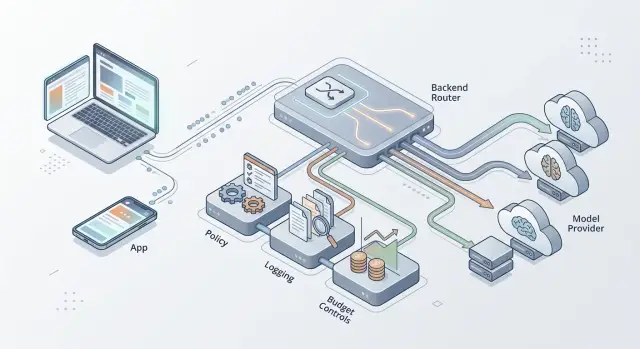
Маршрутизатор моделей на бэкенде: держите логику провайдеров на сервере
Бэкенд-маршрутизатор моделей позволяет менять провайдеров ИИ, обновлять политику, логировать запросы и контролировать расходы без выпуска новой версии приложения.
Содержание
Почему это становится проблемой
Большинство команд не планируют маршрутизатор моделей с самого начала. Они выбирают одного провайдера, хардкодят модель в приложении и выкладывают релиз. Рано это кажется нормальным: трафик небольшой, продукт меняется каждую неделю, и обычно выигрывает самый быстрый путь.
Проблемы начинаются, когда что-то вне приложения меняется. Провайдер повышает цены, ужесточает лимиты, меняет поведение безопасности или снимает модель с поддержки. Вдруг выбор провайдера перестаёт быть мелкой деталью реализации. Он влияет на стоимость, надёжность и поддержку.
Если выбор остаётся за клиентом, каждое исправление превращается в выпуск приложения. Веб-команды могут двигаться быстро, но мобильные и десктопные обычно — нет. Некоторые пользователи остаются на старых версиях днями или неделями, и один и тот же продукт начинает вести себя по-разному на разных устройствах.
Разрыв быстро порождает путаницу. Один клиент получает короткие ответы, потому что его приложение всё ещё вызывает старую модель. Другому мешает политика, которую команда уже хотела избежать. Контроль расходов тоже усложняется, потому что старые версии приложений продолжают отправлять трафик по старым правилам.
Поддержка ощущает это первой. Пользователь говорит: «моё сообщение не отправилось», но команда не может быстро сказать, какой провайдер обработал запрос, какая модель сработала и сработало ли какое-то правило fallback. Инженерам приходится рыться в логах нескольких приложений, и ответ часто зависит от версии клиента.
Проблема распространяется тихо. Веб-приложение держит одну настройку модели, iOS — другую, Android добавляет своё правило ретрая, а десктоп копирует старый промпт. Через пару месяцев изменение логики провайдера означает правку нескольких клиентов и надежду, что они всё ещё совпадут.
Простой чат-продукт делает это очевидным. Команда начинает с одного провайдера, потому что так быстрее. Позже хотят более дешёвую модель для коротких ответов и более сильную для больших файлов. Если маршрутизация живёт в клиенте, нужны свежие сборки, одобрение магазинов и время на обновление пользователей.
Как только важны стоимость, политика и отладка, логика провайдеров должна жить на сервере. Клиент должен отправлять запрос на бэкенд, а бэкенд решать, что делать дальше.
Что ломается, когда клиент выбирает модель
Когда приложение решает, какую модель или провайдера вызвать, мелкие изменения перестают быть мелкими. Изменение цены, сбой или новая политика конфиденциальности теперь ждут ревью iOS, выката на Android, обновлений десктопа и тех старых версий, которыми люди ещё пользуются. То, что могло занять десять минут, может растянуться на две недели.
Старая логика в клиентах тоже остаётся дольше, чем команды ожидают. Некоторые пользователи обновляются быстро. Многие — нет. Это оставляет несколько правил маршрутизации одновременно, а значит один и тот же запрос может идти разными путями в зависимости от устройства.
Это приводит к тихим отказам. Один пользователь попадает на Провайдера A со старым форматом запроса. Другой попадает на Провайдера B с новым правилом fallback. Саппорт получает скриншоты, продукт — расплывчатые жалобы, а инженеры не видят единого места, где можно понять, что произошло.
Клиентская маршрутизация также раскрывает больше, чем должна. Код приложения часто содержит имена провайдеров, ID моделей, поведение fallback и фрагменты стратегии ценообразования. Пользователям это не нужно. Скрейперы и конкуренты с радостью соберут эти данные.
Контроль бюджета быстро становится неуправляемым. Если каждый клиент сам решает, когда использовать дорогую модель, вы не можете применить единый лимит расходов ко всем версиям приложений. Баг в одном выпуске может послать лавину премиум-запросов, прежде чем кто-то заметит. Финансы видят один счёт, а саппорт слышит три разные истории.
Отладка по платформам
Когда маршрутизация живёт на устройстве, каждая платформа превращается в мини-бэкенд. Веб, iOS, Android и десктоп могут немного по-разному формировать промпты, ретраи и таймауты. Один и тот же вопрос пользователя может вести себя по-разному по причинам, которые сервер никогда не записал.
Чат-приложение это хорошо показывает. Допустим, веб-переход перешёл на более дешёвую модель для коротких вопросов, а мобильный всё ещё отправляет всё на премиум. Пользователи жалуются на медленные ответы на телефонах и разное качество на десктопе. Оба доклада правдивы, но причина разделена между клиентами.
Бэкенд-маршрутизатор решает эту проблему. Вы меняете логику провайдера в одном месте, применяете единую политику маршрутизации и логируете каждое решение туда, где команда может это проверить.
За что должен отвечать бэкенд
Любое решение, влияющее на деньги, безопасность или доступность, должно жить на сервере. Клиент должен отправлять сообщение пользователя, немного контекста продукта и, возможно, ID разговора. Всё остальное — задача бэкенда.
Начните с секретов. API-ключи провайдеров, лимиты по запросам, правила квот и месячные капы должны находиться в бэкенд-коде и конфигурации. Если эти значения лежат в мобильном приложении или браузерном клиенте, их можно просмотреть, скопировать и использовать вне вашего продукта. Даже без злого умысла клиентские лимиты слабы, потому что старые версии приложений продолжают работать по старым правилам.
Выбор модели тоже должен оставаться на сервере. Короткий запрос для сводки не требует той же модели, что сложный кейс поддержки или ревью кода. Уровень пользователя важен. Бюджет важнее, чем многие команды ожидают.
Простая политика часто достаточна:
- использовать более дешёвую модель для коротких, низко-рисковых запросов
- резервировать более мощные модели для длинных или ценных задач
- предоставлять платным пользователям лучшее время отклика или большие контексты
- останавливать или понижать запросы при приближении бюджетного порога
Правила fallback тоже должны быть в одном месте. Если один провайдер начинает тормозить, бэкенд может повторить запрос, сократить контекст, переключить провайдера или вернуть понятную ошибку. Это изменение должно происходить один раз. Не ждите одобрения в магазине приложений, чтобы починить маршрутизацию.
Сервер должен ещё и вести бумажный след. Записывайте ID запросов, имя провайдера, имя модели, задержку, количество токенов и оценку стоимости каждого вызова. Когда пользователи жалуются на медленные ответы, нужны реальные данные. Когда расходы растут без видимой причины, нужен способ отследить это.
Проверки безопасности должны выполняться до выхода любого вызова к провайдеру. Блокируйте промпты, которые пытаются раскрыть секреты, нарушают правила продукта или злоупотребляют дорогими путями. Это одна из самых очевидных причин держать маршрутизацию на сервере: вы можете менять фильтры, добавлять проверки и ужесточать политику без принуждения каждого пользователя обновлять приложение.
Если клиент выбирает провайдера, вы теряете контроль понемногу каждую неделю. Если бэкенд владеет этим, вы меняете политику редактированием одного сервиса.
Как перенести маршрутизацию на сервер
Начните с того, чтобы дать каждому клиенту одно место для отправки работы модели. Веб, мобильные и внутренние инструменты должны вызывать один и тот же бэкенд-эндпойнт. Приложение должно просить результат, а не выбирать OpenAI, Anthropic или любого другого провайдера.
Это означает, что запросу нужны лучшие входные данные. Отправляйте тип задачи, уровень плана пользователя, размер сообщения, уровень безопасности и несколько фактов о сессии. Не отправляйте имена провайдеров из клиента. Как только клиенты начнут указывать провайдеров, вы привяжете продукт к сегодняшним выборам и заставите обновлять приложения ради мелких политических изменений.
На сервере сопоставьте каждую задачу с моделью по умолчанию. Запрос на сводку может использовать одну модель, анализ длинного документа — другую, а ревью кода — третью. Здесь проявляется выгода серверной маршрутизации: вы можете изменить карту в одном месте.
Практическая настройка проста:
- создайте один серверный endpoint для всех запросов к моделям
- определите небольшой набор типов задач, таких как чат, сводка, извлечение и помощь с программированием
- добавьте таблицу маршрутизации на сервере, которая выбирает модель по умолчанию для каждой задачи
- задайте правила fallback для таймаутов, ошибок и лимитов провайдеров
- возвращайте одинаковую форму ответа каждый раз, даже если сервер переключил провайдера
Формат ответа важнее, чем многие команды предполагают. Если каждый клиент получает одинаковые поля — текст вывода, статус завершения, использование токенов и флаги безопасности — вы можете менять провайдеров без правки кода приложения. Мобильному приложению не нужно изучать новый SDK просто потому, что в среду изменилась цена.
Лимиты по запросам тоже принадлежат серверу. Вы можете ограничивать дорогие задачи, замедлять абузный трафик и защищать платных пользователей от «шумных соседей». Команды, которые заботятся о расходах, обычно добавляют на том же уровне логирование, чтобы видеть, какие типы задач сжигают деньги и какие модели слишком часто падают.
Если у вас уже есть чат-продукт, перенесите одну трассу первой. Оставьте старый клиентский выбор модели за флагом, пропустите 10% трафика через сервер, сравните стоимость и задержку, затем переключайтесь. Это скучная работа, но скучные планы миграции обычно выдерживают контакт с продом.
Простой пример из чат-продукта
Представьте чат-поддержку онлайн-сервиса. Сначала команда отправляет каждое сообщение в одну быструю модель, потому что она дешевая, быстрая и достаточно хороша для обычных вопросов вроде сброса пароля или статуса доставки.
Это работает, пока чат не начинает обрабатывать вопросы по биллингу. Клиент пишет: «мне списали два раза, нужен возврат». Это отличается от «где мой заказ?». Слабый ответ может породить новые тикеты, злые отклики или даже чарджбек. Тогда бэкенд маршрутизирует споры по оплате на более мощную модель с более строгим промптом для поддержки.
Пользователю не нужно ничего выбирать. Приложение по-прежнему отправляет тот же запрос на тот же API. Бэкенд читает сообщение, проверяет тип аккаунта и выбирает маршрут.
Обычная политика может выглядеть так:
- обычные вопросы поддержки идут на быструю, недорогую модель
- споры по оплате идут на более сильную модель
- у бесплатных пользователей после дневного лимита используется более дешёвый маршрут
- у платных пользователей сохраняется лучший маршрут для длинных разговоров
Это становится особенно полезно при изменении цен. Скажем, команда использовала Провайдера A для всех платежных чатов, затем увидела резкий рост цен. Если маршрутизация на сервере, они могут в тот же день перенести этот поток на Провайдера B. Мобильное приложение не меняется. Веб-приложение не меняется. Никто не отправляет новый релиз приложения, чтобы сделать такую смену.
Это важно, потому что ревью в магазинах приложений занимает время, и многие пользователи не обновляют сразу. Если логика провайдера в клиенте, старые версии продолжают использовать старые правила, старые цены и старые лимиты. Вы теряете контроль над расходами и политикой, как только пользователи отстают с обновлениями.
Сервер также может фиксировать, почему он принял то или иное решение. Он может логировать, что сообщение совпало с правилом по биллингу, что пользователь перешёл лимит бесплатного уровня, или что трафик ушёл на резервного провайдера из-за роста цен. Это даёт саппорту, финансам и инженерам одно место, где смотреть, что произошло.
Для чат-продукта практическая выгода проста: приложение остаётся простым, а бизнес может менять качество модели, бюджетные правила и провайдеров, когда нужно.
Логи, политика и расходы
Маршрутизатор помогает только в том случае, если команда видит, что он делает ежедневно. Нужны чистые логи, простые средства управления политикой и жёсткие лимиты по стоимости. Если хотя бы одно из этого живёт в клиенте, вы теряете контроль как только приложение выпущено.
Что записывать
Логируйте одно событие на каждый запрос к модели. Содержимое должно быть небольшим, но полезным. Записывайте фичу или endpoint, провайдера и модель, размер промпта, размер ответа, общую задержку, финальный статус и оценочную стоимость. Если позже можно получить фактическую стоимость по счёту — храните и её.
Этого достаточно, чтобы заметить дорогие пути. Чат поддержки может казаться дешёвым, пока логи не покажут, что длинные промпты и ретраи удваивают счёт. Фича по написанию текстов может казаться медленной, пока данные не покажут, что один провайдер добавляет две лишние секунды под нагрузкой.
Не храните сырой пользовательский контент, если это не действительно необходимо. Удаляйте или маскируйте e‑mail, телефоны, имена, номера аккаунтов и всё, что может идентифицировать человека, до записи в хранилище. Во многих командах метаданные и короткие редактированные примеры достаточно для отладки маршрутизации без хранения полного промпта.
Если вы уже используете Grafana, Prometheus или Loki, шлите события маршрутизатора туда. Один общий дашборд лучше, чем отдельный отчёт, который никто не смотрит.
Держите политику и расходы на сервере
Поместите правила маршрутизации за редактируемыми флагами на бэкенде. Меняйте провайдеров, снижайте лимиты контекста, блокируйте рискованную модель для одной фичи или отправляйте премиум-пользователей на более быстрый маршрут без ожидания релиза мобильного или десктопного приложения.
Устанавливайте жёсткие лимиты расходов по фиче и по плану. Когда лимит срабатывает, сервер должен переключиться на более дешёвую модель, сократить контекст или выключить фичу до сброса бюджета. Мягкие предупреждения легко игнорировать. Жёсткие лимиты защищают маржу.
Просматривайте события fallback каждую неделю. Если один маршрут часто падает, перестаньте относиться к этому как к случайности. Исправьте правило, измените таймаут или удалите этого провайдера с этого пути.
Большинство команд смотрит общий счёт по ИИ. Им также стоит смотреть фоллбеки, ретраи и размер промпта — обычно там прячется основная трата.
Ошибки, которые делают команды в начале
Одна частая ошибка — позволить клиенту отправлять имена провайдеров типа «use Claude» или «use GPT-4» в запросе. Это кажется гибким пару недель. Потом меняются цены, срабатывают лимиты или один провайдер начинает хуже отвечать на определённую задачу, и теперь цикл релизов приложения контролирует вашу политику маршрутизации. Бэкенд-маршрутизатор помогает только если сервер принимает решение.
Команды также прячут правила маршрутизации внутри UI-кода. Экран чата проверяет одну галочку, экран документа — другую, и вскоре на каждой поверхности своя маленькая политика. Никто не может объяснить, почему один и тот же пользователь получает разное поведение в разных местах. Мобильные усугубляют это, потому что старые клиенты могут жить месяцами.
Небольшой пример делает проблему очевидной. Допустим, ваше приложение даёт суммаризацию тикетов поддержки. Версия 1 мобильного приложения отправляет имя провайдера, температуру и порядок fallback. Позже вы хотите более дешёвую маршрутизацию для коротких тикетов и строгую логировку для корпоративных аккаунтов. Вы уже не сможете полностью поменять это на сервере, потому что старый клиент всё ещё навязывает вчерашние правила.
Другая ошибка — логировать слишком много. Команды сбрасывают полные промпты, вставленные сообщения клиентов, внутренние заметки и иногда секреты в сырой лог ради удобной отладки. Такая привычка быстро становится дорогой и создаёт проблему с конфиденциальностью. Если в промпте могут быть e‑mail, токены, номера аккаунтов или контрактный текст, сначала логируйте метаданные и выборочно содержимое только при явной необходимости.
Петли fallback создают другой тип беды. Приложение повторяет один провайдер, затем другой, затем третий, а пользователь видит нормальный статус успеха. Пользователи получают медленные ответы. Инженеры пропускают проблему. Финансы замечают это позже.
Ищите такие паттерны:
- клиент отправляет имена провайдеров или ID моделей
- UI-код решает маршрутизацию, ретраи или лимиты расходов
- логи по умолчанию сохраняют полные промпты
- fallbacks скрывают ошибки вместо их отчёта
- планы выката игнорируют старые версии приложений
Более безопасный подход намеренно скучен. Пусть клиент отправляет задачу, контекст пользователя и немного разрешённых ограничений. Держите выбор провайдера, правила логирования, редактирование, ретраи и лимиты расходов на сервере, где вы можете поменять их сегодня, а не ждать следующего релиза.
Проверки перед релизом
Выбор модели в приложении превращает любое изменение политики в деплой. Это медленно на вебе и болезненно на мобильных платформах, где старые версии могут сидеть у пользователей неделю и больше. Серверная маршрутизация помогает избежать этой ловушки.
Перед запуском убедитесь, что вы можете поменять провайдера в конфигурации сервера без обновления приложения. Убедитесь, что можно установить лимит расходов для отдельной фичи из одного места. Саппорт должен иметь возможность смотреть упавшие запросы по trace ID, ошибкам провайдеров и версиям политики, не видя при этом сырых секретов. iOS, Android и веб должны получать одинаковую форму ответа, даже если бэкенд под капотом выбирал разные модели. И вы должны иметь возможность тестировать новые правила маршрутизации в стенде или проигрывать недавний трафик до того, как реальные пользователи их увидят.
Если хоть что‑то из этого не работает — исправьте до релиза. Команды часто говорят себе, что уберут это позже. Обычно этого не происходит. Как только пользователи зависят от фичи, любое изменение маршрутизации кажется рискованным.
Один простой тест ловит много проблем: заставьте бэкенд отправлять 10% одной фичи на резервного провайдера в течение дня. Клиент не должен заметить. В логах должно быть видно, какой провайдер обработал каждый запрос, сколько это стоило и почему маршрутизатор принял решение. Саппорт должен уметь отвечать «почему это упало?» из одного дашборда, а не просить инженеров собирать улики из трёх систем.
Это также даёт свободу продукту. Если одна модель медленнее, дороже или начинает плохо справляться с задачей, вы можете поменять правило на сервере в тот же день. Это и есть настоящая выгода: политика, логирование и контроль расходов в одном месте, а клиенты остаются проще.
Что делать дальше
Начните с простого инвентаря. Запишите все места, где ваш продукт сегодня вызывает модель: чат, сводки, инструменты поддержки, ответы поиска, фоновые задания и внутренние админ-фичи. Команды часто пропускают дорогие пути, потому что считают только то, что видно на основном экране.
Затем выберите одну загруженную трассу и сначала переместите её за один бэкенд-эндпойнт. Поток ответов чата обычно удобен для старта: он даёт реальный трафик, понятные числа по задержке и быстрый фидбэк при ошибках. Вам не нужно сразу перестраивать всё приложение.
Перед тем как переводить больше трафика, решите, что именно сервер должен контролировать: лимиты бюджета по дням, месяцам или пользователям; правила fallback при медлительности или недоступности провайдера; логи по использованию токенов, ошибкам и задержкам; правила по данным — что нельзя пускать в промпты и логи; и кто может менять политику маршрутизации без релиза клиента.
После этого упростите клиента. Пусть он отправляет намерение, историю сообщений и безопасные метаданные, и на этом всё. Сервер выбирает провайдера, применяет политику, фиксирует расходы и возвращает чистый результат. В этом смысл держать логику провайдеров на сервере: решения в одном месте вместо рассыпания по приложениям.
Держите первую версию маленькой. Один endpoint, один файл политики, один формат логов и один отчёт по стоимости достаточно, чтобы начать. Маршрутизатор не обязан быть хитрым в день запуска. Ему достаточно остановить распространение жёстко зашитых выборов моделей.
Вы поймёте, что всё работает, когда команда сможет понизить лимит бюджета, сменить провайдера по умолчанию или включить fallback без ожидания обновления приложения. Если провайдер замедлится в пятницу вечером, сервер должен обойти это до того, как пользователи заметят.
Если хотите второе мнение до того, как логика расползётся по нескольким клиентам и сервисам, Oleg Sotnikov на oleg.is предлагает помощь внештатного CTO по маршрутизации ИИ, контролю затрат и дизайну бэкенда. Такой обзор особенно полезен на раннем этапе, пока правила ещё помещаются в одном сервисе и легко меняются.
Часто задаваемые вопросы
Почему приложение не должно выбирать провайдера или модель?
Поместите выбор провайдера и модели на сервер. Это позволяет вашей команде менять правила стоимости, проверки безопасности и поведение при отказах в тот же день, не ожидая деплоя веба или обновления в магазинах приложений.
Если выбор делает приложение, старые версии продолжают отправлять трафик по старым правилам. Это разделяет поведение между устройствами и сильно усложняет поддержку.
Что клиент должен посылать на бэкенд вместо этого?
Отправляйте сообщение пользователя, тип задачи, уровень плана, идентификатор разговора или сессии и немного безопасного контекста. Пусть бэкенд решает, какой провайдер, модель и правило повторной попытки использовать.
Держите имена провайдеров, ID моделей, API-ключи и бизнес-логику бюджета вне клиента. Это упрощает приложение и даёт свободу менять политику позже.
Это всё ещё важно для маленького продукта?
Да, это важно с ранних этапов. Малый продукт может отправлять всё одному провайдеру сначала, но вам всё равно нужен тонкий слой на бэкенде между приложением и провайдером.
Этот слой — удобное место для логов, лимитов расходов и правил маршрутизации по мере роста трафика. Так вы избегаете большой переделки позже.
Как старые версии приложений усугубляют проблемы маршрутизации?
Пользователи обновляют приложения с разной скоростью, поэтому старый код маршрутизации живёт дольше, чем команды ожидают. Один телефон может использовать старую модель, в то время как веб-приложение — новую.
Это приводит к разным ответам, разным расходам и сложным для воспроизведения багам. Саппорт затем угадывает, какая версия приложения обработала запрос.
Что должен бэкенд логировать для каждого запроса к ИИ?
Логируйте по одному событию на каждый запрос к модели. Сохраняйте: имя фичи или endpoint, провайдер и модель, задержку, использование токенов, статус и оценочную стоимость. Добавьте trace ID, чтобы саппорт и инженеры могли отследить запрос между системами.
Не сохраняйте полные промпты по умолчанию. Маскируйте или удаляйте личные данные, если только вам не нужна выборка для отладки конкретной проблемы.
Как удерживать расходы на ИИ под контролем?
Устанавливайте лимиты расходов и правила маршрутизации на сервере, а не в коде приложения. Когда фича приближается к лимиту, бэкенд может переключиться на более дешёвую модель, сократить контекст или остановить поток до сброса бюджета.
Жёсткие лимиты работают лучше, чем одни только предупреждения. Они предотвращают массовую рассылку премиум-запросов из-за бага в одной версии.
Где должны жить повторные попытки и правила fallback?
Держите повторные попытки и fallback-правила в одном бэкенд-сервисе. Когда провайдер медлит или падает, сервер может выполнить одну повторную попытку, переключить провайдера или вернуть понятную ошибку с тем же форматом ответа.
Если каждое приложение делает это само, у каждой платформы будут разные таймауты и правила повтора. Это приводит к медленным отказам и сложной отладке.
Нужен ли единый формат ответа от бэкенда?
Да. Возвращайте одни и те же поля независимо от того, какой провайдер использовался: текст ответа, статус завершения, использование токенов и флаги безопасности.
Единый формат ответа упрощает клиентов. Вы сможете поменять провайдера или модель без переписывания мобильного и веб-кода.
Как безопасно перевести маршрутизацию с клиента на сервер?
Перенесите сначала одну загруженную трассу, например ответы чата. Поставьте за флагом фичи, пропустите небольшой процент трафика через бэкенд-маршрутизатор и сравните задержку, ошибки и стоимость перед полной сменой.
Постепенный перенос снижает риск и даёт реальные продовые данные. Он также показывает, где старый клиентский код всё ещё протекает в поток.
Когда стоит подключать внештатного CTO к этому вопросу?
Обратитесь за внешней помощью, когда логика провайдеров уже разрослась по нескольким приложениям, расходы продолжают вас удивлять или команда не может объяснить, почему упал конкретный запрос. Короткий аудит выявит слабые места до того, как они превратятся в долгую чистку.
Если вам нужна такая помощь, Oleg Sotnikov на oleg.is работает с маршрутизацией ИИ, дизайном бэкенда и контролем расходов как внештатный CTO.


