в модели. Они начинаются с размытого процесса. Если вы не можете нарисовать путь от первого входа до финального результата, автоматизация будет скрывать ошибки вместо того, чтобы ограничивать их.
Запишите точное начало и конец. Говорите прямо. Началом может быть «новый запрос в поддержку поступил» или «черновик договора попал на проверку». Конец должен быть таким же конкретным, например «клиент получил финальный ответ» или «одобренный договор сохранен и отправлен».
Потом назовите каждый шаг между ними как состояние, а не как промпт. Промпт — это только одно действие. Состояние показывает, где работа находится сейчас, кто за нее отвечает и что может произойти дальше.
Обычно достаточно простого листа. Для каждого состояния запишите, что в него вошло, кто или что действует в нем, какое решение переводит его дальше и куда оно идет в случае сбоя. Такая маленькая привычка рано ловит много скрытых проблем.
Особенно внимательно смотрите на решения. Часть из них должна принадлежать модели, например классификация сообщения или извлечение полей. Другие должны оставаться за человеком, например одобрение возврата, публикация контента или отправка чего-то чувствительного. Если нужен человек, сделайте это отдельным состоянием вроде waiting_for_approval, а не заметкой, спрятанной в коде.
Отмечайте все внешние действия в заметках отдельно. Отправка письма, списание с карты, обновление записи, удаление файла или создание тикета могут причинить ущерб, если они сработают дважды. Для таких шагов нужны жесткие границы и видимые результаты.
Обработке исключений тоже нужен владелец. Решите, кто отвечает за низкую уверенность, отсутствующие данные, тайм-ауты и конфликты с политиками. Если за эти случаи никто не отвечает, они просто лежат в логах, пока их не заметит клиент.
Основатель может набросать это на бумаге за 15 минут. Такое быстрое упражнение часто сразу показывает слабые места: неясные согласования, дублирующие действия и тупики, где у workflow нет безопасного следующего шага.
Соберите первую версию по шагам
Первая версия должна быть скучной. Начните с обычного пути, который доводит задачу до конца, когда ничего не идет не так. Если вы не можете назвать этот путь в пяти или шести состояниях, workflow все еще слишком размытый для автоматизации.
Запишите состояния по порядку и держите каждое из них маленьким. Состояние должно делать одну работу: собирать вход, вызывать модель, ждать согласования, записывать данные или запускать внешнее действие. Когда одно состояние пытается делать две или три работы, сбои становится трудно отследить.
Структура может оставаться простой. Начните с понятного состояния входа, добавьте по одному состоянию для каждого вызова модели или внешнего действия и завершите явным состоянием завершения. Дайте каждому состоянию одно правило выхода. Используйте названия, которые понятны неинженерам.
После этого добавляйте состояния сбоя только там, где ошибка может навредить. Модель может вернуть плохой ответ. API может не ответить вовремя. Сообщение может уйти дважды. Запирайте такие рискованные шаги за явными состояниями вроде failed_validation, retrying или awaiting_review.
Правила повторных попыток и тайм-аутов задайте до того, как писать код. Держите лимит повторов небольшим, обычно две или три попытки. Если вызов модели все равно не удается, переводите задачу на ручную проверку или в состояние сбоя вместо бесконечного цикла. С тайм-аутами нужен такой же подход. Решите, сколько времени каждый шаг может ждать и что произойдет, когда этот предел будет достигнут.
Сохраняйте след каждого перехода. Записывайте вход, выход, смену состояния и причину, по которой workflow двинулся дальше, остановился или сломался. Добавьте еще метку времени и ID задачи. Позже, когда кто-то спросит, почему задача остановилась или почему она сработала дважды, вы ответите фактами, а не догадками.
Проверяйте управляющие сценарии заранее, а не в конце. Остановите задачу на середине и возобновите ее. Отмените ее до того, как произойдет побочный эффект. Принудительно вызовите сбой после локального изменения и проверьте, работает ли откат. Если шаг нельзя откатить, добавьте состояние восстановления для ручной очистки. Workflow готов тогда, когда он может остановиться, восстановиться и точно показать, что произошло.
Простой пример: согласование счетов с AI
Представьте финансовую команду, которая получает по 200 счетов в неделю по email. AI-модель читает каждый файл, вытаскивает название поставщика, номер счета, итоговую сумму, дату оплаты и номер заказа, а затем передает эти данные дальше. Вот где машина состояний действительно помогает: каждый счет находится в одном понятном состоянии, и никому не нужно догадываться, что произошло.
Простой поток может выглядеть так:
received: файл пришел, получил ID и ждет проверокextracted: модель разобрала счет и сохранила оценки уверенности для каждого поляneeds_review: человек проверяет неясные или отсутствующие данныеpayment_ready: счет прошел проверку и может перейти в платежную системуfailed: у счета плохие данные, это дубликат или согласование так и не пришло
Проверка на дубликаты должна происходить до любого шага с оплатой. Если у двух счетов совпадают поставщик, номер счета и сумма, система должна остановиться и пометить один из них как дубликат или как failed. Звучит просто, но это предотвращает одну из самых дорогих ошибок в многошаговой автоматизации.
Оценки уверенности решают, когда AI может двигаться дальше, а когда должен вмешаться человек. Если модель с высокой уверенностью прочитала сумму и номер счета, этого часто достаточно. Если название поставщика размыто или номер заказа отсутствует, счет должен перейти в needs_review, а не скользить дальше.
Проверяющий может исправить поля, подтвердить итоговую сумму и одобрить или отклонить счет. Система должна записать, кто его одобрил и когда. Если никто его не одобрит, счет не должен висеть в подвешенном состоянии. Через заданное время он должен перейти в failed, чтобы команда увидела его и смогла с ним что-то сделать.
Когда согласование готово, счет может перейти в payment_ready. Обратите внимание, что остается разделенным: чтение счета — это один шаг, согласование — другой, а платеж — третий. Такое разделение держит побочные эффекты под контролем. Если PDF не читается, сумма не совпадает или согласование так и не приходит, счет попадает в failed, где команда может его проверить, исправить и безопасно запустить повторно.
Ставьте повторы и согласования в нужное место
Повторы помогают, когда модель не смогла классифицировать сообщение или извлечь поля. Они не помогают, когда система уже коснулась внешнего мира. Если модель вернула сломанный JSON, повторите вызов модели. Если приложение уже отправило письмо или списало деньги, слепой повтор может продублировать действие и создать еще больший хаос.
Ставьте точки согласования прямо перед необратимыми шагами. Черновик ответа клиенту может оставаться автоматическим. Но отправка этого ответа должна ждать, если в сообщении есть возврат денег, юридическое обещание или изменение цены. То же правило действует для платежей, закрытия аккаунтов и отмены заказов. Пусть AI подготовит работу, а потом попросите человека одобрить момент, который меняет деньги, данные или доверие клиента.
Уникальный run ID для каждого внешнего действия помогает легко замечать дубли. Думайте о нем как о номере квитанции, прикрепленном к send_email_A41 или refund_A41. Если workflow перезапустится, система проверит этот ID перед тем, как действовать снова. Когда она увидит тот же самый ID, она поймет, что действие уже произошло, и не станет запускать его второй раз.
Хорошие настройки по умолчанию просты. Повторяйте вызовы модели небольшое число раз. Не повторяйте автоматически платежи, письма или вебхуки. Ставьте человеческое согласование перед тем, как двинутся деньги или уйдет сообщение клиенту. После повторяющегося сбоя переводите запуск в needs_review и останавливайте его.
Это состояние остановки очень важно. Многие плохие workflow крутятся по кругу до тех пор, пока кто-нибудь не заметит это через несколько часов. Явное состояние остановки делает сбой видимым. Кто-то может проверить входные данные, исправить плохую информацию и возобновить процесс с правильного места вместо того, чтобы начинать заново.
Ошибки, которые создают скрытые сбои
Скрытые сбои начинаются тогда, когда команда относится к многошаговому процессу как к одному длинному разговору. Модель отвечает, следующий промпт использует этот ответ, и никто не сохраняет, что произошло между шагами. Когда что-то идет не так, невозможно понять, где именно модель угадала неправильно, человек изменил решение или внешняя система дала сбой. Видна только финальная путаница.
Сохраненное состояние это исправляет. Каждый шаг должен записывать, что он получил, что решил и почему двинулся дальше. Звучит скучно, но именно скучность и нужна, когда в деле деньги, данные клиентов или живая работа системы.
Еще одна частая ошибка — смешивать вывод модели с бизнес-правилами. Модель может читать письмо, классифицировать документ или писать краткое резюме. Но она не должна тихо решать ваш лимит возврата, порог согласования или то, можно ли договор отправлять на подпись. У этих правил должны быть собственные проверки. Если смешать все вместе, плохой вывод модели начнет выглядеть как политика.
Повторы причиняют вред и по-другому. Команды часто повторно запускают весь workflow после одного неудачного шага. Из-за этого можно дважды отправить одно и то же письмо, создать два тикета или снова списать деньги с той же карты. Повторяйте только неудачное состояние и только если это состояние безопасно повторять. Если оно не безопасно, остановитесь и позовите человека.
Согласования и ручные исправления тоже создают слепые зоны, если никто не оставляет заметок. Если менеджер одобряет исключение, система должна сохранить, кто одобрил его, когда и что именно изменилось. Если оператор исправляет плохой результат модели, сохраните обе версии. Без этого следа любая последующая проверка превращается в угадывание.
Проблема становится еще хуже, когда внешние действия выполняются до окончания проверки. Модель извлекает поля из заявки на закупку, а система отправляет заказ до проверки кода бюджета. Модель пишет черновик ответа клиенту, а система отправляет его до подтверждения статуса аккаунта. Как только внешнее действие сработало, откат становится быстрым и сложным.
Большинство скрытых сбоев идут по одному и тому же сценарию. В логах есть финальный результат, но нет пути к нему. Повторная попытка повторяет побочный эффект. Человек что-то меняет, а система это забывает. Предположение модели проходит как будто это правило.
Решение простое: делайте поток явным, держите аудит-след простым и делайте каждый шаг легко останавливаемым или повторяемым. Если сбой остается видимым, его можно исправить до того, как он распространится.
Быстрые проверки перед запуском
Перед тем как workflow начнет трогать деньги, сообщения или записи клиентов, проверьте, можете ли вы восстановиться после плохого шага за минуты, а не за часы. Именно здесь ломается много автоматизаций. В демо все выглядит нормально, а потом одна ошибка модели оставляет команду в догадках.
Надежная система не прячет прогресс внутри логов или промптов. Для любого запуска вы должны открывать запись и видеть текущее состояние, последний завершенный шаг и причину, по которой он двинулся или остановился. Если кто-то из вашей команды не может за несколько секунд ответить на вопрос «где это зависло?», workflow еще не готов.
Используйте короткую проверку перед релизом:
- у каждого запуска есть понятное состояние, а не просто стена событий
- человек может повторить только один неудачный шаг, не перезапуская всю задачу
- отмена запуска вызывает правила очистки, чтобы плохой вывод модели не оставлял после себя частичных изменений
- система хранит причины остановки простым языком, например тайм-аут, не прошла проверка, отсутствует согласование или повторный запрос
- любому важному внешнему действию, например отправке письма или списанию денег, поставлена защита от повторного запуска
Защита от дубликатов — это то, что многие команды пропускают. Если модель не успела ответить, ваш worker может попробовать еще раз. Если этот шаг отправляет сообщение, создает тикет или обновляет запись дважды, пользователи заметят это очень быстро. Добавьте ключ идемпотентности или другую проверку на дубликаты до того, как сработает действие.
Повторы тоже должны иметь границы. Повторяйте вызовы модели и временные сетевые ошибки. Не повторяйте автоматически шаги, где нужен человеческий выбор, например согласования, проверки на соответствие правилам или правки живой записи клиента. Помещайте такие шаги в явные состояния ожидания, чтобы люди могли их проверить.
Еще одна проверка очень помогает: вызовите сбой специально. Отклоните согласование, отключите сеть или верните плохой ответ модели. Потом посмотрите, что сделает workflow. Хорошая система чисто остановится, объяснит причину и позволит продолжить с нужного места вместо того, чтобы начинать с нуля.
Что делать дальше
Начните с процесса, который уже немного раздражает людей каждую неделю. Не выбирайте самый большой и политически чувствительный процесс в компании. Возьмите тот, где теряются детали, нужен ручной follow-up или все зависает, когда один шаг ломается.
Хорошими первыми кандидатами будут запросы на возврат, согласование смет или onboarding поставщиков. Небольшие трещины — это хорошие тестовые случаи. Они показывают, где промпт-цепочки скрывают проблемы, и дают достаточно объема, чтобы быстро заметить закономерности.
Сначала поместите весь поток на одну страницу, а уже потом пишите код. Если вы не можете описать состояния простыми словами, потом систему будет сложнее отлаживать. Назовите моменты, которые действительно важны: запрос получен, данные проверены, человек одобрил, платеж отправлен, ошибка и ожидание повтора, закрыто.
Первый пилот держите компактным. Выберите один workflow с частыми, но низкорисковыми ошибками. Нарисуйте на бумаге каждое состояние, переход, повтор и согласование. Запустите его с реальными людьми, которые могут одобрять, отклонять и эскалировать. Логируйте каждый путь сбоя, а не только успешный путь.
Логи успеха рассказывают историю о том, как все хорошо. Логи ошибок показывают, где слабая конструкция. Когда модель извлекает не ту сумму, когда API не успевает ответить или когда менеджер не успевает согласовать вовремя, вы хотите, чтобы система останавливалась в известном состоянии, а не гадала.
Сделайте пилот достаточно маленьким, чтобы один человек мог проверить его от начала до конца. Неделя чистых наблюдений лучше месяца шумного запуска. Вам не нужно автоматизировать все сразу. Вам нужно доказать, что workflow остается видимым, обратимым и спокойным под нагрузкой.
Если вам нужен внешний взгляд, Oleg Sotnikov на oleg.is работает как Fractional CTO и советник для стартапов по AI-first разработке ПО и автоматизации. Короткая проверка потока, путей отказа и плана запуска часто обходится дешевле, чем разбор сломанной автоматизации после того, как она уже начала трогать деньги, записи клиентов или production-системы.
Когда пилот работает, копируйте не только код, но и подход. Повторяемая часть — это дизайн состояний, точки согласования и правила повторных попыток.
Часто задаваемые вопросы
Почему промпт-цепочки ломаются в реальной работе?
Промпт-цепочки предполагают, что каждый шаг выполняется один раз, по порядку и с чистым входом. В реальной работе это быстро перестает работать. Люди отвечают с опозданием, API падают, а плохие данные проскакивают дальше, поэтому цепочка может продолжать движение, хотя задача уже пошла не туда.
Когда мне лучше использовать машину состояний, а не промпт-цепочку?
Используйте машину состояний, когда процесс может останавливаться, повторяться, ждать человека или обращаться к внешним системам вроде почты, платежей или CRM. Она дает каждой задаче понятное место, где можно остановиться, продолжить или зафиксировать ошибку, не гадая по логам.
Что считается состоянием в AI-рабочем процессе?
Думайте о состоянии как о текущем положении задачи, а не просто о следующем промпте. Названия вроде received, waiting_for_approval, needs_review, sent или failed сразу показывают, что произошло и что может случиться дальше.
Сколько состояний должно быть в первой версии?
Начинайте с малого. Если вы можете описать нормальный путь в пяти или шести состояниях, этого обычно достаточно для первой версии. Держите каждое состояние сфокусированным на одной задаче, чтобы можно было отследить ошибки без путаницы.
Где должны происходить повторные попытки?
Повторяйте вызовы модели и временные сетевые сбои. Не повторяйте автоматически шаги, которые уже отправили письмо, списали деньги или изменили запись. Если рискованный шаг не удался, остановите запуск и отправьте его на проверку вместо повторения действия.
Где в процессе должно стоять человеческое согласование?
Размещайте согласование прямо перед шагом, который меняет деньги, данные клиента или уровень доверия. Пусть ИИ подготовит работу, а потом дождитесь в отдельном состоянии, пока человек одобрит или отклонит ее.
Как не допустить дублирующихся писем, тикетов или платежей?
Дайте каждому внешнему действию уникальный run ID или проверку на идемпотентность. Перед отправкой письма или оформлением возврата система должна проверить, не выполнялось ли это же действие раньше, и не делать его дважды.
Что нужно логировать при каждом изменении состояния?
Для каждого перехода сохраняйте входные данные, результат, изменение состояния, отметку времени, ID задачи и причину перехода. Также фиксируйте, кто одобрил шаг, что именно пошло не так и что система пыталась сделать до остановки.
Как проверить AI-рабочий процесс перед запуском?
Перед запуском специально вызовите сбои. Отключите сеть, отклоните согласование, подайте плохой ответ модели и остановите процесс на середине. Хорошая система должна аккуратно остановиться, объяснить причину и позволить продолжить с нужного места.
Какой первый процесс лучше взять для пилота с машиной состояний?
Выберите процесс, который раздражает людей каждую неделю, но не приведет к серьезному ущербу во время пилота. Запросы на возврат, согласование смет и onboarding поставщиков хорошо подходят, потому что быстро показывают, где не хватает согласований, появляются дублирующие действия и слабо работают правила повторов.


