Логическая декодировка Postgres для аудита и синхронизации: что выбрать
Логическая декодировка Postgres помогает, когда нужны audit trail почти в реальном времени или синхронизация данных, но polling все еще выигрывает для небольших и простых задач.
Содержание
Почему polling со временем начинает мешать
Polling сначала кажется дешевым решением. Команда добавляет столбец updated_at, запускает запрос каждые 30 секунд и выпускает функцию. Для маленькой таблицы с низкой нагрузкой это действительно может работать нормально.
Проблемы появляются позже. Polling снова и снова задает один и тот же вопрос, даже когда почти ничего не изменилось. База все равно проверяет индексы, читает строки, сортирует результаты и возвращает данные. Приложение тоже сравнивает timestamps, хранит offsets и отбрасывает дубликаты. Большая часть этой работы не находит ничего нового.
Короткие интервалы особенно хорошо показывают, сколько лишней работы возникает. Задача, которая запускается каждые пять секунд по нескольким занятым таблицам, создает постоянную фоновую нагрузку, даже если за последнюю минуту изменилось всего несколько строк. Для audit logging или синхронизации данных из Postgres это быстро становится дорогим. В итоге вы платите за множество чтений, чтобы поймать очень небольшой объем новых данных.
Длинные интервалы уменьшают нагрузку, но создают другую проблему. Свежие изменения просто ждут следующей проверки. В support-инструменте может минуту отображаться старый статус. Система отчетности может отставать. Worker синхронизации может за один раз вытащить много обновлений, и тогда downstream-системам придется работать сильнее, чем нужно.
Polling еще и подталкивает команды к неудобным правилам. Появляются watermarks, окна повторных попыток и пересекающиеся запросы на всякий случай, чтобы не пропустить строки с одинаковым timestamp. Код тихо разрастается. Быстрый скрипт превращается в небольшой проект по надежности.
Поэтому polling часто кажется простым ровно до того момента, пока им уже не становится. Многие команды начинают с него, и это совершенно нормально. Но когда объем изменений растет или бизнесу нужны данные почти в реальном времени, polling перестает быть самым удобным вариантом. В этот момент логическая декодировка Postgres часто выигрывает, потому что она фиксирует реальные изменения, а не снова и снова спрашивает, изменилось ли что-то.
Что на самом деле дает логическая декодировка
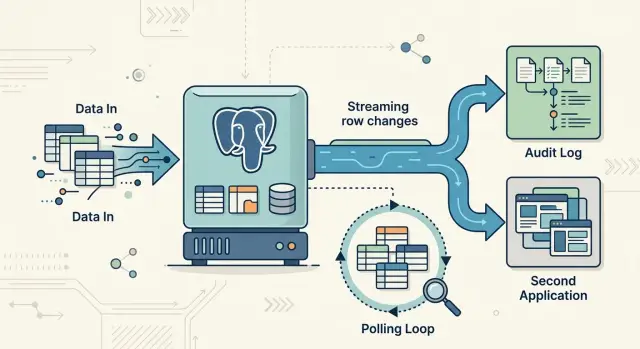
Логическая декодировка Postgres читает изменения из журнала предзаписи, а не проверяет одни и те же таблицы снова и снова. Это важно, потому что в журнале уже записано то, что база подтвердила. Вместо запроса каждые 10 секунд в стиле «что изменилось с прошлого раза?» другая служба может читать поток изменений напрямую.
Если говорить просто, логическая декодировка дает поток событий по строкам. Она может передавать вставки, обновления и удаления в порядке подтверждения, поэтому consumer видит изменения в той же последовательности, в которой их принял Postgres. Для audit-задач такой порядок помогает собрать понятную хронологию. Для синхронизации он помогает другой системе оставаться близко к источнику без постоянных повторных сканов.
Polling-задаче обычно нужна дополнительная логика, чтобы находить новые или измененные строки. Команды добавляют столбцы updated_at, сравнивают ID или ведут таблицы checkpoint. Это может работать, но быстро становится неудобным, когда обновления происходят часто или когда нужна минимальная задержка. Логическая декодировка убирает повторный скан таблиц и отправляет только реальные изменения.
Простой пример помогает лучше всего. Допустим, приложение хранит заказы клиентов в Postgres, а второй сервис ведет поисковый индекс или audit trail. С логической декодировкой второй сервис может реагировать, когда заказ появляется, меняет статус или удаляется. Ему не нужно каждые несколько минут просматривать всю таблицу заказов только ради двух измененных строк.
При этом поток сообщает только о том, что изменилось в Postgres. Он не принимает бизнес-решения за вас. Если audit log должен скрывать чувствительные поля, логика все равно нужна. Если две системы расходятся, вам по-прежнему нужны обработка конфликтов, retries и правила, какая сторона выигрывает.
Правильная ментальная модель такая: логическая декодировка дает надежный поток подтвержденных изменений базы. Она избавляет вас от повторного сканирования таблиц. Но прикладную логику она не отменяет.
Когда она выигрывает у polling
Polling выглядит безобидно, когда изменения редки. Он начинает усложняться, когда строки меняются весь день, а другим системам нужно получать эти обновления быстро. В такой ситуации логическая декодировка Postgres часто выигрывает, потому что Postgres сам сообщает, что изменилось, вместо того чтобы заставлять приложение постоянно спрашивать.
Самый очевидный случай — audit trail. Если вам нужны все insert, update и delete в правильном порядке, polling оставляет пробелы. Строка может измениться дважды между проверками, и ваш poller увидит только последнее состояние. Логическая декодировка дает сам поток изменений, так что вы можете записывать то, что произошло, а не только то, как строка выглядит сейчас.
Она также хорошо подходит для синхронизации. Если вы отправляете данные из Postgres в search, аналитику, warehouse или другое приложение, polling обычно означает повторные сканы или сложные фильтры по updated_at. Оба варианта шумят на занятых таблицах. Поток изменений чище. Поисковый индекс обновляется через несколько секунд, аналитический pipeline остается свежим, и вы перестаете перечитывать строки, которые вообще не менялись.
Нагрузка на чтение тоже важна. В системе с большим количеством записей polling создает лишнее давление именно там, где оно не нужно. Каждая частая проверка конкурирует с обычными запросами. Логическая декодировка меняет задачу с «сканировать и сравнивать» на «читать следующее изменение», а это обычно легче и дешевле.
Быстрые обновления downstream — еще одна веская причина. Если клиент меняет статус заказа, потом ждет 10 минут и все еще видит устаревшие данные в dashboard или support-инструменте, polling начинает казаться сломанным. Захват изменений решает эту проблему. Обновление может почти сразу попасть в другие системы.
Рабочее правило простое. Выбирайте декодировку, когда важно каждое изменение строки, когда другим системам нужно оставаться близко к реальному времени, когда polling слишком часто бьет по занятым таблицам или когда вам нужен именно порядок изменений, а не только итоговое состояние строки.
Если вашему приложению нужна надежная история и быстрая синхронизация при меньшей нагрузке на базу, логическая декодировка обычно оказывается лучшим инструментом.
Когда polling остается проще
Во многих небольших системах polling по-прежнему лучший выбор. Если за час меняется всего несколько строк, простой запрос по расписанию часто удобнее, чем полноценный поток изменений.
Представьте back office-приложение, где сотрудники иногда дописывают заметки к заказам, отмечают счета как оплаченные или исправляют карточку клиента. Если worker проверяет данные каждые пять или десять минут, забирает измененные строки и сохраняет последний checkpoint, такая задержка обычно вполне приемлема. Вы получаете нужный результат без второй системы рядом с базой данных.
Особенно хорошо это работает, когда таблицу можно подстроить под задачу. Добавьте updated_at, убедитесь, что приложение меняет его при каждой записи, и поставьте хороший индекс по столбцам, которые использует worker. Во многих случаях этого достаточно, чтобы запрос оставался быстрым даже по мере роста таблицы.
Polling обычно остается проще, когда объем изменений невелик, задержка в несколько минут не мешает, один фоновый worker справляется с нагрузкой, а команде не хочется лишней операционной работы.
Именно последний пункт люди недооценивают чаще всего. Логическая декодировка действительно может дать события почти в реальном времени, но за это придется платить дополнительными consumers, отслеживанием offsets, обработкой retries и аккуратным восстановлением после сбоев. Если команда небольшая или никто не хочет владеть этой обвязкой, скучный polling-задача часто оказывается более безопасным выбором.
Его и будущим коллегам объяснить проще. «Выбираем строки, которые изменились с прошлого запуска» — это легко читать, тестировать и чинить в 2 часа ночи, если что-то остановилось. Пропущенный запуск polling обычно означает, что job нужно просто перезапустить. Сломанный поток изменений может означать lag, дубликаты или slot, который держит старые WAL-файлы дольше, чем вы ожидали.
Если данные меняются медленно, а точность по времени не критична, лучше оставить все простым. Один worker, один checkpoint и один индексированный запрос трудно превзойти.
Как выбрать шаг за шагом
Начинайте не с инструмента, а с таблиц. Сделайте короткую карту: какие таблицы меняются, какое именно изменение важно и кто должен об этом узнать. Команды часто говорят, что им нужен CDC, а потом выясняется, что важны только три таблицы и только одно downstream-приложение.
Короткий путь принятия решения работает лучше длинного архитектурного спора. Перечислите таблицы, которые часто меняются, и системы или команды, которые от них зависят. Запишите, какую задержку может терпеть каждый consumer: секунды, минуты или часы. Решите, какой сбой хуже: пропустить изменение, отправить его дважды или не суметь воспроизвести историю. Затем посчитайте не только код, который вы напишете, но и то, сколько частей придется поддерживать в production, и выберите самый простой вариант, который все еще укладывается в требования по времени и надежности.
Время решает больше, чем кажется. Если другой системе достаточно получать свежие данные раз в 15 минут, polling может быть вполне достаточно и намного проще в эксплуатации. Если нужны обновления почти в реальном времени или каждое изменение строки должно быть зафиксировано по порядку, логическая декодировка начинает иметь смысл.
Риск важен не меньше. Audit trail и финансовые события часто должны воспроизводиться. Вам может понадобиться доказать, что изменилось, в каком порядке, и восстановиться после сбоя consumer. Polling может пропустить краткоживущие состояния, если не добавить дополнительную логику. Логическая декодировка дает поток изменений, и это часто лучше подходит для такой задачи.
Затем честно посчитайте стоимость владения. Логическая декодировка — это не просто переключатель в базе. Вам придется управлять replication slots, lag consumer, retries, обработкой изменений схемы и monitoring. Если команда небольшая и бизнесу подойдут более медленные обновления, polling может сэкономить много времени и нервов.
Быстрая проверка интуиции тоже помогает. Если один внутренний dashboard читает несколько таблиц раз в час, лучше оставить все скучным и использовать polling. Если нескольким системам нужны одни и те же изменения в течение секунд, и вы не можете позволить себе пропущенные события, используйте логическую декодировку и заранее заложите операционную поддержку.
Реальный пример
Представим небольшой SaaS, который работает с онлайн-заказами. В его базе Postgres есть три загруженные области: orders, refunds и customer notes. Support использует эти записи, чтобы разбирать спорные случаи, а продуктовая команда — чтобы search оставался свежим.
Клиент пишет: «Я не просил этот refund». Support нужен понятный таймлайн. Им важно увидеть, когда изменился заказ, кто оформил refund и не добавил ли agent заметку сразу после звонка.
Если эти факты лежат в отдельных таблицах без общей истории событий, команде приходится слишком долго собирать историю вручную. И это только хуже, когда несколько человек трогают один и тот же заказ за короткий промежуток.
У search есть второе требование. Когда заказ меняет статус с paid на refunded или когда заметка помечает аккаунт как sensitive, поисковый индекс должен обновляться за несколько секунд. Polling таблицы orders каждые пять секунд звучит безобидно, но он продолжает читать строки, даже когда ничего не менялось.
Потом команда замечает, что одних orders недостаточно. Нужны еще refunds и notes, поэтому они добавляют больше polling-задач и больше правил для updated_at, чтобы все синхронизировать. Чтения растут, крайних случаев становится больше, а история аудита все еще выглядит рваной.
Логическая декодировка подходит для такого случая лучше. Небольшой relay читает поток изменений из replication slot и отправляет только новые события двум consumers. Один consumer пишет audit log в порядке подтверждения. Второй обновляет поисковый индекс сразу после того, как Postgres фиксирует изменение.
Это меняет повседневную работу. Support открывает спор и видит понятную цепочку: заказ создан в 10:02, refund запрошен в 10:14, заметка agent добавлена в 10:15, refund одобрен в 10:19. Search тоже почти сразу отражает refund, поэтому агенты не ищут устаревшие данные во время разговора.
Вам по-прежнему нужно запускать relay, следить за lag слота и аккуратно обрабатывать изменения схемы. Но в такой схеме дополнительная обвязка себя оправдывает. Для небольшой SaaS-команды это обычно лучше, чем три тихих, но постоянных polling-workers.
Что вам придется запускать
Логическая декодировка добавляет небольшой pipeline, а не просто настройку базы. Postgres должен держать replication slot открытым, а вам нужен consumer, который читает изменения достаточно быстро. Если consumer отстанет, Postgres дольше хранит старые WAL-файлы, и место на диске может закончиться намного быстрее, чем ожидается.
Начните со слота. Создавайте по одному слоту на каждый реальный сценарий consumer, а не по слоту на каждую экспериментальную идею. Потом отслеживайте lag так же внимательно, как свободное место на диске, потому что эти вещи связаны.
Есть несколько показателей, которые важно смотреть каждый день:
- lag слота в байтах и во времени
- рост диска из-за WAL
- задержка consumer с момента последнего обработанного изменения
- успешный перезапуск после сбоя
- backlog после всплесков нагрузки
Consumer требует больше внимания, чем ожидает большинство команд. Ему нужно хранить offsets, обычно последний подтвержденный LSN, чтобы он мог корректно останавливаться и продолжать работу. Если состояние хранится только в памяти, один перезапуск может привести к дубликатам, пропускам или к тому и другому сразу.
Для audit-задач изменения строк сами по себе не становятся полезными audit-данными. Нужны правила, как превращать insert, update и delete во что-то, что люди смогут потом читать. Большинству команд как минимум нужны название таблицы, первичный ключ, тип операции, измененные поля и порядок подтверждения. Если вам нужен понятный человеку audit trail, заранее решите, как вы будете добавлять контекст пользователя или запроса, потому что сами изменения в базе часто не рассказывают всей истории.
Вам также нужен план на плохие дни. Сети падают, downstream-API замедляются, а consumers могут упасть сразу после обработки сообщения, но до сохранения offsets. Делайте retries с ограничениями. Добавляйте backpressure, чтобы медленный sink не тянул вниз весь pipeline. Если какие-то события все же не удалось обработать, отправляйте их в dead letter queue или отдельную таблицу ошибок и разбирайте их позже.
Один тест рассказывает очень многое: остановите consumer на целые сутки в staging. Затем запустите его снова и измерьте время catch up, рост WAL, обработку дубликатов и то, срабатывают ли alerts достаточно рано. Если этот прогон выглядит хаотично, в production будет еще сложнее.
Ошибки, которые создают проблемы
Команды часто воодушевляются логической декодировкой и начинают отправлять изменения строк, прежде чем решат, как должно выглядеть событие. Обычно это заканчивается плохо. Один consumer ожидает полные строки, другой — только измененные поля, а третьему нужны бизнес-события вроде «invoice paid», а не сырые обновления таблицы.
Сначала определите форму события. Решите, что должно быть в каждом сообщении, как consumers будут его читать и какие поля должны оставаться стабильными со временем.
Удаления причиняют много тихого вреда. Многие команды умеют обрабатывать insert и update, а про delete вспоминают только тогда, когда клиент спрашивает, почему старые записи все еще видны в search, cache или отчетной таблице. Если downstream-система не умеет удалять строки, синхронизация неполная.
Дубликаты создают такой же беспорядок, только быстрее. Consumer может упасть после того, как записал данные, но до того, как сохранил offset. После перезапуска он может обработать то же изменение еще раз. Если записи не idempotent, один заказ превращается в две отправки, а одно обновление пользователя — в две записи аудита.
Lag слота — ошибка, которая превращается в счет. Replication slot держит старые WAL-файлы, пока consumer не догонит поток. Если никто не следит за lag, место на диске растет, бэкапы становятся шумными, а база начинает испытывать давление из-за проблемы, которая живет вне приложения.
Обычно признаки появляются заранее: consumers отстают уже при обычной нагрузке, downstream-таблицы никогда не удаляют старые строки, повторные прогонки создают лишние записи, а разные команды спорят о том, что именно означает change event.
Еще одна частая ошибка — смешивать две задачи в одном consumer. Audit logging и app integrations звучат похоже, но тянут в разные стороны. Audit-данные должны оставаться близкими к исходному изменению и легко отслеживаться. App integrations часто требуют фильтрации, преобразования, retries и бизнес-правил. Если объединить это в один pipeline, любое маленькое изменение становится рискованным.
Я видел это в startup advisory work не один раз: команда использует одного CDC consumer для audit, analytics, indexing в search и доставки webhooks. Месяц все работает, а потом одно изменение правила ломает три downstream-системы. Отдельные consumers стоят немного дороже в начале, но позже экономят массу времени на исправления.
Быстрая проверка перед решением
Логическая декодировка оправдана, когда объем изменений высок, а целевой системе нужны свежие данные в течение секунд. Если таблицы меняются всего несколько раз в час, scheduled query с хорошим индексом может оказаться намного проще в жизни.
Начинайте с цифр, а не с архитектурных схем. Посчитайте insert, update и delete по нужным таблицам за обычный день и в пиковые периоды. Таблица с 80 изменениями в день — это совсем не то же самое, что таблица с 80 000 изменениями до обеда.
Затем решите, насколько свежими данные действительно должны быть downstream. Если другой системе можно отставать на пять или десять минут, polling, возможно, уже закрывает задачу. Если support, billing или проверки fraud требуют обновлений почти в реальном времени, логическая декодировка начинает окупаться.
Также стоит нормально проверить простой вариант. Многие команды считают polling неудобным, но один индексированный запрос по updated_at или монотонному ID может долго работать очень хорошо. Для одного audit log или одной внутренней синхронизации небольшой trigger или маленькая задача могут закрыть всю проблему с меньшим количеством кода и без лишнего операционного шума.
Сложность не только в чтении изменений. Кому-то придется следить за lag replication slot, обрабатывать retries, безопасно воспроизводить события и замечать, когда consumer отстает. Маленькие команды особенно быстро ощущают эту стоимость, особенно если они держат инфраструктуру компактной.
Перед тем как принять решение, ответьте на пять простых вопросов. Каковы дневные и пиковые объемы изменений по важным таблицам? Какую задержку может терпеть целевая система? Проверяли ли вы polling-запрос с правильным индексом, а не отказывались от него на интуиции? Кто отвечает за lag слота, retries и проблемы с replay? И не решает ли уже ваш текущий сценарий trigger или scheduled job?
Если ответы расплывчаты, подождите. Спор CDC против polling редко бывает спором о красоте архитектуры. Обычно это выбор между еще одним движущимся элементом сейчас и одной настоящей проблемой позже.
Что делать дальше
Начните специально с малого. Выберите одну таблицу и одного consumer, а потом наблюдайте за этим путем достаточно долго, чтобы увидеть обычную нагрузку, несколько правок и хотя бы одну небольшую ошибку. Узкий тест покажет, подходит ли логическая декодировка вашей реальной нагрузке, а не той, которую вы представили на доске.
Выберите таблицу, которая важна, но не создаст хаос, если тест придется приостановить. Orders, invoices или изменения аккаунта обычно проще понять, чем огромная таблица событий на все случаи жизни. Первую версию держите скучной.
Перед тем как что-то трогать в production, запишите шаги отката простыми словами. Решите, кто выключает consumer, кто приостанавливает или удаляет replication slot, как вы возвращаетесь к polling и как проверяете, что изменения не потерялись. Если эти шаги существуют только у кого-то в голове, первый инцидент будет неприятнее, чем должен быть.
Достаточно простого первого шага. Включите логическую декодировку для одной исходной таблицы, передайте изменения одному consumer, несколько дней сравнивайте decoded changes с текущим состоянием таблицы, проведите тест на отказ и зафиксируйте нагрузку на базу, lag слота и lag consumer.
Эти цифры важнее мнений. После теста на отказ проверьте, сколько времени занимает replay, когда consumer отстает, какую нагрузку база получает во время catch up и успевает ли downstream-система работать в том же темпе. Дизайн, который выглядит чистым в первый день, все равно может навредить вам, если восстановление после перезапуска занимает слишком много времени.
Если тест прошел хорошо, расширяйте область по одной таблице за раз. Не добавляйте сразу трех новых consumers, изменения схемы и backfill logic одновременно. Медленный рост проще отлаживать и дешевле разворачивать обратно.
Если вашей startup-команде нужен второй взгляд на trade-offs, Oleg Sotnikov на oleg.is работает как Fractional CTO и startup advisor и может помочь проверить архитектуру, протестировать план отката и сохранить систему компактной вместо того, чтобы добавлять лишние moving parts.
Часто задаваемые вопросы
Что такое логическая декодировка Postgres простыми словами?
Postgres записывает каждое подтвержденное изменение в WAL. Логическая декодировка читает этот поток и передает вашему приложению вставки, обновления и удаления в порядке подтверждения, чтобы вы реагировали на реальные изменения, а не заново сканировали таблицы.
Когда лучше оставить polling, а не переходить на логическую декодировку?
Используйте polling, когда изменений немного и задержка в несколько минут не мешает. Один worker, один checkpoint и один индексированный запрос по updated_at обычно проще в эксплуатации, чем CDC pipeline.
Почему polling плохо подходит для audit trail?
Polling часто видит только текущее состояние строки. Если строка изменилась дважды между проверками, job может пропустить промежуточный шаг. Логическая декодировка дает каждое подтвержденное изменение по порядку, поэтому audit trail получается гораздо понятнее.
Снижает ли логическая декодировка нагрузку на базу данных?
Обычно да. Polling снова и снова задает базе один и тот же вопрос, даже когда ничего не изменилось. Логическая декодировка читает следующее изменение из журнала, поэтому не нужны повторные сканы занятых таблиц.
Убирает ли логическая декодировка необходимость в прикладной логике?
Нет. Логическая декодировка дает сырой поток изменений базы, а не бизнес-смысл. Вам по-прежнему нужен код для скрытия чувствительных полей, формирования событий, retries, правил конфликтов и всего, что ожидает downstream-система.
Что может пойти не так, если неправильно настроить логическую декодировку?
Следите за lag слота репликации, ростом диска из-за WAL, задержкой consumer и поведением при перезапуске. Если consumer отстает, Postgres дольше хранит старые WAL-файлы, и место на диске может быстро закончиться.
Как тестировать CDC перед запуском в production?
Начните с одной таблицы и одного consumer. Проверьте все в staging, остановите consumer на время, перезапустите его и замерьте время catch up, дубли, lag слота и задержку downstream до того, как расширять область применения.
Стоит ли одному CDC consumer одновременно вести audit logs, search и webhooks?
Разделите их. Audit logging и app integrations требуют разной формы событий, разных правил retries и разной обработки ошибок. Если смешать все в одном consumer, одно изменение может сломать сразу несколько downstream-задач.
Что должно быть в хорошем change event?
Включите название таблицы, первичный ключ, тип операции, порядок подтверждения и измененные поля. Добавьте контекст пользователя или запроса, если людям нужно читать audit trail позже, потому что сами изменения строки редко рассказывают всю историю.
Можно ли вернуться к polling, если логическая декодировка создает слишком много overhead?
Да, если вы это предусмотрите. Опишите, как остановить consumer, удалить или приостановить slot, вернуться к polling и проверить, что изменения не потерялись. План отката экономит время, когда первый тест идет не по сценарию.


