Машины состояний для процессов утверждения, которым команда может доверять
Машины состояний для процессов утверждения делают их проще для отслеживания, тестирования и изменения. Узнайте, как ясно моделировать состояния, повторы, исключения и откаты.
Содержание
Почему логика утверждений быстро становится запутанной
Потоки утверждений обычно начинают с простого сценария. Один человек отправляет запрос, один менеджер его утверждает, и команда двигается дальше.
Потом в дело вмешивается реальная работа. Финансы хотят проверять всё выше определённой суммы. Юристы должны смотреть некоторые контракты. Запрос может истечь, вернуться на доработку или открыться снова после изменения бюджета. Вскоре правила живут в пяти разных местах.
Один контроллер блокирует действие. Фоновая задача отправляет напоминания через два дня. Ночной скрипт закрывает старые запросы. Админский инструмент позволяет поддержке вручную "починить" зависшие записи. Каждая часть сама по себе имеет смысл, но весь процесс перестаёт быть понятным.
Именно тогда появляются пограничные случаи. Двое нажимают кнопку одновременно, и запрос утверждается дважды. Повторная попытка снова отправляет письмо после того, как запись уже продвинулась дальше. Отклонённый элемент редактируют, и он попадает в состояние, о котором никто не думал. Команда не ставила задачу создавать хаос. Правила просто тихо разошлись по разным местам.
Аудиты тоже становятся сложными. Когда кто-то спрашивает: "Почему этот платёж прошёл?", ответ часто можно найти в старых логах, истории очередей и нескольких догадках от команды. В базе данных может быть текущий статус, но не то, что происходило до этого, какое правило разрешило переход или кто его отменил.
Это усугубляется, когда бизнес меняет процесс каждый месяц. Каждое быстрое исправление добавляет ещё одно условие где-то в коде. Через некоторое время даже небольшое изменение кажется рискованным, потому что никто не доверяет, что произойдёт дальше.
Машина состояний решает это, помещая процесс в одну понятную модель. Вместо того чтобы искать по контроллерам, задачам и скриптам, команда видит все допустимые состояния, все переходы и все исключения в одном месте.
Что такое машина состояний простыми словами
Машина состояний — это простой способ описать процесс так, чтобы все могли видеть, где что находится, куда оно может пойти дальше и что должно быть верно перед переходом.
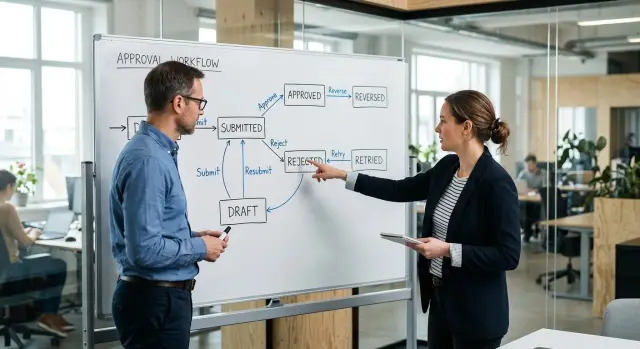
Состояние — это просто именованный момент в процессе. Для запроса на утверждение это может быть draft, submitted, approved, rejected, canceled или paid. Каждое состояние отвечает на вопрос: "Каков текущий статус?"
Переход — это разрешённый шаг из одного состояния в другое. Запрос может перейти из draft в submitted. Он может перейти из submitted в approved или rejected. Он не должен прыгать из draft прямо в paid, если ваши правила этого не разрешают.
Guard'ы — это проверки, которые разрешают или блокируют переход. Это не магия. Переход из submitted в approved может требовать проверки менеджера, ограничения по сумме или заполнения всех обязательных полей.
Проще думать так:
- Состояния — это места, где может находиться запрос.
- Переходы — это двери между этими местами.
- Guard'ы — это замки на этих дверях.
Такая структура делает процесс гораздо понятнее. Когда кто-то спрашивает: "Почему этот запрос изменил статус?" или "Почему это было заблокировано?", ответ живёт в модели, а не в пяти разных местах кода.
Разбросанные if-выражения обычно превращаются в беспорядок, потому что каждое исключение попадает в другой файл. Одно правило живёт в API, другое — в админ-панели, третье — в фоновом воркере. Через несколько месяцев никто не может уверенно объяснить весь процесс.
Машина состояний это фиксирует, делая правила видимыми и тестируемыми.
Отобразите состояния до того, как писать код
Большинство команд начинают с экранов, кнопок или названий API. Это кажется практичным, но скрывает реальный процесс. Начните с простого списка состояний. Если двое не могут согласовать текущее состояние запроса, код быстро станет грязным.
Состояние — это факт бизнеса, а не надпись в интерфейсе. "Ожидание проверки менеджера" — это состояние. "Требует внимания" — просто текст интерфейса. Вы можете потом поменять слова в приложении без изменения правил.
Запишите каждое состояние, которое может существовать в реальной жизни, включая неловкие, которые команды обычно пропускают. Все помнят approved и rejected, но часто забывают скучные промежуточные состояния и случаи отказа, которые создают тикеты в поддержку.
Полезный первый вариант может включать draft, waiting_for_review, waiting_for_more_information, failed и closed. Точные названия будут разными, но важно само правило: включите ожидание, состояния ошибки и финальные состояния, такие как approved, rejected, canceled или expired.
Дайте каждому состоянию одно небольшое предложение. Держите определение строгим. "Отправлено и, возможно, ждёт проверки финансов, если сумма велика" — это не одно состояние. Это две или три идеи, сжатые вместе. Разделите их, пока каждое состояние не станет простым для тестирования.
Полезное эмпирическое правило: если кто-то может спросить "Что может произойти дальше?" и получить один понятный набор ответов, вероятно, у вас реальное состояние. Если ответ меняется из-за скрытых условий, вы, наверное, пропустили состояние.
Сделайте это прежде, чем будете называть эндпоинты, поля в базе или вкладки страниц. Когда состояния ясны, остальное становится проще, потому что каждое действие имеет понятное начало и конец.
Определите переходы, правила и побочные эффекты
Машина состояний начинает окупаться, когда каждый переход читается как маленький контракт. draft -> submitted — это лишь метка. Полезная часть — всё вокруг неё: кто начал переход, что должно быть верно, что система изменяет и какие доказательства сохраняются в записи.
Начните с триггера. Назовите актёра простыми словами. Пользователь нажимает "утвердить". Система финансов подтверждает оплату. Планировщик помечает запрос как просроченный. Если оставить триггер расплывчатым, правила снова уйдут в случайные проверки контроллеров и одноразовые скрипты.
Затем пропишите guard-условие для перехода. Держите его коротким и тестируемым. Например: "Менеджер может утвердить только если сумма в пределах лимита, у запроса есть все требуемые документы и он всё ещё в submitted." Если правило не проходит, оставляйте текущее состояние и сохраняйте причину.
Побочные эффекты должны быть рядом с переходом, а не спрятаны где-то ещё. Когда запрос меняет состояние, система может отправить уведомление, создать бухгалтерскую запись, назначить следующего рецензента или разблокировать шаг платежа. Поместите эти действия в определение перехода, чтобы одно место рассказывало всю историю.
Обычно спецификация перехода нуждается в четырёх вещах:
- кто или что запускает переход
- что должно быть верно сначала
- что система делает в процессе перехода
- что вы сохраняете для аудита и поддержки
Данные аудита важнее, чем многие команды ожидают. Сохраняйте старое состояние, новое состояние, время, актёра, причину и любые бизнес-значения, которые объясняют решение — сумму, отдел или лимит утверждения. Если побочный эффект провалился, запишите это тоже.
Эта история экономит время позже. Когда кто-то спрашивает, почему запрос поменял статус в 16:12, поддержка не должна читать код или искать логи в трёх системах. Должна открыться одна понятная история переходов и дать ответ за секунды.
Смоделируйте повторы, таймауты и отмены
Потоки утверждений разваливаются, когда система тихо повторяет действия, ждет бесконечно или ведёт себя так, как будто прежнего решения не было. Каждый из этих случаев требует своего состояния или перехода.
Повторы не должны быть невидимыми. Если письмо об утверждении не отправилось или внешняя система отклонила обновление, переместите элемент в состояние повтора и запишите причину. Считайте попытки. Установите время следующей попытки. Остановитесь после ясного лимита. Это даёт поддержке что-то реальное для проверки, вместо расплывчатого "должно было сработать".
Таймауты требуют того же отношения. Запрос, который находится в pending_approval 12 дней, не здоров просто потому, что никто его не трогал. Перемещайте его в timed_out или overdue после заданного окна. Затем решайте, что дальше: отправить напоминание, эскалировать другому утверждающему или закрыть его.
Отмены требуют не меньшего внимания. Бюджеты меняются. Правила соответствия обновляются. Кто-то утвердил не тот запрос. Не перезаписывайте approved на rejected и называйте это исправлением. Добавьте реальный переход, например approved -> revoked или approved -> returned_for_review. История останется понятной, и аудит не превратится в детективное расследование.
Несколько решений снимут большую часть путаницы:
- Установите максимальное количество повторов для каждого типа ошибки.
- Определите окно таймаута для каждого ожидания.
- Ограничьте, кто может отменять решение.
- Решите, какие отмены требуют указания причины.
- Разделите окончательное отклонение и отправку на доработку.
Последний пункт важен. Некоторые отклонения должны завершать поток сразу, например нарушение политики или отсутствие юридического согласования. Другие должны возвращать запрос на доработку, чтобы отправитель мог исправить проблему и отправить снова. Это разные пути и их следует держать раздельно.
Простой пример: утверждение запроса на покупку
Запрос на покупку — хороший тест-кейс, потому что в одном процессе пересекаются деньги, политика и исключения.
Предположим, сотрудник хочет купить ноутбук. Каждый запрос начинается в draft, затем переходит в submitted, когда сотрудник отправляет его. Дальше менеджер сначала проверяет.
Если запрос на $800, менеджер может утвердить и перевести его прямо в approved. Если сумма $4,500, менеджер может утвердить, но запрос не завершится — он перейдёт в finance_review, потому что превышает порог компании.
Простая модель может выглядеть так:
draft->submittedsubmitted->manager_reviewmanager_review->approvedкогда сумма меньше $2,000manager_review->finance_reviewкогда сумма $2,000 или большеfinance_review->approvedилиrejected
Теперь добавьте распространённую проблему: отсутствие информации. Сотрудник забыл приложить коммерческое предложение. Менеджер не должен отклонять весь запрос, если покупка всё ещё имеет смысл. Перемещайте его в needs_info.
Это создаёт чистый путь для повтора. Сотрудник добавляет документ, затем отправляет запрос обратно в submitted или прямо в manager_review, в зависимости от ваших правил. То, что раньше было расплывчатой практикой "отправить обратно и попробовать ещё раз", становится ясным переходом.
Отмена после утверждения — ещё одно место, где команды часто хитрят с кастомными скриптами. Лучше моделировать это прямо. Если сотрудник отменяет после утверждения, но до размещения заказа, переведите запрос в cancel_requested, выполните шаги по откату, затем завершите в canceled.
Эти шаги по откату важны. Финансы могут освободить удержание бюджета, а закупки — остановить заказ. Когда вы моделируете этот путь как реальное изменение состояния, правила остаются видимыми.
Как строить это шаг за шагом
Начните с одного потока утверждений, который уже тратит время или вызывает ошибки. Выберите тот, о котором больше всего жалуются: утверждение покупок или запросы на доступ. Если пытаться смоделировать все процессы сразу, вы отстроите тот же беспорядок в более красивой диаграмме.
Разместите весь рабочий процесс на одной странице прежде, чем писать код. Назовите каждое состояние простыми словами: draft, submitted, approved, rejected, canceled, failed. Затем нарисуйте допустимые переходы между ними. Если кто-то не может указать на линию и объяснить, зачем она нужна, вероятно, этот переход не нужен.
Держите первую версию компактной. Многие команды добавляют слишком много состояний, путая состояние с побочными эффектами. Email_sent обычно не является состоянием. Waiting_for_finance_review часто — является.
Перенесите правила в одну модель
Когда карта выглядит правильно, вынесите правила из контроллеров, запланированных задач и случайных скриптов. Поместите их в одну модель рабочего процесса, где каждый переход имеет ясные проверки и чёткие результаты. Эта модель должна быстро отвечать на простые вопросы: кто может утвердить, что происходит при отклонении, когда разрешён повтор и требует ли отмена указания причины.
Затем протестируйте пути, которые обычно ломаются в реальной жизни. Счастливый сценарий прост, так что на нём не останавливайтесь. Прогоните несколько случаев намеренно: успешное утверждение, отклонение, повтор после временной ошибки и отмена после ошибочного утверждения. Если модель аккуратно справляется с ними, она достаточно сильна для первого релиза.
Сделайте изменения состояния видимыми
Логируйте каждое изменение состояния в порядке их появления. Записывайте старое состояние, новое, кто это инициировал и почему. Когда поддержке приходит тикет через два месяца, такой след аудита спасает часы работы.
Сделайте первую версию скучной. Это хорошо. Небольшая, явная модель лучше умного кода в контроллерах и даёт одно место для изменения бизнес-правил без копания по всему приложению.
Распространённые ошибки при моделировании утверждений
Команды обычно ломают потоки утверждений банальными способами. Они относятся к рабочему процессу как к нескольким полям статуса и набору if-ов. Это работает неделю. Потом исключения накапливаются, люди добавляют ручные исправления, и никто не может объяснить, почему один запрос прошёл, а другой завис.
Одна типичная ошибка — пропуск промежуточных состояний. Запрос редко прыгает чисто из draft в approved или rejected. Он может ждать менеджерской проверки, юридической проверки, недостающих документов или второго контроля после правок. Если вы пропустите эти состояния, люди запихнут логику в комментарии, флаги и побочные скрипты.
Ещё одна ошибка — прятать правила утверждения внутри фоновых задач. Ночная задача тихо эскалирует запросы. Воркеры в очереди автоотклоняют устаревшие элементы. Вебхук меняет статус после появления документа. Эти действия могут быть нормальными, но правила всё равно должны выглядеть как явные переходы. Если правило живёт только в воркере, рабочий процесс превращается в охоту на сокровища.
Прямые прыжки создают ещё больше проблем. Кто-то добавил ярлык из submitted в approved, потому что "финансы уже проверили это в другом инструменте". Полгода спустя половина проверок обходится случайно. Если есть ярлык, дайте ему имя и ограничьте, кто им может пользоваться.
Команды также путают технический сбой и бизнес-отклонение. Это разные события. Если почтовый сервис упал, запрос не провалил проверку. Если платежный API завис, утверждающий не отклонил запрос. Поместите эти случаи в отдельные состояния или пути ошибок. Иначе отчётность станет путанной, повторы будут вести себя плохо, а пользователи получат неверные сообщения.
Отмены требуют такого же внимания, как и утверждения. Многие команды добавляют reopen или undo поздно и забывают про права доступа. Могут ли любой проверяющий отменить окончательное утверждение? Только первоначальный утверждающий? Только админ с указанием причины? Если это не смоделировать ясно, люди начнут править записи вручную.
Простой тест-«нюх» помогает:
- Пользователи спрашивают поддержку, почему элемент пропустил проверку.
- Инженерам приходится читать код воркеров, чтобы объяснить решение.
- Отклонённые элементы и сбои задач имеют один и тот же статус.
- Админы меняют строки в базе, чтобы отменить решения.
- Отчёты не показывают, где запросы действительно ждут.
Если вы видите два или три из этих признаков, модель, вероятно, слишком расплывчата.
Проверки перед релизом
Если ваш рабочий процесс всё ещё зависит от племенных знаний, он не готов. Хорошая машина состояний выглядит скучной в продакшене, потому что каждый может сказать, что случилось, почему это случилось и что можно сделать дальше.
Проведите короткий обзор перед релизом.
Попросите нескольких человек назвать все состояния по памяти. Если они спорят, называется ли что-то "pending review", "waiting" или "on hold", модель всё ещё мутная.
Дайте поддержке одну зависшую запись и попросите объяснить причину простыми словами. Они должны найти состояние, провалившееся правило и следующее допустимое действие без чтения кода.
Возьмите один реальный ID запроса и воспроизведите его путь от начала до конца. Вы хотите чистую историю: кто инициировал каждый переход, когда это произошло и какое правило это позволило.
Протестируйте каждый переход сам по себе. Переход из submitted в approved должен проходить или проваливаться по понятным причинам, без зависимости от побочных эффектов предыдущих шагов.
Измените одно бизнес-правило в безопасной ветке. Если это небольшое изменение заставляет вас лазить по контроллерам, задачам, триггерам базы и вспомогательным файлам, рабочий процесс всё ещё слишком разбросан.
Небольшой пример делает это очевидным. Скажем, запрос на покупку остановился после проверки финансов, потому что сумма перешла порог. Поддержка должна увидеть, что он попал в needs_director_approval и стоял там, потому что директор ещё не решил. Им не нужно исследовать логи трёх сервисов или гадать, какой скрипт запустился ночью.
Ещё одна проверка: можете ли вы ясно объяснить отмены? Если утверждение отменили, рабочий процесс должен показать точный обратный переход или компенсирующее действие. "Мы просто сбросили" — тревожный сигнал.
Что делать дальше
Начните с малого. Выберите один поток утверждений, которым команда пользуется каждую неделю, и прорисуйте его на бумаге прежде, чем трогать код. Утверждения расходов, запросы на покупку и запросы на возврат — хорошие кандидаты, потому что путь легко распознать, а исключения обычно скрыты.
Запишите реальные состояния сначала. Затем добавьте все допустимые переходы между ними, кто может инициировать каждый переход и что должно быть верно перед ним. Если двое описывают один и тот же шаг по-разному, вы, вероятно, нашли баг до того, как он попал в прод.
Хорошая первая версия проста:
- выберите один живой рабочий процесс, не теоретический
- найдите старые скрипты, ветки в контроллерах и ручные шаги вокруг него
- отметьте каждое скрытое решение, повтор, таймаут и отмену
- добавьте заметку аудита к каждому переходу, а не только к финальному утверждению
- протестируйте несколько мрачных случаев, например дублированные отправки или поздние отклонения
Эти заметки аудита важнее, чем многие думают. Когда кто-то спрашивает: "Почему этот запрос вернулся на проверку?", ответ должен лежать прямо в переходе — с меткой времени и актёром. Это экономит часы позже.
Также полезно просмотреть «клей» вокруг процесса. Диаграммы утверждений часто выглядят чистыми, в то время как продакшен остаётся грязным, потому что реальные правила скрыты в задачах по расписанию, админ-панелях и одноразовых скриптах. Вынесите эти решения в модель, чтобы рабочий процесс жил в одном месте.
Если вашей команде нужен второй взгляд прежде, чем строить вокруг этого много, Oleg Sotnikov на oleg.is работает как Fractional CTO и стартап-советник и помогает компаниям превращать разбросанные бизнес-правила в системы, которые легче поддерживать. Иногда короткий обзор достаточно, чтобы заметить пограничные случаи, которые команда привыкла игнорировать.
Одной прорисованной карты на этой неделе достаточно. Если эта модель понятна, следующая будет гораздо проще.
Часто задаваемые вопросы
Какая проблему решает машина состояний в процессе утверждения?
It puts the whole approval process in one model. Your team can see every allowed state, every move, and every rule without digging through controllers, jobs, and manual scripts.
Нужна ли машина состояний для простого рабочего процесса?
Not always. If one person submits and one person approves, simple code may work. Once you add finance checks, retries, timeouts, or reversals, a state machine usually saves time and prevents messy fixes later.
Что считается настоящим состоянием?
A real state describes a clear business fact, like draft, manager_review, or needs_info. If people can name one clear set of next actions from that point, you likely have a real state.
Чем состояние отличается от побочного эффекта?
A state tells you where the request sits right now. A side effect is something the system does during a move, like sending an email, creating an accounting entry, or assigning the next reviewer.
Стоит ли явно моделировать повторы и таймауты?
Yes, when they change how the team handles the request. If a failed delivery needs another attempt, store that as an explicit retry path. If a request waits too long, move it to overdue or timed_out instead of leaving it stuck in a vague pending status.
Как отличать отклонение от отправки на доработку?
Treat them as different paths. A final rejection ends the flow. A return for edits sends the request back so the user can fix something and submit again. If you merge those into one status, support and reporting get messy fast.
Что нужно сохранять для аудита?
Save the old state, the new state, who triggered the move, when it happened, and why it happened. Store business details that explain the decision too, such as amount, approval limit, or missing documents.
Как избежать двойного утверждения и дублирующих побочных эффектов?
Put every state change behind one transition rule and check the current state before you move it. Add idempotent actions for things like emails and payments so a retry does not repeat work after the request already moved forward.
Как начать, не переделывая всё сразу?
Start with one workflow that already causes mistakes or delays. Map the states on one page, add the allowed moves, then pull hidden rules out of controllers, jobs, and scripts into one model. Test the awkward cases first, not just the happy path.
Когда стоит привлекать внешнюю помощь для рабочих процессов утверждения?
Bring in help when small rule changes feel risky, support cannot explain why requests moved, or admins fix records by hand. A short workflow review often finds missing states, hidden shortcuts, and audit gaps before they turn into bigger problems.


