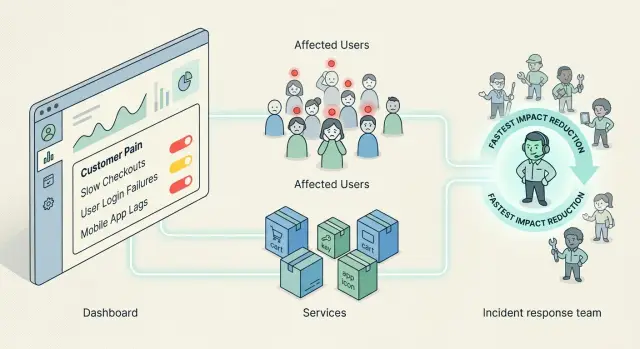
Маршрутизация оповещений по влиянию на клиентов, которая будит нужного владельца
Маршрутизация оповещений по влиянию на клиентов помогает командам будить того, кто быстрее всего снимет боль пользователей, даже если сломанный сервис принадлежит другой команде.
Содержание
Почему маршрутизация по сервисам не работает
Оргструктуры выглядят аккуратно. Инциденты — нет.
Когда оповещения маршрутизируются по названию сервиса, они обычно идут по границам команд. Оповещения по базе данных уходят команде базы данных, по кэшу — владельцу кэша, по API — backend-команде. Это кажется упорядоченным, но часто первое уведомление получает тот, кто меньше всего может снизить боль пользователей.
Пользователи не чувствуют «Redis тормозит» или «queue-worker-3 упал». Они чувствуют «Я не могу оформить заказ», «мой счет не отправился» или «приложение зависло после того, как я нажал оплатить». Названия сервисов описывают части системы. Они не описывают ущерб.
Этот разрыв стоит времени. Владелец кэша просыпается, смотрит на графики и видит всплеск. Потом он спрашивает, кто использует этот путь и насколько это важно. А владелец оформления заказа уже знает запасной сценарий, может отключить необязательный шаг и вернуть заказы в работу за пару минут. Ошибка может быть в кэше, но самый быстрый способ снизить влияние может находиться в оформлении заказа.
Простой пример показывает, почему это важно. Кластер кэша начинает отвечать с тайм-аутами. Первый заметный симптом — сбой оформления заказа, потому что шаг с расчетом цены не может достаточно быстро прочитать данные сеанса. Если оповещение будит команду кэша, владелец кэша может потратить десять минут на настройку узлов или поиск шумных соседей. Если же первым будят владельца оформления заказа, он может переключиться на безопасный запасной сценарий, отключить одно правило промоакции или сократить зависимость от кэшированных данных и вернуть поток заказов в работу еще до того, как будет исправлен кэш.
Поэтому маршрутизация оповещений по влиянию на клиентов часто работает лучше, чем оповещения по сервисам. Первое оповещение должно идти к тому, кто может быстрее всего снизить ущерб, а не к тому, чье название команды совпадает с отказавшим компонентом.
Маршрутизация по сервисам становится еще слабее, когда один сервис обслуживает много продуктовых потоков. Проблема в поисковом индексе может слегка ухудшить поиск товаров, сильно сломать административные инструменты и полностью заблокировать один платный сценарий. Одно оповещение по сервису не скажет, какая проблема важнее, если правило не привязано к пользовательскому результату.
Лучшее первое оповещение начинается с нескольких прямых вопросов. Какое действие пользователя сейчас не работает? Какая команда владеет этим действием от начала до конца? У кого есть самый быстрый способ смягчить проблему, а не просто самые глубокие знания о системе? Кто может сделать безопасное упрощение, не дожидаясь передачи между командами?
Когда это правило понятно, все остальное в настройке инцидентов становится проще.
Что на самом деле означает боль клиента
Боль клиента начинается в тот момент, когда реальный человек не может сделать то, зачем он пришел. Он не может войти в систему, оплатить, завершить регистрацию, открыть дашборд или получить нужный ответ. Если пользователь теряет время, деньги или доверие, боль реальна.
Многие команды по-прежнему будят людей из-за неправильных сигналов. Реплика базы данных, которая отстает на 30 секунд, может выглядеть пугающе на графике, но пользователи этого могут не заметить. В то же время небольшая ошибка в форме оплаты может заблокировать каждый новый заказ и почти не изменить ни один инфраструктурный показатель.
Хорошая маршрутизация отделяет вред для пользователя от технического шума. Технический шум все равно важен. Инженеры должны его видеть, отслеживать и исправлять. Просто он не должен будить не того человека в 2 часа ночи, если пользователь вообще этого не чувствует.
Здесь помогает простой тест: если проблема продлится еще 15 минут, что именно не смогут сделать пользователи? Если ответ ясный и болезненный, относитесь к этому как к срочной проблеме. Если ответ расплывчатый, скорее всего, это инженерное оповещение, а не клиентское.
У большинства команд уже есть более хорошие сигналы, чем им кажется. Неудачные заказы, заблокированные входы, сломанный сброс пароля, провалы регистрации, пользовательские тайм-ауты и обращения в поддержку по одной задаче говорят о боли клиента куда яснее, чем голый метрик сервиса.
«API оформления заказа деградировал» помогает с диагностикой. «32% заказов не проходят» объясняет, почему это должно волновать кого-то и насколько быстро нужно действовать.
Срочность должна следовать за влиянием, а не за владельцем системы. Если кэш-узел вышел из строя, но оформление заказа по-прежнему работает, команда кэша может заняться этим, не будя остальных. Если же оформление заказа ломается из-за сервиса налогов, флага функции или неудачного разворота в другом сервисе, будите того, кто быстрее всего может снизить боль клиента.
Пишите оповещения сначала на языке клиента, а уже потом на техническом языке. «Клиенты не могут оформить заказ» сильнее, чем «сервис X возвращает 500 ошибки». Первая строка говорит людям, что важно. Вторая подсказывает, где искать причину.
Такой подход еще и снимает частый спор. Команды меньше времени тратят на выяснение, у кого «горит коробка», и больше — на исправление той части продукта, с которой пользователи действительно взаимодействуют.
Кого нужно будить первым
Будите того человека или ту команду, которые могут уменьшить боль клиента в ближайшие несколько минут.
Это звучит очевидно, но плохой порядок оповещения сильно тормозит все остальное. Пользователи продолжают натыкаться на ту же ошибку. Поддержка тонет в обращениях. Первый ответственный тратит время на поиск «правильного» владельца вместо того, чтобы снова сделать продукт пригодным для использования.
Практический тест простой. Кто может остановить боль прямо сейчас? Кто может добавить безопасный обходной путь за 10–15 минут? Кто может уменьшить зону поражения, не дожидаясь другой команды? Кто может сделать изменение на стороне пользователя, откат, переключение флага или временный запасной сценарий?
Именно эта команда должна получить первое оповещение.
Иногда корень проблемы лежит глубоко в другой системе, но самый полезный быстрый шаг находится ближе к пользователю. Если ошибки оформления заказа вызваны сервисом налогов, первым оповещением все равно может стать команда оформления заказа. Она может отключить необязательную проверку, переключиться на запасной сценарий или поставить проблемный шаг на паузу, чтобы клиенты могли продолжать покупать. Команда налогов тоже должна подключиться. Просто ей не всегда нужно идти первой.
Вот различие, которое многие команды упускают: ответственность за первое оповещение и ответственность за исправление — это не одно и то же. Первое оповещение идет команде, которая может быстрее всего снизить влияние. Исправление остается за командой, которая владеет ошибкой, сервисом или проблемой у поставщика.
Постоянные исправления тоже занимают больше времени. Полное устранение может требовать логов, тестирования, ответа от поставщика или изменения кода. А обходной путь может потребовать лишь одного аккуратного решения и изменения конфигурации. Хорошая маршрутизация учитывает эту разницу.
Если могут действовать две команды, выбирайте ту, которая может действовать самостоятельно и с наименьшим риском. В небольших компаниях это часто владелец продукта или приложения, а не инфраструктурная команда. В компактных командах один человек может отвечать и за приложение, и за инфраструктуру, и за поставку изменений. Правило остается тем же: будите того владельца, который сначала может снизить ущерб, а уже потом подключайте команду, которая исправит глубинную причину.
Хорошие дежурные оповещения не спрашивают: «Кто владеет этим сервисом?» Они спрашивают: «Кто может сделать это лучше для клиентов до того, как пройдут следующие пять минут?»
Как настроить маршрутизацию шаг за шагом
Большинство правил оповещений начинается с систем: база данных, очередь, API, worker. Для дашбордов это удобно, но часто первым делом будит не того человека. Если вы хотите быстро снизить влияние на клиентов, начинайте с того действия, которое клиент пытался выполнить.
Сначала составьте короткий список пользовательских действий, которые сильнее всего страдают при сбое. Для большинства продуктов это вход в систему, регистрация, оплата, оформление заказа, отправка сообщения или выгрузка данных. Список должен быть коротким.
Для каждого действия выберите сигналы, которые показывают сбой с точки зрения клиента. Используйте сигналы, которые люди действительно ощущают, например падение успешности, всплеск задержки, рост повторных попыток или увеличение обращений в поддержку. Потом добавьте один или два системных сигнала, которые помогут объяснить сбой.
Затем выберите первого ответственного по скорости снижения ущерба, а не по владению сервисом. Если оформление заказа ломается из-за того, что сторонний платежный провайдер не отвечает вовремя, первым оповещением все равно может быть владелец платежей, даже если первыми ошибку заметили сетевые инженеры.
Запишите правило простым языком. Человек должен понять его с первого прочтения. «Если успешность платежей падает ниже 92% в течение 5 минут, будить дежурного по платежам. Он ведет инцидент и при необходимости подключает базу данных или инфраструктуру» — куда понятнее, чем «будить при насыщении базы данных».
Потом пересматривайте каждое правило после реального инцидента. Задайте три вопроса: дошло ли оповещение до нужного человека, сработало ли оно достаточно быстро и мог ли этот человек действительно уменьшить влияние?
Небольшим командам стоит упростить все еще сильнее. Используйте имена или понятные роли, если именно так у вас на самом деле устроена работа. В стартапе лучшим первым ответом может быть инженер, который может отключить плохой флаг функции, владелец продукта, который может поставить сломанный поток на паузу, или Fractional CTO, который быстро скоординирует откат.
Одна деталь особенно важна: дайте первому владельцу право вести инцидент даже тогда, когда причина лежит где-то еще. Ему не нужно исправлять все системы. Ему нужно снизить боль клиента, а затем подключить владельцев сервиса.
Если правило не отвечает на два вопроса, перепишите его: какое действие пользователя сломано и кто может первым уменьшить ущерб?
Простой пример из реального пользовательского сценария
Пользователь выбирает тариф, вводит карту и нажимает «Оплатить». Платежный шлюз работает нормально. Код оформления заказа тоже работает нормально. Но прямо перед списанием оформление заказа обращается к общему сервису аутентификации, чтобы обновить сеанс пользователя.
Этот вызов auth начинает отвечать с тайм-аутом. Теперь не проходит каждая покупка, хотя проблема находится вне платежного стека. Пользователям все равно, какой внутренний сервис сломался. Они видят только одно: оформление заказа не работает.
Если ваше оповещение сначала будит команду auth, восстановление может идти медленнее, чем должно. Инженер auth может потратить первые 10–15 минут на просмотр логов, сравнение ошибок и решение, откатывать ли развертывание. Эта работа важна, но она не всегда быстрее всего снижает боль клиента.
У владельца оформления заказа часто есть более быстрый ход. Он знает, какой шаг необязателен, какое правило можно временно ослабить и какой запасной сценарий достаточно безопасен, чтобы заказы продолжали проходить. В этом случае он может отключить шаг обновления сеанса и дать вошедшим пользователям завершить оплату с текущим сеансом.
Это не исправляет auth. Но это исправляет то, что чувствуют клиенты.
Разумная реакция выглядит так:
- Сначала будим владельца оформления заказа, потому что именно там заблокирована выручка.
- Он отключает неудачную проверку auth или переключается на более простой запасной сценарий.
- Сразу после этого подключается команда auth, чтобы исправить общий сервис.
- Оповещение остается открытым, пока успешность оформления заказа не вернется к норме.
Такой порядок работает, потому что владелец оформления заказа может снизить влияние за несколько минут, а команда auth в это время спокойно ищет корень проблемы, не давая потерянным продажам накапливаться в реальном времени.
Команды упускают это, потому что карты сервисов аккуратные, а пользовательские потоки — нет. Общий сервис auth может обслуживать вход, оплату, админ-инструменты и мобильные сеансы. Оповещение, привязанное только к названию сервиса, считает все эти сбои одинаковыми. Это не так. Ошибка auth при сбросе пароля отличается от ошибки auth, которая блокирует оформление заказа.
Это еще и тот самый компромисс, о котором Oleg Sotnikov часто пишет на oleg.is: самый быстрый фикс не всегда самый глубокий. В оповещениях это различие очень важно.
Частые ошибки, которые тратят время впустую
Много боли на дежурстве начинается с одной плохой привычки: будить команду, которая владеет тем ящиком, что выглядит сломанным на архитектурной схеме. Это кажется аккуратным, но часто только замедляет исправление. Если база данных шумит, но быстрее всего снизить ущерб можно, остановив падающее задание, показав запасное сообщение или перенаправив трафик, первое оповещение должно идти тому, кто может сделать это прямо сейчас.
Еще одна частая ошибка — отправлять одно и то же оповещение сразу трем командам. Людям кажется, что так экономится время. На деле обычно получается мини-совещание еще до того, как кто-то начнет действовать. Одна команда спрашивает, реальна ли проблема, другая начинает копаться в логах, а третья ждет, потому что думает, что это делает кто-то другой.
Один понятный ответственный лучше, чем шумное групповое оповещение. Остальные команды могут подключиться через эскалацию, если первый ответственный не сможет снизить влияние за несколько минут.
Оповещения тоже теряют время, когда описывают симптомы системы, но пропускают боль пользователя. «Насыщение пула базы данных» может быть правдой, но это не говорит, заблокированы ли пользователи, раздражены ли они или вообще ничего не заметили. Название оповещения должно делать это очевидным.
Команды также слишком долго держат плохие правила. Владелец меняется, обходные пути меняются, а пути эскалации тихо стареют. Правило, которое имело смысл полгода назад, во время живого инцидента может оказаться бесполезным.
Быстрые проверки для каждого правила оповещения
Если правило будит человека, этот человек должен быстро иметь возможность сделать что-то полезное.
Короткая проверка отсекает большинство плохих оповещений. Спросите, заметил бы пользователь проблему в течение нескольких минут. Если нет, правило, возможно, лучше подходит для дашборда, задачи или дневной очереди, а не для дежурного оповещения.
Потом проверьте, может ли первый человек, получивший сигнал, действовать сразу. Он должен уметь быстро откатить изменение, перевести систему на запасной сценарий, отключить сломанную функцию, отправить статус-обновление или быстро подключить нужную подстраховку.
Прочитайте название оповещения вслух. Оно должно описывать влияние на пользователя, а не только внутренний метрик. «Ошибки оформления заказа выше 8%» — понятно. «Насыщение пула базы данных» полезно только если это насыщение уже мешает пользователям.
Откройте runbook и посмотрите, есть ли там запасной сценарий. Если там написано только «проверить логи», он не готов. Там должен быть указан обходной путь, например отключение флага функции, переключение трафика или временный ручной процесс.
Наконец, убедитесь, что кто-то недавно проверял этот маршрут. Команды меняются. Владельцы меняются. Старые пути эскалации ломаются быстрее, чем люди ожидают.
Поиск — хороший пример. Если поиск замедляется, потому что отстал индексирующий процесс, пользователи могут видеть пустые или устаревшие результаты. Команда инфраструктуры поиска может оказаться не той, кто быстрее всего снижает боль. Это может сделать владелец продукта или приложения — например, скрыть сломанный фильтр, показать кэшированные результаты или приостановить свежий релиз.
Для небольших команд правило еще проще: будите того, кто знает самый быстрый безопасный обходной путь.
Быстрое правило для чистки оповещений
Если оповещение не отвечает, кто страдает, кто должен действовать и что он может сделать в первые 10 минут, перепишите его. Если кто-то недавно не проверял маршрут, проверьте его на этой неделе.
Такая проверка занимает немного времени и экономит много впустую потраченных оповещений, когда следующий инцидент начинается в 2 часа ночи.
Что делать дальше
Начните с одного клиентского пути, который действительно сильно страдает при сбое. Регистрация — нормальная отправная точка. Оплата еще лучше, если она приносит выручку каждый день. Не пытайтесь сразу исправить все правила оповещений. Одного болезненного пути достаточно, чтобы понять, работает ли ваша модель дежурных оповещений.
Потом перепишите небольшой набор шумных оповещений с учетом влияния на пользователя. Обычно для первого прохода хватает трех-пяти правил. Хорошее оповещение говорит, что не могут сделать клиенты, как долго длится проблема и кто может быстрее всего снизить ущерб.
Примеры простые:
- Новые пользователи не могут завершить регистрацию в течение 10 минут
- Успешность оплаты упала ниже обычного порога
- Клиенты не могут сбросить пароль в приложении
- Заказы зависли до того, как подтверждение дошло до пользователя
Такие оповещения подталкивают людей к действию, потому что ответственный понятнее, чем название сервиса.
После этого проведите один разбор инцидента с узкой целью. На время забудьте про поиск виноватых и споры о инструментах. Посмотрите на один недавний инцидент и задайте простой вопрос: кого будили первым и мог ли этот человек снизить влияние на клиентов в первые 15 минут?
Если ответ «нет», измените правило. Возможно, база данных замедлилась, но человек, который отвечает за оформление заказа, мог бы быстрее остановить повторные попытки, переключить трафик или написать сообщение клиентам. Именно этот человек и должен получать первое оповещение.
Сделайте первую версию простой: один основной владелец для пользовательского пути, один запасной, если основной не отвечает, одна эскалация после короткой задержки и короткая заметка о первом действии, которое снижает влияние.
Небольшие команды часто переусложняют эту часть. Вам не нужна огромная схема маршрутизации. Вам нужны несколько понятных правил, которые соответствуют реальной боли клиентов.
Если ваша система оповещений со временем стала слишком запутанной, поможет внешний взгляд. Oleg Sotnikov делает такую работу через oleg.is как Fractional CTO и советник для стартапов, особенно для команд, которые хотят держать операции легкими и при этом двигаться к более AI-assisted разработке.
Через неделю у вас должен быть прикрыт один клиентский путь, меньше шумных оповещений и один понятный ответственный на каждое оповещение. Этого уже достаточно, чтобы следующий инцидент был короче и менее хаотичным.
Часто задаваемые вопросы
Почему нельзя будить команду, которой принадлежит сломанный сервис?
Потому что владение сервисом не всегда совпадает с самым быстрым способом исправить ситуацию. Если из-за общего сервиса ломается оформление заказа, владелец оформления заказа часто может включить запасной сценарий, отключить один шаг или откатить плохое изменение раньше, чем владелец сервиса найдет корень проблемы.
Что считается болью клиента в оповещении?
Боль клиента начинается, когда пользователь не может закончить реальную задачу. Это может быть неудачный вход, блокировка оплаты, сломанная регистрация, пропавший счет или долгий тайм-аут на странице, которая нужна прямо сейчас.
Кого нужно будить первым во время инцидента?
Будите того, кто может снизить ущерб в ближайшие несколько минут. Этот человек должен понимать пользовательский сценарий и иметь достаточно доступа, чтобы быстро откатить изменение, переключить флаг, остановить сломанный шаг или подключить следующую команду.
Может ли первая команда, получившая оповещение, отличаться от команды, которая исправляет корень проблемы?
Да. Первое оповещение должно идти той команде, которая может быстро улучшить опыт пользователя. Команда, владеющая сломанным сервисом, все равно должна исправить настоящую проблему, но ей не всегда нужен первый сигнал.
Какие сигналы лучше всего подходят для оповещений о влиянии на клиентов?
Используйте сигналы, которые пользователи реально чувствуют. Хорошие примеры — падение числа успешных заказов, снижение успешных входов, провал завершения регистрации, рост пользовательских тайм-аутов и обращения в поддержку по одной сломанной операции.
Как назвать оповещение, чтобы люди действовали быстро?
Сначала пишите проблему пользователя, а уже потом техническую деталь. Клиенты не могут оформить заказ сразу объясняет, почему оповещение важно. Тайм-аут сервиса налога помогает уже после того, как люди начали разбираться.
Стоит ли оповещать сразу несколько команд?
Обычно нет. Один понятный ответственный действует быстрее, чем три команды, которые пытаются решить, кто должен начать. Если первый ответственный не может быстро снизить ущерб, он должен подключить следующую команду через простой путь эскалации.
Как небольшой команде настроить это без сложной системы?
Начните с простого. Выберите несколько бизнес-сценариев, которые сильнее всего страдают при сбое, назначьте по одному основному владельцу на каждый сценарий, добавьте запасного и укажите первый безопасный обходной путь. Чтобы получить лучший результат, не нужна огромная схема маршрутизации.
Что должен делать первый ответственный в первые 10 минут?
Им нужно сначала вернуть продукт в рабочее состояние, а не пытаться за один раз решить все технические детали. Хороший первый шаг — откат, изменение флага, запасной путь, сообщение о статусе или быстрая передача команде, которая может исправить глубокую причину.
Как часто нужно пересматривать и тестировать маршруты оповещений?
Проверяйте маршруты после реальных инцидентов и тестируйте их по расписанию. Команды меняются, обходные пути меняются, а старые правила владения быстро устаревают. Если маршрут отправляет оповещение тому, кто не может действовать сразу, перепишите его.


