Маршрутизация моделей по типу задач, чтобы сократить расходы на ИИ для команд
Узнайте, как маршрутизация моделей по типу задач помогает командам назначать поддержку, кодирование, извлечение и суммаризацию самой дешёвой модели, которая всё ещё справляется.
Содержание
Почему один дефолт‑модель тратит деньги зря
Большинство команд начинают с одной модели для всего, потому что это просто. Они подключают её к поддержке, чату, внутренним инструментам и нескольким автоматизациям, а затем двигаются дальше. Это работает какое‑то время. Потом счёт растёт быстрее, чем ценность.
Проблема проста. Разным задачам нужны разные уровни рассуждения. Поиск возврата, короткая правка письма или чистая задача по извлечению данных не требуют той же модели, которой вы бы доверили рискованное изменение кода или сложное продуктовое решение. Если каждый запрос идёт к самой сильной модели, вы платите премию за рутинную работу.
Потери проявляются быстро. Простые запросы сжигают дорогие токены. Быстрые задачи ждут медленных ответов. Команды перестают тестировать идеи, потому что каждый эксперимент стоит дороже. Финансы начинают видеть в ИИ растущую статью расходов, а не полезный инструмент.
Команды поддержки обычно ощущают это первыми. Они обрабатывают сотни коротких запросов, многие из которых повторяют одни и те же паттерны. Если каждый идёт к топовой модели, затраты растут, даже когда ответы остаются базовыми. У задач по извлечению та же проблема. Если нужно просто вытащить имена, даты или номера заказов из текста, премиальная модель часто избыточна.
Кодирование другое, но и там не каждая задача заслуживает одинакового подхода. Написание regex, создание небольшого unit‑теста и ревью рискованной миграции — это разные работы. Отношение к ним как к одной и той же — источник утечки денег.
Вот почему маршрутизация по типу задач важна. Вопрос полезности звучит не «Какую модель мы используем?», а «Что этой задаче действительно нужно?». Как только команды понимают это, выбирать самую дешёвую модель, которая всё ещё справляется, становится гораздо проще.
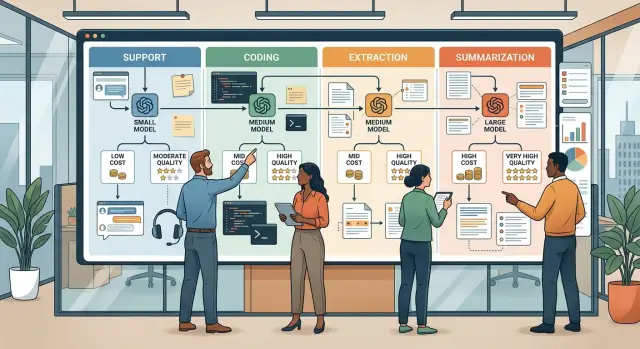
Что на самом деле означают поддержка, кодирование, извлечение и суммаризация
Команды обычно начинают экономить, когда перестают думать в терминах одного общего рабочего процесса ИИ и начинают думать в терминах типов задач.
Работа поддержки — это понятная помощь клиентам. Кто‑то спрашивает, почему платеж не прошёл, как сбросить пароль или идёт ли ещё возврат. Модели здесь не нужны свежие инсайты. Нужно прочитать сообщение, следовать правилам компании, держать спокойный тон и понимать, когда передать дело человеку.
Кодирование несёт больше риска. Слабый ответ в поддержке может создать ещё один тикет. Слабый кодовый ответ может сломать сборку, провалить тесты, замедлить приложение или открыть уязвимость. Поэтому команды обычно дробят кодинг на мелкие задачи и добавляют этапы ревью, прежде чем доверять выводу.
Извлечение — это работа со структурированными данными. Вход может быть грязным: письма, счета, PDF, чат‑логи или текст формы. Выход должен быть фиксированным и аккуратным: имя клиента, номер заказа, дата, сумма, статус. Стиль здесь почти не важен. Важны точность и последовательность.
Суммаризация — снова другое. Модель берёт длинный текст и делает его коротким, не теряя сути. Это может быть превращение стенограммы встречи в список действий или сжатие длинной цепочки поддержки в короткий заметку по делу. Обычно тут требуется меньше рассуждений, чем в кодинге, но всё ещё нужна оценка: что оставить, что убрать и что обязано остаться точным.
Когда команда помечает работу таким образом, выбор модели упрощается. Вы уже не ищете одну идеальную модель. Вы подбираете для каждой задачи самую дешёвую модель, которая делает её хорошо.
Как команды выбирают самую дешёвую модель, которая всё ещё проходит
Команды, которые контролируют расходы на ИИ, обычно оценивают каждую модель по трём вещам: качество, скорость и стоимость на задачу. Дешёвая модель, которая ошибается в фактах, не годится. Модель, которая красиво пишет, но слишком медленна для живой поддержки, тоже не годится. Лучший выбор — самая дешёвая модель, которая соответствует стандарту для конкретной задачи.
Хорошие команды часто начинают ниже, чем ожидают. Они пробуют самую дешёвую модель, которая может подойти, затем тестируют её на реальных подсказках, прежде чем сделать дефолтом. Это важно, потому что экономия появляется только тогда, когда вы перестаёте считать, что каждый запрос нуждается в самой сильной модели.
Простой процесс оценки подойдёт большинству команд:
- Определите, что означает «проходит» для каждой задачи.
- Тестируйте на реальных подсказках от вашей команды, а не на демо от вендора.
- Сравнивайте частоту отказов, задержку и стоимость вместе.
- Переходите на более сильную модель только когда дешёвая слишком часто не проходит.
Реальные подсказки меняют всё. Команде поддержки может быть важен правильный порядок возврата денег, спокойный тон и ответы меньше чем за шесть секунд. Команда разработчиков может принять более медленный ответ, если код запускается и соответствует стилю репозитория. Для извлечения может требоваться почти идеальная точность полей, в то время как для сводки допустимы разные формулировки, если факты остаются.
Поэтому один общий бенчмарк обычно не работает. Каждый рабочий процесс требует своего небольшого набора тестов из реальных тикетов, документов и кодовых запросов.
Практическое правило помогает держать расходы под контролем: повышайте модель только там, где это действительно нужно. Если дешёвая модель проходит 80% запросов, держите их там. Направляйте более сложные 20% вверх. Такое изменение часто быстро сокращает расходы, не понижая качество, которое люди действительно видят.
Как команды поддержки маршрутизируют запросы
Большинство тикетов поддержки не требуют самой крупной модели. Сброс пароля, сроки доставки, лимиты аккаунта и базовые вопросы «как сделать» обычно подходят для маленькой быстрой модели, которая отвечает за секунды и стоит недорого.
Дорогой маршрут начинается, когда тикет может повлиять на доверие или деньги. Споры по биллингу, запросы на возврат, вопросы по контрактам, исключения из политики или сообщения, полные гнева и неясных фактов, требуют больше внимания. Более сильная модель обычно лучше обрабатывает длинные переписки и реже пропускает деталь, спрятанную в истории сообщений.
Это работает только если у всех маршрутов одинаковые правила. Тон, правила эскалации, ограничения по приватности и правила отказа должны храниться в одном общем наборе инструкций. Тогда модель меняется только когда меняется задача или уровень риска. Клиенты не должны чувствовать, что они разговаривают с двумя разными компаниями.
Простой шаблон триажа часто достаточен. Короткие FAQ‑вопросы и вопросы про статус заказа идут к маленькой модели. Тикеты, связанные с биллингом, политикой, возвратами или доступом к аккаунту, идут к более сильной. Если ответ выглядит неуверенным, система либо эскалирует к человеку, либо повторяет запрос уже на сильной модели.
Команды получают лучшие результаты, когда еженедельно просматривают промахи. Смотрите на ответы, которые вызвали повторные тикеты, возвраты или ручные исправления. Если дешёвая модель постоянно сбоит на одном паттерне, переведите этот паттерн на более сильный маршрут или ужесточите подсказку.
Так выглядит хорошая маршрутизация в поддержке. Используйте дешёвый маршрут, когда задача ясна. Платите больше только когда стоимость ошибки выше, чем дополнительные токены.
Как кодирование обычно делится между моделями
Кодированию не нужна одна модель для каждого шага. Команды обычно переплачивают, когда отправляют каждый запрос по коду в самую сильную модель, даже если задача мала.
Лучшее разделение простое. Используйте сильную модель для нового кода, сложных рефакторингов и багов, требующих реального рассуждения. Если сервис падает только при нагрузке или миграция затрагивает несколько частей приложения, более способная модель часто оправдывает свою цену.
Используйте дешёвую модель для узких задач. Хорошие примеры: написание unit‑тестов по существующему коду, обновление небольшой функции, исправление простого type‑ошибки или изменение копирайта в UI‑файлах. Эти задачи всё ещё требуют ревью, но редко требуют глубокого рассуждения.
Запросы на объяснение должны идти по отдельному пути от изменений кода. Если разработчик спрашивает «Объясни этот stack trace» или «Кратко опиши, что делает этот файл», часто достаточно низкозатратной модели, потому что никто не собирается вставлять ответ прямо в прод.
Маршрут должен зависеть меньше от того, кто спросил, и больше от того, что модель должна выдать.
Одно правило важнее выбора модели: весь сгенерированный код должен проходить проверки после генерации. Линтеры, тесты, сборка и код‑ревью ловят слабые ответы до продакшна. Именно здесь появляется большая часть экономии. Дешёвая модель становится гораздо полезнее, когда вокруг неё выстроен строгий рабочий процесс.
Тот же подход встречается в реальных AI‑first инженерных настройках. Oleg Sotnikov, в своей работе Fractional CTO на oleg.is, строит окружения разработки с автоматизированным ревью кода и интеллектуальным тестированием. Принцип тот же: сгенерировать, проверить и смержить только то, что проходит.
Маленькая команда может использовать сильную модель для исправления сложной ошибки с кэшем, а для генерации тестов и уборки комментариев — более дешёвую. Один и тот же репозиторий, один и тот же спринт, разная цена для разной работы.
Как извлечение и суммаризация ломаются по‑разному
Извлечение вытаскивает точные факты в фиксированные поля. Суммаризация сжимает смысл. Они звучат похоже, но ломаются по‑разному, поэтому не должны использовать одну дефолтную модель.
Извлечение часто хорошо работает на меньшей, дешёвой модели, особенно если вход чистый и повторяемый. Счета, формы заказов и стандартные логи поддержки — хорошие примеры. Если структура предсказуема, маленькая модель может с низкой стоимостью вытянуть даты, суммы, имена, ID и типы проблем.
Это работает, только если формат остаётся жёстким. Команды должны валидировать каждый ответ по схеме и сравнивать выборочные выходы с реальными записями. Если модель меняет имена полей, пропускает значения или добавляет болтливый текст вокруг результата — она провалилась.
Суммаризация менее строгая. Сводка может использовать разные слова и всё равно быть хорошей, что делает оценку сложнее. Часто нет единственно правильного вывода. Команды должны проверять несколько простых вещей: сохранила ли сводка факты, не вырезано ли что‑то важное, не придумала ли модель утверждений, которых не было в источнике, и достаточно ли коротка она для рабочего процесса.
Разнообразие документов меняет маршрут для обеих задач. Чистая форма легко поддаётся извлечению. Грязная цепочка писем, отсканированный PDF или длинный контракт с необычными разделами часто требуют более сильной модели. То же самое для суммаризаций, влияющих на реальные решения, где упущенная деталь создаст дополнительную работу.
Метрики должны соответствовать задаче. Для извлечения отслеживайте пропущенные поля, неправильные метки, лишний текст и записи, отправленные на ручную проверку. Для суммаризации отслеживайте упущения, вымышленные детали и слишком длинные или не по сути сводки.
Это одно из самых очевидных мест для экономии. Держите дешёвые модели на чистом захвате полей. Переводите выше только если документ грязный, схема ломается или сводка требует больше суждения.
Простой пример от небольшой команды
12‑членная SaaS‑команда обрабатывает около 600 тикетов поддержки в неделю, пишет релиз‑ноты каждую пятницу и обрабатывает 900 счетов в месяц. Несколько месяцев они отправляли всё в одну большую модель, потому что так казалось безопаснее. Система работала, но счёт рос, а большинству задач не требовалось столько рассуждений.
Они перешли на маршрутизацию по задачам. Тикеты поддержки направили к маленькой чат‑модели для типичных вопросов по биллингу, логину и настройке. Релиз‑ноты шли на среднюю модель, которая превращала грубые внутренние заметки в понятные обновления. Счета шли в небольшую модель извлечения, которая вытягивала имя поставщика, дату, сумму и налог в фиксированные поля. Большая модель оставалась запасной для неясных тикетов, странных макетов счетов или отсутствующего продуктового контекста.
Они также ввели одно правило эскалации. Если первая модель показала низкую уверенность, оставила поля пустыми или получила «палец вниз» от человека, система повторяла запрос на более крупной модели. Команда всё ещё проверяла всё, что выходит к клиенту.
Через три недели картина стала очевидной. Примерно 82% тикетов поддержки оставались на маленькой модели. Релиз‑ноты требовали запасной вариант только когда инженеры писали очень расплывчатые заметки без деталей. Счета оставались на маршруте извлечения, если только поставщик не присылал грязный скан PDF.
Уровень качества не упал. Время первого ответа осталось прежним. Релиз‑ноты всё ещё требовали одного прохода редактора. Финансы заметили ту же частоту ошибок, а затем чуть меньшую после того, как команда добавила несколько шаблонов для счетов.
Счёт изменился быстро. Поскольку до дорогой модели доходили только сложные случаи, общие затраты упали примерно на 45% за месяц. Ничего хитрого — команда просто сопоставила каждую задачу с самой дешёвой моделью, которая могла её выполнить, и оставила одну сильную опцию для случаев, когда правило ломалось.
Как настроить маршрутизацию без избыточной сложности
Большинству команд не нужен сложный роутер с первого дня. Нужен небольшой тест, который соответствует реальной работе и показывает, где дешёвая модель подходит.
Начните с того, что соберите неделю реальных подсказок и разложите их по простым корзинам: ответы поддержки, помощь в коде, извлечение данных и сводки. Если какая‑то корзина почти пустая, объедините её или не трогайте, пока она не вырастет.
Дальше дайте каждой корзине одно правило приёма. Держите его простым. Черновик поддержки должен следовать политике и звучать спокойно. Результат извлечения должен вернуть правильные поля. Сводка должна сохранить решения и действия. Помощь по коду должна компилироваться или, по крайней мере, не делать очевидно плохих изменений.
Затем прогоните тот же набор через две‑три модели. Вам не нужен огромный бенчмарк. 30–50 примеров на корзину обычно хватает, чтобы заметить проблемы. Сравните стоимость, скорость и частоту ошибок бок о бок.
После этого определите один маршрут по умолчанию, один резервный и одного владельца ревью. Небольшая модель может делать первый проход для распространённых тикетов или коротких сводок. Если подсказка длинная, грязная или рискованная — отправляйте на более сильную модель. Назначьте одного человека, который каждую неделю будет просматривать промахи и корректировать маршруты по мере необходимости.
Наконец, пропишите точные причины, по которым запрос должен подняться. Не оставляйте это на интуицию. Производственные изменения кода, споры по возвратам, отсканированные документы с плохим текстом и сводки длинных встреч с множеством решений — все это ясные примеры.
Небольшая команда может сделать всё это в таблице, прежде чем писать какую‑либо автоматизацию. Это часто умнее: вы увидите, где падает качество, где растут расходы и какие задачи действительно заслуживают дорогую модель.
Ошибки, которые возвращают расходы назад
Самый быстрый способ тратить деньги зря — судить модель по одному удачному демо. Удачный результат почти ничего не говорит о поведении модели при 500 ответах поддержки, 200 задачах извлечения или неделе кодирования. Командам нужны показатели прохождения, частота отказов, количество повторов и среднее использование токенов для каждой задачи.
Ещё одна распространённая ошибка — применять одно и то же требование к качеству для очень разных задач. Ответ в поддержке может быть кратким, вежливым и в основном корректным. Изменение кода требует гораздо более жёстких проверок. Извлечение заботится только о структурной точности. Если смешать всё это, самая сильная модель начнёт выглядеть как единственно безопасный вариант, даже если это не так.
Размер подсказки тихо толкает счёт вверх. Ретраи тоже. Как и запросы на длинные ответы, когда можно обойтись коротким. Многие команды смотрят на цену за токен и пропускают более важную проблему: слабая логика маршрутизации шлёт простую сводку через огромную подсказку, вызывает два ретрая и генерирует тысячу слов, которые никому не нужны.
Рискованные работы всё ещё требуют человеческой проверки, даже если модель выглядит хорошо на тестах. Сводки контрактов, production‑код, решения по возвратам и всё, что связано с соответствием требованиям, не стоит отправлять прямо пользователям или системам без проверки. Пропустите ревью после нескольких удачных прогонов — и уборка обычно стоит дороже, чем сэкономленные токены.
Правила маршрутизации устаревают. Модели меняются, цены меняются, ваша работа меняется. Поток поддержки, который три месяца назад требовал среднюю модель, теперь может проходить на более дешёвой. Кодовый поток может потребовать более сильной модели по мере усложнения базы кода.
Лёгкий ежемесячный обзор обычно достаточен. Перепроверяйте каждый маршрут на фиксированной выборке. Отслеживайте ретраи, длину подсказок и длину вывода по типам задач. Держите отдельные правила приёма для поддержки, кодирования, извлечения и суммаризации. Оставляйте человеческое одобрение для работ, которые могут причинить реальный вред. Убирайте маршруты, которыми никто не пользуется или которые слишком часто падают.
Команды, которые так делают, обычно тратят меньше, не снижая планку качества. Те, кто этого не делает, часто винят цены моделей, хотя настоящая проблема — слабая дисциплина маршрутизации.
Перед масштабированием
Маршрутизация может выглядеть дешёвой на бумаге и всё равно жечь деньги в ежедневной эксплуатации. Ретраи, сломанные форматы и медленные ответы быстро стирают экономию.
Прежде чем развернуть систему для большего числа пользователей, протестируйте её на нормальной нагрузке хотя бы неделю, а не на чистом демо. Реальный трафик показывает, где дешёвая модель держится, а где тихо создаёт дополнительную работу.
Сначала проверьте процент успешных проходов. Если самая дешёвая модель выполняет задачу достаточно часто без второго прохода — оставляйте её. Если люди постоянно перезапускают одни и те же запросы, это уже не дешёво.
Проверьте соответствие формату. Модель, возвращающая неправильную JSON‑форму, пропускающая поля или добавляющая лишний текст, кладёт работу на парсеры и сотрудников.
Проверьте время ожидания. Низкий счёт мало помогает, если ответы поддержки задерживаются или внутренний инструмент становится настолько медленным, что люди перестают им пользоваться.
Также посмотрите, где скапливаются ошибки. Часто одна категория задач создаёт большинство проблем: длинные ветки поддержки, грязное извлечение или изменения кода с неясным контекстом. Наконец, следите за размером подсказок. Подсказки со временем растут, когда люди добавляют правила и примеры. Расходы тихо растут, и никто этого не замечает, пока счёт не подскакивает.
Карточка оценки не должна быть сложной. Отслеживайте процент прохождений, процент исправлений, задержку и среднее количество токенов на запрос для каждого типа задачи. Если маршрут не проходит по двум из четырёх показателей — меняйте его до роста трафика.
Что делать дальше
Начните с малого. Выберите один поток, который уже стоит слишком дорого — например длинные ответы поддержки или генерацию кода — и отслеживайте его две недели. Измерьте стоимость на задачу, процент прохождений и сколько раз человек исправляет результат.
Этот короткий тест обычно решает спор быстрее, чем месяц дебатов. Команды часто обнаруживают, что одна модель вполне справляется с лёгкой работой, а сильная модель нужна только для пограничных случаев.
Держите правила простыми. Если никто в команде не может объяснить логику маршрутизации за одну минуту, она, вероятно, слишком запутана.
Перед добавлением моделей пропишите порог приёма простыми словами. Черновик поддержки может считаться пройденным, если он корректен, вежлив и требует меньше минуты правки. Задача извлечения может проходить только если поля совпадают с источником и ничего не пропущено.
Простой следующий шаг: выберите один дорогой рабочий поток, запустите текущую модель и одну более дешёвую бок о бок на две недели, оцените результаты по письменному порогу и направляйте только те задачи, где дешёвая модель явно проходит.
Не гонитесь за мелкой экономией с помощью сложных правил. Экономия нескольких центов не стоит дополнительных проверок, сломанной логики или путаницы в команде.
Если вашей команде нужна помощь с настройкой, Oleg Sotnikov на oleg.is работает со стартапами и малыми компаниями по AI‑first рабочим процессам, инфраструктуре и практической маршрутизации моделей. Внешний аудит полезен, когда расходы растут, качество кажется неравномерным или никто не может договориться, какая модель должна обрабатывать какую задачу.
Лучший следующий шаг обычно скучный: протестируйте один поток, держите правило простым и заранее опишите, что значит «достаточно хорошо», прежде чем расширять.
Часто задаваемые вопросы
What is model routing by task type?
Это означает, что вы не отправляете все запросы в одну модель. Вы подбираете для каждой задачи самую дешёвую модель, которая всё ещё соответствует вашему порогу качества, а более сложные или рискованные случаи направляете к более сильной резервной модели.
Why does one default model usually waste money?
Потому что простые задачи начинают использовать дорогие токены. Кроме того, вы замедляете быструю работу и делаете небольшие эксперименты дороже, чем нужно.
Which tasks usually fit a cheaper model?
Короткие ответы в поддержку, базовые правки, простые сводки и чистое извлечение полей часто подходят для более дешёвой модели. Узкие задачи по кодированию — такие как маленькие тесты, правки копирайта или простые исправления типов — тоже могут туда подойти, если у вас есть проверки, которые ловят ошибки.
When should we use a stronger model instead?
Перенаправляйте работу вверх, когда ошибка может стоить денег, доверия, безопасности или большого количества исправлений. Споры по оплате, решения по возврату, грязные документы, рискованные изменения кода и длинные ветки с неясным контекстом обычно требуют большей мощности модели.
How do we test if a cheaper model is good enough?
Возьмите 30–50 реальных примеров для каждой задачи и напишите простое правило приёма. Затем сравните частоту прохождений, скорость, количество ретраев и стоимость за задачу — и оставляйте дешёвую модель только если она стабильно проходит по критериям.
Should support teams use more than one model?
Да. Для поддержки направляйте распространённые вопросы вроде сброса пароля или статуса заказа к маленькой быстрой модели. Для биллинга, политик, возвратов, доступа к аккаунту и агрессивных или неясных тикетов используйте более сильную модель или человека.
How should we split coding tasks across models?
В кодировании разделяйте задачи по риску, а не по должности. Используйте сильную модель для нового кода, сложных багов и рефакторинга, и более дешёвую — для узких правок, черновиков тестов, объяснений и мелких фиксов, которые ваша система сборки и ревью может проверить.
Can small models handle extraction and summarization?
Да, если входные данные остаются чистыми, а формат вывода — строгим. Малые модели часто хорошо работают с счетами, формами и короткими сводками, но грязные сканы, длинные контракты и суммаризации, где важны решения, обычно требуют более сильной модели.
Do we still need human review?
Да. Оставьте людей в цикле для production‑кода, решений по возвратам, суммаризации контрактов, работ, связанных с соответствием требованиям, и всего, что прямо влияет на пользователей или может нанести реальный вред.
What is the simplest way to start model routing?
Начните с одного дорогого рабочего потока и параллельно запустите текущую модель и одну более дешёвую в течение двух недель. Отслеживайте частоту прохождений, количество исправлений, задержки и потребление токенов, и оставляйте дешевый маршрут только там, где он явно работает.