Маршрутизация алертов Grafana по командам и сервисам, чтобы убрать шум
Узнайте, как настроить маршрутизацию алертов в Grafana по командам и сервисам, чтобы каждый сигнал попадал к нужному владельцу, снижал шум в чатах и не пропускал инциденты.
Содержание
Почему одна общая комната для алертов перестаёт работать
Когда все алерты падают в одну общую комнату, люди перестают читать их внимательно. Команда платежей видит предупреждения о кэше, который ей не принадлежит. Бэкенд-команда получает пинги из-за всплесков на CDN, которые она не может исправить. Через несколько дней канал становится просто фоном.
Реальный инцидент легко теряется среди обычных уведомлений. Скачки CPU, предупреждения о диске, повторные попытки заданий, сообщения из тестовой среды и низкоприоритетные проверки всё сваливаются в одну кучу. Люди не понимают, что нужно исправлять прямо сейчас, а что может подождать.
И они реагируют вполне нормально. Они отключают звук, гасят уведомления или бегло просматривают только знакомые имена сервисов. Это логично, когда большая часть сообщений им не нужна. Но из-за этого появляется слепое пятно: тот самый алерт, который должен разбудить человека, стоит рядом с горой шума.
Общая комната для алертов ещё и скрывает проблемы с ответственностью. Если алерт принадлежит «всем», значит, обычно он не принадлежит никому. Один инженер думает, что за него отвечает команда базы данных. Команда базы данных считает, что что-то изменили в приложении. Пока они это выясняют, пользователи продолжают ловить ту же ошибку.
Такой паттерн заметить легко:
- Канал весь день выглядит занятым, но по немногим алертам действительно есть реакция.
- Команды всё время спрашивают: «Кто за это отвечает?»
- Люди воспринимают алерты как фоновый шум, а не как сигнал.
- Серьёзные проблемы дольше доходят до нужного человека.
Эта задержка накапливается. Пять или десять лишних минут могут показаться ерундой, но именно они превращают небольшую проблему сервиса в заметный для клиентов простой. Это ещё и выматывает людей. Дежурства становятся тяжелее, когда инженерам сначала приходится отсеивать шум, а уже потом решать саму проблему.
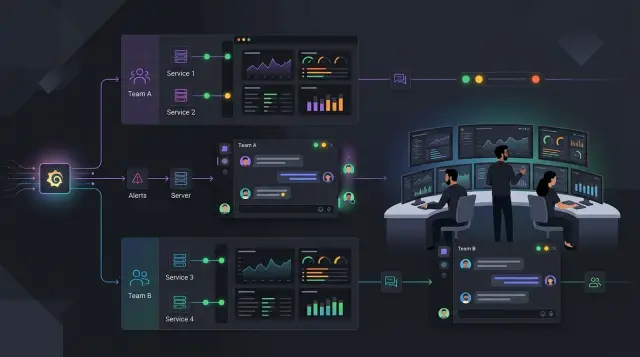
Вот почему маршрутизация алертов в Grafana становится важной. Отправлять всё в одну комнату кажется простым, пока команда маленькая. Но это перестаёт работать, когда у вас несколько сервисов, несколько владельцев и разный уровень срочности. Понятная маршрутизация убирает шум, потому что каждая команда видит только те алерты, на которые она действительно может повлиять.
Сначала определите ответственность, потом трогайте Grafana
Маршрутизация алертов в Grafana работает только тогда, когда карта ответственности понятна. Если никто не может ответить на вопрос «Кто отвечает за этот сервис в 2 часа ночи?», алерт всё равно окажется не там, даже при идеальных ярлыках и политиках.
Начните с простого списка сервисов. Сделайте его коротким и конкретным. «Backend» — слишком размыто. А вот «Billing API», «customer web app», «Redis cache» и «PostgreSQL cluster» уже лучше: с ними можно работать, не гадая.
Обычной таблицы достаточно. Для каждого сервиса запишите команду, которая занимается повседневными исправлениями, человека или ротацию, которые дежурят в выходные и праздники, общие системы, от которых он зависит, и команду, которая принимает финальное решение во время инцидента между несколькими командами.
Запасной владелец важнее, чем думает большинство команд. Многие схемы алертов выглядят нормально во вторник днём, а потом разваливаются в праздник, потому что обычный владелец не на связи и никто не знает, кто должен подхватить. Выберите один запасной путь и зафиксируйте его. Если запасной человек меняется каждую неделю, отправляйте алерты на on-call-ротацию, а не на конкретного человека.
Для общих систем нужны явные владельцы
Именно общие системы создают больше всего шума, потому что на них завязаны сразу несколько команд, но ни одна не чувствует себя полностью ответственной. Базы данных, кластеры Kubernetes, CI runners, ingress и системы идентификации обычно попадают именно сюда.
Назначьте каждой общей системе понятного основного владельца. Потом решите, кого подключать вторым. Если за PostgreSQL отвечает команда базы данных, команды приложений не должны получать каждый низкоуровневый алерт по БД. Им нужны только те уведомления, которые затрагивают их сервис или требуют действий с их стороны.
Именно здесь растущие компании часто застревают. Небольшая команда может хорошо управлять большой инфраструктурой, но только если ответственность чётко описана и записана. Одних инструментов обычно меньше, чем кажется, если карта ответственности остаётся размытой.
Заранее решите, что меняется при межкомандном инциденте
Некоторые инциденты начинаются в одном месте и быстро расходятся. Сбой очереди может за несколько минут ударить по биллингу, почте и внутренним инструментам. Заранее решите, кто ведёт инцидент, кто помогает и когда проблема переходит из канала сервиса в канал платформы или руководства.
Для этого не нужен длинный регламент. Часто хватает одного правила передачи. Например, если затронуто две команды и проблема длится больше 15 минут, владелец платформы координирует действия, а каждый владелец сервиса сообщает о влиянии в своём канале. Такие простые правила быстро убирают путаницу.
Группируйте сервисы так, как люди их понимают
Люди реагируют быстрее, когда названия алертов совпадают со словами, которые они уже используют каждый день. Если команда говорит в чате и тикетах «checkout», «admin portal» или «customer API», используйте эти же названия и в Grafana. Не придумывайте таксономию, которая понятна только внутри мониторинга.
Это важно, потому что когда алерт попадает не в ту комнату, люди сначала тратят время на то, чтобы расшифровать название сервиса, а потом ещё и на поиск владельца. Один раз такая задержка незаметна. В 2:30 ночи она ощущается совсем по-другому.
Хорошая группа обычно соответствует сервису, который люди узнают, а не каждой мелкой детали внутри него. Такие широкие категории, как customer web app, billing and payments, internal admin tools, data pipeline и shared infrastructure, легче маршрутизировать и проще потом проверять. И они дольше остаются актуальными. Маленькие компоненты меняются постоянно. А сервис, который видит клиент, обычно остаётся узнаваемым.
Отделяйте внешние сервисы от внутренних инструментов как можно раньше. Ошибка входа в публичном приложении — это не то же самое, что падение отчётной задачи во внутреннем back-office-инструменте. Оба случая могут быть важными, но им не нужна одинаковая срочность, одна и та же комната и один и тот же путь дежурства.
Именно с детализацией у команд чаще всего начинаются проблемы. Один маршрут на каждый микросервис звучит точно, но очень быстро превращается в обслуживание, которое никому не хочется поддерживать. Если десять маленьких сервисов обслуживают один пользовательский сценарий, объединяйте их вокруг этого сценария, если только одному из них действительно не нужен другой владелец, другой уровень срочности или другой способ реакции.
Например, «checkout» — лучший групповой маршрут, чем разнесение каждого платёжного воркера, налогового модуля и отправителя чеков по отдельным путям. Если не проходит задача резервного копирования базы данных, её можно отнести к «shared infrastructure», потому что владелец и реакция здесь другие.
Маршрутизация алертов в Grafana работает лучше всего, когда группы совпадают с тем, как люди думают во время инцидента. Если новый инженер может прочитать алерт и сразу понять, куда он попадёт, не открывая схему, значит, структура, скорее всего, выбрана правильно.
Стройте политики уведомлений по шагам
Хорошая маршрутизация алертов в Grafana начинается с ярлыков, а не с точек контакта. Если у алерта нет понятной ответственности, Grafana может только гадать, куда его отправить, а догадки и создают шумные комнаты.
Сначала добавьте к каждому правилу алерта три ярлыка: team, service и severity. Пусть значения будут простыми. platform, billing-api и critical работают лучше, чем хитрые названия, которые люди по-разному трактуют в 2 часа ночи.
Потом создайте точки контакта для тех мест, которые люди уже и так проверяют. Большинству команд хватает чата для обычных алертов, почты для низкосрочных сообщений и пейджинга для инцидентов, где нужна быстрая реакция. Если две команды всё ещё делят одну общую комнату, сначала разделите именно её, иначе правила маршрутизации останутся запутанными.
Хорошо работает простой порядок. Сначала сопоставляйте team, чтобы ответственность оставалась ясной. Потом уточняйте service внутри этой команды, если одна команда владеет несколькими системами. И уже потом смотрите на severity, чтобы в пейджер попадали только серьёзные алерты. Всё, где не хватает ярлыков, должно идти по одному маршруту по умолчанию.
Этот default route важнее, чем кажется. Новые алерты часто приходят без ярлыков, особенно если кто-то копирует старое правило и забывает его отредактировать. Отправляйте такие алерты в общий канал triage или в общую почту и просите одного человека проверять их каждый день, пока ярлыки не будут исправлены.
Небольшой пример помогает увидеть логику. Если у алерта есть team="payments", service="checkout" и severity="critical", отправьте его в pager команды payments. Если у него те же team и service, но severity="warning", отправьте его в чат payments. Владелец остаётся тем же. Меняется только уровень вмешательства.
Перед запуском проверьте каждое правило. Отправьте по одному тестовому алерту на каждый маршрут и посмотрите, куда он попадёт. Обязательно протестируйте и сломанный алерт без ярлыка team или service, потому что именно такие случаи потом тихо заполняют неправильную комнату.
Делайте дерево коротким. Когда правил маршрутизации становится слишком много, люди перестают им доверять и начинают вручную делать исключения. Короткие правила, простые ярлыки и один запасной путь обычно лучше, чем слишком умная схема.
Отправляйте каждый алерт туда, где ему место
Большая часть проблем с алертами начинается тогда, когда всё летит в одно и то же место. Хорошая маршрутизация Grafana отправляет каждый алерт туда, где кто-то может действовать в ожидаемый срок.
Предупреждения обычно должны попадать в чат команды этого сервиса. Warning часто означает, что система дрейфует, а не ломается. Например, время ответа выросло на 15 минут, расход диска растёт или фоновая задача пропустила один запуск. Команда сервиса должна увидеть такой паттерн, обсудить его и исправить в рабочее время, если пользователи пока в порядке.
Срочные алерты должны будить одного человека, а не двадцать. Если резко растут ошибки, очередь перестаёт двигаться или приложение падает, отправляйте такой алерт дежурному владельцу затронутого сервиса. Можно продублировать его в чат команды для видимости, но пейдж должен иметь одну понятную цель.
Некоторым алертам нужен вообще другой маршрут. Всплеск облачных расходов относится к финансам или операциям, а не к инженерному пейджеру. Повторяющиеся алерты по аудиту или доступу сначала должны идти в безопасность или compliance. Ошибка в платёжном экспорте или нарушение политики важны, но им не место в том же потоке пейджей, что и у production-аварии.
Алерты по общей платформе тоже должны иметь твёрдое место. Уведомления по базе данных, Kubernetes, ingress, CI и observability сначала должны попадать к владельцу платформы. Если одной платформой пользуются несколько команд, назначьте одного основного владельца и одного запасного.
Руководителям редко нужны живые пинги по обычным проблемам. Им нужен краткий свод, который можно прочитать за две минуты. Отправляйте плановый дайджест или короткую заметку после инцидента с названием сервиса, длительностью проблемы, влиянием на клиентов и тем, что ещё нужно доработать. Прямые пинги руководителям оставляйте для простоев, которые влияют на выручку, клиентов или сроки.
Простая схема для трёх команд
Хорошая настройка маршрутизации алертов в Grafana часто начинается всего с трёх команд: product, platform и support. Каждый алерт должен содержать как минимум team и service, иначе правила быстро запутаются.
В простой модели product владеет алертами веб-приложения, такими как login, checkout, search и payments. Platform отвечает за алерты по базе данных, кэшу, кластеру и сети. Support отвечает за публичные уведомления о доступности, которые клиенты могут заметить первыми. Так внутренние сбои не попадают в очередь поддержки, а product-инженеры не получают пейдж из-за шумного предупреждения о диске на узле базы данных.
Платёжный поток — хороший пример для проверки. Допустим, сервис checkout начинает возвращать ошибки. Алерт срабатывает с ярлыками вроде team=product, service=payments и severity=critical. Политики уведомлений Grafana могут отправить его команде product, потому что она владеет платёжным кодом.
Если добавить ярлык customer_impact=yes, тот же алерт может отправить второе уведомление в support. Support не чинит код, но ему нужно знать заранее, что клиенты могут обратиться в компанию в ближайшие десять минут. Такое небольшое разделение сильно снижает путаницу. Product исправляет проблему. Support занимается коммуникацией.
Теперь посмотрите на backend-часть того же инцидента. Если настоящая причина — падающий узел Postgres, этот алерт должен прийти с team=platform и service=postgres. Он идёт в platform, а не в product, даже если клиент видит сбой внутри checkout. Алерт другой — владелец другой.
Вам также нужно безопасное место для плохих ярлыков. Неверно размеченный платёжный алерт, например service=payments без team, должен попадать в общий triage-канал. Не отправляйте такие алерты сразу во все комнаты. Это только вернёт тот шум, от которого вы хотели избавиться.
Считайте этот канал ремонта очередью на исправление. Если за неделю туда попало три алерта, исправьте ярлыки в источнике. Обычно проблема не в самих правилах маршрутизации. Чаще всего проблема — в отсутствии ясной ответственности.
Ошибки, из-за которых шум возвращается
Шум часто возвращается через несколько недель после запуска, когда ярлыки расползаются, а никто не чистит маршруты. Маршрутизация алертов в Grafana работает хорошо только тогда, когда у каждого ярлыка одна задача и люди держат карту в актуальном состоянии.
Частая ошибка — смешивать названия команд и названия сервисов в одном и том же ярлыке. Один алерт говорит owner=payments, другой — owner=checkout-api, а третий — owner=platform. Теперь политики уведомлений Grafana не могут понять, означает owner команду или систему. Оставляйте для каждого ярлыка одно значение. Например, держите отдельно team=payments и service=checkout-api.
Команды также сами создают шум, когда отправляют один и тот же алерт сразу в чат, почту и пейджер. Первые день-два это кажется безопасным. Потом люди начинают отключать каналы, игнорировать почту и перестают доверять пейджеру, потому что слишком много низкоуровневых алертов летит по всем маршрутам. Пейдж должен означать, что сейчас нужно действовать.
Старые маршруты создают тихую путаницу. Команда меняет название, два сервиса переходят в другую группу, или старую систему уже вывели из эксплуатации, а дерево маршрутизации осталось тем же. Алерты всё ещё срабатывают, только уходят не тем людям. Такое постоянно происходит после организационных изменений.
Быстрый ежемесячный обзор помогает поймать большую часть таких ошибок: удаляйте маршруты для удалённых сервисов, обновляйте ярлыки команд после смены ответственности, проверяйте, что у общих систем всё ещё есть реальный владелец, и убеждайтесь, что правила для пейджа всё ещё соответствуют текущей severity.
Общие системы требуют особого внимания. DNS, CI runners, auth, logging и базы данных часто поддерживают несколько команд. Если никто не назначит резервного владельца по умолчанию, эти алерты будут ходить по кругу, пока кто-то не догадается. Назначьте для каждой общей системы запасную команду, даже если она будет только разбирать и перенаправлять.
Ярлыки severity тоже могут сломать чистую схему. Если одна команда использует critical для медленного ответа, а другая — только для полного простоя, пейджер начинает работать почти случайно. Держите шкалу маленькой и понятной. Запишите, что означает каждый уровень, кто получает уведомление и как быстро должен реагировать.
Если хотите меньше усталости от дежурства, относитесь к правилам маршрутизации как к коду. Проверяйте их, упрощайте и исправляйте каждый раз, когда меняется ответственность.
Короткая проверка перед запуском
Прежде чем включать маршрутизацию алертов Grafana для всех, проверьте скучные детали. Большинство проблем с шумом начинается с мелких пробелов, а не со сломанной логики. Один отсутствующий ярлык или одна мёртвая точка контакта могут отправить пейдж не в ту комнату в 2 часа ночи.
Начните с ярлыков. У каждого алерта должны быть и team, и service. Если какой-то сервис всё ещё отправляет алерты без указания владельца, Grafana может только гадать, а догадки обычно заканчиваются маршрутом по умолчанию. Этот default route полезен, но он должен ловить исключения, а не половину трафика алертов.
Потом проверьте людей и каналы. У каждого маршрута должна быть реальная точка контакта, которую кто-то действительно просматривает. Старые списки рассылки, заброшенные чаты и тестовые вебхуки создают тихие отказы. Срочным алертам нужен один понятный владелец. Если две команды думают, что ответит другая, быстро не ответит никто.
Быстрый предзапусковой обзор должен проверить четыре вещи:
- Посмотрите несколько алертов по каждому сервису и убедитесь, что ярлыки присутствуют и каждый раз написаны одинаково.
- Откройте каждую точку контакта и убедитесь, что она всё ещё ведёт в активный почтовый ящик, чат или инструмент пейджинга.
- Разберите серьёзные алерты по одному и назовите команду или человека, который отвечает за первую реакцию.
- Посмотрите историю default route и проверьте, какие алерты всё ещё попадают туда.
Проведите один реальный тест вне обычного рабочего времени. Не останавливайтесь на дневной проверке, потому что днём слабые места скрыты. Люди онлайн, чаты активны, и кто-то часто замечает пропущенный алерт просто случайно. Тихий вечерний тест показывает, работают ли маршрут, эскалация и само сообщение тогда, когда это действительно важно.
Если после теста слишком много алертов всё ещё попадает в default route, приостановите запуск и исправьте ярлыки до внедрения. Чистая маршрутизация зависит от чистой ответственности. Без этого политики уведомлений Grafana превращаются в сортировочную шляпу с плохим зрением.
Что делать дальше, чтобы дежурство стало спокойнее
Большинство команд получают лучший результат, если начинают с малого. Не перестраивайте всю систему алертов за один заход. Сначала возьмите десять самых шумных алертов, а потом исправьте, куда они идут, кто за них отвечает и должны ли они вообще будить людей.
Именно этот первый набор обычно быстро показывает настоящие проблемы. Один алерт срабатывает слишком часто. Другой принадлежит команде, которой больше не существует. Третий полезен в чате, но не в 2 часа ночи. Когда вы наведёте порядок в этих десяти, остальную систему будет гораздо легче разобрать.
Простая карта ответственности помогает сильнее, чем думают люди. Сделайте её удобной для быстрого просмотра. Если кто-то видит «checkout latency» или «database storage», он должен сразу понимать, какая команда получит алерт, без дополнительных вопросов. Короткой таблицы с названием сервиса, владельцем команды, признаком пейджинга и запасным контактом обычно достаточно.
После этого дайте новой схеме неделю, прежде чем оценивать её. Посмотрите на объём алертов, повторные срабатывания и на то, кто реально получил каждое сообщение. Если одну команду всё ещё заваливает, правила маршрутизации, скорее всего, слишком широкие. Если серьёзный алерт никто не видит, правила, вероятно, слишком узкие.
Жёстко убирайте ложные тревоги и малополезные уведомления из пейджинга. Предупреждение, которое может подождать до рабочего времени, должно идти в чат или на почту. Пейджьте людей только тогда, когда нужно действовать прямо сейчас. Одно это изменение быстро снижает усталость от дежурств.
Если карта ответственности всё ещё выглядит запутанной, внешний взгляд может сэкономить время. Oleg Sotnikov на oleg.is работает как fractional CTO и startup advisor, и такая работа по наведению порядка хорошо сочетается с тем, что он помогает небольшим командам усиливать ответственность за инфраструктуру и внедрять практичный AI-first engineering без навешивания лишних инструментов.
Цель проста: меньше алертов, понятнее владельцы и быстрее реакция.
Часто задаваемые вопросы
Почему одна общая комната для алертов — плохая идея?
Потому что люди перестают замечать комнаты, где слишком много алертов, на которые они не могут повлиять. Отправляйте каждый алерт команде, которая владеет сервисом, и важные проблемы быстрее дойдут до нужного человека.
Какие ярлыки должны быть у каждого алерта Grafana?
Начните с team, service и severity. Эти три ярлыка помогают сначала определить владельца, а потом понять, должен ли алерт идти в чат, на почту или в пейджер.
Сначала маршрутизировать алерты по команде или по сервису?
Сначала маршрутизируйте по команде, а уже потом уточняйте по сервису, если у команды несколько систем. Так ответственность остаётся понятной, и одна команда не получает алерты за чужую работу.
Куда отправлять алерты, если ярлык отсутствует?
Отправляйте их в один общий маршрут triage, а не во все комнаты сразу. Потом исправьте ярлыки в источнике, чтобы в следующий раз алерт попал к правильному владельцу.
Должны ли warning-алерты отправляться на дежурного инженера?
Обычно нет. Предупреждения лучше отправлять в чат команды, если только реагировать не нужно немедленно. Пейджинг оставьте для простоев, резких всплесков ошибок и любых проблем, которые уже влияют на пользователей.
Как обрабатывать алерты для общих систем вроде Postgres или Kubernetes?
Назначьте для каждой общей системы одного основного владельца и один запасной путь. Маршрутизируйте алерты по базе данных, кластеру, CI и ingress сначала к этому владельцу, а команды приложений подключайте только если проблема затрагивает их сервис или требует действий с их стороны.
Насколько детальной должна быть маршрутизация алертов в Grafana?
Держите группы маршрутизации близко к тому, как люди говорят о продукте, например checkout или admin portal. Если разбить каждый маленький компонент на отдельный путь, схема быстро превратится в неудобное обслуживание, к которому никто не хочет возвращаться.
Нужны ли менеджерам уведомления об алертах в реальном времени?
Чаще всего — нет. Руководителям нужен короткий сводный отчёт с влиянием, длительностью и следующими шагами, а живой алерт нужен дежурному владельцу.
Как проверить маршрутизацию алертов перед запуском?
Запустите по одному тестовому алерту на каждый маршрут и проверьте, куда он попадает. Затем протестируйте ещё и сломанный алерт без ярлыка, а также проведите хотя бы один тест вне рабочего времени, чтобы увидеть слабые места.
Что нужно проверять после запуска, чтобы снизить шум?
Проверяйте ярлыки, контактные точки, правила severity и default route каждый месяц. Названия команд меняются, сервисы переезжают, а старые маршруты продолжают шуметь, пока кто-то их не почистит.


