Лимиты шлюза федеративных моделей, предотвращающие зависания
Лимиты шлюза федеративных моделей помогают поддерживать поток запросов, когда один поставщик замедляется. Узнайте про маршрутизацию, backoff, квоты и правила отказа, которые реально работают.
Содержание
Что идёт не так, когда один поставщик достигает лимита
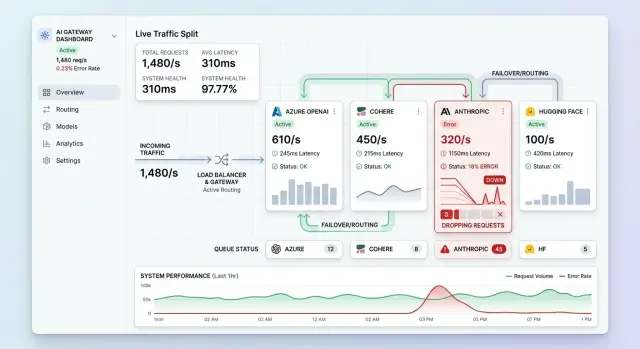
Когда у поставщика моделей начинают возвращаться 429 или он замедляется до ползания, проблема редко остаётся локальной. В общем шлюзе заблокированные вызовы сидят на рабочих, держат соединения открытыми и стареют в тех же очередях, которые нужны другим запросам. Скоро чат, поиск и суммаризация начинают чувствоваться медленнее, даже если проблемен только один поставщик.
Распределение по очередям обычно первое, что даёт сбой. Если запросы продолжают ждать ограниченного поставщика, они занимают тот же пул воркеров или бюджет таймаутов, что и здоровые маршруты. Повторные попытки только ухудшают ситуацию. Один неудачный вызов превращается в несколько, когда клиент, шлюз и задача-раннер все повторяют по своим таймерам. То, что началось как лимит поставщика, превращается в пробку, созданную вашей системой.
Здоровые поставщики при этом могут простаивать. Маршрутизатор всё равно отдаёт предпочтение привычному провайдеру из‑за устаревших весов, кэшированных правил или слишком медленных проверок состояния. Так шлюз продолжает кормить перегруженную полосу, в то время как свободные полосы остаются пустыми.
Представьте продукт, который отправляет чат, поиск и суммаризацию через один мультипровайдерный AI-шлюз. Поставщик A достигает минутного лимита в часы пик. Шлюз ждёт через длинные таймауты и повторяет попытки после отказа. Поставщики B и C всё ещё имеют запас, но общие воркеры заняты бэклогом. Пользователи, которые никогда не задействовали поставщика A, всё равно испытывают задержки.
Пользователи замечают это раньше, чем срабатывают большинство алертов. Они видят паузы набора, спиннеры, которые зависают на 10 секунд, и ответы, приходящие не по порядку. Дашборды ошибок могут сначала выглядеть мягко, потому что многие запросы ещё не упали — они просто застряли.
Со стороны это выглядит случайным. Один пользователь получает ответ за 2 секунды, следующий ждёт 20. Такое неравномерное поведение часто первое свидетельство того, что отказоустойчивость есть лишь на бумаге. Шлюз имеет резервный маршрут, но он не формирует трафик в реальном времени.
Что должен делать шлюз
Шлюз должен относиться к каждому поставщику и каждой модели как к отдельной дороге с собственным ограничением скорости. Один провайдер может разрешать высокий уровень запросов для маленькой модели и жёстко ограничивать большую. Если шлюз смешивает их вместе, он принимает плохие решения и посылает трафик в стену.
Для корректной маршрутизации шлюзу нужна живая картина из четырёх вещей для каждого маршрута поставщик→модель: квота, скорость пополнения, текущее потребление и недавние ошибки. Для этого не нужен сложный control plane. Нужно просто быть достаточно актуальным, чтобы решения по маршрутизации базировались на измеряемой пропускной способности, а не на догадках.
Совместные очереди причиняют больше вреда, чем многие команды ожидают. Медленная пакетная задача может заполнить ту же линию, что и чат‑запрос, и тогда оба кажутся сломанными. Держите отдельные полосы для пользовательских запросов, фоновой работы и повторных попыток. Дайте интерактивному трафику приоритетный доступ к здоровой мощности. Пусть фоновые задания используют то, что осталось. Сделайте повторные попытки отдельной очередью со строгими правилами.
Когда поставщик начинает таймаутиться или выдавать всплески 429, шлюз не должен держать каждый запрос открытым в надежде на скорое восстановление маршрута. Установите чёткий бюджет ожидания и перенаправляйте, когда он истёк. Для интерактивного трафика 1–3 секунды часто достаточно. Пакетные задания могут ждать дольше, но только если очередь остаётся ограниченной.
Перенаправление тоже нуждается в предохранителях. Если Поставщик A переполнен, шлюз должен проверить, есть ли у Поставщика B действительно запас, прежде чем переносить трафик. Иначе вы просто переместите пробку. Здравый маршрутизатор смотрит на оставшийся бюджет, глубину очереди, недавнюю задержку и тип запроса перед любым перемещением.
Если шлюз сделает эти базовые вещи правильно, проблема одного поставщика останется локальной и не разольётся по всему продукту.
Пропишите реальные лимиты
Лимиты скорости в федеративном шлюзе кажутся простыми, пока вы их не пропишете. Большинство команд думает, что у них один лимит на поставщика. На практике у них стопка лимитов, которые накладываются друг на друга и конфликтуют.
Шлюз обычно живёт как минимум в трёх лимитах одновременно: запросы в минуту, токены в минуту и одновременные вызовы. Модель может позволять много запросов, но захлебываться по объёму токенов. Другая может иметь щедрый лимит по токенам, но жёсткие ограничения на стриминг сессии. Если вы отслеживаете только одно число, остальные удивят вас в самый неподходящий момент.
Разделяйте эти лимиты по реальным границам, которые используют ваши поставщики. Это часто означает модель, регион, endpoint и аккаунт. Один аккаунт в одном регионе может работать плавно, а та же модель в другом регионе упирается гораздо раньше. Тестовые аккаунты, платные и корпоративные квоты тоже часто ведут себя по‑разному.
Держите одну понятную таблицу для всей команды
Ведите одну простую таблицу со всеми маршрутами, к которым ваш шлюз может обращаться. Для каждой строки записывайте жёсткие числа, окно сброса и любые правила всплесков. Некоторые поставщики пополняют лимит по скользящему окну. Другие разрешают короткий пик и затем жёстко ограничивают на следующую минуту.
Это важнее, чем кажется. Провайдер может выглядеть нормально на бумаге при 600 RPM и всё равно отклонить внезапную волну, потому что он допускает лишь небольшой всплеск в начале минуты. Чат‑трафик, повторные попытки и пакетные задания создают ровно такие волны.
Отделяйте ошибки «троттлинга» от аварийных ошибок
Маршрутизатору нужна короткая карта ошибок. 429 обычно значит «замедлитесь», а не «забудьте про этого поставщика на час». 5xx, таймауты или сбои соединения указывают на другую проблему. Некоторые провайдеры используют собственные коды перегрузки или заголовки, так что нормализуйте их в несколько простых категорий внутри шлюза.
Загруженный продукт может использовать одну модель для длинных ответов, другую для быстрого чата и резервную модель на более дешёвом аккаунте. Если у каждого маршрута разные крышки, поведение при ресете и сигналы ошибок, вашей команде нужны эти факты в письменном виде. Без этой карты отказоустойчивость превращается в домыслы, а домыслы создают пробки.
Маршрутизация по бюджету, а не по интуиции
Если вы распределяете трафик на глаз, один загруженный час может разрушить весь шлюз. Проще и безопаснее: относитесь к каждому поставщику как к бюджету с жёсткими краями, а не к бесконечной трубе. Этот бюджет включает запросы в минуту, токены в минуту, ежедневные расходы и небольшой резерв на непредвиденные ситуации.
Начните с резервирования доли трафика для каждого поставщика до того, как она понадобится. Если сегодня один провайдер кажется самым дешёвым, не посылайте туда всё. Дайте каждому поставщику постоянную долю на основе того, что он может безопасно выдержать, а не наибольшего числа в документации. На практике многие команды используют только 70–85% от заявленного лимита в обычном режиме.
Этот запас важен. Внезапные всплески ужасны, и лимиты часто отрабатывают быстро. Маркетинговая рассылка, шумный рабочий процесс клиента или шторм повторных попыток могут съесть ваш последний запас за секунды. Если у вас есть резерв на двух поставщиках, шлюз может поглотить всплеск вместо того, чтобы кидать 429 пользователям.
Бюджетирование также означает ранжирование задач по важности. Живой чат всегда выше пакетных суммаризаций, эмбеддингов и задач очистки. Когда давление растёт, перемещайте фоновые работы первыми. Поставьте их на паузу, замедлите или переключите на поставщика с неиспользованной квотой. Пользователи простят задержанный отчёт. Они не простят зависший чат.
Большие промпты нуждаются в собственной полосе. Длинный контекст может съесть тот же токен‑бюджет, что и несколько коротких разговоров. Маршрутизируйте такие запросы к поставщикам, у которых ещё есть место, даже если они чуть медленнее или дороже. Сохраните быстрый маршрут с жёстким бюджетом для коротких чатов и простых вызовов инструментов.
Практическое разделение просто: пусть Поставщик A обрабатывает большинство коротких чатов. Держите Поставщик B с запасом для всплесков и отказа. Отправляйте большие промпты и ночные задания Поставщику C. Это менее изящно, чем постоянные догадки маршрутизатора, но гораздо надёжнее под нагрузкой.
Настройка отказа по шагам
Шлюз должен переключаться плавно, как диммер, а не как автоматический выключатель. Если один поставщик начинает возвращать 429, таймаутиться или увеличивать возраст очереди, должны быть чёткие правила, которые перемещают трафик до того, как пользователи почувствуют полный простой.
- Наблюдайте отдельные сигналы. Повторяющиеся 429, всплески таймаутов и рост возраста очереди — это разные вещи. Поставщик может отвечать медленнее, прежде чем начнёт отклонять запросы, поэтому отслеживайте все три сигнала.
- Сначала остановите новые отправки к перегретому поставщику. Поддерживайте health probes, но блокируйте свежий пользовательский трафик, чтобы очередь не росла.
- Дайте выполняющимся запросам завершиться, если у них есть реальный шанс. Не обрывайте активные вызовы, если только они не превысили ваш собственный бюджет таймаута. Жёсткие обрывы часто превращают одно медленное окно в волну повторных попыток.
- Перемещайте трафик маленькими шагами и возвращайте так же. Переместите 10%, затем 25%, затем 50%, наблюдая задержки, ошибки и расходы. Второй поставщик может выглядеть здоровым на малой нагрузке и сломаться под полной.
Простой пример делает это конкретным. Допустим, ваш ассистент поддержки обычно отправляет 70% трафика Поставщику A и 30% Поставщику B. Поставщик A начинает возвращать 429 и средний возраст очереди удваивается. Шлюз прекращает новые отправки к A, даёт текущим вызовам стекать в течение короткого окна, затем перемещает часть нагрузки к B и остальное — к третьему провайдеру. Пользователи почувствуют небольшой всплеск задержки, но продукт останется доступным.
Здесь маршрутизация отказа становится реальной работой, а не схемой на диаграмме. Пропишите пороги, протестируйте их с фейковыми штормами 429 и держите движения трафика скучными. Скучная отказоустойчивость обычно и лучшая.
Пример часа пиковой нагрузки
В 12:05 бот поддержки получает мировой всплеск после рассылки биллингового письма: тысячи пользователей сразу открывают чат. Большинство вопросов простые, но всплеск острый — и это самое опасное.
В обычный день бот отправляет почти всё к одному поставщику, потому что этот маршрут быстрый и дешёвый. Затем поставщик начинает возвращать 429. Если приложение продолжит повторять тот же путь, очередь вырастет, время ответа подпрыгнет, и пользователи будут смотреть на спиннер.
Хороший шлюз не обрабатывает все задачи одинаково. Он держит живые ответы клиентам на самом здоровом low‑latency маршруте. При этом переносит генерацию суммаризаций и классификацию намерений ко второму поставщику, у которого ещё есть запас. Эти задачи обычно портативны, так что замена не ломает продукт.
Шлюз также замедляет работу, которая сейчас никому не нужна. Пакетные суммаризации, тегирование тикетов и отчёты по трендам могут подождать, пока лимит не сбросится. Это одно правило часто спасает систему. Загруженные продукты блокируются, когда низкоприоритетная работа борется за ресурсы с живым чатом.
На практике пользователи могут заметить небольшие изменения: ответы короче, некоторые реплики занимают лишнюю секунду. Но чат продолжает отвечать, и это важнее, чем идеальная согласованность в пик.
Именно так формирование трафика в LLM‑шлюзе должно работать в реальном трафике: защищать путь пользователя в первую очередь, а затем тратить оставшуюся квоту там, где это всё ещё полезно.
Ошибки, которые создают пробки
Пробки обычно начинаются с одной плохой предпосылки: каждое упавшее обращение заслуживает мгновенной повторной попытки. Когда один поставщик возвращает 429 или замедляется, многие команды отправляют тот же запрос снова со всех воркеров почти одновременно. Это превращает небольшое событие лимита в поток. Поставщик остаётся перегруженным, ваша очередь растёт, и пользователи видят задержки повсюду.
Проблема усугубляется, когда повторные попытки используют один таймер. Если все задания ждут две секунды и снова пытаются вместе, вы создаёте пульс трафика вместо плавного потока. Случайная задержка (jitter), ограниченные попытки и правила приоритета в очередях работают лучше. Некоторые запросы могут подождать, некоторые должны быстро падать.
Ещё одна распространённая ошибка — один глобальный счётчик для всех поставщиков. Это выглядит просто, но скрывает реальные границы. Один провайдер может ограничивать запросы в минуту, другой — токены в минуту, третий — по модели или региону. Если вы сводите всё к одному числу, вы либо теряете вместимость, либо отправляете трафик к поставщику, который уже близок к краю.
Команды также ломают систему, когда перебрасывают 100% трафика в один прыжок. Поставщик A стал медленным, значит всё уходит к B. Через минуту B достигает своего предела, и продукт снова останавливается. Перемещайте трафик шагами. Смотрите ошибки, задержки и расход токенов перед каждым увеличением. Сдвиг на 10–20% скучный, но он сохраняет систему живой.
Тяжёлые по токенам промпты причиняют более тихий ущерб. Шлюз может выглядеть здоровым по числу запросов, в то время как один клиент посылает огромные контексты и долгие выходы, съедая квоту поставщика. Решение простое: отслеживайте токены, а не только вызовы. Короткий запрос и запрос на 40 000 токенов не должны стоить одинаково в маршрутизаторе.
Квоты по клиентам и командам важны тоже. Без них один занятой аккаунт может истощить общую ёмкость, и все остальные будут платить. Так «случайные простои» происходят во время запуска продукта или крупной внутренней пакетной работы.
Большинство этих сбоев начинаются не внутри самого вызова модели. Они начинаются в правилах вокруг него.
Быстрая проверка перед релизом
Шлюз часто выглядит нормально в staging, потому что трафик там вежливый. В проде — нет. Одна плохая минута у поставщика может превратиться в растущую очередь, шторм повторных попыток и гораздо больший счёт.
До релиза сломайте одного поставщика намеренно и посмотрите, как ведёт себя остальная система. Приложение должно чуть замедлиться, но не замереть. Если запросы продолжают идти по другому маршруту, ваша настройка, вероятно, готова к реальному отказу.
Используйте этот короткий чек‑лист перед тем, как пропустить реальный трафик:
- Отключите одного поставщика на 10 минут и подтвердите, что трафик перенаправляется, задержка остаётся в целевых рамках, а продукт по‑прежнему возвращает полезные ответы.
- Настройте алерты по глубине очередей, числу повторных попыток и времени до первого токена. Срабатывайте рано, до того как пользователи заметят и прежде чем воркеры накопятся.
- Отслеживайте токены промптов и токены завершений на том же дашборде, что и число запросов. Только число запросов может выглядеть нормально, в то время как использование токенов и расходы быстро растут.
- Добавьте backoff с джиттером для 429 и 5xx, ограничьте повторные попытки и сначала останавливайте низкоприоритетные задачи.
Одна деталь важнее, чем многие думают: дашборды должны показывать трафик по поставщику, модели и типу токенов. Если вы смотрите только суммарные запросы, вы пропустите момент, когда короткие промпты превращаются в длинные завершения и съедают оставшуюся квоту.
Маленький продукт поддержки — хороший пример. Он может обслуживаться одним основным поставщиком и одним резервным. Если основной маршрут начинает возвращать 429, резерв должен брать только тот бюджет трафика, который он может позволить себе, а шлюз — задерживать или отбрасывать менее срочные работы. Это сохраняет ответы в чате для активных пользователей.
Выпускайте, только когда один поставщик может упасть, алерты срабатывают рано, повторные попытки успокаивают систему вместо того, чтобы её захлестнуть, и команда видит стоимость каждого сдвига трафика.
Следующие шаги для безопасного шлюза
Выберите один пользовательский путь, который важен каждый день. Для большинства команд это один поток: ответы чата, черновики поддержки или суммаризации документов. Подключите этот путь к основному поставщику, затем добавьте одного резервного с чётким правилом переключения. Двух поставщиков достаточно, чтобы многому научиться.
Начните с лимитов, которые можно объяснить в одном предложении. Установите минутную крышку, потолок повторных попыток и таймаут для каждого поставщика. Затем решите, что делает шлюз, когда провайдер возвращает 429, замедляется или перестаёт отвечать. Хорошая обработка лимитов не просто блокирует трафик — она целенаправленно его перемещает.
Проводите тесты отказа до того, как пользователи столкнутся с ними в проде. Форсируйте 429, форсируйте таймауты. Отключайте поставщика на пять минут и смотрите на длину очереди, задержки и ошибки. Если запросы собираются и не сходят, ваша логика повторов слишком настойчива или правило переключения ждёт слишком долго.
Держите цикл обзора коротким. Тестируйте один основной путь и один резервный сначала. Повторяйте тренировки 429 и таймаутов каждый раз, когда меняете маршрутизацию. Проверяйте расходы после каждого нового правила, а не только аптайм. Пропишите, кто может менять лимиты в проде и кто утверждает экстренные изменения.
Аудит расходов важен, потому что формирование трафика может скрыть расточительность. Правило маршрутизации может снизить ошибки и при этом отправлять слишком много запросов к более дорогой модели. Команды часто это пропускают, потому что система на поверхности выглядит здоровой.
Пропишите операционные правила там, где команда быстро их найдёт. Если служба поддержки видит всплеск, она должна знать, снижать ли трафик, отключать повторные попытки или перемещать больше нагрузки на резервного поставщика. Если только один инженер понимает лимиты, шлюз по‑прежнему хрупок.
Если вы хотите внешнего обзора, Oleg Sotnikov at oleg.is работает со стартапами и небольшими командами по правилам шлюзов, инфраструктурным решениям и практичному внедрению AI. Второй просмотр часто ловит простые исправления: меньше повторных попыток, жёстче бюджеты поставщиков или чище пути отката.
Более безопасный шлюз обычно не сложнее. Он более обдуман.
Часто задаваемые вопросы
Почему лимит одного поставщика может замедлить весь шлюз?
Зависание начинается, когда медленные или ограниченные по скорости вызовы занимают рабочих, соединения и бюджет таймаутов. На это сверху набрасываются повторные попытки, и здоровые маршруты оказываются в очереди за застрявшей работой — в итоге весь продукт кажется медленным.
Как долго чат должен ждать перед перенаправлением?
Для пользовательских чатов и других взаимодействий дайте маршруту короткий бюджет ожидания и быстро переключайте трафик. В большинстве настроек 1–3 секунды — хорошая отправная точка, потому что пользователи сразу замечают более длинные паузы.
Должны ли повторные попытки быть в той же очереди, что и пользовательский трафик?
Нет. Держите пользовательский трафик, фоновые задачи и повторные попытки в отдельных очередях. Если они делят одну линию, низкоприоритетная работа может блокировать живые запросы при замедлении поставщика.
Какие лимиты нужно отслеживать для каждого поставщика и модели?
Отслеживайте запросы в минуту, токены в минуту и одновременные вызовы для каждого маршрута поставщик→модель. Также разделяйте лимиты по реальным границам поставщиков: регион, endpoint и аккаунт часто имеют свои собственные квоты.
Сколько запаса нужно держать на каждом поставщике?
Оставляйте запас вместо того, чтобы гонять каждый поставщик на максимум. Часто используют около 70–85% от опубликованного лимита в нормальном режиме, чтобы иметь буфер для всплесков и переключений.
Когда шлюз должен прекратить отправлять новый трафик поставщику?
Перестаньте посылать новую нагрузку, когда видите повторяющиеся 429, растущие таймауты или увеличение времени в очереди на этом маршруте. Дайте рабочим в полёте закончить работу, если они ещё имеют шанс, но не подбрасывайте в джем свежие запросы.
Можно ли сразу перевести 100% трафика на резервного поставщика?
Не переводите сразу всё. Сдвигайте трафик поэтапно, наблюдайте задержки и ошибки, и подтверждайте, что следующий поставщик действительно имеет запас перед каждым увеличением.
Как обращаться с большими промптами в загруженные периоды?
Для больших промптов заведите отдельную полосу: они съедают намного больше токенов, чем короткие диалоги. Во время всплеска отправляйте их к поставщикам с большим лимитом по токенам или откладывайте, если пользователю это не критично.
Почему пользователи замечают проблемы раньше, чем дашборды показывают серьёзные показатели?
Пользователи чувствуют очереди раньше, чем в метриках появится заметный рост ошибок. Пока спиннеры крутятся и время до первого токена растёт, общая ошибка может быть ещё небольшой, — но восприятие уже ухудшилось.
Что нужно протестировать перед запуском отказоустойчивости шлюза?
Имитируйте отказ одного поставщика и посмотрите реакцию системы. Проверьте, что трафик перераспределяется, повторные попытки применяют джиттер, глубина очередей остаётся в пределах и дашборды показывают запросы, токены, задержки и расходы по поставщикам и моделям.


