Ограничения CPU замедляют сервисы: проверьте всплески трафика перед базой данных
Ограничения CPU тормозят сервисы чаще, чем команды думают. Научитесь сравнивать всплески запросов с лимитами контейнеров прежде чем обвинять базу данных.
Содержание
Почему здоровый сервис всё равно кажется медленным
Задержки часто подпрыгивают прежде, чем что‑то явно ломается. API начинает отвечать за 800 мс вместо 80 мс, пользователи это сразу чувствуют, и первой подозревают базу данных. Потом смотрят логи запросов и видят одно и то же: SQL остаётся быстрым.
Такое несоответствие встречается часто. Короткий всплеск трафика может за секунды «съесть» бюджет CPU контейнера. Код может быть в порядке, запросы — меньше 10 мс, а хост всё ещё иметь свободный CPU. Всё это не важно, если сервис работает под жёстким лимитом CPU.
Kubernetes и похожие платформы применяют лимиты к каждому контейнеру. Нода может быть загружена на 40%, а один занятый под постоянно троттлится. Со стороны endpoint кажется, что проблема в базе, потому что запрос большую часть времени ждёт CPU и до базы доходит позже.
Отсюда и путаница у команд. Приложение не падает. Ошибок может почти не быть. База не выглядит перегруженной. Но вы получаете резкие пики задержки при всплесках логинов, промахах кэша, наплывах вебхуков или случаях, когда всплеск попадает в тяжёлый путь в коде.
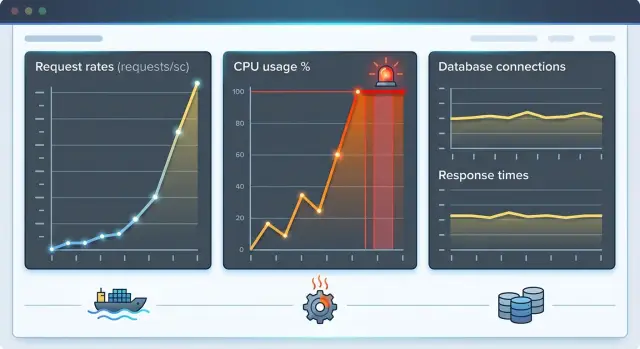
Простой пример API делает это нагляднее. Допустим сервис обычно обрабатывает 20 запросов в секунду, и каждому нужен немного CPU. Всё нормально. Потом трафик прыгает до 100 RPS на 30 секунд. Если лимит контейнера оставляет мало запаса, обработчики запросов начинают конкурировать за CPU. База всё ещё отвечает быстро, но endpoint замедляется, потому что приложение не может запускаться достаточно часто.
Поэтому полезно смотреть всплески трафика, лимиты CPU и троттлинг на одной временной шкале прежде чем тюнить запросы или добавлять индекс. Это быстрая проверка и часто указывает на реальную проблему.
Что делают лимиты CPU во время всплесков
Лимит CPU — это жёсткий потолок. Это не цель и не то, что контейнер может временно превысить и «отдать обратно» позже. Если одному контейнеру достаётся работы больше, чем позволяет его лимит, рантайм тут же замедляет этот контейнер.
Вот почему средние значения вводят в заблуждение. Сервис может выглядеть спокойно 58 секунд, получить удар на 2 секунды и казаться медленным именно в тот момент, который важен пользователям. На дашборде общий CPU может по‑прежнему выглядеть низким. В пути запроса эти короткие всплески быстро накапливаются.
Много работы делается до того, как база вообще что‑то сделает. Приложению нужно принять соединение, распарсить JSON, провести проверку авторизации, сопоставить маршрут, валидировать поля, записать логи и подготовить запрос. Каждый шаг сам по себе дешёв, но при всплеске они складываются.
Представьте небольшой API с лимитом 500m CPU. Большую часть минуты он почти ничего не использует. А затем 80 запросов приходят в одну секунду, когда мобильное приложение всё сразу ретраит. База здорова. Память остаётся ровной. Но контейнер не может использовать больше, чем его лимит, поэтому запросы ждут CPU. Пинг растёт с 70 мс до 700 мс ещё до появления первого медленного запроса.
Это не значит, что сервис сломан. Это значит, что сервис не успевает проглотить короткий пик.
Графики памяти обычно остаются невозмутимыми при таких инцидентах, и команды идут по ложному следу. Они смотрят базу, потому что ответы стали медленнее, но задержка началась раньше. Приложение достигло потолка CPU, потратило время на базовую работу запроса и только потом дошло до базы.
Если замедление выглядит резкими всплесками, а не плавным подъёмом, рассматривайте лимиты CPU как раннего подозреваемого. Всплески сильнее наказывают жёсткие лимиты, чем равномерный трафик.
Что измерить прежде чем лезть в базу
Начните с временного разрешения. График запросов в минуту может скрыть всю проблему. Сервис может выглядеть спокойно при 600 запросах в минуту, но получить 2‑секундный взрыв, который одновременно обрушивает все поды.
Стройте графики всплесков в коротких окнах — 1, 5 или 10 секунд. Нужно увидеть форму пика, а не его среднее.
Затем положите три сигнала на один график: использование CPU, троттлинг CPU и задержку запросов. Если задержка подпрыгивает в тот же момент, когда начинается троттлинг, у вас уже сильная подсказка. Если CPU перед прыжком сидит около лимита контейнера, подсказка ещё сильнее.
Не ограничивайтесь числами по всему кластеру. Сравнивайте трафик каждого пода с его лимитом. Два пода одного деплоймента могут вести себя по‑разному, если один получает тяжёлую долю трафика. Средние всё сглаживают и теряют время.
Простая проверка по поду обычно даёт больше, чем долгий аудит базы:
- запросы в секунду в коротких окнах
- использование CPU
- время троттлинга CPU
- p95 или p99 задержки
- счётчик рестартов или флапов готовности
Если один под получает 80 RPS во всплеске при жёстком лимите, троттлинг может быстро проявиться даже при нормальной базе. Время запросов в БД может вырасти позже, но к тому моменту приложение уже замедлилось.
Полезно также смотреть, какая работа окружает запрос. Очереди воркеров часто растут прежде чем пользователи заметят медленные страницы. Ретраи могут удвоить нагрузку за секунды. Fan‑out усугубляет ситуацию, когда один входящий запрос вызывает несколько внутренних вызовов.
Смотрите глубину очередей, частоту ретраев, исходящие вызовы на запрос и старты фоновых задач на одной шкале времени. Совместный вид обычно даёт ясную картину лучше, чем одни только логи запросов. Если трафик всплеснул, троттлинг вырос, очереди набрались, а задержка последовала — начните с лимитов CPU.
Как сравнить всплески и лимиты
Начните с одного endpointа, который громко себя ведёт под нагрузкой, или одного воркера, который шипит при заполнении очереди. Если размазать проверку по всему приложению слишком рано, числа сольются и вы пропустите настоящий хотспот.
Группируйте трафик в короткие корзины, обычно 1–5 секунд. Среднее за минуту может выглядеть безопасно, в то время как короткий пик полностью съедает лимит CPU.
Далее оцените время CPU на запрос. Трейсы дают грубую цифру, и короткий прогон профайлера часто достаточен, если трассы тонкие. Точная точность не нужна — нужен рабочий порядок, например 40 мс CPU на обычный запрос и 90 мс на тяжёлый.
Потом сделайте математику для одного пода. Если под получает 25 RPS во всплеске и каждый запрос использует ~40 мс CPU, поду нужно примерно 1 CPU‑секунду на каждую секундy реального времени. Если лимит контейнера — 500 millicores, под может использовать лишь половину. Недостающая половина не исчезает — ядро начинает троттлить контейнер.
Проверьте счётчики троттлинга в том же окне всплеска. Если использование CPU упирается в лимит, время троттлинга растёт, а время отклика ухудшается в тот же момент — ответ чище, чем «база медленная».
Проделайте ту же арифметику и для всего деплоймента. Сервис из десяти подов всё ещё может страдать, если трафик ложится неравномерно, один endpoint намного тяжелее остальных или один тип воркеров получает уникальный всплеск. Средние по флоту всё это скрывают.
Короткая запись на бумаге обычно достаточна:
- всплеск RPS × CPU‑время на запрос = CPU, нужный в секунду
- сравните это с лимитом на под
- проверьте счётчики троттлинга в окне 1–5 секунд
- повторите расчёт по всем подам вместе
Эта проверка займёт меньше времени, чем глубокий аудит базы, и часто выявляет реальное узкое место.
Откуда обычно начинаются всплески
Многие пики — это обычная работа, которая приходит одновременно. Сервис может быть тихим большую часть часа, а потом схлопнуться от совмещения запланированных задач и реальных пользователей.
Начало часа — частая проблема. Cron‑задачи просыпаются, отчёты запускаются, синхронизации стартуют, и пользователи часто приходят одновременно после перерыва. Каждая задача по отдельности безвредна. Наложение даёт проблему.
Ретраи быстро усугубляют ситуацию. Один медленный ответ может вызвать повтор в приложении, ещё один в воркере и, возможно, ещё в шлюзе. Одна и та же работа запускается два‑три раза, и дополнительная нагрузка проявляется в виде CPU‑давления задолго до того, как кто‑то заметит исходную задержку.
Холодные старты и промахи кэша добавляют скрытую стоимость. После деплоя, масштабирования или тихого периода первые запросы делают больше работы: наполняют кэши, загружают конфигурацию, собирают шаблоны, прогревают пути в коде. Десять тёплых запросов — это одно, десять холодных — может гораздо быстрее съесть лимит контейнера.
Фоновая работа может поглотить нормальный трафик. Один импорт, синхронизация с партнёром или пересборка индекса может держать CPU занятыми так, что обычные пользователи видят медленные страницы и таймауты. В продуктах с интенсивным использованием AI это может резко проявиться. Импорт документов, который кроме прочего создаёт эмбеддинги или вызывает модели, может превратить обычный день в всплеск.
Первые вещи для проверки — запланированные задачи около :00, :15 или :30, циклы ретраев после таймаутов, свежие поды после деплоя или автоскейла, сбросы кэша и импорты/синхи, которые делят CPU с пользовательскими подами. Если одно из этих событий совпадает с пиком задержки, вероятно вы нашли объяснение.
Простой пример API
Представьте маленький API, который в основном ездит на 40 RPS. Ответы быстрые, PostgreSQL в порядке, сервис кажется нормальным.
Потом стартует синхронизация с партнёром. На ~30 секунд трафик прыгает до 180 RPS. База при этом далеко не первая, кто испытывает нагрузку.
Каждый запрос использует примерно 12 мс CPU в приложении до отправки запроса в PostgreSQL. Это число кажется небольшим, пока вы не умножите его на всплеск.
При 180 RPS приложению требуется около 2.16 CPU‑ядер только для этой пред‑базовой работы:
- 180 запросов в секунду
- 12 мс CPU на запрос
- 2160 мс CPU нужно каждую секунду
- примерно 2.16 ядер спроса
Сравните это с лимитами контейнеров. Сервис работает на двух подах, у каждого лимит 0.5 CPU. Вместе они могут использовать 1 ядро до того, как Kubernetes начнёт троттлить.
Итого: приложению нужно чуть больше 2 ядер во всплеске, но кластер разрешает только 1. Поды упираются в потолок. Запросы скапливаются на уровне приложения, воркеры ждут CPU, и задержка растёт ещё до того, как PostgreSQL получает шанс серьёзно поработать.
Эту картину обычно заметить несложно. CPU на подах сидит возле лимита, троттлинг подпрыгивает в окно всплеска, задержка резко растёт. Логи медленных запросов молчат.
Сложность в тайминге. К моменту, когда запрос доходит до PostgreSQL, он уже провёл лишнее время в ожидании внутри контейнера. Если смотреть только end‑to‑end задержку, база попадает в трассу и её обвиняют. Но длительность запроса в БД может почти не измениться.
Команды могут потратить дни на тюнинг индексов в такой ситуации. SQL не причина ожидания — приложению просто не хватает CPU, чтобы пройти всплеск.
Если поднять лимит CPU, добавить поды или сгладить трафик партнёрской синхронизации, те же запросы обычно снова выглядят нормально. Именно поэтому математика всплесков важна.
Частые ошибки, которые тратят время
Большинство команд теряют часы, потому что сначала смотрят не тот график. Сервис может выглядеть спокойно на минутном дашборде и всё же задыхаться по 8–12 секунд.
Это происходит, когда вы читаете средние и не видите всплески. Если трафик идёт короткими волнами, CPU может застревать на лимите достаточно долго, чтобы замедлить запросы, а затем падать до следующей минуты. График покажет 35% использования, а пользователи всё равно будут ощущать тормоза.
Ещё одна ошибка — смотреть CPU ноды вместо CPU контейнера. Нода может иметь большой запас, в то время как один контейнер троттлится из‑за слишком низкого лимита. Хост выглядит здоровым, поэтому команда начинает винить базу, сеть или ORM. Проблема внутри границ контейнера.
Команды также тратят время, если при первых признаках медленных запросов увеличивают пул базы. Это только добавляет рабочих, которые конкурируют за тот же ограниченный CPU. Если потоки приложения уже ждут выполнения, больший пул может ещё сильнее увеличить задержку.
Пара простых проверок ловят это рано:
- сравнивайте скорость запросов в коротких окнах, а не только минутные виды
- смотрите использование CPU и троттлинг по контейнерам, а не только графики ноды
- проверьте, растёт ли задержка одновременно с началом троттлинга
- убедитесь, что очереди или воркеры не набирают очередь раньше, чем растёт время ожидания базы
Нагрузочное тестирование тоже может ввести в заблуждение. Ровный синтетический трафик редко похож на продакшен. Реальные пользователи приходят пачками после истечения кэша, ретраев, пакетных работ, вебхуков или свежего деплоя. Аккуратный тест‑рамп может не показать проблемы.
Oleg Sotnikov часто видит такую картину в стартап‑системах: на бумаге всё хорошо, а при коротких всплесках — провал. Это то, что он разбирает в рамках работы Fractional CTO через oleg.is. Перед изменением запросов или добавлением реплик сравните всплески трафика с лимитами контейнеров.
Быстрая проверка перед тюнингом запросов
Когда растёт задержка, начните со самого медленного пода, а не со средней по кластеру. Проверьте его счётчики троттлинга в те минуты, где пользователи ощущали тормоз. Если троттлинг растёт параллельно с p95, у вас уже лучшее предположение, чем «база медленная».
Положите три линии на один график или хотя бы в одно окно: скорость запросов, использование CPU и задержку. Такой вид быстро показывает порядок событий. Если первым растёт трафик, затем CPU упирается в лимит, а затем растёт задержка — приложение, вероятно, ждёт CPU задолго до того, как запросы станут проблемой.
Дневные усреднения скрывают эту картину. Сервис может выглядеть наполовину свободным в течение дня и при этом сжиматься во время 20‑секундного всплеска. Сравнивайте всплеск с лимитом контейнера, а не со средним трафиком за день.
После этого откройте одну медленную трассу и читайте её последовательно. Посчитайте, сколько работы приложение делает до отправки запроса. Парсинг JSON, проверки авторизации, промахи кэша, ретраи или тяжёлая сборка ответа могут съесть большую часть бюджета запроса. Если запрос в БД занимает 12 мс, а приложение тратит 180 мс в борьбе за CPU, тюнинг SQL мало поможет.
Короткий чек‑лист держит диагностику честной:
- проверьте троттлинг на одном медленном поде в проблемное окно
- наложите скорость запросов, использование CPU и задержку на одну шкалу времени
- сравните всплеск с пределом CPU, а не с дневным средним
- прочитайте одну медленную трассу от начала запроса до ответа
- изменяйте либо лимит CPU, либо количество реплик, затем тестируйте снова
Делайте по одному изменению за раз. Если поднять лимиты и добавить реплики одновременно, вы не узнаете, что именно исправило проблему. То же относится и к тюнингу запросов при одновременном изменении автоскейлинга.
Что делать дальше
Начните с самого простого исправления, которое подтверждается данными. Если графики показывают, что всплески запросов упираются в квоту CPU, повышайте лимиты или масштабируйтесь наружу. Если математика всплеска не указывает на CPU, оставьте лимиты и продолжайте поиски.
Многие команды повышают лимиты слишком рано. Это может скрыть проблему на неделю, а потом задержки возвращаются под большей нагрузкой. Повышайте лимиты только если сервис тратит время в троттлинге во всплеске и задержка растёт в тот же момент.
Если CPU — узкое место, у вас есть два пути: дать контейнеру больше запасa или сделать каждый запрос дешевле. Маленькие оптимизации часто выигрывают. Кэшируйте повторяющиеся чтения, пакетируйте разговорчивые вызовы и заменяйте тяжёлую парсинг/сериализацию на более лёгкие пути.
Простой план работает:
- сравните всплеск трафика с лимитом CPU и фактическим троттлингом
- делайте по одному изменению — лимит, поведение кэша или размер батчей
- сгладьте острые пики очередью, обратным давлением или растягиванием расписания
- после каждого изменения снова проверьте задержку, уровень ошибок и троттлинг
Сглаживание пика часто лучше грубой силы. Если cron‑задача, fan‑out вебхуков или импорт падают все одновременно, переместите работу в очередь или разнесите расписание на несколько минут. Если интерактивный трафик вызывает всплеск, добавьте обратное давление, чтобы сервис сам замедлял приём, прежде чем упадёт.
Держите графики простыми. В большинстве случаев вам нужно лишь несколько линий в одном окне: RPS, использование CPU, троттлинг CPU и задержка. Если эти линии идут в унисон, картина обычно ясна. Если нет — база всё ещё может заслуживать более тщательного рассмотрения.
Небольшой пример показывает ход сделки. Если трафик вырос в 3× на 20 секунд и троттлинг сразу подскочил, повышение лимита часто снизит p95 быстрее, чем любое переписывание запросов. Если же троттлинг остаётся ровным, тратьте время на другие места.
Если нужно второе мнение, Oleg Sotnikov проводит ревью лимитов сервиса, паттернов всплесков и предположений о базе в рамках консультаций. На практике это часто быстрее, чем ещё неделя гонок за неверным узким местом.
Часто задаваемые вопросы
Как база данных может быть «здоровой», но выглядеть медленной?
Приложение может проводить большую часть запроса в ожидании CPU ещё до отправки запроса в базу. Тогда общая задержка растёт, а время выполнения самого запроса остаётся маленьким. Перед правками в SQL проверьте использование CPU на уровне пода, троттлинг и задержки на одной временной шкале.
Как выглядит троттлинг CPU в продакшне?
Обычно вы увидите резкие пики задержки при низком уровне ошибок и нормальном CPU на ноде. Один загруженный под достигает своего лимита CPU, запросы ждут выполнения, и пользователи ощущают тормоза, хотя сервис продолжает отвечать.
Какие метрики стоит сначала построить?
Начните с скорости запросов в окнах 1–5 секунд, использования CPU по подам, времени троттлинга CPU и p95/p99 задержки. Отложите их на одном графике — если сначала растёт трафик, затем троттлинг, а потом задержка, это сильный указатель на проблему с CPU.
Почему графики за одну минуту пропускают проблему?
Среднее за минуту сглаживает те секунды, которые действительно мешают пользователям. Сервис может задыхаться 8 секунд, а оставшиеся 52 секунды выглядеть спокойно. Короткие окна показывают форму всплеска, запускающего троттлинг.
Как соотнести всплески запросов и лимит CPU?
Оцените время CPU на запрос, умножьте на количество запросов в секунду во всплеске для одного пода. Если получается больше CPU, чем разрешено лимитом пода, этот под будет ставить задачи в очередь и троттлиться во время пика.
Стоит ли увеличивать размер пула базы при росте задержки?
Нет. Больший пул соединений чаще добавляет больше рабочих процессов, которые конкурируют за одно и то же ограниченное CPU. Сначала проверьте, не ждёт ли приложение CPU до того, как база начнёт тормозить. Если троттлинг растёт вместе с задержкой — решайте проблему с CPU или обработкой всплесков.
Откуда обычно начинаются эти всплески?
Запланированные задания, циклы повторных попыток, промахи кэша, холодные поды после деплоя, синхронизации с партнёрами, импорты и наплывы вебхуков — многие всплески приходят из этих источников. Ищите события, которые совпадают с пользовательским трафиком, особенно на круглых отметках вроде :00 или :30.
Правильно ли всегда повышать лимиты CPU?
Не всегда. Повышайте лимиты только если данные показывают троттлинг в проблемное окно. Если троттлинг не растёт, ищите причину в другом. Также можно снизить CPU‑стоимость запроса, добавить реплики, поставить работу в очередь или растянуть расписание.
Как понять, что проблема в одном поде?
Смотрите поды по‑отдельности, а не только средние по деплойменту. Один под может получать более горячую долю трафика, достигать лимита и тянуть задержку вверх, пока остальные выглядят нормально. По‑подовые графики быстро это выявляют.
Что менять в первую очередь во время инцидента?
Начните с самого медленного пода в окне, где пользователи ощущали задержку. Проверьте троттлинг, трафик и задержки вместе, затем откройте одну медленную трассу и прочитайте её в порядке: начало запроса → запрос в БД → ответ. Сделайте одно изменение (лимит или количество реплик) и протестируйте снова.


